一种网络数字虚拟资产的分类识别系统及方法与流程
本发明涉及数字信息处理技术,尤其是一种计算机网络中虚拟资产的分类识别方法。
背景技术:
信息技术和电子技术的高速发展使得网络数字虚拟资产无处不在,并迅速地融入到我们的生活中,比如:网上银行、电子邮箱、网络帐号、网络域名、网络虚拟货币、网络虚拟装备、网络所有权等等。这些种类繁多、结构复杂的虚拟资产给管理带来极大的不便,同时也增加了交易的风险。利用现代监测技术,可以检测某个区域服务器上的虚拟资产数据,借助于大数据分析方法建立模型,对网络数字虚拟资产进行有效地分类和识别具有可操作性。
鲁明勇2006年给出了网络虚拟资产的概念和产生的技术背景。说它是依托于互联网产生的,由企业或个人所控制的,能以货币计量的、具有收益预期的网络经济资源,是独立于企业传统资产之外的新型网络无形资产。从计算机技术的角度来看,它实际上是组二进制数字代码,由网络数据库系统来管理,且依赖于计算机硬件和软件系统。网络数字虚拟资产的本质是以数字形式存在,通过网络的形式表现出来的物品。文献中,作者还给出了网络虚拟资产的价值评估原则和方法,并从各网站对网络虚拟资产的实时报价出发,通过定义给出了网络虚拟资产的分类简表。
tibshirani等公开通过间隙统计估计数据集中的簇数。jawadiounousse等使用无监督的概率神经网络(pnn)方法从多时相卫星图像中进行土地利用分类。
李涛等在网络空间数字虚拟资产保护研究构想和成果展望(工程科学与技术,2018)中针对虚拟货币、数字版权、网络游戏等网络空间数字虚拟资产的安全问题,研究数字虚拟资产保护基础理论体系,包括数字虚拟资产的数学模型、安全管理、威胁感知和风险控制等,以此奠定网络空间数字虚拟资产保护的基础理论和方法。研究围绕网络空间数字虚拟资产保护的关键科学问题:数字虚拟资产数学表征问题、数字虚拟资产应用安全可控问题,以及数字虚拟资产威胁管控问题,分别开展研究,通过数字虚拟资产基础数学模型、数字虚拟资产安全管理和交易技术、数字虚拟资产安全威胁感知方法、数字虚拟资产动态风险控制机制等研究。构建了网络空间数字虚拟资产保护理论研究体系,解决了数字虚拟资产的数学表征、数字虚拟资产应用安全可控、数字虚拟资产威胁管控等技术难题。
很多学者认为:网络虚拟财产不应纳入传统的财产分类,为了对越来越多的虚拟资产进行有效的识别和管理,对虚拟资产的分类和识别非常重要。但上述文献没有披露针对网络中种类越来越多,表现形式各种各样的虚拟资产,如何进行分类和识别的相关技术。网络空间数字虚拟资产已成为重要的社会财富。然而,国内外对于数字虚拟资产保护方面的研究均尚处于探索阶段,网络交易更加的普及,虚拟资产的种类越来越多,识别网络虚拟资产的种类,针对不同种类的资产进行相应的管理越来越重要,成为网络空间数字虚拟资产保护研究的趋势和热点。
技术实现要素:
本发明针对现有技术中的上述缺陷,从网络虚拟资产的基本属性出发,基于结构体数据库、ward’s聚类法、概率神经网络、自组织特征映射神经网络和hausdorff距离函数,使用结构体数据库存储数据,利用ward’s等聚类法和聚类有效性指标确定网络数字虚拟资产的最佳聚类数范围后,使用概率神经网络和最佳分类数指标确定其最佳分类数,使用自组织特征映射神经网络和hausdorff距离函数来对数据进行分类和识别。
本发明解决上述技术问题的技术方案是,提出一种网络虚拟资产的分类和识别方法,包括步骤:数据处理模块检测获取的网络虚拟资产数据建立结构体数据库,并创建一个与结构体数据库关联的数据源;对关联的数据源进行滤波去噪处理;滤波去噪处理后的数据进行系统聚类,获得聚类数k;使用ward聚类法对数据进行聚类,利用自组织特征映射神经网络(som)对数据进行分类,得到聚类数k对应网络隐藏层的输出概率矩阵,根据输出概率矩阵,获得最佳分类数k*;根据最佳分类数k*和样本数据构建自组织特征映射神经网络分类器,并确定每类的质心,以已知网络虚拟资产种类数目为行,最佳分类数k*为列构建hausdorff距离矩阵h,并依据该矩阵分类得到类的标签,将相关网络资产匹配到具体类别。
本发明进一步包括,获得聚类数k进一步包括,当得到聚类数范围[kmin,kmax]后,选取范围[kmin,kmax]内的k个整数作为聚类数。根据输出概率矩阵,调用公式
所述将网络虚拟资产匹配具体类别进一步包括,对监测对象网络虚拟资产进行不重复监测,将每个类别的中心对应的二进制字符串依次分组获得类中心特征向量,利用词库模型把网络虚拟资产类别(如域名、虚拟货币、网上银行账户等)转化成特征向量,计算这些特征向量与每个类中心特征向量之间的hausdorff(豪斯多夫)距离。用hausdorff距离度量两个不同类别的网络虚拟资产集合间的最大不匹配程度。
任意选择虚拟资产类别中的两个类,两个类中样本的集合分别为:a=(a1,a2…,ap),b=(b1,b2…,bq),根据公式h(a,b)=max{h(a,b),h(b,a)}确定特征向量集合a与特征向量集合b之间的双向hausdorff距离h(a,b),其中,
根据hausdorff距离,建立hausdorff距离矩阵h,
其中,dij表示第i个已知虚拟资产类与自组织映射神经网络得到的第j个类间的hausdorff距离,可以是双向距离h(a,b)也可以是单向距离h(a,b)和h(b,a)。距离矩阵h中每行的最小元素对应的类别为匹配类别,获得从自组织映射神经网络得到的类别标签(确定类名称),得到每个类别的匹配结果。当出现多重匹配时,以矩阵中元素最小者对应的类别为匹配类别。
本发明还提出一种网络数字虚拟资产的分类和识别系统,包括:数据处理模块,预分类模块,精确分类模块,评价模块,数据处理模块检测获取的网络虚拟资产数据建立结构体数据库,创建一个与结构体数据库关联的数据源,对关联数据源进行滤波去噪处理;预分类模块对滤波去噪处理后的数据进行系统聚类,获得聚类数k,构建聚类数k对应的概率神经网络隐藏层的输出概率矩阵;评价模块利用最佳聚类数评价指标针对每个类别选择样本训练概率神经网络,得到聚类数k对应的网络隐藏层的输出概率矩阵,根据输出概率矩阵,获得最佳分类数k*;利用最佳分类数k*和样本数据构建自组织特征映射神经网络分类器,在每个类别中构建概率矩阵,并计算分类有效性指标d;精确分类模块根据输出概率矩阵选取有效性指标最大值,获得最佳分类数k*,利用k*和样本数据构建自组织特征映射神经网络分类器,确定每个类别的中心,以已知网络虚拟资产种类数目为行,最佳分类数k*为列构建hausdorff距离矩阵h,并依据该矩阵获得分类得到的类的标签。
本发明针对结构复杂品类繁多的网络虚拟资产,利用监测和分类技术,基于结构体数据库、ward’s聚类法、概率神经网络、自组织特征映射神经网络和hausdorff距离函数,使用结构体数据库来存储数据,以便于编程系统读取数据,使用概率神经网络和最佳分类数指标确定其最佳分类数,使用自组织特征映射神经网络和hausdorff距离函数来对数据进行分类和识别可以检测某个区域服务器上的虚拟资产数据,对网络数字虚拟资产进行有效地分类和识别具有可操作性。通过皮尔逊相关系数和显著性检验得到识别结果可信度,达到相关要求。与现有技术相比,本发明不仅提出了网络虚拟资产的具体分类方法,还建立起网络虚拟资产的自动识别系统模型,并能够量化地给出网络虚拟资产的分类和识别准确度。
说明书附图
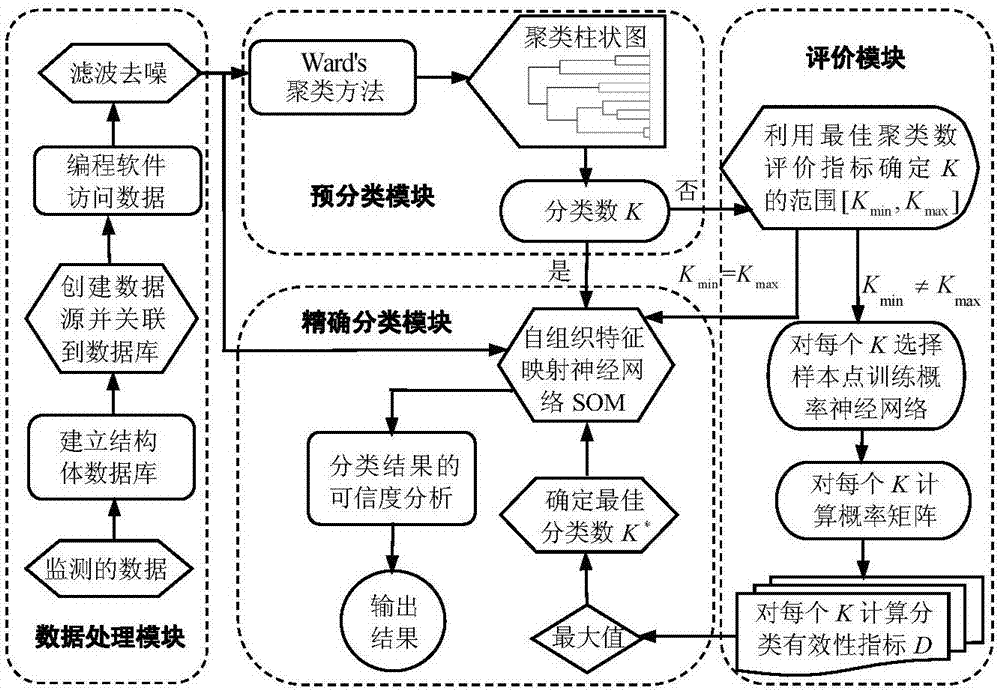
如图1所示为网络数字虚拟资产的分类和识别模型。
具体实施方式
网络中数字虚拟资产的实际存在形式是二进制的数字代码,可以使用监测设备从某个区域的互联网的服务器里合法地获得。监测要具有持续性,比如在同一个区域连续监测n天(如n=30),每天监测m小时(如m=4),并对监测到的数字代码进行编号等。如果获得的不是直接的数字代码,如英文文字和中文文字等,可以通过常用的词库模型(如python3)来实现代码的转换。由于数据量大,为了数据处理的方便性,可以利用监测获得的所有数据构建结构体数据库,当然,也可以借助sql-server软件建立一个空数据库,再把采集处理后的数据导入数据库中,并依此为数据表命名。为了方便将数据库中的数据调入matlab、c++等中执行程序,可以在windows系统下创建一个数据源,并将其关联到建立好的数据库。这样,在对网络数字虚拟资产分类识别时,就可以通过数据库方便地调取需要的数据,在每次使用数据库中的数据时,只需在执行程序中将matlab与数据源相连接即可。
如图1所示为网络数字虚拟资产分类和识别模型,包括,数据处理模块,预分类模块,精确分类模块,评价模块,数据处理模块监测获取的网络数字虚拟资产信息,建立结构体数据库,创建数据源并关联到数据库中,对数据源进行滤波去噪处理;预分类模块可采用ward’s聚类方法、柱状图聚类方法等分类方法将去噪后的数据分为k类,如果不能分成k类,评价模块利用最佳聚类数评价指标获取聚类数的范围[kmin,kmax],选取聚类数范围[kmin,kmax]内的k个整数作为聚类数,从每一个类别中选择样本数据训练概率神经网络,得到聚类数k对应的网络隐藏层的输出概率矩阵,计算分类有效性指标d;精确分类模块选取有效性指标最大值,该最大值作为最佳分类数k*,通过自组织特征映射网络som进行精确分类,对分类结果可行度进行分析,输出处理结果。
以下通过具体实例对本发明的分类和识别方法作具体描述。
步骤1:数据处理模块检测获得网络中虚拟资产数据,建立结构体数据库,并创建一个数据源,用于与数据库关联。
首先,数据处理模块监测数据表里的时间格式调整为以秒计时,然后,可使用sqlserver软件建立一个空数据库,并将其命名,如“监测数据”。再将预处理后的数据表依次导入到“监测数据”中,并将其命名,如“data1”、“data2”,以此类推,以得到所有监测时间对应的数据表。最后,为了方便将该数据库中的数据调入matlab,在windows系统下通过创建名为“资产监测数据”的数据源,并关联到数据库“监测数据”。
步骤2:对关联数据进行滤波去噪处理。由于在监测时,数据常常会受到其它电子信号的干扰,因此有必要对监测到的数据作滤波处理。可以使用自适应滤波、维纳滤波和卡尔曼滤波等滤波器去除干扰数据。
步骤3:使用ward’s聚类法对滤波处理后的数据进行系统聚类,并分析聚类柱状图以获得聚类数k或者聚类数的范围。为了使每一类内数据的方差较小,类与类之间的离差平方和较大,使用ward聚类法对数据进行聚类,当聚类数k确定时,利用自组织特征映射神经网络(som)对数据进行分类,得到对应网络隐藏层的输出概率矩阵,该聚类数k为最佳分类数k*,执行步骤6。
对于聚类数k不能确定的,可以使用聚类评价指标来确定聚类数的范围,当得到聚类数范围[kmin,kmax]时,执行下一步。常用的评价指标有calinski-harabasz指标、silhouette指标、davies-bouldin指标、gap指标等。使用各个评价指标得到评价值。当得到确定的最佳聚类数,利用自组织特征映射神经网络(som)对其进行分类。
步骤4:对聚类数范围内的每一个整数k,随机选择一定数量的样本数据训练概率神经网络(pnn),并得到对应于不同k的网络隐藏层的输出概率矩阵。
步骤5:调用公式
步骤6:利用k*和随机选择的训练样本构建自组织特征映射神经网络分类器,并确定每类的几何中心(质心),再将相关网络资产匹配到具体类别。如具体可采用以下方法,
分类器的输出神经元个数取为k*,训练集包含s个虚拟资产监测样本数据,每个样本数据由一个q维向量(q表示维数,对第k个虚拟资产,假设检测的间隔时间为△t,从第一个获得的检测数据开始,每间隔△t时间获得下一个检测数据,直到获得r个数据为止,由此得到一个向量qk,k=1,2,…,k*。qk中的k为下标)表示,并用一维线阵结构表示输出节点的排列形式,可使用kohonen学习算法对权值进行训练以获得分类器。其中,分类器的初始权值是从训练集中随机抽取k*个输入样本构成的,优胜领域的形式可以采用正方形、六边形等,优胜领域的半径r(t)采用公式r(t)=ce-bt/t进行更新,确定类中心,其中,c为与k*有关的正常数,b为大于1的常数,t为预先设定的最大训练次数;t为当前训练次数,学习效率e是迭代次数的单调下降函数,其表现形式可以是线性的,也可以是非线性和分段的,当学习率减小到0或者小于阀值时训练结束。
然后,利用词库模型把已知的虚拟资产类别(如域名、虚拟货币、网上银行账户等)转化成二进制向量,并计算这些向量与由每个类中心对应的向量之间的hausdorff(豪斯多夫)距离。
hausdorff距离是一种可以应用在边缘匹配算法的距离,能够有效地解决遮挡的问题。任意选择虚拟资产类别中的两个类,两个类中样本的集合分别为:a=(a1,a2…,ap),b=(b1,b2…,bq),其中,ai表示类a中的第i个点,i=1,2,…,p,bj表示类b中的第j个点,j=1,2,…,q,其中,点的维数都为q。则根据公式h(a,b)=max{h(a,b),h(b,a)}确定这两个集合之间的双向hausdorff距离h(a,b),即获得两个类的双向hausdorff距离。其中,
将已知的网络虚拟资产向量集定义为集合a=(a1,a2…,ap),其中的元素表示某类虚拟资产向量数据,如a1表示通过词库模型转换后的域名向量数据,a2表示虚拟货币向量数据,a3表示转换后的网上银行向量数据等等。将分类得到k*个类的中心向量集定义为集合
其中,dij表示第i个已知类与自组织映射神经网络得到的第j个类间的hausdorff距离,可以是双向距离h(a,b)也可以是单向距离h(a,b)和h(b,a)。最后,根据距离矩阵h中每行的最小元素可以得到每个类别的匹配结果,即获得从自组织映射神经网络得到的第j个类的标签(确定的类名称)。当出现多重匹配时,如d12和d22分别是矩阵h第一行和第二行的最小元素,此时就会将分类得到的第2类匹配给a1和a2所对应的已知类。此时,只需比较d12和d22的大小,其中的最小者表示分类得到的类的最终匹配结果。
步骤7:将识别样本输入到自组织特征映射神经网络分类器中,获得识别样本的类,并对结果进行可信度分析。
在网络虚拟资产的识别中,可以将监测获得的任意一个或多个网络虚拟资产视为待识别的样本或样本集合。首先,对识别样本集进行处理,将其加入到数据库中,使其单独成一个数据表,并命名如“识别数据”。然后,将这些待识别的样本输送到已经完成训练的自组织神经网络的输入层中进行学习。最后,通过神经网络的kohonen学习算法,将待识别的样本依次匹配到输出层的神经元,以完成待识别样本的分类。如令待识别样本集为is=(s1,s2…,sr),其中,si,i=1,2,…,r为待识别的第i个样本,其维数与自组织神经网络的各个神经元的维数相同,都为q。将si输送到自组织神经网络的输入层,通过学习后,可以在输出层的k*个神经元中找到一个神经元neuronk,k∈{1,2,…,k*},使得si与neuronk最相似(匹配),从而将si识别为neuronk所对应的类中,依此完成待识别样本的分类。
使用皮尔逊相关系数r和相关系数的显著性检验来量化识别结果的可信程度。皮尔逊相关系数能够表征识别样本si和匹配神经元neuronk之间的相关性。按照公式
一般地,当相关系数的绝对值|r|介于0~0.09时,认为si与neuronk没有相关性;当|r|介于0.1~0.3时,认为si与neuronk为弱相关;当|r|介于0.3~0.5时,认为si与neuronk中度相关;当|r|>0.5时,认为si与neuronk为强相关性。
但是,当样本数量增加时,序列之间的差异就会增大,这样,达到显著相关的相关系数就会越小,因此不能单一地看相关系数的大小来判断序列间的相似程度。此时,需要进行相关系数的显著性检验,检验是采用数理统计中的假设检验方法,实际操作时,先设定可信度为α,利用检测序列的长度减去2和α的值查相关系数的最低值γα,当计算值r大于γα时,通过显著性检验,得到识别结果的可信度为(1-α)%。从而,对识别样本而言,系统就能够给出带可信度的识别结果。
- 还没有人留言评论。精彩留言会获得点赞!