基于多特征和帧置信分数的低延迟视频动作检测方法与流程
本发明涉及计算机视觉技术中的视频人体动作检测技术,特别是一种基于多特征和帧置信分数的低延迟视频动作检测方法。
背景技术:
随着科学的发展以及计算机技术水平的提高,人们对信息的获取分析有了更高层次的要求,人们越来越期望计算机能够像人一样通过视觉来认知世界,即计算机视觉。人体动作识别作为计算机视觉领域一个研究热点,各种研究技术方法已经变得非常成熟。动作检测由动作识别发展而来,其目的是在一段没有剪辑过的长视频中定位动作的位置,同时需要对视频中的动作给出正确的标签。
有研究者提出了低延迟检测(low-latencydetection)的概念。延迟原本是交互式体验系统中的一项关键指标,指的是用户在做出动作到得到系统反馈之间的时间差。将此概念扩展到识别领域,可以理解为从观测数据产生到得到正确识别结果之间的时间差。我们可以将其看成是早期、实时、连续和在线识别的一种泛化。简单的来说,低延迟动作检测是指,对于未剪辑的长视频,在播放过程中对已观测到的动作内容进行识别并且定位每一个动作的开始和结束。低延迟识别检测的难点主要来自于两个方面:1)数据的不完全观测性,即在只观测到部分行为数据的情况下就要识别出该行为的类型并且需要定位每一个动作的开始结束;2)对算法的时效性要求,即要求算法能够在视频采集的同时尽快的检测并识别出行为的类型。这两个难点导致很多传统算法无法直接应用到该类问题上。
视频中人类活动的自动检测有很多潜在的应用,如视频理解与检测、自动视频监控和人机交互等。再更进一步地讲,对于许多应用都需要尽早地检测出活动。低延迟的人体动作分析在多样的人机交互系统中已经越来越凸显其重要性。对人机交互系统来说,系统反应延时的最小化是一个非常重要的考虑因素。过高的延迟不仅严重降低了交互系统的用户体验,同时也使得某些特定的交互系统,比如手势控制或者增强感知的电子游戏,丧失吸引力从而难以普及。特别地,在制造机器人方面低延迟检测是非常重要的,如部署一个机器人帮助一位病人站起来之前,需要先检测出这位病人是想做什么动作。或是对于一个可以与人类进行情感交流的机器人,它必须能够准确、迅速地从面部表情发现人类的情绪状态,这样可以及时适当的做出响应。另外,低延迟检测还可以使系统提前做出预报。比如,如果能够在危险行为尚未发生时就给出预警,那么就有可能制止一些危险事件的发生。综上所述,基于视频的人体低延迟动作检测的研究就成为了一个很重要的研究方向,具有极大的商业价值与现实意义。
技术实现要素:
本发明的目的在于提供一种基于多特征和帧置信分数的低延迟视频动作检测方法,可以提供完全的数据观测,以及实时的计算。
实现本发明目的的技术方案为:一种基于多特征和帧置信分数的低延迟视频动作检测方法,包括以下步骤:
步骤1,对数据集进行数据预处理,得到rgb图片和光流图片集;
步骤2,构建三维卷积-反卷积的cdc神经网络模型;
步骤3,将步骤1中得到的rgb图片和光流图片训练集分别输入到步骤2的网络模型中进行训练,得到训练好的模型;
步骤4,将rgb图片和光流图片的测试集分别放入步骤3训练好的两个模型中,生成两个模型的输出后并融合,得到每一帧的置信分数,生成动作片段;
步骤5,使用步骤4得到的动作片段,在时序上分别选取不同百分比的帧数并与真值作比较,得到低延迟动作检测结果。
与现有技术相比,具有以下优点:与传统的完整动作检测需要先提取动作片段放入网络分类不同,本发明只需要在网络中按时序输入帧序列,就能得到每帧的动作类别,是一种基于帧的动作检测方法。同时,本发明引入了一个rankloss的损失函数,能够约束模型输出一个正确标签的单调非减检测分数,从而能尽早地检测出动作的开始,实现低延迟动作检测。并且,本发明使用了两种数据训练网络,一个是rgb图片,充分使用了空间特征,另一个是光流图片,充分使用了时间特征,最后将时空训练数据结合,提取了动作信息,提高帧分类的置信分数,从而提高了动作检测的精度。
下面结合说明书附图对本发明作进一步描述。
附图说明
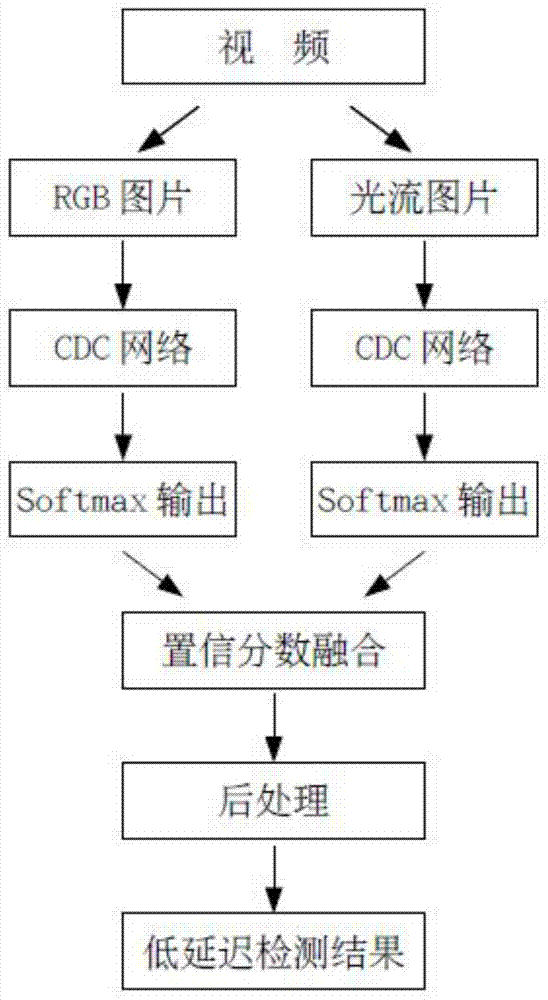
图1为视频低延迟动作检测技术的基本框架示意图。
图2为光流图。
图3为cdc网络结构图。
图4为帧置信分数图。
具体实施方式
下面结合附图对本发明进行进一步详细的说明:
本发明提出一种基于多特征和帧置信分数的低延迟视频动作检测方法,括构建多层三维卷积网络、提取rgb和光流图片、提取帧置信分数、低延迟检测等过程,对未剪辑的长视频进行一系列的计算,在视频播放过程中能检测出动作的发生并判断其类别。视频低延迟动作检测技术的基本框架如图1所示,本发明是按照这个基本框架进行的。
步骤1、把未剪辑的长视频,包括训练集和测试集,以png的图片格式,按照25fps的帧率读出。
步骤2,如图2所示,将从未剪辑长视频中读出的连续rgb图片使用tvl1光流算法获取光流图片。每两帧rgb图片经过算法生成一组x、y方向上的两张单通道光流图片。光流算法的具体方法如下:
假设在时刻t时,图像上一点m(x,y)的灰度值为i(x,y,t),在经过dt后,该点运动到新的位置m'(x+dx,y+dy),该点灰度值为i(x+dx,y+dy,t+dt),假设图像中该点运动后到达位置的灰度值等于运动前位置的灰度值,则有:
i(x,y,t)=i(x+dx,y+dy,t+dt)
将等式右边进行泰勒公式展开,即:
其中ε代表二阶无穷小项,由于dt→0,忽略ε,可以得到
设u、v分别为该点光流沿x轴和y轴方向上的速度矢量,且有
ixu+iyv+it=0
为了求解出上式唯一解u和v,必须附加另外的约束条件。tvl1算法根据平滑性假设——每个像素点的运动与其领域点的运动服从平滑性分布,加入了平滑项建立光流模型,如下:
e是光流模型的能量函数,λ是数据项的权值常数,
步骤3,构建cdc网络,cdc网络结构如图3所示。cdc网络采用c3d网络结构的conv1a-conv5b作为cdc的第一部分,其中将第五层的池化改为1×2×2。然后将c3d的三维卷积网络后的全连接层改成cdc滤波器。cdc6层将卷积后的输出数据(512,l/8,4,4)在空间上下采样、在时间上上采样成为(4096,l/4,1,1),cdc7层将cdc6层的输出在时间上上采样成为(4096,l/2,1,1),然后cdc8层将上一层的输出继续在时间上上采样成为(k+1,l,1,1),最后经过softmax层生成l帧的分类结果。
步骤4,整个网络的损失函数有两个,一个是基于交叉熵的分类损失函数,另一个是基于rankloss的损失函数。整体损失函数计算如下:
其中,
其中,yt是训练序列中第t帧的真实标签,
本发明在基于分类损失函数的基础上还提出了一个rankloss函数。如图4所示,在低延迟检测视频的过程中,看到一个动作的帧数越多,其属于某个正确类别的检测分数则会越高,可信度越大;反之,这个动作属于某个错误类别的检测分数会越低,可信度越小。因此,在一个动作发生时,它的检测分数会是一条单调非减曲线。根据这个特性,如果在t时间内没有发生动作改变,第t帧的检测分数肯定不小于前一帧的检测分数。因此,构建了一个rankloss函数。如果第t帧没有动作发生改变,损失函数计算如下:
如果在第t帧动作发生改变,即第t帧与第t-1帧不属于同一类别,损失函数计算如下:
步骤5,cdc网络第一层的输入为视频中的32帧图像,把视频每32帧作为一个切片输入网络中,第(1~32)、(33~64)、……帧作为输入,切片窗口互不重叠。使用rgb图片和光流图片按照上述方式分别作为训练集放入构建好的cdc网络中并开始训练,使用随机梯度下降(sgd)优化目标函数,初始学习率设置为1e-6,batchsize设为4,迭代25个epoch后最终得到两个训练模型。
步骤6,使用步骤5中的两个训练模型分别对rgb和光流测试集图片进行分类,提取倒数第二层网络的输出,即得到每帧属于每一类的置信分数,并取最大的置信分数当作该类的动作检测分数,最后融合rgb图片和光流图片的输出分数作为最终帧置信分数。
步骤7,根据步骤6中的帧置信分数得到每帧的类别,在一段连续视频帧中,如果相邻两帧属于同一类别,就将这些帧依次合并成为为小片段。
步骤8,如果步骤7中的小片段在时间序列上两两相近,即两个小片段之间相差的帧数小于一个20帧,就将它们继续合并成一个大片段,成为最终的动作片段。
步骤9,使用步骤8得到的动作片段,在时序上分别选取不同百分比的帧数,如一个50帧的动作片段,从中取前3/10的帧数,即取该片段的前15帧来进行低延迟动作检测。将这前15帧与真实的动作片段的前3/10帧数做交集,得到两者的重叠度,然后根据不同的iou阈值来计算平均精度(ap),最后平均所有类别以获得平均精度均值(map)。低延迟动作检测效果是通过map(平均精度均值)来评定的,如果平均精度均值高,那么这个低延迟检测效果就好。(也就是说map相当于这个低延迟检测的结果)。
- 还没有人留言评论。精彩留言会获得点赞!