一种基于机器学习的辅助司法案件判决的装置的制作方法
本发明涉及一种基于机器学习的辅助司法案件判决技术,属于非结构化文本处理技术领域。
背景技术:
近年来,人民群众的法律意识、维权意识不断增强,各种矛盾纠纷大量增多,各类诉讼案件急剧增加,“案多人少”矛盾日趋突出,繁重的工作在一定程度上影响着法院的办案效果,存在同案不同判的现象,不利于公平公正的推展。
在上个世纪计算机技术以惊人的速度发展起来,大家就开始尝试将计算机技术运用到司法领域,比较有代表性的就是基于专家系统的计算机辅助量刑系统——justice系统,该系统根据大量司法领域专家的知识和经验编写规则模拟刑事诉讼过程以实现量刑结果的预测。但该方法耗费大量人力物力,而且实际使用极其不方便,需要自己衡量完善案情的细节以得到符合的结果,而且该系统内部规则制定好后并不能很好的符合实际情况。
随着人工智能的迅速发展,我们处于一个大数据的时代,在拥有海量的文书数据后,大家已经开始尝试将ai技术运用于司法领域。国外比较成功的运用是16年ibm推出的世界首位ai律师ross,它主要用于提供法律咨询服务,实现法律相关对话问答而不运用于司法判决,而且ross仅仅针对于英美法系,语言也仅支持英语。
在计算机技术方面,数据时代互联网容纳了海量的各种类型的数据和信息,为了有效地组织和管理这些信息,并快速、准确、全面地从中找到用户所需要的信息,基于机器学习的文本分类系统作为处理和组织大量文本数据的关键技术,得到有效发展,能够在给定的分类模型下,根据文本的内容自动对文本分门别类,且达到较高的准确率。
随后遇到的许多实际问题中,一个样本可能同时属于多个类别,由此引出了多标记学习(multi-labellearning)的研究。至今,研究者们已经提出了多种多标记学习的方法,比如基于支持向量机的方法,基于bp神经网络的方法,基于概率生成模型的方法等。这些算法在文档分类、生物信息学以及场景分类等许多领域得到了成功的运用。
技术实现要素:
技术问题:本发明提供一种基于机器学习的辅助司法案件判决的装置,通过训练模型学习发现案件事实描述与罚金范围和相关法律条文之间的关联,实现对任意给定案件事实描述文本的罚金额度范围和法条标签进行预测。
技术方案:本发明的基于机器学习的辅助司法案件判决的装置,包括:
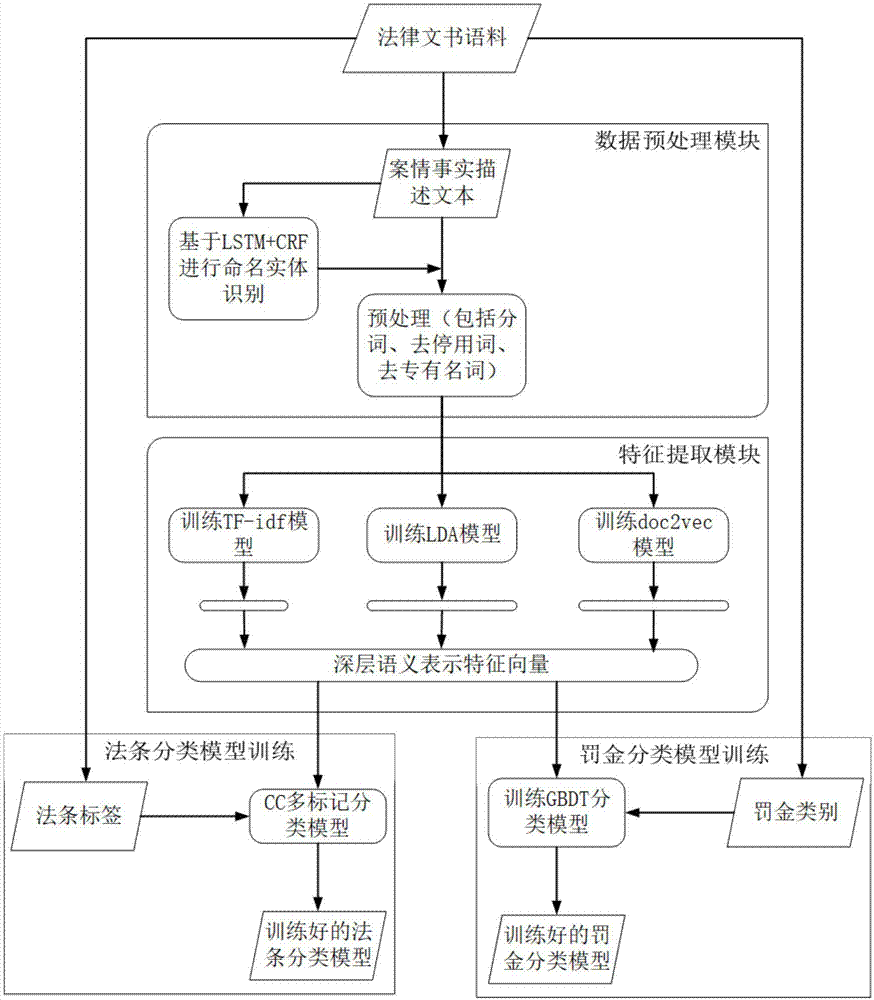
数据预处理模块,对现有初始数据中的案件事实描述文本进行预处理,得到每一份文本对应的词语列表;
特征抽取模块,从所述数据预处理模块处理后的词语列表,抽取得到每一份文本对应的具有深层语义表示的特征向量;
模型训练模块,使用所述特征抽取模块处理得到的深层语义表示的特征向量和初始数据中包含的每一份文本对应的判决结果对模型进行训练,得到相关法条预测模型和罚金预测模型;
判决结果预测模块,对一份任意给出的案件事实描述文本经过预处理和特征抽取后得到一个具有深层语义表示的特征向量,将该特征向量分别输入到模型训练模块得到的相关法条预测模型和罚金预测模型,就能得到该案件事实描述文本对应的相关法条和罚金范围。
进一步的,本发明装置中,初始数据包括案件事实描述文本text,该文本对应的法条标签legalset,该文本对应的罚金范围penalty,数据预处理模块中的预处理具体包括如下内容:
a)分词操作:将案情事实描述文本通过现有的分词工具拆分成词语列表,
其中,texti是第i份案件事实描述文本,wij是第i案件事实描述文本分词得到的第j个词,mi是第i案件事实描述文本分词得到的得到的词语总数;
b)去停用词:将文本中与语义无关的词语从词语列表中删除,得到新的词语列表;
c)命名实体识别:使用条件随机场和长短期记忆网络进行命名实体识别,得到文本中的时间、组织、人名,并分别用time、org、person替换。
进一步的,本发明装置中,特征抽取模块中使用tf-idf、lda和doc2vec特征抽取方法抽取得到每一份文本对应的具有深层语义表示的特征向量,将下式(a)作为tf-idf、lda和doc2vec特征抽取方法的输入:
其中wij是第i案件事实描述文本分词得到的第j个词,mi是第i案件事实描述文本分词得到的得到的词语总数,n是初始数据中案件事实描述文本的数量;
分别得到tf-idf特征向量、lda主题特征向量、doc2vec特征向量,记作:
vec_tfidfi=[ti1,ti2,...,tim]
vec_ldai=[li1,li2,...,lih]
vec_doc2veci=[di1,di2,...,dik]
其中vec_tfidfi是第i篇文本的tf-idf特征向量,tij是vec_tfidfi特征向量的第j位的值,m是数据预处理模块处理得到的所有词语列表中不同词语的个数;
vec_ldai是第i篇文本的lda特征向量,lij是vec_ldai特征向量的第j位的值,h是文本lda特征向量的维度;
vec_doc2veci是第i篇文本的doc2vec特征向量,dij是vec_doc2veci特征向量的第j位的值,k是文本doc2vec特征的维度;
然后将所述tf-idf特征向量、lda主题特征向量、doc2vec特征向量合并得到每一份文本对应的具有深层语义表示的特征向量:
veci=[ti1,ti2,...,tim,li1,li2,...,lih,di1,di2,...,dik]=[vi1,vi2,...,vi(m+h+k)]。
进一步的,本发明装置中,相关法条预测模型是通过训练一个基于classifierchain方法多标记分类模型得到的,模型训练所需数据如下所示:
in=[vec1,vec2,...,vecn]
result=[legalset1,legalset2,...,legalsetn]
其中veci作为输入,表示第i篇文本具有深层语义表示的特征向量,legalseti是初始数据中第i份案件事实描述文本的法条标签结果;
训练的具体方式为:基于classifierchain方法的多标记分类,对每一个标记训练一个单分类器,将所述多个单分类器串联形成一个链,依次训练这些单分类器,然后第一个分类器的输入是in,而后面的单分类器的输入除了in,还包括在链上所有先于自身训练的分类器的输出,在每个单分类器输入后,判断该单分类器输出是否包含在对应的法条标签中。
进一步的,本发明装置中,罚金范围预测模型是通过梯度提升决策树算法训练得到的,自定义罚金的范围分为8个档次:[0,1000元)、[1000元,2000元)、[2000元,3000元)、[3000元,4000元)、[4000元,5000元)、[5000元,10000元)、[10000元,500000元)、[500000元,∞),梯度提升决策树算法模型训练所需数据包括:
in=[vec1,vec2,...,vecn]
result=[penalty1,penalty2,...,penaltyn]
其中veci作为输入,表示第i篇文本具有深层语义表示的特征向量,penaltyi=0|1|2|3|4|5|6|7是初始数据中第i份案件事实描述文本的罚金档次。
本发明装置利用现有文书数据训练模型,然后使用模型对任意案件事实描述文本分析并预测其涉及法条和判决罚金结果。
1.模型训练包括如下模块:
a、数据预处理模块
本发明装置首先对已有的百万级别初始数据进行处理,初始数据包括案情事实描述文本和其对应的相关法条及罚金等级,可以记作为:
corpus=[[text1,legalset1,penalty1],...,[textn,legalsetn,penaltyn]]
其中text为案件事实描述文本,legalset为该文本对应的法条标签,penalty是该文本对应的罚金等级,n是初始数据的数量。
数据预处理操作,具体流程如下:
1).分词操作:将案情事实描述文本通过现有的分词工具拆分成词语列表,
其中,texti是第i份案件事实描述文本,wij是第i案件事实描述文本分词得到的第j个词,ni是第i案件事实描述文本分词得到的得到的词语总数。
2).去停用词:将文本中与语义无关的词语从词语列表中删除,得到新的词语列表;
3).命名实体识别:使用条件随机场和长短期记忆网络进行命名实体识别,得到文本中的时间、组织、人名,并分别用time、org、person代替,语义的损失对于我们要完成的任务并没有影响,却使原文本数据更加清晰,能够提升后续的特征提取效果;
b、特征抽取模块
数据经过预处理之后,每一个案件事实描述文本就变成了一个词语列表,数据如下:
其中wij是第i案件事实描述文本分词得到的第j个词,mi是第i案件事实描述文本分词得到的得到的词语总数,n是初始数据中案件事实描述文本的数量;
本模块抽取(a)式中每一份文本对应的深层语义表示特征向量,过程示意如下:
其中veci是第i篇文本的深层语义表示特征向量。
使用现有效果比较好的特征抽取技术:tf-idf、lda、doc2vec,上述式子(a)作为输入,分别得到每一份案情事实描述文本的tf-idf特征向量、lda主题特征向量、doc2vec特征向量,记作:
vec-tfidfi=[ti1,ti2,...,tim]
vec_ldai=[li1,li2,...,lih]
vec_doc2veci=[di1,di2,...,dik]
其中vec_tfidfi是第i篇文本的tf-idf特征向量,tij是vec_tfidfi特征向量的第j位的值,m是数据预处理模块处理得到的所有词语列表中不同词语的个数;
vec_ldai是第i篇文本的lda特征向量,lij是vec_ldai特征向量的第j位的值,h是文本lda特征向量的维度;
vec_doc2veci是第i篇文本的doc2vec特征向量,dij是vec_doc2veci特征向量的第j位的值,k是文本doc2vec特征的维度;
然后将该三个特征向量合并得到更深层语义表示的特征向量:
veci=[ti1,ti2,...,tim,li1,li2,...,lih,di1,di2,...,dik]=[vi1,vi2,...,vi(m+h+k)]
其中tf-idf、lda、doc2vec在本发明装置中使用细节如下所述:1)tf-idf(termfrequency-inversedocumentfrequency)是一种用于信息检索与数据挖掘的常用加权技术。tf意思是词频(termfrequency),idf意思是逆向文件频率(inversedocumentfrequency)。tf-idf是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
tf计算方法如下:
对应本发明,ni,j是第i份案情事实描述文本中的第j个词出现的次数,∑knk,j是这第j个词在所有案情事实描述文本出现的总次数。
idf计算式如下:
|d|是总案件事实描述文本的数量,|{j:ti∈dj}|是包含词语ti的案件事实描述文本的数量。
通过tf-idf就可以得到一个m维的向量,其中m取决于出现在所有案件事实描述文本的不同词语。
2)lda(latentdirichletallocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。
我们根据自己需求可以设定一个参数h,表示可能具有的主题数,lda通过所有案件事实描述文本的词语列表训练,可以得到每一篇文档可能为h个隐藏主题的概率,即每一个案件事实描述文本都可以得到一个h维的特征向量(l1,l2,...,lh)。
3)word2vec是一项将词转换成向量的技术,word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练;其次,该工具得到的训练结果一—词向量(wordembedding),可以很好地度量词与词之间的相似性,很好的保留词语的语义信息。基于word2vec原理,doc2vec得到一篇文章的语义向量,向量的长度是自己按照需求设定,一般为100~200之间的整数。
c、法条预测模型训练模块
在抽取得到每一份案情事实描述文本的深层语义表示的特征向量vec数组(下述数据in)以及已知的其对应的法条标签(下述数据result),相关法条预测模型的训练任务是训练一个基于classifierchain方法的多标记分类模型。模型训练的所需数据如下所示:
in=[vec1,vec2,...,vecn]
result=[legalset1,legalset2,...,legalsetn]
其中veci作为输入,legalseti是初始数据中第i份案件事实描述文本的法条标签结果。
基于classifierchain方法的多标记分类,对每一个标记训练一个单分类器,将所述多个单分类器串联形成一个链,依次训练这些单分类器,然后第一个分类器的输入是in,而后面的单分类器的输入除了in,还包括在链上所有先于自身训练的分类器的输出,在每个单分类器输入后,判断该单分类器输出是否包含在对应的法条标签中。对应本发明装置,基于classifierchain的模型首先根据输入in判断刑法第一条是否在法条标签结果集合中,然后结合输入in和第一条法条判断结果判断刑法第二条是否在法条标签结果集合中,以此不断进行得到最终模型预测的法条标签结果,对比已知的结果result,不断调整模型参数,使得模型输出的结果与已知的结果result尽可能相似。具体cc多标记中单标记分类器的实现可以有很多方法,本发明使用的是一个开源的使用广泛的cc方法,只需输入in和result,模型就会不断调整使得在输入in时,能得到和result尽可能相似的结果,最后模型稳定后得到的就是本发明装置需要的法条预测模型。
d、罚金预测模型训练模块
罚金范围预测模型的通过训练一个单分类器得到,自定义罚金的范围分为8个档次:[0,1000元)、[1000元,2000元)、[2000元,3000元)、[3000元,4000元)、[4000元,5000元)、[5000元,10000元)、[10000元,500000元)、[500000元,∞),模型训练的所需数据如下所示:
in=[vec1,vec2,...,vecn]
result=[penalty1,penalty2,...,penaltyn]
其中veci作为输入,penaltyi=0|1|2|3|4|5|6|7是初始数据中第i份案件事实描述文本的罚金档次。
使用上述数据训练分类器,本发明使用的是在文本分类任务中表现较好的梯度提升决策树(gbdt)算法,训练学习后得到的模型就是本发明需要的罚金分类预测模型。
2.使用模型预测
对任意给定的一份案件事实描述文本作为测试数据,与训练数据一样,经过预处理模块处理,在经过特征抽取模块后得到该文本的深层语义特征向量:
vectest=[v1,v2,...,v(m+h+k)]
将测试数据的深层语义表示的特征向量输入到使用训练数据训练学习得到的法条预测模型和罚金预测模型,模型的输出即为对该测试数据的相关法条预测和罚金等级预测结果。
本发明将文本分类和多标记分类这些机器学习方法运用到当前迫切需要大数据与ai技术辅助以解决“案多人少”和“同案不同判”窘境的司法领域,实现对案件事实描述文本分析得到相关法条标签与罚金类别,给司法人员一个有价值的裁决参考,提高审案效率,同时也可以作为判决是否公正的评判标准。
有益效果:本发明与现有技术相比,具有以下优点:
与本发明最接近的将计算机技术运用于司法判决的方法主要包括基于专家系统的计算机辅助量刑系统ustice和ibm推出的首位ai律师ross。
justice专家系统根据司法领域专家的知识和经验,编写规则,由用户根据案情判断犯罪情节作为系统的输入,比如:案件指控罪名、犯罪人年龄、认罪态度好不好,然后系统根据设定好的规则计算输出判决结果。本发明对比与justice专家系统的优点在于不需要领域专家耗费大量时间精力来编写规则,通过训练模型能够学习到大量文书数据中的经验,以此来预测判决结果。而随着大数据时代的到来,文书数据的获取并不存在任何问题,我们的发明就使用了300多万份刑事案件文书。此外justice专家系统还存在着不够智能的问题,需要用户自己去了解案情或者阅读案件事实描述文本后且具有一定的法律专业知识才能够判断出具体应该给系统什么输入,操作起来比较麻烦,要想使用该系统对案件描述文本进行量刑结果预测一次需要几分钟,而本发明只需经过一次训练,以后使用只需输入文本,使用最基本配置的计算机就能够在1-2秒左右得到结果,不需要用户有任何关于法律和计算机方面的专业知识。justice专家系统的另一个缺点是扩展性不好,justice实现的是基于刑事案件的量刑系统,刑法条文的些许更改需要对内部规则根据专家意见重新调整,要用于其他类型案件,如民事案件,构建系统需要耗费的工作量与初始并没有多大区别。本发明对比与justice优点还体现于领域的迁移性,只需要将更改训练数据,方法不需调整,就能够训练模型学习到数据中的经验,得到较好的预测结果。
ibm的ai律师ross推出于16年,使用的技术都是比较先进的,包括深度学习、认知计算等技术,但这些技术需要高性能的设备以支持他们的开发,而且开发的难度较高,自发布至今(2018.3),ross主要支持关于破产法、知识产权法、劳动和就业法,其他领域效果不是很理想,而本发明能够针对所有类型刑法案件进行预测,且开发难度较低所需设备的计算能力普通办公电脑就足以支持。此外ross主要是提供法律咨询服务,更契合与英美法系,对于大陆体系效果不可预知,且ross语言更多的是考虑英语,对中文适应新不行,而本发明采取大量中文文书数据,能很好在我国实际运用产生较大效果。
而且本发明从文本中得到更深层的语义表示,有效的提高分类器的效果,在对输入案件描述文本特征提取的过程中,本发明使用了包括lda、tf-idf和doc2vec等多种有效特征,以此为特征输入能有效提高后面的多标记模型法条模型以及罚金单分类模型的训练的效果,最终我们的模型测试结果在罚金预测和法条标签预测的准确率都达到了90%。
本发明采取多标记分类的classifierchain(cc)方法成功克服了没考虑标记之间的关联性这一缺点,因为不同法条很大可能会同时出现结果集合中,cc方法能够有效利用到这些联系。且它的计算复杂度与标记数目成正比,较于其他多标记方法计算复杂度比较低,
经过实例分析证明,利用基于机器学习的辅助司法案件判决方法,可以在大规模文本中有效的获取案件描述对应的法条集合与罚金类别,并且拥有更高的准确率和泛化能力。
附图说明
图1是本发明训练模型的基本过程的示意图;
图2是本发明模型实际使用预测的基本过程的示意图;
具体实施方式
下面结合实施例和说明书附图对本发明作进一步的说明。
本发明的基于机器学习的辅助司法案件判决的装置,主要包括利用案件事实描述文本分析训练模型和利用训练后的模型进行预测。
1:训练模型:
a)对初始数据预处理:
本发明的初始数据是百万级数量的刑事案件法律文书,将文书中本院认为前的文本作为案件事实描述文本,并且从后续的本院认为和判决结果段落中抽取到法院对该案件的量刑结果,包括罚金和依照的法条,比如,对于案号为“(2016)冀0281刑初253号”的文书,案件事实描述文本为“河北省遵化市人民检察院指控,2016年5月23日16时45分许,被告人李金强驾驶冀被告人李某驾驶冀b×××××、鲁×××rv165挂重型自卸半挂车沿大玉线由南向北行驶至遵化市刘官屯路段时,与延翠兰驾驶的电动自行车发生交通事故与延某驾驶的电动自行车发生交通事故,造成车辆损坏,延翠兰经医院抢救无效死亡延某经医院抢救无效死亡。遵化市交通警察大队责任认定:被告人李金强承担本起事故的主要责任被告人李某承担本起事故的主要责任,延翠兰承担本起事故的次要责任延某承担本起事故的次要责任。”(截取一段文字),结果为:“法条:刑法第133条、第67条、第72条、第73条;罚金:第一档次[0,1000)”(详情见文书)。初始数据包含200多万份数据,每份数据有一个案件事实描述文本、对应的法条和罚金等级,可以记作为:
corpus=[[text1,legalset1,penalty1],...,[textn,legalsetn,penaltyn]]
其中text为案件事实描述文本,legalset为该文本对应的法条标签,penalty是该文本对应的罚金等级,n是数据的数量。
i)首先对每一份数据的案件事实描述文本进行分词,实现:
其中,texti是第i份案件事实描述文本,wij是第i案件事实描述文本分词得到的第j个词,ni是第i案件事实描述文本分词得到的得到的词语总数。
比如对上述文书中的一句“与延翠兰驾驶的电动自行车发生交通事故与延某驾驶的电动自行车发生交通事故,造成车辆损坏,延翠兰经医院抢救无效死亡延某经医院抢救无效死亡”经分词后得到[与/p延翠兰/nr驾驶/v的/uj电动/n自行车/n发生/v交通事故/n与/p延某/nr驾驶/v的/uj电动/n自行车/n发生/v交通事故/n造成/v车辆/n损坏/v延翠兰/nr医院/n抢救无效/l死亡/v延某/nr医院/n抢救无效/l死亡/v]。
ii)然后去停用词,对i)中例句分词后,去除没有具体语义的词‘的’、‘,’、‘与’、‘经’后,得到的词语列表为:[延翠兰/nr驾驶/v电动/n自行车/n发生/v交通事故/n延某/nr驾驶/v电动/n自行车/n发生/v交通事故/n造成/v车辆/n损坏/v延翠兰/nr医院/n抢救无效/l死亡/v延某/nr经/n医院/n抢救无效/l死亡/v]。
iii)对ii)中处理得到的词语进行命名实体识别得到人名有延翠兰、延某,用person代替,得到[person/nr驾驶/v电动/n自行车/n发生/v交通事故/nperson/nr驾驶/v电动/n自行车/n发生/v交通事故/n造成/v车辆/n损坏/vperson/nr医院/n抢救无效/l死亡/vperson/nr经/n医院/n抢救无效/l死亡/v],同理识别出组织代以org,识别出时间代以time。
经上述预处理操作,n份文本数据最后可以表示为:
其中wij是第i案件事实描述文本分词得到的第j个词,mi是第i案件事实描述文本分词得到的得到的词语总数,n是初始数据中案件事实描述文本的数量。
b)特征抽取
初始数据在经过预处理模块处理后得到数据如下式所示(即a中式(1)):
其中wij是第i案件事实描述文本分词得到的第j个词,mi是第i案件事实描述文本分词得到的得到的词语总数,n是初始数据中案件事实描述文本的数量。
对每一份数据
例如文本“与延翠兰驾驶的电动自行车发生交通事故与延某驾驶的电动自行车发生交通事故,造成车辆损坏,延翠兰经医院抢救无效死亡延某经医院抢救无效死亡”预处理得到的词语列表为[person/nr驾驶/v电动/n自行车/n发生/v交通事故/nperson/nr驾驶/v电动/n自行车/n发生/v交通事故/n造成/v车辆/n损坏/vperson/nr医院/n抢救无效/l死亡/vperson/nr经/n医院/n抢救无效/l死亡/v],然后使用tf-idf、lda和doc2vec方法分别得到其对应的tf-idf、lda、doc2vec特征向量为:(0.12,0.01,…,0.2)、(0.02,0.03,…,0.05)、(0.12,0.07,…,0.11),合并得到其具有深层语义表示的特征向量为(0.12,0.01,…,0.2,0.02,0.03,…,0.05,0.12,0.07,…,0.11)。
c)法条预测模型和罚金预测模型训练
法条预测模型的使用数据格式示例如下:
[(0.12,0.01,0.2,0,0.03,0.05,…,0.11):[12,23,67],
(0.11,0.02,0,0.08,0.05,0.3,…,0.09):[45,123,124],…](其中()内数据是b)步骤特征抽取最终得到的具有深层语义表示的特征向量,[]内数字是刑法法条的条目)
罚金预测模型所使用的训练数据格式示例如下:
[(0.12,0.01,0.2,0,0.03,0.05,…,0.11):1,
(0.11,0.02,0,0.08,0.05,0.3,…,0.09):2,…](:后数字是罚金的档次结果)
模型训练过程不断学习输入数据,使得在给出上述训练数据的输入,模型尽可能得到对应结果,
这样在后续预测时相似的文书会得到相似的特征向量,模型也就能预测到较为合理的结果。
模型训练完成后可以得到法条预测模型和罚金预测模型,保存下来用于后续对未知数据进行预测。
2:使用模型进行预测
输入任意给定一份案件事实描述文本,如“被告人谭伏求驾驶湘akf291轻型普通货车沿本市天心区新韶路由东往西行驶至新姚路口准备左转弯时,恰遇行人江某某在此横过道路,由于被告人谭伏求驾驶车辆忽视安全,注意不够,且转弯时超速行驶,遇行人通过人行横道时,未减速停车让行,加之被害人江某某未按信号灯指示通行,导致被告人谭伏求所驾车辆左前部与被害人江某某相撞,造成车辆受损、被害人江某某受伤后经医院抢救无效死亡的重大交通事故”,经预处理模块和特征提取模块得到具有深层语义表示的特征向量(f1,f2,...,fn)。输入到训练好的模型,法条预测模型输出结果为相关法条为:刑法第133条:“违反交通运输管理法规,因而发生重大事故,致人重伤、死亡或者使公私财产遭受重大损失的,处三年以下有期徒刑或者拘役;交通运输肇事后逃逸或者有其他特别恶劣情节的,处三年以上七年以下有期徒刑;因逃逸致人死亡的,处七年以上有期徒刑”;刑法第73条:“【考验期限】拘役的缓刑考验期限为原判刑期以上一年以下,但是不能少于二个月。有期徒刑的缓刑考验期限为原判刑期以上五年以下,但是不能少于一年。缓刑考验期限,从判决确定之日起计算。”罚金预测模型预测罚金为:第一档[0,1000)。
上述实施例仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和等同替换,这些对本发明权利要求进行改进和等同替换后的技术方案,均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!