一种出车途中人车分离判断方法及装置与流程
本发明涉及轨迹数据处理领域,尤其涉及一种出车途中人车分离判断方法及装置。
背景技术:
在地理信息管理系统应用中,经常需要监控车辆和司机的行为,从而得知司机是否有不规范的操作。例如,物流运输等行业中,需要司机在运送过程中按规范操作,不能出现司机和汽车上时间分离的情况,防止造成物品丢失,损坏客户利益。现有技术中,可通过对司机和汽车两者移动的曲线轨迹进行比较,判断两者是否相似,从而确认司机在出车途中是否有长时间与汽车分离,例如:lcss,dtw,frechetdistance,onewaydistance,lipdistance等,均可用于判断两条曲线轨迹是否相似。但是,上述提到的方法中,如lcss,dtw,frechetdistance等,其需要对数据点与数据点之间的距离计算,最终得出一个无量纲的数值结果,其算法计算复杂度较高;而如onewaydistance,lipdistance等,其需要以分段形式收集轨迹数据,但现在的轨迹数据基本上都是以点的形式收集,导致需要进行一次数据转换,效率太低。
技术实现要素:
本发明提供了一种出车途中人车分离判断方法及装置,以解决现有技术中判断出车途中是否发生人车分离的方法存在计算复杂度高,效率低的问题。
为了解决上述问题,本发明提供了一种出车途中人车分离判断方法,其包括:获取司机定位装置采集的多个司机轨迹点并存储至目标轨迹点集;获取汽车定位装置采集的多个汽车轨迹点并存储至所述目标轨迹点集;采用密度聚类算法对所述目标轨迹点集进行聚类处理,得到所述目标轨迹点集的至少一个目标聚类簇;判断所述目标聚类簇的数目是否大于一;若所述目标聚类簇的数目大于一,则确定与所述目标轨迹点集对应的区域发生了人车分离。
作为本发明的进一步改进,所述获取司机定位装置采集的多个司机轨迹点并存储至目标轨迹点集的步骤之后,还包括:采用所述密度聚类算法对所述多个司机轨迹点进行聚类处理,得到所述多个司机轨迹点的至少一个司机聚类簇;判断所述司机聚类簇的数目是否大于一;若所述司机聚类簇的数目大于一,则获取每一个司机聚类簇对应的司机轨迹点的个数,并确定司机正常聚类簇,所述司机正常聚类簇为对应司机轨迹点个数最多的司机聚类簇;保留所述司机正常聚类簇对应的司机轨迹点,且删除其他司机聚类簇对应的司机轨迹点。
作为本发明的进一步改进,所述获取汽车定位装置采集的多个汽车轨迹点并存储至所述目标轨迹点集的步骤之后,还包括:;采用所述密度聚类算法对所述多个汽车轨迹点进行聚类处理,得到所述多个汽车轨迹点的至少一个汽车聚类簇;判断所述汽车聚类簇的数目是否大于一;若所述汽车聚类簇的数目大于一,则获取每一个汽车聚类簇对应的汽车轨迹点的个数,并确定汽车正常聚类簇,所述汽车正常聚类簇为对应汽车轨迹点个数最多的汽车聚类簇;保留所述汽车正常聚类簇对应的汽车轨迹点,且删除其他汽车聚类簇对应的汽车轨迹点。
作为本发明的进一步改进,所述确定与所述目标轨迹点集对应的区域发生了人车分离的步骤之后,还包括:获取每一个目标聚类簇对应的目标轨迹点的个数;根据所述每一个目标聚类簇对应的目标轨迹点的个数确定主聚类簇和至少一个从聚类簇,所述主聚类簇为对应目标轨迹点个数最多的目标聚类簇;确定每一个从聚类簇对应的多个分离轨迹点,所述分离轨迹点对应的区域即发生人车分离的区域。
为了解决上述问题,本发明还提供了一种出车途中人车分离判断装置,其包括:第一获取模块,用于获取司机定位装置采集的多个司机轨迹点并存储至目标轨迹点集;第二获取模块,用于获取汽车定位装置采集的多个汽车轨迹点并存储至所述目标轨迹点集;第一聚类模块,用于采用密度聚类算法对所述目标轨迹点集进行聚类处理,得到所述目标轨迹点集的至少一个目标聚类簇;第一判断模块,用于判断所述目标聚类簇的数目是否大于一;第一确定模块,用于若所述目标聚类簇的数目大于一,则确定与所述目标轨迹点集对应的区域发生了人车分离。
作为本发明的进一步改进,其还包括:第二聚类模块,用于采用所述密度聚类算法对所述多个司机轨迹点进行聚类处理,得到每一个所述多个司机轨迹点的至少一个司机聚类簇;第二判断模块,用于判断所述司机聚类簇的数目是否大于一;第三获取模块,用于若所述司机聚类簇的数目大于一,则获取每一个司机聚类簇对应的司机轨迹点的个数,并确定司机正常聚类簇,所述司机正常聚类簇为对应司机轨迹点个数最多的司机聚类簇;第一删除模块,用于保留所述司机正常聚类簇对应的司机轨迹点,且删除其他司机聚类簇对应的司机轨迹点。
作为本发明的进一步改进,其还包括:第三聚类模块,用于采用所述密度聚类算法对所述多个汽车轨迹点进行聚类处理,得到所述多个汽车轨迹点的至少一个汽车聚类簇;第三判断模块,用于判断所述汽车聚类簇的数目是否大于一;第四获取模块,用于若所述汽车聚类簇的数目大于一,则获取每一个汽车聚类簇对应的汽车轨迹点的个数,并确定汽车正常聚类簇,所述汽车正常聚类簇为对应汽车轨迹点个数最多的汽车聚类簇;第二删除模块,用于保留所述汽车正常聚类簇对应的汽车轨迹点,且删除其他汽车聚类簇对应的汽车轨迹点。
作为本发明的进一步改进,其还包括:第五获取模块,用于获取每一个目标聚类簇对应的目标轨迹点的个数;第二确定模块,用于根据所述每一个目标聚类簇对应的目标轨迹点的个数确定主聚类簇和至少一个从聚类簇,所述主聚类簇为对应目标轨迹点个数最多的目标聚类簇;第三确定模块,用于确定每一个从聚类簇对应的多个分离轨迹点,所述分离轨迹点对应的区域即发生人车分离的区域。
相比于现有技术,本发明通过采用密度聚类算法对多个司机轨迹点和多个汽车轨迹点进行聚类处理,从而得到多个司机轨迹点和多个汽车轨迹点的至少一个目标聚类簇,并通过判断目标聚类簇的数目确认多个司机轨迹点和多个汽车轨迹点中是否存在“异常点”,当目标聚类簇的数目大于一时,说明存在“异常点”,即可确认在出车途中存在人车分离的行为,本发明提供的方法不需要对轨迹数据进行转换,仅需采用密度聚类算法对轨迹点进行聚类处理,其算法复杂度低,效率更高。
附图说明
图1为本发明出车途中人车分离判断方法第一个实施例的流程示意图;
图2为本发明出车途中人车分离判断方法第二个实施例的流程示意图;
图3为本发明出车途中人车分离判断方法第三个实施例的流程示意图;
图4为本发明出车途中人车分离判断方法第四个实施例的流程示意图;
图5为本发明出车途中人车分离判断方法第五个实施例的流程示意图;
图6为本发明出车途中人车分离判断装置第一个实施例的功能模块示意图;
图7为本发明出车途中人车分离判断装置第二个实施例的功能模块示意图;
图8为本发明出车途中人车分离判断装置第三个实施例的功能模块示意图;
图9为本发明出车途中人车分离判断装置第四个实施例的功能模块示意图
图10为本发明出车途中人车分离判断装置第五个实施例的功能模块示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用来限定本发明。
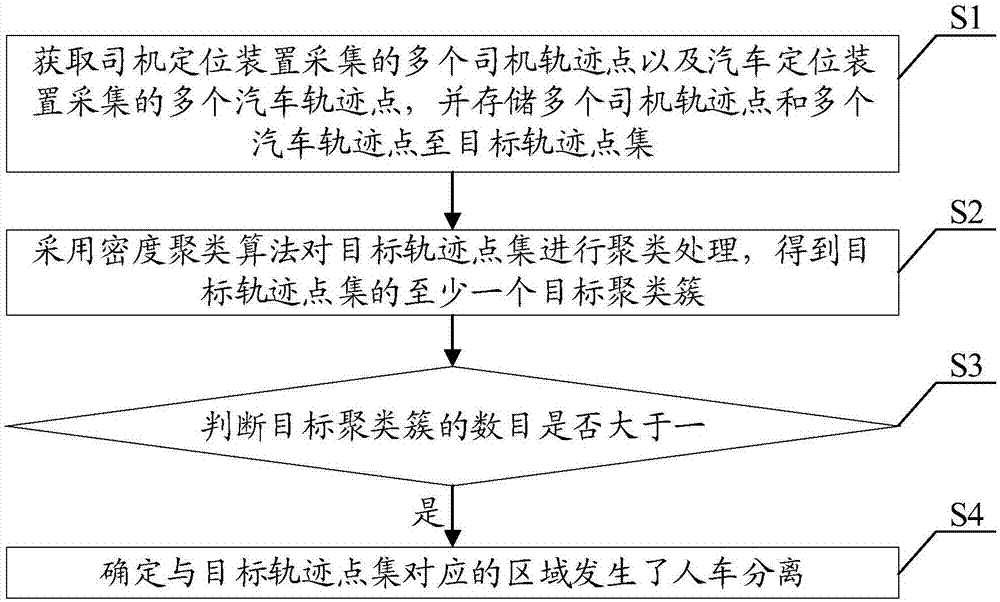
图1展示了本发明出车途中人车分离判断方法的一个实施例。在本实施例中,如图1所示,该出车途中人车分离判断方法包括:
步骤s1,获取司机定位装置采集的多个司机轨迹点以及汽车定位装置采集的多个汽车轨迹点,并存储多个司机轨迹点和多个汽车轨迹点至目标轨迹点集。
需要说明的是,该司机定位装置为移动终端内置gps定位仪,例如手机内置gps定位仪,该汽车定位装置为汽车gps定位仪。
具体地,在行车过程中,通过司机定位装置每间隔预设时间段即采集一次司机的当前位置数据,从而得到多个司机轨迹点,并将该多个司机轨迹点存储至目标轨迹点集中,同时,还通过汽车定位装置每间隔同一预设时间段即采集一次汽车的当前位置数据,从而得到多个汽车轨迹点,并将该多个汽车轨迹点也存储至目标轨迹点集中,从而,该目标轨迹点集中包括多个司机轨迹点和多个汽车轨迹点。
步骤s2,采用密度聚类算法对目标轨迹点集进行聚类处理,得到目标轨迹点集的至少一个目标聚类簇。
需要说明的是,密度聚类算法可以通过分析样本分布的紧密程度来对样本进行类别划分,同一类别的样本,它们之间是紧密相连的,也就是说,在该类别任意样本周围一定范围内存在同类别的样本。通过将紧密相连的样本划为一类,这样就得到了一个聚类类别。通过将所有各组紧密相连的样本划为各个不同的类别,则我们就得到了最终的所有聚类类别结果,即得到样本数据划分的簇,以及簇的数目。例如,设样本集是d=(x1,x2,...,xm),则密度聚类算法具体的密度描述定义如下:
(1)∈-邻域:对于xj∈d,其∈-邻域包含样本集d中与xj的距离(欧氏距离)不大于∈的子样本集,即n∈(xj)={xi∈d|distance(xi,xj)≤∈},这个子样本集的个数记为|n∈(xj)|;
(2)核心对象:对于任一样本xj∈d,如果其∈-邻域对应的n∈(xj)至少包含minpts个样本,即如果|n∈(xj)|≥minpts,则xj是核心对象。
(3)密度直达:如果xi位于xj的∈-邻域中,且xj是核心对象,则称xi由xj密度直达。注意反之不一定成立,即此时不能说xj由xi密度直达,除非且xi也是核心对象。
(4)密度可达:对于xi和xj,如果存在样本样本序列p1,p2,...,pt,满足p1=xi,pt=xj,且pt+1由pt密度直达,则称xj由xi密度可达。也就是说,密度可达满足传递性。此时序列中的传递样本p1,p2,...,pt-1均为核心对象,因为只有核心对象才能使其他样本密度直达。注意密度可达也不满足对称性,这个可以由密度直达的不对称性得出。
(5)密度相连:对于xi和xj,如果存在核心对象样本xk,使xi和xj均由xk密度可达,则称xi和xj密度相连。注意密度相连关系是满足对称性的。
根据上述定义,可以获知密度聚类算法的具体流程:
输入:样本集d=(x1,x2,...,xm),邻域参数(∈,minpts),样本距离度量方式(欧氏距离);
输出:簇划分c。
(1)初始化核心对象集合
(2)对于j=1,2,...m,按下面的步骤找出所有的核心对象:
a)通过距离度量方式,找到样本xj的∈-邻域子样本集n∈(xj);
b)如果子样本集样本个数满足|n∈(xj)|≥minpts|,将样本xj加入核心对象样本集合:ω=ω∪{xj}。
(3)如果核心对象集合
(4)在核心对象集合ω中,随机选择一个核心对象o,初始化当前簇核心对象队列ωcur={o},初始化类别序号k=k+1,初始化当前簇样本集合ck={o},更新未访问样本集合γ=γ-{o}。
(5)如果当前簇核心对象队列
(6)在当前簇核心对象队列ωcur中取出一个核心对象o′,通过邻域距离阈值∈找出所有的∈-邻域子样本集n∈(o′),令δ=n∈(o′)∩γ,更新当前簇样本集合ck=ck∪δ,更新未访问样本集合γ=γ-δ,更新ωcur=ωcur∪(n∈(o′)∩ω),转入步骤(5)。
输出结果为:簇划分c={c1,c2,...,ck}。
具体地,本实施例中,确认该目标轨迹点集包括的所有目标轨迹点,并将所有目标轨迹点作为样本输入至密度聚类算法中进行聚类处理,即可得到该目标轨迹点集的目标聚类簇以及其数目。
步骤s3,判断目标聚类簇的数目是否大于一。若目标聚类簇的数目大于一,则执行步骤s4。
具体地,根据上述该密度聚类算法可知,若行车过程中,司机和汽车未分离,则采集的两者的轨迹点之间的距离较近,是紧密相连的轨迹点,此时得到一个目标聚类簇,而若司机和汽车发生了长时间的人车分离,则此时司机和汽车之间的距离拉大,使得司机轨迹点和汽车轨迹点之间的距离增大,导致两者不是紧密相连的,此时得到至少两个目标聚类簇。本实施例中,判断该目标轨迹点集的目标聚类簇的数目是否大于一,若目标轨迹点集的目标聚类簇的数目大于一,则说明目标轨迹点集中存在至少两组紧密相连的目标轨迹点,执行步骤s4。
步骤s4,确定与目标轨迹点集对应的区域发生了人车分离。
具体地,若目标轨迹点集的目标聚类簇的数目大于一,即该目标轨迹点集包括有两个以上的目标聚类簇,即目标轨迹点集中存在至少两组紧密相连的目标轨迹点,说明司机和汽车在目标轨迹点集对应的区域发生了人车分离。
进一步的,本实施例中,在行车过程中,因为信号丢失或其他原因会导致司机定位装置和汽车定位装置采集的轨迹点出现不连续的情况,而为了降低计算量,提高计算效率,在获取目标轨迹点集之后,获取目标轨迹点集中相邻两个目标轨迹点之间的距离值,并判断距离值是否小于预设距离阈值。具体地,目标轨迹点包括有经纬度信息,通过经纬度信息即可计算得到相邻两个目标轨迹点之间的距离值。当距离值小于预设距离阈值时,即认为此相邻两个目标轨迹点之间连续,则划分与距离值关联的两个目标轨迹点至同一个目标连续点集,从而将目标轨迹点集中的目标轨迹点划分为至少一个目标连续点集,再采用密度聚类算法分别对每一个目标连续点集进行聚类处理,根据聚类结果判断任一目标连续点集的目标轨迹点对应的区域是否发生人车分离。通过将目标轨迹点集拆分为多个至少一个目标连续点集分别进行聚类处理,降低每一次的计算量,提高了计算效率。
本实施例通过采用密度聚类算法对多个司机轨迹点和多个汽车轨迹点进行聚类处理,从而得到多个司机轨迹点和多个汽车轨迹点的至少一个目标聚类簇,并通过判断目标聚类簇的数目确认多个司机轨迹点和多个汽车轨迹点中是否存在“异常点”,当目标聚类簇的数目大于一时,说明存在“异常点”,即可确认在出车途中存在人车分离的行为,本发明提供的方法不需要对轨迹数据进行转换,仅需采用密度聚类算法对轨迹点进行聚类处理,其算法复杂度较低,效率更高。
图2展示了本发明出车途中人车分离判断方法的第二个实施例。如图2所示,本实施例中,该出车途中人车分离判断方法包括:
步骤s10,获取司机定位装置采集的多个司机轨迹点以及汽车定位装置采集的多个汽车轨迹点,并存储多个司机轨迹点和多个汽车轨迹点至目标轨迹点集。
该步骤与步骤s1类似,具体可参照步骤s1的描述,在此不再赘述。
步骤s11,分别处理多个司机轨迹点和多个汽车轨迹点,并根据处理结果确认异常轨迹点,并删除异常轨迹点。
具体地,在获取到多个司机轨迹点和多个汽车轨迹点之后,通过对多个司机轨迹点和多个汽车轨迹点进行处理,并根据处理结果确认多个司机轨迹点和多个汽车轨迹点中的异常轨迹点,再删除异常轨迹点。
本实施例中,可通过采用密度聚类算法分别对多个司机轨迹点和多个汽车轨迹点进行聚类处理,并得到聚类处理的结果,根据聚类处理的结果确认多个司机轨迹点和多个汽车轨迹点中的异常轨迹点。
需要说明的是,本实施例中的异常轨迹点是指因为司机定位装置或汽车定位装置信号波动而采集的与真实位置偏差过大的司机轨迹点或汽车轨迹点,或者是因其他外因而采集的误差过大的司机轨迹点或汽车轨迹点。
步骤s12,采用密度聚类算法对目标轨迹点集进行聚类处理,得到目标轨迹点集的至少一个目标聚类簇。
该步骤与步骤s2类似,具体可参照步骤s2的描述,在此不再赘述。
步骤s13,判断目标聚类簇的数目是否大于一。若目标聚类簇的数目大于一,则执行步骤s14。
该步骤与步骤s3类似,具体可参照步骤s3的描述,在此不再赘述。
步骤s14,确定与目标轨迹点集对应的区域发生了人车分离。
该步骤与步骤s4类似,具体可参照步骤s4的描述,在此不再赘述。
本实施例通过对多个司机轨迹点和多个汽车轨迹点进行处理,并根据处理结果分别确认多个司机轨迹点和多个汽车轨迹点中的异常轨迹点,再删除异常轨迹点,从而提高获取的多个司机轨迹点和多个汽车轨迹点的数据质量,避免因数据误差影响人车分离的判断结果。
进一步的,上述实施例的基础上,其他实施例中,如图3所示,步骤s11包括如下步骤:
步骤s1100,采用密度聚类算法对多个司机轨迹点进行聚类处理,得到多个司机轨迹点的至少一个司机聚类簇。
具体地,当多个司机轨迹点中存在异常轨迹点时,根据上述实施例中所述的密度聚类算法对多个司机轨迹点进行聚类处理,即可确定多个司机轨迹点包括至少两个司机聚类簇,其中,正常轨迹点分属于一个聚类簇,异常轨迹点分属于另外的聚类簇。
步骤s1101,判断司机聚类簇的数目是否大于一。若司机聚类簇的数目大于一,则执行步骤s1102。
具体地,当多个司机轨迹点中存在异常轨迹点时,根据密度聚类算法进行聚类处理后,得到至少两个聚类簇,因此,通过判断多个司机轨迹点的司机聚类簇的数目是否大于一即可确认该多个司机轨迹点中是否存在异常轨迹点。
步骤s1102,获取每一个司机聚类簇对应的司机轨迹点的个数,并确定司机正常聚类簇。
需要说明的是,司机正常聚类簇为对应司机轨迹点个数最多的司机聚类簇。
具体地,若多个司机轨迹点的司机聚类簇的数目大于一,则说明该多个司机轨迹点中存在异常轨迹点,则获取多个司机轨迹点的每一个司机聚类簇对应的司机轨迹点的个数,其中对应司机轨迹点个数最多的司机聚类簇即为司机正常聚类簇,其对应的司机轨迹点均为正常轨迹点,而其余司机聚类簇对应的司机轨迹点即为异常轨迹点。
步骤s1103,保留司机正常聚类簇对应的司机轨迹点,且删除其他司机聚类簇对应的司机轨迹点。
具体地,删除异常轨迹点,完成对多个司机轨迹点的清洗。
本实施例通过采用密度聚类算法对多个司机轨迹点进行聚类处理,根据聚类处理得到的司机聚类簇的数目判断多个司机轨迹点中是否存在异常轨迹点,若存在异常轨迹点,则通过确定每一个司机聚类簇对应的司机轨迹点的个数,从而确认正常司机聚类簇,并删除正常司机聚类簇外,其余司机聚类簇对应的司机轨迹点,从而达到了对司机轨迹点进行清洗的目的,提高司机轨迹点的数据的质量,提高最终判断人车分离的结果的准确性。
进一步的,上述实施例的基础上,其他实施例中,如图4所示,步骤s11还包括如下步骤:
步骤s1110,采用密度聚类算法对多个汽车轨迹点进行聚类处理,得到多个汽车轨迹点的至少一个汽车聚类簇。
具体地,当多个汽车轨迹点中存在异常轨迹点时,根据上述实施例中所述的密度聚类算法对多个汽车轨迹点进行聚类处理,即可确定多个汽车轨迹点包括至少两个汽车聚类簇,其中,正常轨迹点分属于一个聚类簇,异常轨迹点分属于另外的聚类簇。
需要说明的是,此处所述异常轨迹点主要是指因为汽车定位装置信号波动而采集的与真实位置偏差过大的汽车轨迹点,或者是因其他外因而采集的误差过大的汽车轨迹点。
步骤s1111,判断汽车聚类簇的数目是否大于一。若汽车聚类簇的数目大于一,则执行步骤s1112。
具体地,当多个汽车轨迹点中存在异常轨迹点时,根据密度聚类算法进行聚类处理后,得到至少两个聚类簇,因此,通过判断多个汽车轨迹点的汽车聚类簇的数目是否大于一即可确认该多个汽车轨迹点中是否存在异常轨迹点。
步骤s1112,获取每一个汽车聚类簇对应的汽车轨迹点的个数,并确定汽车正常聚类簇。
需要说明的是,汽车正常聚类簇为对应汽车轨迹点个数最多的汽车聚类簇。
具体地,若多个汽车轨迹点的汽车聚类簇的数目大于一,则说明该多个汽车轨迹点中存在异常轨迹点,则获取多个汽车轨迹点的每一个汽车聚类簇对应的汽车轨迹点的个数,其中对应汽车轨迹点个数最多的汽车聚类簇即为汽车正常聚类簇,其对应的汽车轨迹点均为正常轨迹点,而其余汽车聚类簇对应的汽车轨迹点即为异常轨迹点。
步骤s1113,保留汽车正常聚类簇对应的汽车轨迹点,且删除其他汽车聚类簇对应的汽车轨迹点。
具体地,删除异常轨迹点,完成对多个汽车轨迹点的清洗。
本实施例通过采用密度聚类算法对多个汽车轨迹点进行聚类处理,根据聚类处理得到的汽车聚类簇的数目判断多个汽车轨迹点中是否存在异常轨迹点,若存在异常轨迹点,则通过确定每一个汽车聚类簇对应的汽车轨迹点的个数,从而确认正常汽车聚类簇,并删除正常汽车聚类簇外,其余汽车聚类簇对应的汽车轨迹点,从而达到了对汽车轨迹点进行清洗的目的,提高汽车轨迹点的数据的质量,提高最终判断人车分离的结果的准确性。
图5展示了本发明出车途中人车分离判断方法的第五个实施例。如图5所示,本实施例中,该出车途中人车分离判断方法包括:
步骤s20,获取司机定位装置采集的多个司机轨迹点以及汽车定位装置采集的多个汽车轨迹点,并存储多个司机轨迹点和多个汽车轨迹点至目标轨迹点集。
该步骤与步骤s1类似,具体可参照步骤s1的描述,在此不再赘述。
步骤s21,采用密度聚类算法对目标轨迹点集进行聚类处理,得到目标轨迹点集的至少一个目标聚类簇。
该步骤与步骤s2类似,具体可参照步骤s2的描述,在此不再赘述。
步骤s22,判断目标聚类簇的数目是否大于一。若目标聚类簇的数目大于一,则执行步骤s23。
该步骤与步骤s3类似,具体可参照步骤s3的描述,在此不再赘述。
步骤s23,确定与目标轨迹点集对应的区域发生了人车分离。
该步骤与步骤s4类似,具体可参照步骤s4的描述,在此不再赘述。
步骤s24,获取每一个目标聚类簇对应的目标轨迹点的个数。
步骤s25,根据每一个目标聚类簇对应的目标轨迹点的个数确定主聚类簇和至少一个从聚类簇。
需要说明的是,主聚类簇为对应目标轨迹点个数最多的目标聚类簇,从聚类簇为对应目标轨迹点个数少于主聚类簇的目标聚类簇。
步骤s26,确定每一个从聚类簇对应的多个分离轨迹点,分离轨迹点对应的区域即发生人车分离的区域。
具体地,在目标轨迹点集对应的区域中可能发生了多次人车分离的事件,因此,可得到至少一个从聚类簇,根据从聚类簇即可确认分离轨迹点,分离轨迹点对应的区域即为人车分离的发生区域,从而确认人车分离的具体地点
本实施例在确认目标轨迹点集对应的区域发生了人车分离之后,通过获取该目标轨迹点集的每一个目标聚类簇对应的目标轨迹点的个数,从而确认其中发生了人车分离的目标聚类簇,即从聚类簇,然后根据从聚类簇即可确认分离轨迹点,从而根据分离轨迹点确认人车分离发生的区域,其进一步方便了解到司机在发生人车分离的地点,进一步方便判断司机的操作是否符合规则。
图6展示了本发明出车途中人车分离判断装置的一个实施例。在本实施例中,如图6所示,该出车途中人车分离判断装置包括第一获取模块10、第二获取模块11、第一聚类模块12、第一判断模块13和第一确定模块14。
其中,第一获取模块10,用于获取司机定位装置采集的多个司机轨迹点并存储至目标轨迹点集;第二获取模块11,用于获取汽车定位装置采集的多个汽车轨迹点并存储至目标轨迹点集;第一聚类模块12,用于采用密度聚类算法对目标轨迹点集进行聚类处理,得到目标轨迹点集的至少一个目标聚类簇;第一判断模块13,用于判断目标聚类簇的数目是否大于一;第一确定模块14,用于若目标聚类簇的数目大于一,则确定与目标轨迹点集对应的区域发生了人车分离。
上述实施例的基础上,其他实施例中,如图7所示,该出车途中人车分离判断装置还包括清除模块20。其中,清除模块20,用于分别处理多个司机轨迹点和多个汽车轨迹点,并根据处理结果确认异常轨迹点,并删除异常轨迹点。
上述实施例的基础上,其他实施例中,如图8所示,该清除模块20包括第二聚类模块2000、第二判断模块2001、第三获取模块2002和第一删除模块2003。
其中,第二聚类模块2000,用于采用密度聚类算法对多个司机轨迹点进行聚类处理,得到每一个多个司机轨迹点的至少一个司机聚类簇;第二判断模块2001,用于判断司机聚类簇的数目是否大于一;第三获取模块2002,用于若司机聚类簇的数目大于一,则获取每一个司机聚类簇对应的司机轨迹点的个数,并确定司机正常聚类簇,司机正常聚类簇为对应司机轨迹点个数最多的司机聚类簇;第一删除模块2003,用于保留司机正常聚类簇对应的司机轨迹点,且删除其他司机聚类簇对应的司机轨迹点。
上述实施例的基础上,其他实施例中,如图9所示,该清除模块20还包括第三聚类模块2010、第三判断模块2011、第四获取模块2012和第二删除模块2013。
其中,第三聚类模块2010,用于采用密度聚类算法对多个汽车轨迹点进行聚类处理,得到多个汽车轨迹点的至少一个汽车聚类簇;第三判断模块2011,用于判断汽车聚类簇的数目是否大于一;第四获取模块2012,用于若汽车聚类簇的数目大于一,则获取每一个汽车聚类簇对应的汽车轨迹点的个数,并确定汽车正常聚类簇,汽车正常聚类簇为对应汽车轨迹点个数最多的汽车聚类簇;第二删除模块2013,用于保留汽车正常聚类簇对应的汽车轨迹点,且删除其他汽车聚类簇对应的汽车轨迹点。
上述实施例的基础上,其他实施例中,如图10所示,该出车途中人车分离判断装置还包括第五获取模块30、第二确定模块31和第三确定模块32。
其中,第五获取模块30,用于获取每一个目标聚类簇对应的目标轨迹点的个数;第二确定模块31,用于根据每一个目标聚类簇对应的目标轨迹点的个数确定主聚类簇和至少一个从聚类簇,主聚类簇为对应目标轨迹点个数最多的目标聚类簇;第三确定模块32,用于确定每一个从聚类簇对应的多个分离轨迹点,分离轨迹点对应的区域即发生人车分离的区域。
关于上述五个实施例出车途中人车分离判断装置中各模块实现技术方案的其他细节,可参见上述实施例中的出车途中人车分离判断方法中的描述,此处不再赘述。
需要说明的是,本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。对于装置类实施例而言,由于其与方法实施例基本相似,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
以上对发明的具体实施方式进行了详细说明,但其只作为范例,本发明并不限制于以上描述的具体实施方式。对于本领域的技术人员而言,任何对该发明进行的等同修改或替代也都在本发明的范畴之中,因此,在不脱离本发明的精神和原则范围下所作的均等变换和修改、改进等,都应涵盖在本发明的范围内。
- 还没有人留言评论。精彩留言会获得点赞!