一种非结构化数据中的特定实体关系的提取方法与流程
本发明涉及一种在非结构化数据中提取特定实体关系的方法,属于数据处理
技术领域:
。
背景技术:
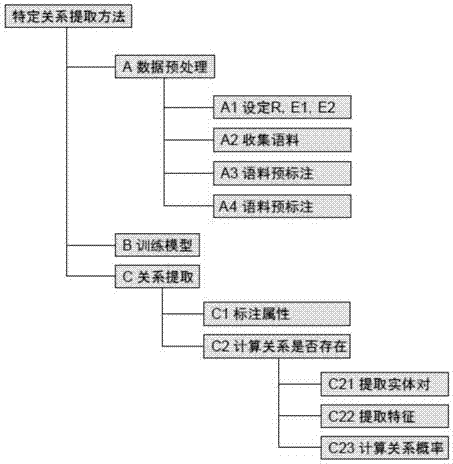
:随着信息技术的发展和互联网的普及,人、机构、事件等实体之间的关系以及实体及其诸如电话、地址等属性之间的关系变得越来越紧密和复杂,如何从海量的非结构化数据中快速准确地提取实体之间的某些关系,对于构建实体之间的关系网络,挖掘实体的关系强度与类型,研究实体之间的联系都有着重要的意义。目前,从非结构化数据中提取实体之间关系的方法主要有监督的学习方法、半监督的学习方法和无监督的学习方法等三种。有监督的学习方法需要专家手工在文本中标记出包含特定关系的实体及其关系,然后根据实体所在文本拥有的特征,将关系提取当作分类问题,使用诸如支持向量机、逻辑回归、深度学习等方法进行分类。该方法存在的缺点是需要大量的语料及人工标注。半监督的学习方法首先使用人工生成若干种子实例,然后在语料中通过查询种子实例来抽取该关系对应的模板,再使用该模板匹配更多的实例,这样迭代地对模板进行优化和补充,以抽取更多的实例。该方法的缺点是准确度不如有监督的学习方法,而且需要一定的人工参与。无监督的学习方法根据实体对的上下文进行聚类,将拥有某种特定关系的实体对聚为一类。该方法的缺点是准确性较差并且不能确定关系类型。总之,现有的方法或者提取准确度低,或者计算复杂度高、人工标注的工作量大,因此有必要加以改进。技术实现要素:本发明的目的在于针对现有技术之弊端,提供一种非结构化数据中的特定实体关系的提取方法,以提高实体关系提取的准确度,降低计算复杂度和人工标注的工作量。本发明所述问题是以下述技术方案实现的:一种非结构化数据中的特定实体关系的提取方法,所述方法首先限定实体关系类型,然后从语料文本中筛选出仅包含该关系类型的语料,并只对一定大小的特征窗口中的语料进行特征识别、组合和提取,同时对实体对进行关系标记,得到实体对的上下文特征以及实体对所包含关系的标记,之后对该标记数据进行学习,得到判断模型,并通过模型准确度的计算,将特征窗口的大小调整到最优,最后利用判断模型从非结构化文本中提取某一特定类型关系的实体对。上述非结构化数据中的特定实体关系的提取方法,所述方法包括以下步骤:步骤a、数据预处理具体过程为:a1.设定实体对的类型,也即设定实体对中第一实体类型e1和第二实体类型e2;设定实体对中两实体关系类型r;a2.收集语料,从互联网上或文档库中获取若干条文本;a3.语料预标识,首先对每一条语料文本进行句子分割、分词(中文)/词干化(英文),标识每个词在文本中的位置,即每个词在文本中的顺序数,然后对其进行命名实体标注;a4.筛选语料,从语料中筛选出那些同时包含属于第一实体类型e1的实体和属于第二实体类型e2的实体的语料;步骤b、训练基于朴素贝叶斯的关系判断模型具体步骤为:b1.生成训练集和测试集包括2个步骤,具体为:b11.设置训练集占语料的百分比;b12.对筛选出的每条语料随机生成一个位于区间[0,1]中的浮点数,如果该数大于步骤b11中所设定的百分比,将该语料归入测试集,否则归为训练集;b2.关系标识对训练集和测试集中的每一条语料文本用人工进行关系标注,当某个第一实体类型e1的实体和某个第二实体类型e2的实体之间存在实体关系r时,标注它们之间存在实体关系r;b3.拟合实体关系的存在情况与距离之间的关系函数包括4个步骤,具体为:b31.从训练集和测试集的每一条语料文本中提取每一对符合实体对类型的实体对;b32.分别用a和b表示实体对中的两个实体,对步骤b31中得到的每个实体对,使用下式计算两实体之间的距离:d(a,b)=positionb-positiona其中d(a,b)表示实体a和实体b之间的距离,positiona是实体a在语料文本中的位置,positionb是实体b在语料文本中的位置;b33.统计训练集语料中存在实体关系r的实体对之间的距离出现的次数,以及不存在实体关系r的实体对之间的距离出现的次数;b34.设存在实体关系r的实体对之间的距离d与其出现的次数之间的关系可以用下式表示:其中fp(d)为存在实体关系r的实体对之间的距离d与d出现的次数之间的关系函数,wpi为多项式中指数为i的项的参数;m为自然数,一般可设为3;利用b33中得到的存在实体关系r的实体对之间的距离出现的次数和距离,使用最小二乘法进行拟合,得到其参数wp1,…,wpm;设不存在实体关系r的实体对之间的距离出现的次数和距离之间的关系可以用下式表示:其中fn(d)为不存在关系r的实体对之间的距离d与d出现的次数之间的关系函数,wni为多项式中指数为i的项的参数,m为自然数,一般可设为3;利用b33中得到的不存在实体关系r的实体对之间的距离出现的次数和距离,使用最小二乘法进行拟合,得到其参数wn1,…,wnm;b4.生成属性候选集包括3个步骤,具体为:b41.列出所能标注的属性,组成一个属性集s;b42.列出属性集s的所有子集,构成一个属性集s′;b43.列出s′的所有子集,构成一个属性集s″;b5.筛选属性候选集包括3个步骤,具体为:b51.对训练集和测试集中的每一条文本中的每个词标注s里的每个属性;b52.对b43所生成的属性集s″中的每个元素,进行以下5个操作:b521.对训练集中的每个文本语料中的每个实体对,即实体a-实体b,进行以下3个操作:b5211.设置ws和we均为0;b5212.设置该实体对的特征窗口位置为从位置较小的实体的位置减去ws开始到位置较大的实体的位置加上we结束,如果位置较小的实体的位置减去ws小于0,那么特征窗口从0开始,如果位置较大的实体的位置加上we大于文本中最后一个词的位置,那么特征窗口到文本中最后一个词结束,特征窗口中的每个词都是该实体对的特征词;b5213.对特征窗口中的每个词提取子集s″中的所有属性,组成该实体对的每个词的特征;b522.计算实体关系r存在的先验概率p(r)和r不存在的先验概率以及存在关系r时关于特征fi的条件概率p′(fi|r),和不存在r时关于特征fi的条件概率包括3个步骤,具体为:b5221.在训练集中,统计实体a和实体b存在关系r的情况的数量|r|,以及在存在关系r的情况下每个特征f1,…,fn出现的次数|(f1,r)|,…,|(fn,r)|;同时也统计实体a和实体b虽然出现在语料中,但实体a和实体b不存在关系r的情况的数量以及该情况下特征f1,…,fn出现的次数b5222.计算实体a和实体b存在关系r时的先验概率p(r),和实体a和实体b不存在关系r时的先验概率b5223.对所有fi,其中i∈[1,n],计算实体a和实体b存在关系r时的关于特征fi的条件概率p′(fi|r)并保存:对所有fi,其中i∈[1,n],计算实体a和实体b不存在关系r时的关于特征fi的条件概率并保存:b523.对测试集中的每个文本语料c中的每个实体对,即实体a-实体b,使用b5211,b5212,b5213中的方法,提取特征窗口中的每个词的特征fci;b524.计算测试集中的每个文本语料中的每个实体对是否包含实体关系r,包括2个步骤,具体是:b5241.在步骤b5223保存的p′(fi|r)和中查询由步骤b523提取的特征fci,如果特征fci出现在步骤b5223保存的p′(fi|r)的fi中,那么p(fci|r)=p′(fi|r)否则p(fci|r)为所有p′(fi|r)中的最小值即:如果特征fci出现在步骤b5223保存的的fi中,那么否则为所有中的最小值即:b5242.计算语料c中实体a和实体b存在关系r的概率pc(r|x;(a,b)):当pc(r|x;(a,b))的值大于0时,表示实体a和实体b之间存在关系r;b525.计算测试集中的参数f1score:其中tp是在测试集的每个语料中实体a和实体b标记为拥有关系r时,计算得到的pc(r|x;(a,b))大于0的实体对的数量;fp是在测试集的每个语料中实体a和实体b标记为不拥有关系r时,计算得到的pc(r|x;(a,b))大于0的实体对的数量;fn是在测试集的每个语料中实体a和实体b标记为拥有关系r,计算得到的pc(r|x;(a,b))不大于0的实体对的数量;b53.对于属性集s″中的每个子集所对应的参数f1score,保存其中最大的f1score所对应的子集,以及对应的p(r),和所有的p(fi|r),b6.优化特征窗口大小包括5个步骤,具体为:b61.设置特征窗口位置为以实体a的位置和实体b的位置中较小的为初始开始位置ps(包括该位置),较大的为初始结束位置pe(包括该位置),设置初始f1score′为0,设置初始f1score的提高增量xi为区间(0,1)中某一小于设定值的数,设置窗口增量t为0;b62.重复执行下列步骤,直到前后2次的f1score的提高增量δf1小于xi,δf1的计算公式如下:δf1=f1score′-f1scoreb621.特征窗口的开始位置等于初始开始位置减去窗口增量t,即:ps=ps-t对测试集执行步骤b523、步骤b524和步骤b525的操作,得到本次的f1score,计算δf1,如果δf1<xi,转至步骤b63,否则执行b622;b622.更新t、f1score的值:t=t+1f1score=f1score′转至步骤b621;b63.保存窗口开始位置的增量,即ws=t,设置窗口增量t=1;b64.重复执行下列步骤,直到前后2次的f1score的提高增量δf1小于xi:b641.特征窗口的结束位置等于初始结束位置加上窗口增量t,即:ps=ps+t对测试集执行步骤b523、步骤b524和步骤b525的操作,得到本次的f1score,计算δf1,如果δf1<xi,转至步骤b65,否则执行b642;b642.安装步骤b622的方法更新f1score、t的值,转至步骤b641;b65.保存保存窗口结束位置的增量,即we=t;步骤c、关系提取包括2个步骤,具体为:c1.对于要提取关系的文本c,首先按照步骤a3对其进行句子分割、分词(中文)/词干化(英文),标识每个词在文本中的位置以及命名实体,然后标注步骤b53所得到的子集中涉及的每个属性;c2.计算关系r是否存在包括3个步骤,具体为:c21.根据步骤a1所设置的第一实体类型e1和第二实体类型e2,提取文本c中的所有实体对;c22.按照步骤b6得到的ws和we设置特征窗口,并按照b53所得到的子集使用步骤b5212和b5213的方法提取特征;c23.按照步骤b5242的方法计算pc(r|x;(a,b)),当其值大于0时,表示文本c中实体a和实体b之间存在实体关系r。上述非结构化数据中的特定实体关系的提取方法,所述训练集占所筛选语料的百分比设为90%。本发明只对特定关系类型的数据进行提取,并选择最适合该关系提取的特征集和最适合该关系提取的窗口大小。该方法避免了多种关系混合提取时的相互干扰,可提高关系提取的准确度,有效降低计算复杂度和人工标注的工作量。附图说明下面结合附图对本发明作进一步说明。图1是本发明的流程图;图2是训练模型的流程图。文中各符号为:e1:实体类型1e2:实体类型2r:两实体关系类型p(r):实体关系存在的先验概率实体关系不存在的先验概率fi:第i个特征p′(fi|r):实体关系r存在时关于特征fi的条件概率d(a,b):两实体之间的距离positiona:实体a在语料中的位置fp(d):存在关系的实体对之间的距离d与d出现的次数之间的关系函数fn(d):不存在关系的实体对之间的距离d与d出现的次数之间的关系函数pc(r|x;(a,b)):文本c中实体a和实体b存在关系r的概率具体实施方式本发明提出了一种针对特定实体关系提取的方法。其基本思想是首先限定关系类型,然后从语料文本中筛选出仅包含该关系类型的语料,并使用一定大小的特征窗口,只对该窗口中的语料进行特征识别、组合和提取,同时对实体对进行关系标记,得到实体对的上下文特征以及实体对所包含关系的标记,最后对该标记数据进行学习,得到判断模型,并使用不同大小的特征窗口计算模型的准确度,从而得到最优的窗口大小。在对非结构化文本进行特定关系提取时使用该模型即可从中提取某一特定类型关系的实体对。与其他方法相比,本方法可以在不降低提取准确度的情况下显著减少训练所需的数据量和训练时间。该方法包括3个步骤:a、数据预处理;b、训练模型;c、关系提取。具体过程为:步骤a、数据预处理包括4个步骤,具体为:步骤a1、设定实体关系类型r,设定实体对的类型,也即设定第一实体类型e1和第二实体类型e2。步骤a2、收集语料,从互联网上或文档库中获取若干条文本。步骤a3、语料预标识,首先对每一条语料文本进行句子分割、分词(中文)/词干化(英文),标识每个词在文本中的位置,然后对其进行命名实体标注。步骤a4、筛选语料,从语料中筛选出那些同时包含属于第一实体类型e1的实体和属于第二实体类型e2的实体的语料(以下简称语料)。步骤b、训练基于朴素贝叶斯的关系判断模型包括6个步骤,具体为:步骤b1、生成训练集和测试集,包括2个步骤,具体为:步骤b11、设置训练集占语料的百分比,通常可设为90%。步骤b12、对每条语料随机生成一个位于区间[0,1]中的浮点数,如果该数大于b11中所设定的百分比,将该语料归入测试集,否则归为训练集。步骤b2、关系标识对训练集和测试集中的每一条语料文本用人工进行关系标注,当某个第一实体类型e1的实体和某个第二实体类型e2的实体之间存在实体关系r时,标注它们之间存在实体关系r。步骤b3、拟合实体关系的存在情况与距离之间的关系函数包括4个步骤,具体为:步骤b31、从训练集和测试集的每一条语料文本中的提取每一对符合实体对类型的实体对。步骤b32、对步骤b31中得到的每个实体对,计算实体之间的距离:d(a,b)=positionb-positiona其中d表示实体之间的距离,positiona是实体a在语料文本中的位置,positionb是实体b在语料文本中的位置。步骤b33、统计训练集语料中存在关系的实体对之间的距离出现的次数,以及不存在关系的实体对之间的距离出现的次数。步骤b34设存在关系的实体对之间的距离出现的次数和距离之间的关系可以用以下公式表示,其中fp(d)为实体关系r的实体对之间的距离d与d出现的次数之间的关系函数,wpi为多项式中指数为i的项的参数,m一般可设为3。利用b33中得到的存在关系的实体对之间的距离出现的次数和距离,使用最小二乘法进行拟合,得到其参数wp1,…,wpm。设不存在关系的实体对之间的距离出现的次数和距离之间的关系可以用以下公式表示,其中fp(d)为实体关系r的实体对之间的距离d与d出现的次数之间的关系函数,wni为多项式中指数为i的项的参数,m一般可设为3。利用b33中得到的不存在关系的实体对之间的距离出现的次数和距离,使用最小二乘法进行拟合,得到其参数wn1,…,wnm。步骤b4、生成属性候选集,包括3个步骤,具体为:步骤b41、列出所能标注的属性,组成一个属性集s。步骤b42、列出属性集s的所有子集,构成一个属性集s′。步骤b43、列出s′的所有子集,构成一个属性集s″。步骤b5、筛选属性候选集包括3个步骤,具体为:步骤b51、对训练集和测试集中的每一条文本中的每个词标注s里的每个属性。步骤b52、对步骤b43所生成的属性集s″中的每个元素,进行以下5个操作:步骤b521、对训练集中的每个文本语料中的每个实体对,即实体a-实体b,进行以下3个操作:步骤b5211、设置ws和we均为0。步骤b5212、该实体对的特征窗口为从位置较小的实体的位置减去ws开始到位置较大的实体的位置加上we结束(包括开始位置和结束位置,如果位置较小的实体的位置减去ws小于0,那么特征窗口从0开始,如果位置较大的实体的位置加上we大于文本中最后一个词的位置,那么特征窗口到文本中最后一个词结束),特征窗口中的每个词都是该实体对的特征词。步骤b5213、对特征窗口中的每个词提取子集s″中的所有属性,组成该实体对的每个词的特征。步骤b522、计算实体a和实体b存在关系r时的先验概率p(r),和实体a和实体b不存在关系r时的先验概率包括3个步骤,具体为:步骤b5221、在训练集中,统计实体a和实体b存在关系r的情况的数量|r|,以及在存在关系r的情况下每个特征f1,…,fn出现的次数|(f1,r)|,…,|(fn,r)|同时也统计实体a和实体b虽然出现在语料中,但实体a和实体b不存在关系r的情况的数量以及该情况下特征f1,…,fn出现的次数步骤b5222、计算实体a和实体b存在关系r时的p(r),和实体a和实体b不存在关系r时的步骤b5223、对所有fi,即i∈[1,n],计算实体a和实体b存在关系r时的p′(fi|r)并保存。对所有fi,即i∈[1,n],计算实体a和实体b不存在关系r时的并保存。步骤b523、对测试集中的每个文本语料c中的每个实体对,即实体a-实体b,使用步骤b5211,b5212,b5213中的方法,提取特征窗口中的每个词的特征fci。步骤b524、计算测试集中的每个文本语料中的每个实体对是否包含实体关系r,包括2个步骤,具体是:步骤b5241、在步骤b5223保存的p′(fi|r)和中查询由步骤b523提取的特征fci,如果特征fci出现在步骤b5223保存的p′(fi|r)或的fi中,那么p(fci|r)=p′(fi|r)否则p(fci|r)为所有p′(fi|r)中的最小值,为所有中的最小值:步骤b5242、计算语料c中实体a和实体b存在关系r的后验概率pc(r|x;(a,b)),当其值大于0时,表示实体a和实体b之间存在关系r。其中d(a,b)由步骤b32计算得到,fp的参数由步骤b34计算得到,p(r),由步骤b5222计算得到,p(fci|r),由步骤b5241计算得到,fn的参数由步骤b33计算得到。步骤b525、计算测试集中的参数f1score:其中tp是在测试集的每个语料中实体a和实体b标记为拥有关系r,计算得到的pc(r|x;(a,b))大于0的实体对的数量;fp是在测试集的每个语料中实体a和实体b标记为不拥有关系r,计算得到的pc(r|x;(a,b))大于0的实体对的数量;fn是在测试集的每个语料中实体a和实体b标记为拥有关系r,计算得到的pc(r|x;(a,b))不大于0的实体对的数量。步骤b53、经过步骤b52,可以得到属性集s″中的每个子集所对应的参数f1score,保存其中最大的f1score所对应的子集,以及对应的p(r),和所有的p(fi|r),步骤b6、优化特征窗口大小包括5个步骤,具体为:步骤b61、设置特征窗口大小为以实体a的位置和实体b的位置中较小的为初始开始位置ps(包括该位置),较大的为初始结束位置pe(包括该位置),设置初始f1score′为0,设置初始f1score的提高增量xi为区间(0,1)中某一较小的数,如0.001,设置窗口增量t为0。步骤b62、重复执行下列步骤,直到前后2次的f1score的提高增量δf1小于xi,δf1的计算公式如下:δf1=f1score′-f1scoreb621、特征窗口的开始位置等于初始开始位置减去窗口增量t,即:ps=ps-t对测试集执行b523,b524,b525得到本次的f1score,使用b62计算δf1,如果δf1<xi,转至步骤b63,否则执行b622。b622、更新t、f1score的值,转至步骤b621:f1score=f1score′t=t+1b63、保存窗口开始位置的增量,即ws=t,设置窗口增量t=1。b64、重复执行下列步骤,直到前后2次的f1score的提高增量δf1小于xi。b641、特征窗口的结束位置等于初始结束位置加上窗口增量t,即:ps=ps+t对测试集执行b523,b524,b525得到本次的f1score,使用b62计算δf1,如果δf1<xi,转至步骤b65,否则执行b642。b642、更新f1score、t的值,转至步骤b641。b65、保存保存窗口结束位置的增量,即we=t。步骤c、关系提取包括2个步骤,具体为:步骤c1、对于要提取关系的文本c,首先按照步骤a3对其进行句子分割、分词(中文)/词干化(英文),标识每个词在文本中的位置以及命名实体,然后标注步骤b53所得到的子集中涉及的每个属性。步骤c2、计算关系r是否存在包括3个步骤,具体为:步骤c21、根据步骤a1所设置的第一实体类型e1和第二实体类型e2,提取文本c中的所有实体对。步骤c22、按照步骤b6得到的ws和we设置特征窗口,并按照b53所得到的子集使用b5212,b5213提取特征。步骤c23、由步骤b5242计算pc(r|x;(a,b)),其中各参数的计算参见b5242,当其值大于0时,表示文本c中实体a和实体b之间存在步骤a1中设定的实体关系。本发明优点:1.只对特定关系类型进行提取,避免了多种关系混合提取时的相互干扰,可以有效降低计算复杂度和人工标注的工作量;2.灵活使用多种特征并进行组合,从中找到最适合该关系提取的特征集,可以提高准确度以及降低计算复杂度;3.通过调整特征窗口的大小,从中找到最适合该关系提取的窗口大小,可以提高准确度以及降低计算复杂度;4.本方法与具体的关系类型无关,可以扩展到任何实体关系的提取上。下面结合实施例进行说明:步骤a、数据预处理包括4个步骤,具体为:步骤a1、设定实体关系类型r,设定实体对的类型,也即设定第一实体类型e1和第二实体类型e2。例如:设定实体关系类型r为“人物拥有电话”关系,设定实体对的类型为“人物-电话”,也即设定第一实体类型e1为“人物”,第二实体类型e2为“电话”。步骤a2、收集语料,从互联网上或文档库中获取若干条文本。例如:收集到下列2条文本:“北京市海淀区测腾公司张三的电话不是123456,而是223456,李四的电话是323456。”“北京市电信局的服务热线是123456。”步骤a3、语料预标识,首先对每一条语料文本进行句子分割、分词(中文)/词干化(英文),标识每个词在文本中的位置,然后对其进行命名实体标注。例如对句子1:“北京市海淀区测腾公司张三的电话不是123456,而是223456,李四的电话是323456。”进行标注如表1:表1句子1的位置和命名实体标记其中命名实体标记中的“location”表示位置,“o”表示其他,“person”表示人物,“tel”表示电话,下同。对句子2:“北京市电信局的服务热线是123456。”进行标注如表2:表2句子2的位置和命名实体标记位置词命名实体标0北京市location1电信局o2的o3服务o4热线o5是o6123456tel7。o步骤a4、筛选语料,从语料中筛选出那些同时包含属于第一实体类型e1的实体和属于第二实体类型e2的实体的语料(以下简称语料)。例如:对包含下列文本的语料进行筛选:“北京市海淀区测腾公司张三的电话不是123456,而是223456,李四的电话是323456。”“北京市电信局的服务热线是123456。”筛选后保留下列语料(因为其中既包含“人物”实体又包含“电话”实体):“北京市海淀区测腾公司张三的电话不是123456,而是223456,李四的电话是323456。”步骤b、训练基于朴素贝叶斯的关系判断模型包括6个步骤,具体为:步骤b1、生成训练集和测试集包括2个步骤,具体为:步骤b11、设置训练集占语料的百分比,通常可设为90%。例如:设置训练集占语料的百分比为90%,步骤b12、对每条语料随机生成一个位于区间[0,1]中的浮点数,如果该数大于b11中所设定的百分比,将该语料归入测试集,否则归为训练集。例如:对语料“北京市海淀区测腾公司张三的电话不是123456,而是223456,李四的电话是323456。”生成的随机浮点数是0.76,因为其小于90%,所以将语料“北京市海淀区测腾公司张三的电话不是123456,而是223456,李四的电话是323456。”归入训练集。步骤b2、关系标识具体为:对训练集和测试集中的每一条语料文本用人工进行关系标注,当某个第一实体类型e1的实体和某个第二实体类型e2的实体之间存在实体关系r时,标注它们之间存在实体关系r。例如:对“北京市海淀区测腾公司张三的电话不是123456,而是223456,李四的电话是323456。”进行关系标识如表3:表3句子1的关系标记其中第13行“关系”中的4表示该行的词“223456”和第4行的词“张三”是步骤a1所设置的“人物-电话”关系。步骤b3、拟合实体关系的存在情况与距离之间的关系函数具体为:步骤b31、从训练集和测试集的每一条语料文本中的提取每一对符合实体对类型的实体对。例如:如从“北京市海淀区测腾公司张三的电话不是123456,而是223456,李四的电话是323456。”中提取符合”人物-电话“的下列实体对,即命名第一实体类型e1为“person”,和命名第二实体类型e2为“tel”的实体对如表4:表4句子1中提取的实体对实体1实体2张三123456张三223456张三323456李四123456李四223456李四323456步骤b32、对步骤b31中得到的每个实体对,计算实体之间的距离:d(a,b)=positionb-positiona其中d表示实体之间的距离,positiona是实体a在语料文本中的位置,positionb是实体b在语料文本中的位置。例如b31中得到的实体对之间的距离如表5:表5句子1中实体对的距离实体1实体1的位置实体2实体2的位置距离张三412345695张三4223456139张三43234561915李四151234569-6李四1522345613-2李四15323456194步骤b33、统计训练集语料中存在关系的实体对之间的距离出现的次数,以及不存在关系的实体对之间的距离出现的次数。例如:在训练集语料中存在关系的实体对之间的距离出现的次数如表6:表6训练集语料中存在关系的实体对之间的距离出现的次数存在关系的实体对之间的距离存在关系的实体对之间的距离出现的次数-22-1111022145461397在训练集语料中不存在关系的实体对之间的距离出现的次数如表7:表7训练集语料中不存在关系的实体对之间的距离出现的次数不存在关系实体对之间的距离不存在关系实体对之间的距离出现的次数-1022-731-420-12021255614923步骤b34设存在关系的实体对之间的距离出现的次数和距离之间的关系可以用如下公式表示,其中dp(d)为实体关系r的实体对之间的距离d与d出现的次数之间的关系函数,wpi为多项式中指数为i的项的参数,m一般可设为3。利用b33中得到的存在关系的实体对之间的距离出现的次数和距离使用最小二乘法进行拟合,得到其参数wp1,…,wpm。设不存在关系的实体对之间的距离出现的次数和距离之间的关系可以用r如下公式表示,其中fn(d)为不存在关系r的实体对之间的距离d与d出现的次数之间的关系函数,wni为多项式中指数为i的项的参数,m一般可设为3:利用b33中得到的不存在关系的实体对之间的距离出现的次数和距离,使用最小二乘法进行拟合,得到其参数wn1,…,wnm。例如,对步骤b33中的存在关系的实体对之间的距离及其出现的次数进行拟合,得到wp0,wp1,wp2,wp3分别为:10.90,6.68,-0.07,-0.08。对步骤b33中的不存在关系的实体对之间的距离及其出现的次数进行拟合,得到wn0,wn1,wn2,wn3分别为:14.97,-2.40,0.12,0.03。步骤b4、生成属性候选集包括3个步骤,具体为:步骤b41、列出所能标注的属性,组成一个属性集s。例如,对文本中的词可以标注的属性包括该词在句子中的位置、词、该词的词性、以及词的命名实体标识,那么它们组成的属性集s为:{该词在句子中的位置,词,该词的词性,该词的命名实体标识}步骤b42、列出属性集s的所有子集,构成一个属性集s′。例如:步骤b43、列出s′的所有子集,构成一个属性集s″。例如:步骤b5、筛选属性候选集包括3个步骤,具体为:步骤b51、对训练集和测试集中的每一条文本中的每个词标注s里的每个属性。例如:对“北京市海淀区测腾公司张三的电话不是123456,而是223456,李四的电话是323456。”进行属性标注如表8:表8句子1的属性标注步骤b52、对步骤b43所生成的属性集s″中的每个元素,进行以下5个操作:步骤b521、对训练集中的每个文本语料中的每个实体对,即实体a-实体b,进行以下3个操作:步骤b5211、设置ws和we均为0。步骤b5212、该实体对的特征窗口为从位置较小的实体的位置减去ws开始到位置较大的实体的位置加上we结束(包括开始位置和结束位置,如果位置较小的实体的位置减去ws小于0,那么特征窗口从0开始,如果位置较大的实体的位置加上we大于文本中最后一个词的位置,那么特征窗口到文本中最后一个词结束),特征窗口中的每个词都是该实体对的特征词。例如:实体对“张三-123456”的特征窗口所包含的特征词有:“张三”、“的”、“电话”、“不”、“是”、“123456”。实体对“张三-223456”的特征窗口所包含的特征词有:“张三”、“的”、“电话”、“不”、“是”、“123456”、“而”、“是”、“223456”。实体对“李四-123456”的特征窗口所包含的特征词有:“123456”、“,”、“而”、“是”、“223456”、“,”、“李四”。步骤b5213、对特征窗口中的每个词提取子集s″中的所有属性,组成该实体对的每个词的特征。例如:实体对“张三-123456”所包含的特征词有:“张三”、“的”、“电话”、“不”、“是”、“123456”。对对s″的子集{{该词在句子中的位置,该词的词性},{词,该词的词性}}提取的每个词的特征有:{4,nr},{"张三",nr},{5,ude1},{"的",ude1},{6,nr},{"电话",nr},{7,d},{"不",d},{8,vshi},{"是",vshi},{9,n},{"123456",n},步骤b522、计算实体a和实体b存在关系r时的先验概率p(r),和实体a和实体b不存在关系r时的先验概率包括3个步骤,具体为:步骤b5221、在训练集中,统计实体a和实体b存在关系r的情况的数量|r|,以及在存在关系r的情况下每个特征f1,…,fn出现的次数|(f1,r)|,…,|(fn,r)|例如:在语料中实体a的实体类型为“人物”,实体b的实体类型为“电话”,实体a和实体b之间存在“人物拥有电话”关系的实例数量有30个,那么|r|=30,对这30个实体对使用步骤b5213得到特征{"电话",nr}的数量有20个,那么|({"电话",nr},r)|=20。同时也统计实体a和实体b虽然出现在语料中,但实体a和实体b不存在关系r的情况的数量以及该情况下特征f1,…,fn出现的次数类似的,在语料中实体a的实体类型为“人物”,实体b的实体类型为“电话”,实体a和实体b之间不存在“人物拥有电话”关系的实例数量有70个,那么对这70个实体对使用步骤b5213得到特征{"电话",nr}的数量有30个,那么|({"电话",nr},r)|=30。步骤b5222、计算实体a和实体b存在关系r时的p(r),和实体a和实体b不存在关系r时的例如:实体a和实体b之间存在“人物拥有电话”关系的实例数量有30个,那么|r|=30,实体a和实体b之间不存在“人物拥有电话”关系的实例数量有70个,那么步骤b5223、对所有fi,即i∈[1,n],计算实体a和实体b存在关系r时的p′(fi|r)并保存。对所有fi,即i∈[1,n],计算实体a和实体b不存在关系r时的关于特征fi的条件概率并保存。例如,已知|({"电话",nr},r)|=20,|r|=30,那么p'({"电话",nr}|r)=|({"电话",nr},r)|/|r|=20/30=0.67。步骤b523、对测试集中的每个文本语料c中的每个实体对,即实体a-实体b,使用步骤b5211,b5212,b5213中的方法,提取特征窗口中的每个词的特征fci。例如:测试集里的句子3“王五的手机号码是123456”,提取的实体对有:“王五-123456”,对应的特征有:{0,nr},{"王五",nr},{1,ude1},{"的",ude1},{2,nr},{"手机",nr},{3,nr},{"号码",nr},{4,vshi},{"是",vshi},{5,n},{"123456",n},步骤b524、计算测试集中的每个文本语料中的每个实体对是否包含实体关系r,包括2个步骤,具体是:步骤b5241、在步骤b5223保存的p′(fi|r)和中查询由步骤b523提取的特征fci,如果特征fci出现在步骤b5223保存的p′(fi|r)或的fi中,那么p(fci|r)=p′(fi|r)否则p(fci|r)为所有p′(fi|r)中的最小值,为所有中的最小值:步骤b5242、使用如下公式计算语料c中实体a和实体b存在关系r的概率pc(r|x;(a,b)),当其值大于0时,表示实体a和实体b之间存在关系r。其中d(a,b)由步骤b32计算得到,fp的参数由步骤b34计算得到,p(r),由步骤b5222计算得到,p(fci|r),由步骤b5241计算得到,fn的参数由步骤b33计算得到。例如:在句子3“王五的手机号码是123456”中,a=“王五”,b=“123456”d(a,b)=5提取的特征fci及其对应的条件概率p(fci|r)如表9:表9句子3的特征及其条件概率p(fci|r)提取的特征fci及其对应的条件概率如表10:表10句子3的特征及其条件概率使用步骤b34中的例子中的参数fp(5)=31.97fn(5)=9.37因为pc(r|x;(a,b))大于0,所以实体“王五”和实体“123456”之间存在“人物拥有电话”关系。步骤b525、如下计算测试集中的参数f1score:其中tp是在测试集的每个语料中实体a和实体b标记为拥有关系r,计算得到的pc(r|x;(a,b))大于0的实体对的数量;fp是在测试集的每个语料中实体a和实体b标记为不拥有关系r,计算得到的pc(r|x;(a,b))大于0的实体对的数量;fn是在测试集的每个语料中实体a和实体b标记为拥有关系r,计算得到的pc(r|x;(a,b))不大于0的实体对的数量。例如:tp=30,fp=10,fn=20,那么:步骤b53、经过步骤b52,可以得到属性集r″中的每个子集所对应的参数f1score,保存其中最大的f1score所对应的子集,以及对应的p(r),和所有的p(fi|r),例如:测试集中{{该词在句子中的位置,该词的词性},{词的具体形式,该词的词性}}对应的f1score为0.67;{该词在句子中的位置,该词的词性}对应的f1score为0.5;{该词在句子中的位置,{词的具体形式,该词的词性}}对应的f1score为0.6;其中{{该词在句子中的位置,该词的词性},{词的具体形式,该词的词性}}对应的f1score的0.67最大,那么保存子集{{该词在句子中的位置,该词的词性},{词的具体形式,该词的词性}}及其对应的p(r),以及所有的p(fi|r),步骤b6、优化特征窗口大小包括5个步骤,具体为:步骤b61、设置特征窗口大小为以实体a的位置和实体b的位置中较小的为初始开始位置ps(包括该位置),较大的为初始结束位置pe(包括该位置),设置初始f1score′为0,设置初始f1score的提高增量xi为区间(0,1)中某一较小的数,如0.001,设置窗口增量t为0。步骤b62、重复执行下列步骤,直到前后2次的f1score的提高增量δf1小于xi,δf1的计算公式如下。δf1=f1score′-f1scoreb621、特征窗口的开始位置等于初始开始位置减去窗口增量t,即:ps=ps-t对测试集执行b523,b524,b525得到本次的f1score,由b62计算δf1,如果δf1<xi,转至步骤b63,否则执行b622。b622、更新t、f1score的值,转至步骤b621。f1score=f1score′t=t+1b63、保存窗口开始位置的增量,即ws=t,设置窗口增量t=1。例如:设置窗口大小为以实体a的位置和实体b的位置中较小的为初始开始位置ps(包括该位置),较大的为初始结束位置pe(包括该位置),设置初始f1score′为0,设置初始f1score的提高增量xi为0.001,设置窗口增量t为0。迭代执行b621,b622,每次得到的δf1和窗口增量t如表11:表11δf1和窗口增量t当窗口增量t为4时,δf1小于xi,设置ws为4,b64、重复执行下列步骤,直到前后2次的f1score的提高增量δf1小于xi。b641、特征窗口的结束位置等于初始结束位置加上窗口增量t,即:ps=ps+t对测试集执行b523,b524,b525得到本次的f1score,由b62计算δf1,如果δf1<xi,转至步骤b65,否则执行b642。b642、使用(18)和(19)更新f1score、t的值,转至步骤b641。b65、保存保存窗口结束位置的增量,即we=t。例如,设置特征窗口的结束位置等于初始结束位置。迭代执行b641,b42,每次得到的f1score′和窗口增量t如表12:表12δf1和窗口增量tf1scoretδf10.63010.0400.65020.0200.65030.000当窗口增量t为3时,δf1小于xi,设置ws为3。c、关系提取包括2个步骤,具体为:步骤c1、对于要提取关系的文本c,首先按照步骤a3对其进行句子分割、分词(中文)/词干化(英文),标识每个词在文本中的位置以及命名实体,然后标注步骤b53所得到的子集中涉及的每个属性。例如,设步骤b53所得到的子集为:{{词在文本中的位置,词},{命名实体,词性}}对于句子4“北京测腾公司赵六的电话是123456。”,根据步骤a3进行标注,标注结果如表13:表13句子4的标注结果位置词命名实体词性0北京locationns1测腾ontc2公司ontc3赵六personnr4的oude15电话on6是ovshi7123456teln8。ow步骤c2、计算关系r是否存在包括3个步骤,具体为:步骤c21、根据步骤a1所设置的第一实体类型e1和第二实体类型e2,提取文本c中的所有实体对。例如,提取句子4“北京测腾公司赵六的电话是123456。”中的实体对为“赵六-123456”。步骤c22、按照步骤b6得到的ws和we设置特征窗口,并按照b53所得到的子集使用b5212,b5213提取特征。例如,设按照b6得到的ws和we为4和3,按照b53所得到的子集是{{词在文本中的位置,词},{命名实体,词性}},提取的特征是:{{0,北京},{location,ns}},{{1,测腾},{o,ntc}},{{2,公司},{o,ntc}},{{3,赵六},{person,nr}},{{4,的},{o,ude1}},{{5,电话},{o,n}},{{6,是},{o,vshi}},{{7,123456},{tel,n}},{{8,。},{o,w}},步骤c23、由步骤b5242计算pc(r|x;(a,b)),其中各参数的计算参见b5242,当其值大于0时,表示文本c中实体a和实体b之间存在步骤a1中设定的实体关系。例如:计算pc(r|x;(a,b)),pc(r|x;(a,b))大于0,因此实体对“赵六-123456”存在“人物拥有电话”关系。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1