一种基于图数据库的关系网查询方法及系统与流程
本发明属于数据处理技术领域,尤其涉及一种基于图数据库的关系网查询方法及系统。
背景技术:
目前,业内常用的现有技术是这样的:
在众多不同的数据模型里,关系数据模型自20世纪80年代就处于统治地位,而且出现了不少巨头,如oracle、mysql,它们也被称为:关系数据库管理系统(rdbms)。数十年来,开发者习惯了使用关系型数据库处理关联的、半结构化的数据集。关系型数据库设计之初是为了处理纸质表格以及表格化结构,它们试图对这种实际中的特殊联系进行建模。然而,随着关系数据库使用范围的不断扩大,也暴露出一些它始终无法解决问题,其中最主要的是数据建模中的一些缺陷和问题,以及在大数据量和多服务器之上进行水平伸缩的限制。同时,互联网发展也产生了一些新的趋势变化:1、用户、系统和传感器产生的数据量呈指数增长,数据量不断增加,大数据的存储和处理;2、新时代互联网形势下的问题急迫性,这一问题因互联网+、社交网络,智能推荐等的大规模兴起和繁荣而变得越加紧迫。
然而关系型数据库在处理“复杂关系”数据时却显得力不从心,从而导致大量解决这些问题中某些特定方面的不同技术出现,它们可以与现有rdbms相互配合或代替它们。
图数据库源起欧拉和图理论,也可称为面向/基于图的数据库,对应的英文是graphdatabase。图数据库的基本含义是以“图”这种数据结构存储和查询数据,而不是存储图片的数据库。它的数据模型主要是以节点和关系(边)来体现,也可处理键值对。它的优点是快速解决复杂的关系问题。图具有如下特征:1、包含节点和边;2、节点上有属性(键值对);3、边有名字和方向,并总是有一个开始节点和一个结束节点;4、边也可以有属性。图数据库它善于处理大量的、复杂的、互联的、多变的网状数据,其效率远远高于传统的关系型数据库的百倍、千倍甚至万倍。
综上所述,现有技术存在的问题是:
(1)现有技术中数据没有采用边分割的方式存储,在复杂图的查询性能上不具备明显优势;
(2)现有技术中不能实现对关系数据的存储和分析。
解决上述技术问题的难度和意义:
解决上述问题的难度在于处理存储后端和索引后端的数据同步;
意义在于使用更合理的数据接口存储数据,提高了存取效率,并为分析数据提供了更便捷的方式。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种基于图数据库的关系网查询方法,
本发明是这样实现的,一种基于图数据库的关系网查询方法,所述的基于图数据库的关系网查询方法,包括:
步骤一:利用直接索引搜索,获取图中心点的主键或者类图中心点的主键列表;
步骤二:选取图中心点进行一度或多度扩线并获取人物关系信息;
步骤三:在扩线过程中过滤出顶点类型或者关系类型,获取人物关系信息;
步骤四:过滤扩线时的回路,使用gremlin提供的的去重方法dedup()去除重复的关系数据;使用gremlin提供的判断是否存在的方法without(),排除已经在集合中的元素;
步骤五:配置顶点类型,自动过滤关系网中的公共顶点。
进一步,步骤一,具体包括:
使用gremlin查询索引的方法对结果数据进行分页。
进一步,步骤二,
具体包括:
获取中心顶点存储到临时集合,并重复步骤不断扩线下一级节点存储到临时集合,直到满足条件或者到达指定扩线级数,则返回临时集合中的所有顶点和关系的数据。
进一步,步骤三中使用gremlin提供的过滤边类型的方法bothe(),传入关系类型,过滤出关注的关系类型数据;使用gremlin提供的过滤顶点类型的方法haslabel(),获取顶点类型;
具体包括:
获取中心顶点存储到临时集合,并重复步骤不断扩线下一级满足关系类型的关系和满足顶点类型的节点存储到临时集合,直到满足条件或者到达指定扩线级数,则返回临时集合中的所有顶点和关系的数据。
进一步,具体包括:
基于步骤4返回的顶点和关系的数据进行处理,使用过滤集合中已存在的数据来减少无效数据的返回。
进一步,步骤五具体包括:
基于步骤5返回的顶点和关系的数据进行处理,使用过滤顶点类型的方式来阻止公共顶点进行扩线,是最终数据更加清晰。
步骤四中使用dedup()方法排除重复的关系数据;使用without()方法,排除掉已经在集合中的元素,过滤扩线时的回路,减少重复信息返回,避免重复数据。
步骤五中,组合使用haslabel和without,屏蔽不需要的顶点类型。
本发明的另一目的在于提供一种实现所述基于图数据库的关系网查询方法的计算机程序。
本发明的另一目的在于提供一种实现所述基于图数据库的关系网查询方法的信息数据处理终端。
本发明的另一目的在于提供一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行所述的基于图数据库的关系网查询方法。
本发明的另一目的在于提供一种实现所述基于图数据库的关系网查询方法的基于图数据库的关系网查询系统,所述基于图数据库的关系网查询系统包括:图数据库,存储后端,索引后端。
图数据库用于引擎,在存储数据时将数据同步到存储后端和索引后端;
进行查询扩线时,存储后端处理简单的等值查询,而索引后端处理复杂的模糊查询。
综上所述,本发明的优点及积极效果为:
本发明提供一种基于图数据库的关系网查询方法,核心是通过gremlin语句对已知的中心顶点进行扩线查询;数据采用边分割的方式存储,在复杂图的查询性能上比传统的关系型数据库更具优势。当数据量达到十万级,查询时图数据库仍可做到秒级响应,而传统关系型数据库会出现疲态;而当数据量达到百万级时,查询时图数据库仍可做到在1~3秒响应,而传统关系型数据库会则无法完成该查询;
选型janusgraph作为图数据库,以hbase作为存储后端,以elasticsearch作为索引后端,采用以gremlin语句的请求gremlin-server的方式获取查询数据,实现对关系数据的存储和分析。
附图说明
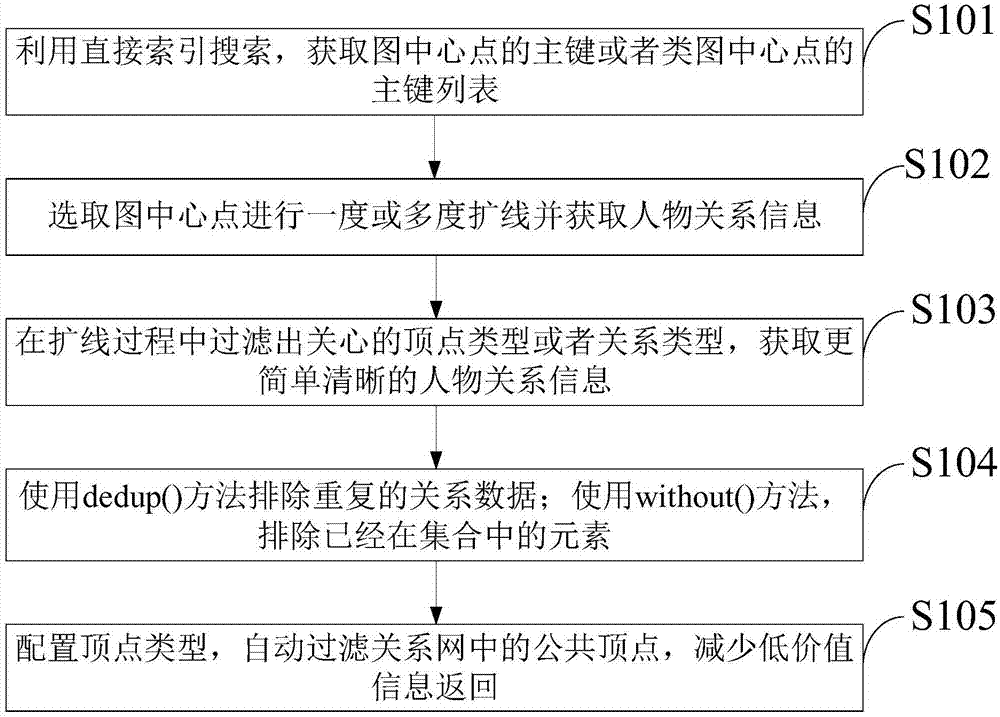
图1是本发明实施例提供的基于图数据库的关系网查询方法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
为了解决现有的技术问题,本发明提供一种基于图数据库的关系网查询方法,核心是通过gremlin语句对已知的中心顶点进行扩线查询;数据采用边分割的方式存储,在复杂图的查询性能上比传统的关系型数据库更具优势。选型janusgraph作为图数据库,以hbase作为存储后端,以elasticsearch作为索引后端,采用以gremlin语句的请求gremlin-server的方式获取查询数据,实现了对关系数据的存储和分析。
下面结合附图对本发明进行进一步详细说明;
如图1所示,本发明实施例提供的一种基于图数据库的关系网查询方法,包括:
s101:利用直接索引搜索,获取图中心点的主键或者类图中心点的主键列表;
s102:选取图中心点进行一度或多度扩线并获取人物关系信息;
s103:在扩线过程中过滤出关心的顶点类型或者关系类型,获取更简单清晰的人物关系信息;
s104:使用dedup()方法排除重复的关系数据;使用without()方法,排除掉已经在集合中的元素;
s105:配置顶点类型,自动过滤关系网中的公共顶点,减少低价值信息返回。
步骤s103中,使用gremlin的bothe()的重载方法传入想获取的关系类型,使用haslabel()方法获取想获取的顶点类型。
步骤s104中,过滤扩线时的回路,减少重复信息的返回。主要使用dedup()方法排除重复的关系数据,使用without()方法排除掉已经在集合中的元素,避免重复数据
步骤s105中,本发明实施例提供的组合使用haslabel和without,屏蔽不需要的顶点类型。
本发明实时例提供的基于图数据库的关系网查询系统包括:图数据库,存储后端,索引后端。
图数据库用于引擎,在存储数据时将数据同步到存储后端和索引后端;
进行查询扩线时,存储后端处理简单的等值查询,而索引后端处理复杂的模糊查询。
选型janusgraph作为图数据库,以hbase作为存储后端,以elasticsearch作为索引后端,采用以gremlin语句的请求gremlin-server的方式获取查询数据,实现了对关系数据的存储和分析。
下面结合具体实施例对本发明进行进一步详细说明;
实施例1;
本发明实施例提供的基于图数据库的关系网查询方法的具体步骤如下:
步骤一:使用直接索引搜索获取图中心点的主键或者类图中心点的主键列表。
获取图的中心点,提供给之后的步骤使用。
执行语句如下:
graph.indexquery(【查询索引】,'v.【查询字段】:【查询字段值】').offset(0).limit(10).vertexstream().iterator().next().getelement()
步骤二:使用步骤1获得的中心点主键进行一度或多度扩线并获取人物关系信息。
获取中心点多度扩线后的顶点和边的数据。
执行语句如下:
g.v(【中心点主键】).aggregate('x').bothe().dedup().aggregate('x').otherv().aggregate('x').repeat(bothe().dedup().aggregate('x').otherv().aggregate('x')).times(1).cap('x').unfold()
步骤三:在扩线中过程中过滤出关心的顶点类型或者关系类型,获取更简单清晰的人物关系信息。在步骤二的基础上加入了对顶点和关系类型的过滤条件,获取自己关心的顶点和边的类型后的结果。
执行语句如下:
g.v(【中心点主键】).aggregate('x').bothe(【关心的边类型】).dedup().choose(otherv().haslabel(【关心的顶点类型】),__.aggregate('x')).otherv().choose(__.haslabel(【关心的顶点类型】),__.aggregate('x')).repeat(bothe(【关心的边类型】).dedup().choose(inv().haslabel(【关心的顶点类型】).and().outv().haslabel(【关心的顶点类型】),__.aggregate('x')).aggregate('x').otherv().choose(__.haslabel(【关心的顶点类型】),__.aggregate('x')).aggregate('x')).times(1).cap('x').unfold()
步骤四:过滤扩线时的回路,减少重复信息的返回。此步骤的作用主要是在步骤2或者步骤3的基础上减少多度扩线下出现顶点或边的重复问题。可以明显察觉到返回的数据的变化。
执行语句如下:
g.v(【中心点主键】).aggregate('x').bothe().dedup().aggregate('x').otherv().aggregate('x').repeat(bothe().dedup().where(without('x')).aggregate('x').otherv().where(without('x')).aggregate('x')).times(2).cap('x').unfold()
步骤五:配置顶点类型并自动过滤关系网中的公共顶点,减少低价值信息的返回。此步骤的作用主要是在步骤四的基础上减少多度扩线下出现公共顶点数据过多的问题。可以过滤掉步骤二中公共顶点的扩线结果。
执行语句如下:
g.v(【中心点主键】).aggregate('x').bothe().dedup().aggregate('x').otherv().aggregate('x').repeat(has('v_label',without(【公共顶点类型】)).bothe().dedup().where(without('x')).aggregate('x').otherv().where(without('x')).aggregate('x')).times(2).cap('x').unfold()。
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用全部或部分地以计算机程序产品的形式实现,所述计算机程序产品包括一个或多个计算机指令。在计算机上加载或执行所述计算机程序指令时,全部或部分地产生按照本发明实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(dsl)或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输)。所述计算机可读取存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,dvd)、或者半导体介质(例如固态硬盘solidstatedisk(ssd))等。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!