基于Lucene和文法网络的聊天机器人及其实现方法与流程
本发明涉及人工智能技术领域,特别涉及基于lucene和文法网络的聊天机器人及其实现方法。
背景技术:
随着人工智能与自然语言处理的兴起,聊天机器人作为自然语言处理中自动问答下的一个重要方向,主要研究模拟人类对话或聊天的问题,当前,主要的技术手段是面向特定领域的规则匹配和面向开放域的基于检索、机器学习等。
市面上商业化的聊天机器人,主要是通过规则化(正则匹配或文法网络)的方法实现的,这种聊天机器人的设计,是通过人工构造模板和规则,用以设定特定场景、编写特定的对话问答,来匹配用户问题,来生成答案,给出回答的。无论是正则匹配还是文法网络,对于它们构建有限规则外的开放性问句,由于人类日常通用随意语言不规则、句式成分缺失等,难以构建规则,都无法识别,也就是说不能处理开放域的聊天问答,只能实现特定领域的问答。同时对于句式单一、实体丰富的聊天场景,实体数据达百万、千万级,规则上万,规则匹配慢,这显然是不合理的。
规则化的方案通过构建场景模板等用于自动问答,匹配方式虽然能够给出精确回答,但人类语言、聊天句式、聊天场景等千千万万、不可计数,不可能、也不能够构建所有可能出现问答的模板;同时经典常用句式的实体达千万、亿甚至是兆级,也不是结构化的数据,常用的数据库等的匹配就变得很慢了。因为这样既不经济(需要大量人力和有经验的文法工程师),同时也不能够罗列出所有自然语言句式(存在句式语义分歧问题)。不能穷举出所有的语法可能,单一的规则化方法就只能处理特定领域的问题,目前还没有一种通用化方法。针对规则和检索化两个方法的优缺点,采用规则匹配和搜索引擎搭配并行的方法构建聊天机器人,不失为一种通用化的合理方案。
技术实现要素:
本发明的目的是克服上述背景技术中不足,提供基于lucene和文法网络的聊天机器人及其实现方法,通过使用abnf提供标准的语义规范构建问答模板,规则中实体部分采用lucene精确检索,实体关系使用arango数据库构建的知识图谱查询;规则化模板不能识别的问句部分将提取关键词,并模糊检索已经存储在lucene中的真实用户聊天问答语料;实体、实体关系、语料的检索发生在规则匹配前,并存在于缓存里,解决了基于规则化的聊天机器人规则匹配速度慢、不能处理开放域、规则匹配穷举困难等问题,同时能够对对特定领域和开放领域进行自动回答。
为了达到上述的技术效果,本发明采取以下技术方案:
基于lucene和文法网络的聊天机器人的实现方法,包括以下步骤:
a.通过lucene在硬盘中构建实体变量的索引文件以及真实用户聊天问答语料索引文件、通过arngo数据库在硬盘上构建实体、实体关系;
b.选择abnf文法规范和解析器构建对应的问答模板,用以解析聊天问句;
c.在abnf解析器添加lucene检索实体的叶子节点、arango查询关系的叶子节点、lucene检索语料的叶子节点;
d.进行语句匹配按照定义的规则,匹配指定的叶子节点;
e.选择最优的回答。
本发明的基于lucene和文法网络的聊天机器人的实现方法主要是通过lucene在硬盘中构建作者writer、视频video、音乐music等变量的索引文件,以及真实用户聊天问答语料(包括问题和回答)qadb索引文件;同时通过arngo数据库在硬盘上构建作者与视频、作者与音乐等的实体和关系,然后选择恰当的abnf文法规范和解析器,构建对应的问答模板,用以解析聊天问句,然后在abnf解析器中添加lucene检索实体的叶子节点、lucene检索语料的叶子节点和arango查询关系的叶子节点,其次,再进行语句匹配按照定义的规则,匹配指定的叶子节点并确定对应的回答结果,最后返回选择最优的回答;
其中,通过添加lucene检索实体的叶子节点和arango查询关系的叶子节点,可构建特定领域的文法网络,用以解决精确、快速识别封闭域的聊天问题,通过添加lucene检索语料的叶子节点,可实现模糊全文检索语料识别聊天问句,解决真实用户开放域聊天问题。
进一步地,所述步骤c中的lucene检索实体的叶子节点是通过lucene全文检索引擎,使用精确、高并发的lucene检索功能,实现短文本聊天问句中的所有实体的匹配,所述实体变量的索引文件采用的是string格式,用以规则化的快速、精确的字符串匹配。
进一步地,所述步骤d中按照定义的规则,匹配到lucene检索实体的叶子节点时,将采用任意字符组合的方式切词再通过lucene检索实体的叶子节点检索索引文件中存在的实体,从而得到实体。
进一步地,所述步骤d中按照定义的规则,匹配到arango查询关系的叶子节点时,是同匹配到lucene检索实体的叶子节点时得到的所述实体一同通过任意字符切分分词后,再检索arango数据库获取实体对应关系的实体,再抽取后面的实体,从而得到新的实体。
进一步地,所述步骤c中的lucene检索语料的叶子节点是通过收集,处理、清洗用户真实数据并将用户聊天问答集合起来采用lucene的text格式存储。
进一步地,当在所述步骤d中按照定义的规则,匹配到lucene检索语料的叶子节点时,是使整个句子模糊匹配lucene中所有语料问句,使用levenshtein算法,提取出匹配程度最高的问句并抽取回答。
同时,本发明还公开了一种基于lucene和文法网络的聊天机器人,包括:
语音识别模块:将用户语句转化为文本信息;
abnf文法网络模块:以规则化方法穷举所有用户问句的语法、关系和实体,以精确封闭域聊天问答,给出聊天的回答结果;
lucene存储模块:存储实体和问答语料;
arangodb知识图谱模块:存储实体间的关系,用以实现实体间关系的查找;
lucene全文模糊检索模块:模糊检索与用户问句相似的存储语料,给出回答结果;
ansj-搜索引擎搜索模块:用于在ansj工具提取出用户问句的关键字后,到第三方搜索引擎进行关键词搜索,给出搜索引擎的回答结果;
问答结果判断模块:对abnf文法网络模块、lucene全文模糊检索模块及ansj-搜索引擎搜索模块给出的结果进行取优判断并返回优选的回答结果;
语音生成模块:根据问答结果判断模块得到的回答结果的文本语句生成语音;
其中,所述语音识别模块及问答结果判断模块均分别与abnf文法网络模块、lucene全文模糊检索模块、ansj-搜索引擎搜索模块相连,且问答结果判断模块还与语音生成模块相连,abnf文法网络模块分别与arangodb知识图谱模块、lucene存储模块相连,lucene全文模糊检索模块与lucene存储模块相连。
进一步地,所述lucene全文模糊检索模块中模糊查询搜索评分采用的算法是damerau-levenshtein算法,且其阀值设为10。
进一步地,所述问答结果判断模块在进行结果进行取优判断并返回优选的回答结果时具体是若abnf文法网络模块有聊天的回答结果返回时则返回abnf文法网络模块的回答结果,否则,确认lucene全文模糊检索模块中是否有评分高于阀值的回答结果返回,若有,则返回lucene全文模糊检索模块的回答结果,否则返回ansj-搜索引擎搜索模块的回答结果。
进一步地,所述lucene存储模块内存储实体和问答语料时,实体采用string格式,问答语料使用text格式。
本发明与现有技术相比,具有以下的有益效果:
本发明的基于lucene和文法网络的聊天机器人及其实现方法,通过lucene全文检索引擎、arango数据库、ansj分词工具和abnf文法规范等,公开了一种基于lucene和文法网络的聊天机器人设计方法,并构造出半开放聊天机器人装置,可解决基于规则化的聊天机器人规则匹配速度慢、不能处理开放域、规则匹配穷举困难等问题,同时能够对对特定领域和开放领域进行自动回答,且相比其他聊天机器人装置,本发明的基于lucene和文法网络的聊天机器人的lucene存储模块和arangodb知识图谱模块,有利于实体的关系的匹配和大规模并发,使用ansj-搜索引擎搜索模块,解决开放域问题。
附图说明
图1是本发明的一个实施例的基于lucene和文法网络的聊天机器人的实现方法的流程示意图。
图2是本发明的一个实施例的基于lucene和文法网络的聊天机器人的实现方法中规则匹配的流程示意图。
图3是本发明的一个实施例的基于lucene和文法网络的聊天机器人的示意图。
具体实施方式
下面结合本发明的实施例对本发明作进一步的阐述和说明。
实施例:
实施例一:
一种基于lucene和文法网络的聊天机器人实现方法,其包含的步骤如下:
1)通过lucene在硬盘中构建作者writer、视频video、音乐music等变量的索引文件,以及真实用户聊天问答语料(问题和回答)qadb索引文件;通过arngo数据库在硬盘上构建作者与视频、作者与音乐等的实体和关系。
2)选择恰当的abnf文法规范和解析器,构建对应的问答模板,用以解析聊天问句。
3)在abnf解析器中添加lucene检索实体的叶子节点、lucene检索语料的叶子节点和arango查询关系的叶子节点。
4)按照定义的规则,匹配指定的叶子节点。
5)选择最优的回答。
具体的,本发明的技术方案中是通过添加lucene检索实体的叶子节点和arango查询关系的叶子节点构建特定领域的文法网络,用以解决精确、快速识别封闭域的聊天问题;通过添加、lucene检索语料的叶子节点,模糊全文检索语料,识别聊天问句,解决真实用户开放域聊天问题。
其中,匹配lucene检索实体的叶子节点就是通过lucene全文检索引擎,使用精确、高并发的lucene检索功能,实现短文本聊天问句中的所有实体的匹配。通过lucene在硬盘构建动画、漫画、游戏、小说、作者、角色等实体变量的索引文件,采用的是string格式,用以精确匹配,例如有一个问句:
问句q1:“我想看动漫某夜叉!”
则将问句q1处理特殊符号得到“我想看动漫某夜叉”后,使用lucene检索实体的叶子节点就会采用任意字符组合的方式切词,再通过lucene检索实体节点,检索“我想看动漫某夜叉”、“我想看”、“我想”…“想看动漫某夜叉”、“看动漫某夜叉”……“叉”等,检索索引文件中存在的实体,得到“某夜叉”、“夜叉”、“动漫”等实体。
匹配lucene检索语料的叶子节点是通过收集,处理、清洗用户真实数据,将那些经典的和奇怪的用户聊天问答集合起来,采用lucene的text格式存储起来后,然后,使用levenshtein算法,整个句子模糊匹配lucene中所有语料问句,提取出匹配程度最高的问句并抽取回答,即通过lucene在硬盘构建实际用户数据的问答语料qadb的索引文件,用以模糊匹配。
例如来了一个问句:
问句q2:“成都这个城市好不好?”
lucene聊天语料节点就会使用整个短文本,通过levenshtein算法检索所有的语料问句,假设有以下语料问句与:
(q2.1)成都好不好?
(q2.2)成都这个城市好吗?
(q2.3)成都这个城市咋样?
根据levenshtein算法,匹配结果得分高低的顺序就是(q2.2),(q2.3),
(q2.1),那么就会抽取问句(q2.2)所对应的回答。
匹配arango查询关系的叶子节点是通过arango在硬盘构建动画、漫画、游戏、小说、作者、角色等变量的关系(relation)知识图谱,同匹配lucene检索实体的叶子节点中得到的实体后的通过任意字符切分分词后的词(关系),检索arango数据库,获取实体对应关系的实体,再抽取后面的实体,例如:
问句q3:我想看邓某妻子的电视剧
在(1.1)中匹配得到实体“邓某”后,再切分“妻子的电视剧”,任意切分有“妻”、“妻子”、“妻子的”…“剧”,再对这些分词对着实体邓某查找关系,能查询到“妻子”,那么就抽取得到的新的真正的实体,也就是邓某的妻子——“孙某”,如此,就能扩大范围,使得聊天问答更加精确。
具体的,本发明的技术方案中是基于lucene的精确规则匹配和模糊检索,即分别将lucene检索实体的叶子节点、lucene检索语料的叶子节点和arango查询关系的叶子节点当做一个条件规则,写入自动问答的文法网络规则模板中。
例如:
rule_music_question=[“俺”][“要看”][writer“的”[relation]]music
rule_music_answer=[“给你”]music
其中,writer表示实体作者,music表示实体音乐名,relation表示实体间的关系,比如说人物关系夫妻、兄弟等,当问句匹配到writer或music的时候,就会采用lucene检索的方式检索所有的writer和music实体,当用户文本问句匹配到relation的时候,就会采用arangodb数据库查询的方式查询所有的relation实体,用以替代规则穷举的方法。
具体的,当规则rule_music_question能够匹配上的时候,提取出匹配到的writer或animation实体,和relation实体后,根据对应的rule_music_answer规则,给出回答。
lucene语料的模糊匹配中模糊匹配主要是使用lucene的标准分词器standardanalyzer对问答语料进行分词处理,最后再用testfield进行存储,使用levenshtein算法,用以模糊搜索,具体方法如下:
question=“你好”answer=“你也好”
其中,检索方法采用的是damerau-levenshtein算法进行模糊查询,模糊查询搜索评分采用的算法是damerau-levenshtein算法,且其阀值设为10。
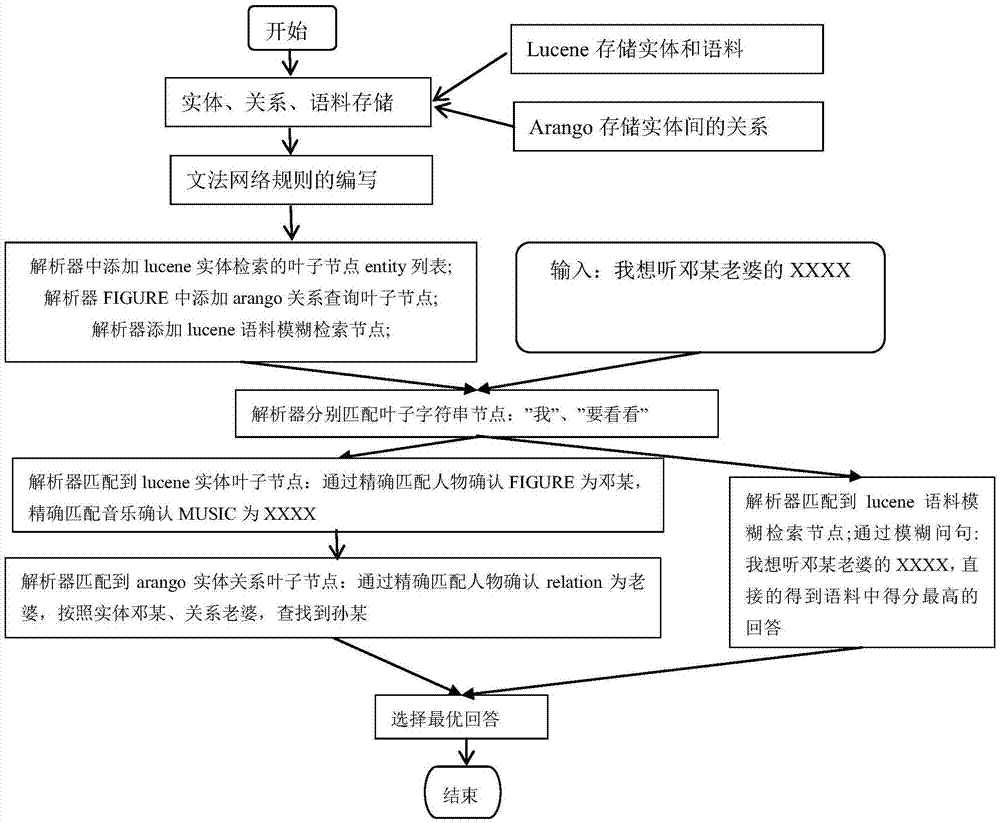
如图1所示,一种基于lucene和文法网络的聊天机器人实现方法的具体工作流程的实施例,具体如下:
a.根据需求编写文法网络语法规则:如下
rule_music_question=[”我”][“看看”][figure][relation]music
rule_music_answer=”给你”[figure][relation]music
b.实体、语料的lucene索引文件增量构建,arango关系的构建等,如下:
新建或更新索引文件:figure、music等;
新建或更新arango指数图谱:relation等;
c.在解析器中添加music、figure、语料等rule节点,在figure实体的lucene检索中添加relation查询的arango节点;
d.问句匹配,按照定义的规则,匹配指定的叶子节点。
如图2所示为文法网络规则匹配的流程图:按照各个节点层层匹配,在该图中详细描绘了一条规则的完整匹配过程。
实施例二
如图3所示,一种基于lucene和文法网络的聊天机器人,具体包括:
语音识别模块、abnf文法网络模块、lucene存储模块、arangodb知识图谱模块、lucene全文模糊检索模块、ansj-搜索引擎搜索模块、问答结果判断模块、语音生成模块。
其中,语音识别模块及问答结果判断模块均分别与abnf文法网络模块、lucene全文模糊检索模块、ansj-搜索引擎搜索模块相连,且问答结果判断模块还与语音生成模块相连,abnf文法网络模块分别与arangodb知识图谱模块、lucene存储模块相连,lucene全文模糊检索模块与lucene存储模块相连。
具体的,语音识别模块用于接受用户语音,使用语音识别工具,将用户语句转化为文本信息。
abnf文法网络模块则用于规则化方法穷举所有用户问句的语法、关系和实体,以精确封闭域聊天问答,给出标准聊天回答,其具体实现方式如下:
首先,分别包括并行处理的文法网络匹配,lucene模糊检索和ansj关键词提取三个子方法,具体内容如下:
其中,文法网络匹配是根据预先设定的规则,从前往后依次匹配已经分领域设定好的规则,如当匹配到实体关键字figure和music的时候,则采用lucene检索预先在硬盘上的构造好的实体索引文件;当匹配到实体关键字figure中含有relation的时候,则查询arangodb中实体关键字singer的relation对应的实体,如果能够匹配上,则返回对应回答模板。
在本实施例中若输入的语音为“我想听邓某老婆的xxxx”
即首先利用lucene查询到邓某,然后再使用知识图谱arangodb查找邓某老婆,找到孙某,然后再查找孙某唱的音乐“xxxx”,这时判断能够匹配上,那么就抽取实体孙某,实体具体的音乐,返回对应的回答,也就是回答为“播放孙某的电影”。
lucene全文模糊检索是与文法网络匹配并行处理,根据damerau-levenshtein算法,通过修改插入一个字符,修改一个字符或者删除一个字符,对比用户问句与预先存储的lucene中问答语料,找到编辑距最小的问句,计算评分,并抽取其回答;
ansj-搜索引擎搜索也是与文法网络匹配并行处理,根据td-idf算法提取关键词[“想听”,“邓某”,“老婆”,“xxxx”],然后再根据这些词四个组合搜素,获取排名最靠前的回答:
“盘点邓某老婆孙某演过的几部电影,你看过吗?《xx天使》饰演:查某某;《大话xx》饰演:金某;《x壁》饰演:芍某;《xx长》饰演:某兰;《xx宝盒》饰演:某某仙子;《x山》饰演:某虎”。
lucene存储模块:用于存储实体和问答语料,实体用于规则穷举,包含电影,音乐,动漫,小说等名字,问答语料用以lucene搜索引擎检索模糊检索。
arangodb知识图谱模块:用于存储实体、实体间的关系,用以实现规则中关系的查找。
lucene全文模糊检索模块:用于模糊检索与用户问句相似的存储语料,给出回答的结果。
ansj-搜索引擎搜索模块:用于在ansj工具提取出用户问句的关键字后,到百度或者360进行关键词搜索,给出搜索引擎的回答结果。
问答结果判断模块:用于对abnf文法网络模块、lucene全文模糊检索模块及ansj-搜索引擎搜索模块给出的结果进行取优判断并返回,具体过程如下:
若abnf文法网络模块有聊天的回答结果返回时则返回abnf文法网络模块的回答结果,否则,确认lucene全文模糊检索模块中是否有评分高于阀值即高于10分的回答结果返回,若有,则返回lucene全文模糊检索模块的回答结果,若上述条件均不符合,返回ansj-搜索引擎搜索模块的回答结果。
语音生成模块用于将返回的文本信息回答转化为语音。
由上可知,在本发明的基于lucene和文法网络的聊天机器人中,将lucene、文法网络和知识图谱相结合,问答规则模板部分使用文法网络构建,规则不能识别部分采用lucene搜索引擎实现,例如问答:
question_vedio_query_0:[“能不能”]“播”[“放”][writer[relation]“的”]vedioname
ansswer_vedio_query_0:“给你播放”[writer[relation]“的”]vedioname
可以根据匹配到的“能不能播放vedioname”、“放映vedioname”、“放张某某的vedioname”用户问句等,给出回答,如果所有的规则不能匹配上,那么就使用分词工具(比如说ansj)提取问句中的关键字后,采用搜索引擎检索已经拥有的问答语料qadb。其中vedioname表示电影电视剧的实体名,writer表示作者、导演,relation表示关系等。
vedioname、writer等这些实体名使用lucene构建索引存储(搜索引擎的检索速度比mongo、mysql等数据库、redis等缓存系统要快、并发程度高),用以精确匹配检索;relation这些关系采用知识图谱数据库(比如说arangodb)存储,用以表示各个实体间的关系;最后的问答语料qadb也用lucene构建索引存储到硬盘,用以实现模糊检索。
在lucene全文检索工具采用的是:前缀压缩的fst结构词典、数据压缩和跳跃表相结合的frameofreference倒排表、以及能够分块和压缩的正向文件,构建倒插排序索引;使用语法树和td-idf算法,实现大规模数据精确和模糊全文检索。
本发明中充分利用了lucene对于大规模实体的高并发数据的检索时高速检索。由于倒排文件索引能够提供快速查找,由于索引中按关键词的字典序进行排序,从而使该索引支持快速的二分查找,相比于海量的聊天语料内容而言,关键词的数量是微不足道的,检索这些关键词花费的时间是毫秒级的。所以,将常用聊天模板中的实体构成这些关键词排序后,就能实现高效快速的规则匹配了。
即在本发明的技术方案中通过采用单纯的提取关键词技术,再使用关键词检索的方案,实现了开放域聊天,同时采用基于规则化、基于检索和基于关键词的搜索引擎三种技术方案并行的方式,实现了聊天问答的准确性和半开放性。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!