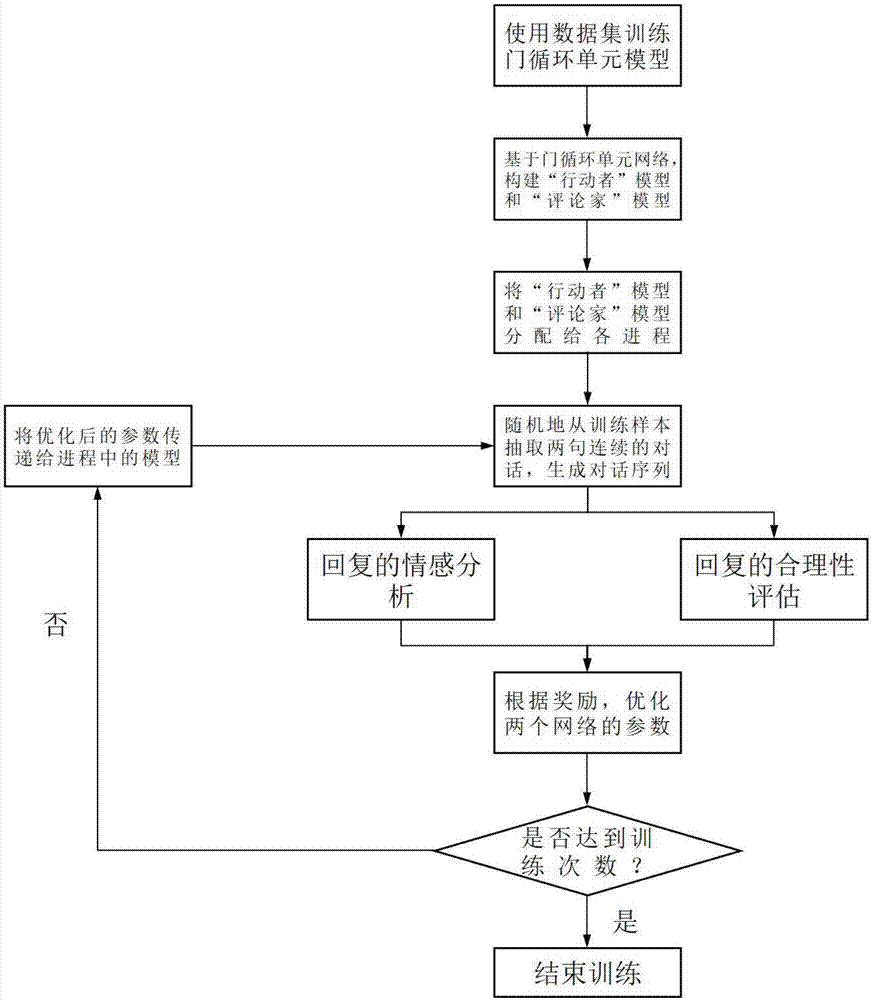
基于行动者评论家强化学习算法的循环网络人机对话方法与流程
本发明涉及人机对话方法,特别是涉及基于行动者评论家强化学习算法的循环网络人机对话方法。
背景技术:
随着科学技术的发展,自然语言处理领域不断涌现新的成果,其中人机对话技术的发展尤为令人瞩目。目前,如电子商务领域,人与人主要是通过在线聊天的方式进行交流。对于店主来说,来自顾客的咨询、售后信息大多是重复的。另外,对于一些较大的店铺,店主往往需要雇佣客服,这无疑会增加营业成本。对顾客来说,他们希望店主能够尽快、得体的回复。人机对话系统可以完成客服的工作,降低企业的运营成本,减少顾客的等待时间。所以,人机对话系统具有非常重要的使用价值和实际意义。
门循环单元(gaterecurrentunit,gru)是循环神经网络(recurrentneuralnetwork,rnn)的一种。和长短时记忆结构(longshorttermmemory,lstm)一样,门循环单元网络也是为了解决长期记忆和反向传播中的梯度问题而被提出来的。门循环单元网络和长短时记忆网络在很多情况下实际性能相差无几,但门循环单元网络的计算效率比长短时记忆网络更好。更具体地说,门循环单元网络虽然和长短时记忆网络都是基于门限机制的深度学习模型,但是长短时记忆网络需要对三个门(输入门、遗忘门和输出门)进行计算,而门循环单元网络只需要对两个门(更新门和重置门)进行计算。门循环单元网络的这一改进,降低了深度学习模型的复杂度。所以,在本发明中,我们基于门循环单元网络来构建对话生成系统。
卷积神经网络(convolutionalneuralnetwork,cnn)是另一种人工智能算法。与长短时记忆网络相比,卷积神经网络可以无偏地确定文本中的关键词,进而可以更好地捕获文本的语义。因此,越来越多的研究者开始关注如何将卷积神经网络应用在自然语言处理领域。
强化学习是试错学习。它反映的是如何根据环境选择合适的行为,以使累计奖励最大。强化学习的研究在近几年取得了很大的突破,其中的典型代表是deepmind的alphago。alphago和其升级版的alphagozero在围棋比赛中分别战胜专业对手,完成了历史性的突破。除在人机博弈领域的应用外,强化学习也开始逐渐应用到自然语言处理领域,在人机对话方面取得了不错的成绩,其中的代表是基于策略搜索的深度强化学习。基于策略搜索的深度强化学习能够在较少的计算资源下,快速找到最优的回复,提升了用户体验。
技术实现要素:
基于此,有必要针对上述技术问题,提供一种基于行动者评论家强化学习算法的循环网络人机对话方法,
一种基于行动者评论家强化学习算法的循环网络人机对话方法,包括:
s1:使用开源数据集对门循环单元网络进行有监督训练,获得一个次优的对话生成模型;
s2:基于从s1获得的门循环单元网络模型,建立了两个网络,分别称之为“行动者”网络和“评论家”网络;将这一对模型分配给多个进程,让它们不断生成新的对话;根据它们生成的对话所能获得的奖励来进一步地调整网络参数;
s3:使用基于卷积的深度网络模型对s2生成的回答进行情感分析;为了处理句子之间的依赖关系,在基本的卷积神经网络结构上,在模型中添加了门循环单元层;使用这样的深度模型来判断s2生成的答复是否是积极向上的。
s4:根据输入的问题,从三个方面来评估s2生成的回答的合理性,即:回答是否是有意义的、回答是否陷入循环以及生成的回答与我们期望的回答是否一致;
s5:根据s3和s4的结果,如果在s2阶段生成的回复是乐观、合理的,则提升该回复出现的概率;否则,应降低该回复出现的概率。
上述基于行动者评论家强化学习算法的循环网络人机对话方法,本发明在输入样本集后,便可自动地进行模型参数的调整,不需要人为的干预,所以具有很高的使用价值;目前服务器的计算能力完全能够满足本发明的需要,所以具有很强的可行性和推广性;此网络可以通过不断训练来调整、优化参数,对于新的业务场景,只需将相关样本加入到训练集中,再次重新训练网络,即可完成系统的升级,所以具有持续使用性;可以全天候运行,保证了服务质量;可以节省人力资源,减轻工作人员的压力;由于机器反应迅速,可以减少用户的等待时间。综上,此发明具有非常大的使用价值和实际意义;本发明在借鉴经典的人机对话算法的同时,融合了强化学习理论和深度学习方面的专业知识,有针对性的完成改进,进行创新,最终完成本发明。人机对话系统作为自然语言处理领域的一个分支,输入的是问题,期望输出积极、合理的回复。
在另外的一个实施例中,“s1:使用开源数据集对门循环单元网络进行有监督训练,获得一个次优的对话生成模型;”具体包括:
通过监督学习的方式、使用opensubtitles数据集训练一个答复生成模型mseq2seq。该网络共有九层,前八层都是门循环单元层(gaterecurrentunitlayer),各层的隐藏单元数目分别为:1024,2048,4096,512,4096,256,1024,64;最后一层是全连接层,隐藏单元数为4096,激活函数为“softmax”函数;
需要对输入输出数据进行处理,转换成对应的特征向量;输入数据的向量化表示需要经过四步:基于glove词向量算法对句子进行分词操作;需要进行词干分析和词汇归并’通过词频-逆文档频率算法构建每个词的特征表示;将句子的特征向量hsentence等长地划分为100份,表示为[v0,v1,v2,...,v97,v98,v99];
输出向量的可读化需要经过三步:将向量序列[v0,v1,v2,...,v97,v98,v99]逐个输入到网络里,在经过编码——解码后,网络就会依次输出相应的向量表示[o0,o1,o2,…,o97,o98,o99];选择了一些常用的单词构成词典,词典的容量为4096,这与网络的输出向量维数是一致的;即,输出向量第i维的值表示词典第i个字出现在回复中的概率;按次序选择每个向量中值最大的元素对应的单词组成一句话,把这句话作为最终的输出st,并把整个序列中的每个向量的最大值的累乘近似地视为输出概率psentence;
即
在另外的一个实施例中,在时刻t,网络的训练(测试)流程为:首先,将历史对话的最后两句(st-2,st-1)的特征向量序列[v0,v1,v3,...,v97,v98,v99]作为答复生成模型mseq2seq的输入数据依次输入到网络后,网络就会输出对应的向量序列[o0,o1,o2,…,o97,o98,o99];然后,通过对输出向量序列进行映射、清洗后,得到所需的回复st。
在另外的一个实施例中,使用反向传播算法对网络参数进行更新;在此之前,需将目标句子starget中的每一个单词都映射为含有4096个元素的一维向量,映射方式为one-hot编码;即,除对应元素设为1外,其它所有元素设为0;如,“i”是词典的第一个单词,则“i”的one-hot编码为
在另外的一个实施例中,“s2:基于从s1获得的门循环单元网络模型,建立了两个网络,分别称之为“行动者”网络和“评论家”网络;将这一对模型分配给多个进程,让它们不断生成新的对话;根据它们生成的对话所能获得的奖励来进一步地调整网络参数;”具体包括:
新建两个模型,分别表示行动者模型mactor和评论家模型mcritic。行动者模型mactor的网络结构与s1的答复生成模型mseq2seq的网络结构一致,模型mactor的参数初始值亦与收敛后的mseq2seq的参数值相同;与模型mactor类似,评论家模型mcritic也是一个九层的网络,其前八层的结构、参数值与收敛后的mseq2seq的结构、参数值完全一致;不同的是,模型mcritic的输出层是一个隐藏单元数为1的全连接层,无激活函数,参数按照标准正态分布被随机初始化。从两个模型的结构及参数的初始化可以看出,行动者模型mactor的作用与s1中的答复生成模型mseq2seq的作用一样,都是根据给定的输入生成相应的答复;而评论家模型mcritic的网络输出是一个实数,表示在给定输入状态及当前策略π下,在未来收获的期望回报v(s);
创建了8个进程;每一个进程都有一对独立的行动者和评论家;其中有7个进程被称为“作家”,表示为[w0,w1,…,w5,w6];剩下的一个进程被称为“编辑”,表示为editor;
其中,“编辑”进程的具体实施方案为:
“编辑”进程不断查询信息队列是否为空;如果信息队列为空,则等待;如果信息队列不为空,则按照先进先出的原则,取出第i个工作进程提交的信息——累加梯度dθi,a和dθi,c;
使用adam算法优化“编辑”进程中的行动者网络参数dθa和评论家网络参数dθc;
将优化后的网络参数dθa和dθc复制给进程i的对应网络;
“唤醒”进程i,使它生成新的对话;
在完成7168次参数更新后,终止本进程的训练;
“作家”进程的具体实施方案为:
从训练样本随机地抽取连续的两句话,将这两句话用s0和s1来表示;
将s0和s1输入到行动者网络mactor中,得到答复s2;
根据预定义的奖励函数,求解在s0和s1下采取动作s2所能获得的奖励r2;
将s1和s2输入到网络中,得到答复s3;依次类推,重复执行“将s0和s1输入到行动者网络mactor中,得到答复s2;”和“根据预定义的奖励函数,求解在s0和s1下采取动作s2所能获得的奖励r2;”,直到奖励rt<-10;
从后向前累加“行动者”网络和“批评家”网络在整段对话上的梯度dθi,a和dθi,c;
将累加梯度dθi,a和dθi,c提交到“编辑”进程的信息队列后,暂停活动,等待“编辑”进程的“唤醒”;在完成1024局对话后,终止本进程的训练。
在另外的一个实施例中,“s3:使用基于卷积的深度网络模型对s2生成的回答进行情感分析;为了处理句子之间的依赖关系,在基本的卷积神经网络结构上,在模型中添加了门循环单元层;使用这样的深度模型来判断s2生成的答复是否是积极向上的。”具体包括:
使用基于卷积的深度神经网络来对句子进行情感分析,判断其是否是乐观的;深度模型的输入是s2阶段行动者模型mactor的输入数据(st-2,st-1)和对应的回复st,输出维数为5的向量;输出向量的每一维依次对应5种不同的判定类型:非常消极、消极、中立、积极和非常积极,每一维的值表示该回复属于此类结果的概率;选最大概率值对应的类型作为最终结果;如果出现不同维度的值相等的情况,则选择该值第一次出现的维度对应的类型作为最终结果;
文本向量化的流程为:
构建字符表;对于字符表未包含的字符,将其忽略。字符表共包含100个字符,如下所示:
abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz
0123456789-,;.!?:”’∧|_@#$%^&*~‘+-=<>()[]{}§¨...—
字符编码;使用one-hot算法将字符表中的字符向量化;
将前512个字符的编码拼接起来,构成大小为512×100的矩阵;如果卷积神经网络的输入数据没有512个单词,我们就用占位符来代替,占位符的独热编码为
在卷积神经网络中添加了门循环单元层。改进后的卷积神经网络共有9层;其中,网络的前6层是滑动步长为1的卷积层,后2层是门循环单元层,最后一层数全连接层;此外在每次卷积后,还需要进行最大池化操作,池化的范围都是2×2,滑动步长都为1;其它参数的设置如下:
第一、二层的卷积核大小是3×3,个数有7个,激活函数为“relu”;第三到第六层的卷积核大小是2×2,个数有3个,激活函数为“relu”;门循环单元层(第七层、第八层)的单元数都是64、512,激活函数为“tanh”;全连接层的单元数为5,激活函数为“softmax”;
根据判定类别及对应的概率来求得回复在s3阶段得到的奖励,为:
其中,p为概率,x∈{0,1,2,3,4}为概率对应的维数。
在另外的一个实施例中,“s4:根据输入的问题,从三个方面来评估s2生成的回答的合理性,即:回答是否是有意义的、回答是否陷入循环以及生成的回答与我们期望的回答是否一致;”具体包括:
判断输出st是否有意义;构建了一张关于句子含义是模棱两可的列表s。我们求解回复与表中每个元素的相似度,并对其累加,作为整个奖励的一部分。计算公式为:
其中,hs和
然后,判断对话是否陷入循环;需要分析st-2、st-1和st之间的相似度。这项指标的奖励函数为:
r2=max(ln(1-f),-64)
分析生成的回复st是否遵循了“标准答案”starget;基于交叉熵损失函数,这一部分的奖励函数被定义为:
回复st(动作)在输入状态(st-2,st-1)下的奖励由上述三个评价标准的加权和构成,即:
rs4(st|st-2,st-1)=λ1r1+λ2r2+λ3r3
其中,λ1=0.4,λ2=0.4,λ3=0.2。
在另外的一个实施例中,“s5:根据s3和s4的结果,如果在s2阶段生成的回复是乐观、合理的,则提升该回复出现的概率;否则,应降低该回复出现的概率。”中,回复st在输入(st-2,st-1)下的最终奖励为:
其中,rs3表示s3阶段对该回复的奖励,rs4表示s4阶段给出的奖励。
上式表明,如果rs3≤-5,即mactor有很大的概率生成了消极性的回复,则最终奖励设为rs3×10;否则,最终奖励通过对rs3和rs4加权求和得到;这里,设ω1=0.4,ω2=0.6。
在求得最终奖励rfinal(st|st-2,st-1)后,把最终奖励反馈给s2,让s2的行动者网络mactor和评论家网络mcritic进行下一步地处理。
一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现任一项所述方法的步骤。
一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现任一项所述方法的步骤。
一种处理器,所述处理器用于运行程序,其中,所述程序运行时执行任一项所述的方法。
附图说明
图1为本申请实施例提供的一种基于行动者评论家强化学习算法的循环网络人机对话方法的整体流程图。
图2为本申请实施例提供的一种基于行动者评论家强化学习算法的循环网络人机对话方法中的的s1阶段流程图。
图3为本申请实施例提供的一种基于行动者评论家强化学习算法的循环网络人机对话方法中的s2“编辑”进程与“工作”进程的关系示意图。
图4为本申请实施例提供的一种基于行动者评论家强化学习算法的循环网络人机对话方法中的s3基于卷积的深度神经网络示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
参阅图1到图4:
s1:有监督的模型训练。我们使用开源数据集对门循环单元网络进行有监督训练,获得一个较优的对话生成模型。
s2:异步模型训练。基于从s1获得的门循环单元网络模型,我们建立了两个网络,分别称之为“行动者”网络和“评论家”网络。我们将这一对模型分配给多个进程,让它们不断生成新的对话。我们根据它们生成的对话来进一步地调整网络参数。
s3:回复的情感分析。我们使用基于卷积的深度网络模型对s2生成的回答进行情感分析。为了处理句子之间的依赖关系,在基本的卷积神经网络结构上,我们在模型中添加了门循环单元层。我们使用这样的深度模型来判断s2生成的答复是否是积极向上的。
s4:回复的合理性评估。根据输入的问题,我们从三个方面来评估s2生成的回答的合理性,即:回答是否是有意义的、回答是否陷入循环以及生成的回答与我们期望的回答是否一致。
s5:确定最终奖励。根据s3和s4的结果,如果在s2阶段生成的回复是乐观、合理的,则提升该回复出现的概率;否则,应降低该回复出现的概率。
在s1中,我们通过监督学习的方式、使用opensubtitles数据集训练一个答复生成模型mseq2seq。该网络共有九层,前八层都是门循环单元层(gaterecurrentunitlayer),各层的隐藏单元数目分别为:1024,2048,4096,512,4096,256,1024,64。最后一层是全连接层,隐藏单元数为4096,激活函数为“softmax”函数。
由于人类的语言无法直接被计算机处理,因此我们需要对输入输出数据进行处理,转换成对应的特征向量。输入数据的向量化表示需要经过四步:首先,我们基于glove词向量算法对句子进行分词操作。分词是将句子划分成多个词向量。如句子——“helloworld”,经过分词后变成两个词:“hello”、“world”。然后,为了减少数据量和提高数据的利用率,我们需要进行词干分析和词汇归并。如“interest”和“interesting”这样的词将被转换成相同的词——“interest”。其次,我们通过词频-逆文档频率算法构建每个词的特征表示。即,我们统计每个词在句子中出现的次数作为词频,然后把所有词的词频作为这个句子的特征向量。这样,我们就将长度不等的句子转换成表示唯一、维数相同的特征向量hsentence。最后,为了避免输入数据过大导致网络难以训练的问题,又为了让网络能够更好地学习到句子之间的依赖关系,我们将句子的特征向量hsentence等长地划分为100份,表示为[v0,v1,v2,...,v97,v98,v99]。我们使用python的nltk库完成了上述工作。
输出向量的可读化需要经过三步:首先,我们将向量序列[v0,v1,v2,...,v97,v98,v99]逐个输入到网络里,在经过编码——解码后,网络就会依次输出相应的向量表示[o0,o1,o2,...,o97,o98,o99]。然后,为了能方便地将网络输出的向量序列转换为可被人类识别的文字,我们选择了一些常用的单词构成词典,词典的容量为4096,这与网络的输出向量维数是一致的。即,输出向量第i维的值表示词典第i个字出现在回复中的概率。我们按次序选择每个向量中值最大的元素对应的单词组成一句话,把这句话作为最终的输出st,并把整个序列中的每个向量的最大值的累乘近似地视为输出概率psentence。
即
进一步地,在时刻t,网络的训练(测试)流程为:首先,将历史对话的最后两句(st-2,st-1)的特征向量序列[v0,v1,v3,...,v97,v98,v99]作为答复生成模型mseq2seq的输入数据依次输入到网络后,网络就会输出对应的向量序列[o0,o1,o2,…,o97,o98,o99]。然后,通过对输出向量序列进行映射、清洗后,我们就得到所需的回复st。图2给出了上述工作(文本的向量化、网络的训练(测试)流程以及输出向量序列可读化)之间的联系。
进一步地,我们使用反向传播算法对网络参数进行更新。在此之前,我们需将目标句子starget中的每一个单词都映射为含有4096个元素的一维向量,映射方式为one-hot编码。即,除对应元素设为1外,其它所有元素设为0。如,“i”是词典的第一个单词,则“i”的one-hot编码为
在s2中,我们使用强化学习算法来进一步对模型mseq2seq的参数进行优化。在本阶段中,我们将输出的动作(回复)看作是策略(模型)对当前状态(历史对话)的映射,在当前状态下采取该动作的好坏以奖励的方式被反应出来。强化学习的一些基本概念解释如下:
策略π:策略π是从状态到动作的映射。在本发明中,策略是由网络的参数集合来定义的;
状态s:状态s是对当前环境的抽象表示。在本发明中,状态被定义为历史对话的最后两句话(st-2,st-1)。进一步地,我们把由(st-2,st-1)变换而来的向量序列输入到策略模型中;
动作a:动作a是在当前状态下可以被执行的操作集合,不同的动作可能会导致不同的状态。在本发明中,动作被定义为策略模型的输出。由于生成回复的长度可能是任意的,因此动作空间是无界的;
折扣因子γ:折扣因子γ表示我们对未来奖励的看重程度。在本发明中,γ被设为0.75;
奖励r:奖励r是环境对在当前状态下采取某个动作的评价。带有折扣因子的累积奖励之和被称为回报,用r表示。在本发明中,奖励被视为用户体验。奖励越高,用户体验越好。强化学习的目标是使未来的累积期望奖励最大,即用户体验最好。我们从四个方面来判定奖励的大小:回答是否是积极向上的、问题是否易于回答、回答是否包含足够的信息、回答是否与问题相关。其中,回复的情感分析在s3阶段完成,其余评价标准的判定在s4阶段完成;
状态值v(s):状态值v(s)表示在当前策略π和当前状态s下,未来收获的期望奖励。在本发明中,v(s)≈mcritic(sj-2,sj-1;θ′i,c);
状态动作值q(s,a):状态动作值q(s,a)表示在当前策略π和当前状态s下,执行指定动作a在未来收获的期望奖励。在本发明中q(s,a)=r;
优势值a(s,a):优势值a(s,a)表示在当前策略π和当前状态s下,执行指定动作α比期望情况下要好多少。在本发明中,a(s,a)=r-mcritic(sj-2,sj-1;θ′i,c)。
在本阶段,我们的目标是进一步地优化答复生成模型mseq2seq的参数,以使累积期望奖励最大,或使期望优势值最小。为了加快训练速度、充分利用计算机资源,我们使用异步优势行动者评论家算法(asynchronousadvantageactor-critic,a3c)。该阶段的详细流程如下:
我们新建两个模型,分别表示行动者模型mactor和评论家模型mcritic。行动者模型mactor的网络结构与s1的答复生成模型mseq2seq的网络结构一致,模型mactor的参数初始值亦与收敛后的mseq2seq的参数值相同。与模型mactor类似,评论家模型mcritic也是一个九层的网络,其前八层的结构、参数值与收敛后的mseq2seq的结构、参数值完全一致。不同的是,模型mcritic的输出层是一个隐藏单元数为1的全连接层,无激活函数,参数按照标准正态分布被随机初始化。从两个模型的结构及参数的初始化可以看出,行动者模型mactor的作用与s1中的答复生成模型mseq2seq的作用一样,都是根据给定的输入生成相应的答复。而评论家模型mcritic的网络输出是一个实数,表示在给定输入状态及当前策略π下,在未来收获的期望回报v(s)。
我们创建了8个进程。每一个进程都有一对独立的行动者和评论家,其模型设置可见步骤1。其中有7个进程被称为“作家”,表示为[w0,w1,…,w5,w6]。剩下的一个进程被称为“编辑”,表示为editor。
“编辑”进程的具体实施方案为:
“编辑”进程不断查询信息队列是否为空。如果信息队列为空,则等待;如果信息队列不为空,则按照先进先出的原则,取出第i个工作进程提交的信息——累加梯度dθi,a和dθi,c;
使用adam算法优化“编辑”进程中的行动者网络参数dθa和评论家网络参数dθc;
将优化后的网络参数dθa和dθc复制给进程i的对应网络;
“唤醒”进程i,使它生成新的对话;
在完成7168次参数更新后,终止本进程的训练。
“作家”进程的具体实施方案为:
从训练样本随机地抽取连续的两句话,我们将这两句话用s0和s1来表示;
将s0和s1输入到行动者网络mactor中,得到答复s2;
根据预定义的奖励函数,求解在s0和s1下采取动作s2所能获得的奖励r2。奖励函数的定义见s3、s4和s5;
将s1和s2输入到网络中,得到答复s3。依次类推,重复执行第2、3步,直到奖励rt<-10;
从后向前累加“行动者”网络和“批评家”网络在整段对话上的梯度dθi,a和dθi,c,具体算法见算法1;
将累加梯度dθi,a和dθi,c提交到“编辑”进程的信息队列后,暂停活动,等待“编辑”进程的“唤醒”;
在完成1024局对话后,终止本进程的训练。
图3是“编辑”和“作家”两者关系的示意图。深红色箭头表示“作家”进程将已求得的累积梯度发送至信息队列;深蓝色箭头表示“编辑”进程从信息队列中获取用于更新梯度的信息;紫色箭头表示“编辑进程”已使用“作家”进程提供的信息进一步地优化了参数,现将优化后的参数传递给提供信息的“作家”进程,并要求“作家”进程重新生成新的对话序列。
在算法1中,r表示回报;rj表示奖励;γ表示折扣因子;mactor(sj|sj-2,sj-1;θ′i,a)表示在参数集合θ′i,a下,输入状态(sj-2,sj-1)输出动作sj的概率;mcritic(sj-2,sj-1;θ′i,c)表示在在参数集合θ′i,c下,状态(sj-2,sj-1)的未来期望回报;r-mcritic(sj-2,sj-1;θi,c)被称为优势a(s,a),表示当前情况比期望情况好多少。
在s3中,我们使用基于卷积的深度神经网络来对句子进行情感分析,判断其是否是乐观的。深度模型的输入是s2阶段行动者模型mactor的输入数据(st-2,st-1)和对应的回复st,输出维数为5的向量。输出向量的每一维依次对应5种不同的判定类型:非常消极、消极、中立、积极和非常积极,每一维的值表示该回复属于此类结果的概率。如,输出向量[0.3,0.1,0.2,0.1,0.3],它表示该回复是非常消极或非常积极的概率是0.3,是中立的概率0.2,是消极或积极的概率是0.1。我们选最大概率值对应的类型作为最终结果。如果出现不同维度的值相等的情况,则选择该值第一次出现的维度对应的类型作为最终结果。如上例所示,非常消极或非常积极的概率都是0.3,我们选择非常消极作为最终结果。
与s1、s2相同,我们并不能直接把回复输入到网络中,需要对其进行预处理。在此阶段,我们没有采用s1中的文本向量化方法。主要是因为,卷积层虽然能够自动地提取出有价值的特征,但是它需要较大的数据集来训练。如果在s1中添加卷积层,那么神经网络就可能不会收敛,影响最后的性能。所以在s1阶段,我们采用复杂的文本映射算法来对文本向量化。但在s3阶段中,我们只是要解决相对简单的多分类问题,所以我们可以让神经网络自动地提取特征。这样的设计,在保证整个系统是最优的情况下,加快了训练速度,降低了对训练数据的需求。
文本向量化的流程为:
构建字符表。在本发明中,我们认为回复中的一些字符对于检测结果没有帮助。因此,对于字符表未包含的字符,我们将其忽略。字符表共包含100个字符,如下所示:
abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz
0123456789-,;.!?:”’∧|_@#$%^&*~‘+-=<>()[]{}§¨...—
字符编码。我们使用one-hot算法将字符表中的字符向量化。如
文本表示。在本发明中,我们将前512个字符的编码拼接起来,构成大小为512×100的矩阵。如果卷积神经网络的输入数据没有512个单词,我们就用占位符来代替,占位符的独热编码为
卷积神经网络能够从输入数据中提取出有价值的特征,但是它并不能处理句子之间的依赖关系。如图4所示,在本发明中,我们在卷积神经网络中添加了门循环单元层。改进后的卷积神经网络共有9层。其中,网络的前6层是滑动步长为1的卷积层,后2层是门循环单元层,最后一层数全连接层。此外在每次卷积后,还需要进行最大池化操作,池化的范围都是2×2,滑动步长都为1。其它参数的设置如下:
第一、二层的卷积核大小是3×3,个数有7个,激活函数为“relu”;第三到第六层的卷积核大小是2×2,个数有3个,激活函数为“relu”;门循环单元层(第七层、第八层)的单元数都是64、512,激活函数为“tanh”;全连接层的单元数为5,激活函数为“softmax”。
在本发明中,我们根据判定类别及对应的概率来求得回复在s3阶段得到的奖励,为:
其中,p为概率,x∈{0,1,2,3,4}为概率对应的维数。
在s4中,我们通过对s2阶段的输入(st-2,st-1)和输出st的分析,来对行动者网络mactor生成的回复进行评价,评价的标准有三个:输出st是否是有意义的、对话是否陷入循环以及输出st与“标准答案”starget(训练样本中的目标)是否接近。
我们首先判断输出st是否有意义。在真实情景下,行动者网络mactor生成的答复应该是有明确目的性的,这样可以避免过早地结束对话。在网络训练过程中,如果对一个问题的回复是“idon’tknow”、“allright”、“ok”这样的句子,那么我们就认为回复是敷衍的。基于上述考虑,我们手动构建了一张关于句子含义是模棱两可的列表
其中,hs和
然后,我们判断对话是否陷入循环。一个可能的对话序列是:
q:howoldareyou?
a:takeaguess.
q:16?
a:no.
q:18?
a:no,butitisclosetothecorrectanswer.
...
此时,我们认为对话已经陷入了循环。因为我们已从对话中获取不到任何有用的信息,或者与所获取的信息相比,我们消耗了过多的时间和资源。所以,我们需要分析st-2、st-1和st之间的相似度。这项指标的奖励函数为:
r2=max(ln(1-f),-64)
最后,我们需要分析生成的回复st是否遵循了“标准答案”starget。基于交叉熵损失函数,这一部分的奖励函数被定义为:
回复st(动作)在输入状态(st-2,st-1)下的奖励由上述三个评价标准的加权和构成,即:
rs4(st|st-2,st-1)=λ1r1+λ2r2+λ3r3
其中,λ1=0.4,λ2=0.4,λ3=0.2。
在s5中,我们需要根据s3和s4的结果,来判断行动者模型mactor生成的回复st是否合适。如果mactor生成的回复是积极乐观、合理的,则输出该回复,并增大该回复出现的概率;否则,应降低该回复出现的概率。
在本发明中,回复st在输入(st-2,st-1)下的最终奖励为:
其中,rs3表示s3阶段对该回复的奖励,rs4表示s4阶段给出的奖励。
上式表明,如果rs3≤-5,即我们认为mactor有很大的概率生成了消极性的回复,则最终奖励设为rs3×10;否则,最终奖励通过对rs3和rs4加权求和得到。这里,我们设ω1=0.4,ω2=0.6。
在求得最终奖励rfinal(st|st-2,st-1)后,我们把最终奖励反馈给s2,让s2的行动者网络mactor和评论家网络mcritic进行下一步地处理。
以上所述仅为本发明的实施例,并非因此限制发明的专利范围,凡是利用本发明说明书内容所作的等效结构或等效流程变换,或直接或间接运用在其它相关的技术领域,均同理包括在本发明的专利保护范围内。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!