一种基于深度多尺度神经网络的语义分割方法与流程
本发明属于深度学习和神经网络领域,特别涉及一种深度多尺度神经网络的语义分割方法。
背景技术:
深度学习(deeplearning,dl)近年迅速发展,已经广泛应用于计算机视觉(computervison,cv)和自然语言处理(naturallanguageprocessing,nlp)等领域。
在计算机视觉中,基于深度学习的卷积神经网络被广泛应用。语义分割是计算机视觉中的一个经典任务,我们需要将视觉输入分为不同的语义可解释类别,即分类类别在真实世界中是有意义的(语义的可解释性)。在自动驾驶的应用中,我们需要对车辆可行驶区域进行像素级的分割,这就要求我们的分割网络满足高精度和实时性。
现阶段领先的语义分割方法有fcn[1],segnet[2]和deeplab[3-6]系列。fcn是一种端到端的神经网络结构,它将传统卷积神经网络的全连接层用卷积层代替,这种方法在一定程度上提高了网络性能但对图像细节处理不好。segnet是一种编解码的网络结构,它将传统卷积神经网络的全连接层用上采样代替,最终的softmax层输出每个像素点的概率。deeplab系列算法是当前最先进的语义分割算法,通过采用膨胀卷积,多尺度和条件随机场等方法大大提高了神经网络的性能。
现阶段的已有的语义分割算法引入多尺度的概念,从不同语义层级对图像进行处理,在一定程度上提高了网络的性能,但这些算法没有考虑这些语义层级间的关系。本发明提出了一种基于深度多尺度神经网络的语义分割方法,通过深度跨链接操作将不同语义层级联合并加以处理
[1]longj,shelhamere,darrellt.fullyconvolutionalnetworksforsemanticsegmentation[c]//computervisionandpatternrecognition.ieee,2015:3431-3440.
[2]badrinarayananv,kendalla,cipollar.segnet:adeepconvolutionalencoder-decoderarchitectureforscenesegmentation.[j].ieeetransactionsonpatternanalysis&machineintelligence,2017,pp(99):2481-2495.
[3]chenlc,papandreoug,kokkinosi,etal.semanticimagesegmentationwithdeepconvolutionalnetsandfullyconnectedcrfs[j].computerscience,2014(4):357-361.
[4]chenlc,papandreoug,kokkinosi,etal.deeplab:semanticimagesegmentationwithdeepconvolutionalnets,atrousconvolution,andfullyconnectedcrfs.arxivpreprintarxiv:1606.00915,2016
[5]chenlc,papandreoug,schrofff,etal.rethinkingatrousconvolutionforsemanticimagesegmentation[j].2017.
[6]chenlc,yukunzhu,papandreoug,schrofff,etal.encoder-decoderwithatrousseparableconvolutionforsemanticimagesegmentation.arxivpreprintarxiv:1802.02611,2018.
技术实现要素:
本发明提出了一种基于深度多尺度神经网络的语义分割方法,采用深度连接膨胀卷积的神经网络结构,以加强不同语义层级的联系,达到提高网络性能的目的。技术方案如下:
一种基于深度多尺度神经网络的语义分割方法,包括下列步骤:
1)收集包含各种不同类别物体的图像,并标注每张图像中的所有感兴趣物体,标注内容每个像素点的所属物体类别,以其作为图像标签信息;
2)图像集划分;将收集的图像划分为训练集,验证集和测试集,训练集用于训练卷积神经网络,验证集用于选择最佳的训练模型,测试集为后续测试模型效果或者实际应用时使用;
3)设计基于深度多尺度神经网络结构,用以有效实现物体检测,包括:
①设计主干网络;
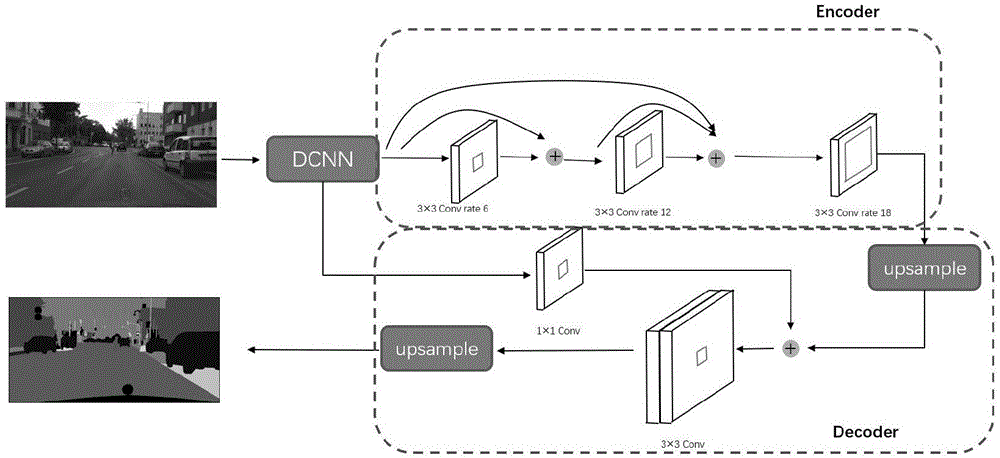
②设计语义分割网络:语义分割网络由三个3×3的卷积神经网络串联而成,采用bottleneck的结构,在每个3×3的卷积层前后分别加1×1的卷积层,前边的用来提高特征图的通道数,后边的用来降低特征图的通道数,采用dense结构连接3×3卷积层;
③设计解码网络:将语义分割网络的输出上采样,与主干网络中的低层级语义特征相加后通过一个3×3的卷积层再上采样,得到最终的分割结果;
④选择合适的损失函数,设置训练迭代次数,初始化参数;
4)输入数据,前向计算预测结果和损失代价,通过反向传播算法计算参数的梯度并更新参数;迭代的更新参数,待代价函数曲线收敛时,模型训练完毕;
5)将训练好的模型应用于测试或实际应用中,当输入图像时,通过该模型可以计算得到图像语义分割结果,辅助实际应用场景中的决策。
本发明网络包含编码结构和解码结构两个部分。在编码结构中,本发明采用三个不同膨胀率的膨胀卷积来获取不同尺度的特征图。为了进一步加强不同尺度的联系,本发明采用了深度跨连接结构。某一个膨胀卷积层对所有比它尺度大的特征图进行卷积操作。在解码结构中,本发明将低层语义的特征图和高层语义的特征图相结合,进一步提高了网络对图像细节的处理能力。另外在每个膨胀卷积层前后,本发明通过引入1×1的卷积层来改变通道数,以达到减少计算量的目的,使网络更容易训练。本发明所述的方法实现简单,在保证效率的同时,大大提高了语义分割的精度,对图像细节也能进行较好的处理。
附图说明
图1深度多尺度神经网络结构
图2bottleneck结构
图3自动驾驶系统
具体实施方式
下面将以自动驾驶为例对本发明的技术方案进行描述,显然自动驾驶只是本发明的一个应用场景,本发明同样适用于其他语义分割场景。
在自动驾驶中,需要从摄像头得到的图像中分割出人行道和汽车的可行驶区域,当紧急情况发生时,要求系统能快速做出反应,这就要求我们的方法需同时兼顾准确率和速度。
将本发明应用于实际语义分割任务中,包含三个步骤:准备数据集;设计并训练网络;测试训练模型。具体步骤描述如下:
第一步:准备训练所用的数据集.
1)选定合适的语义分割数据集。数据集包含图片和标注,标注为像素级的分类标注。
2)处理数据集。将数据集分为训练数据集,验证数据集和测试数据集。训练数据集用来训练模型,验证数据集用来调节网络结构和调整模型参数,测试数据集用来评价模型的最终性能。
3)数据增强。为了进一步提高模型的分割精度,可对训练数据集采用随机翻转,随机裁剪,随机缩放等方法。
第二步:设计基于深度多尺度的神经网络以适用于语义分割。
⑤设计主干网络。主干网络主要由多个卷基层、池化层、非线性激活层等模块组成。为了可以利用imagenet上的初始化模型对网络进行初始化,本专利的主干网络选取经典的resnet。
⑥设计语义分割网络。网络由三个3×3的卷积神经网络串联而成,为了提高网络性能而又不增加计算量,本发明采用bottleneck的结构,在每个3×3的卷积层前后分别加1×1的卷积层,前边的用来提高特征图的通道数,后边的用来降低特征图的通道数(见图2)。为了获得更加稠密的上下文信息,本发明采用dense结构连接3×3卷积层。
⑦设计解码网络。将语义分割网络的输出上采样,与主干网络中的低层级语义特征相加后通过一个3×3的卷积层再上采样,得到最终的分割结果。
⑧选择合适的损失函数,设置训练迭代次数,初始化参数。
第三步:训练本发明的基于深度多尺度神经网络用于语义分割
将训练数据批量输入神经网络,具体步骤如下:
a)将训练数据从主干网络输入,进行前向传播。
b)计算损失函数并反向传播,采用梯度下降法更新网络权重。
c)循环a)和b)的操作,损失函数收敛,得到训练好的权重。
第四步:将训练好的模型应用于测试或者实际应用中
1)测试集:将测试集图像输入网络,得到语义分割结果和测试集的标注比较,计算出miou,评价模型的好坏。
2)实际应用:将摄像头获取的视频或之前保存的实际视频输入网络,得出语义分割的结果。
为了验证本发明的效果,我们对比当前效果较好的fcn,segnet和deeplab,实验数据为在语义分割中广泛使用的pascalvoc2012数据集。表1给出了对比实验结果。
表1对比实验结果
- 还没有人留言评论。精彩留言会获得点赞!