一种基于生成式对抗网络的书法字体自动生成算法的制作方法
本发明属于深度学习领域,具体涉及一种基于生成式对抗网络的书法字体自动生成算法。
背景技术:
在计算机中输入一个汉字,选择需要转换的书法风格,最终的效果是输出对应风格的书法字体,比如输入一个正楷字“张”,选择王羲之字体风格,输出带有王羲之字体风格的“张”字。
现有的字体风格转换方法是,首先输入需要转换字体风格的汉字,比如‘张’,然后通过索引对应的书法字体数据库,找到对应‘张’字的书法字体,最后输出。其中书法字体风格数据库是人工预先仿写某一书法风格的常用汉字,比如仿写王羲之风格的字体,之后扫描存入数据库。这一方法的缺点有:第一、只能转换预先已存入数据库的字的字体风格,如果遇到没有录入的字体风格,只能输出原字体;第二、这种方法是人工仿写,并不能仿写出真正带有对应风格的字体(比如仿写王羲之字体);第三、保存书法字体需要占用较大内存空间。
生成式对抗网络(gan)在图像生成,图像编辑,表征学习等方面都取得了很好的结果。原始gan模型的主要目标是迫使判别模型d辅助生成模型g,产生与真实数据分布相似的伪数据,其中g和d一般为非线性映射函数,通常由多层感知机或卷积神经网络等网络结构来形式化。给定随机噪声变量z服从简单分布pz(z),生成模型g通过将z映射为g(z)隐式地定义了一个生成分布pg来拟合真实样本分布pdata。判别模型d作为一个二分类器,分别以真实样本x和生成样本g(z)作为输入,以一个标量值作为概率输出,表示d对于当前输入是真实数据还是生成的伪数据的置信度,以此来判断g生成数据的好坏。当输入为真实训练样本x~pdata时,d(x)期望输出高概率,当输入为生成样本g(z)时,d(g(z))期望输出低概率,而对于g来说要尽可能使d(g(z))输出高概率,让d无法区分真实数据和生成数据。两个模型交替训练,从而形成竞争与对抗,整个优化过程可以视为一个极小极大博弈。
cyclegan的方法建立在isola等人的pix2pix框架上,pix2pix使用cgan来学习从输入到输出的映射,但它依赖配对训练数据。cyclegan的创新点在于能够在源域和目标域之间,无须建立训练数据间一对一的映射,就可实现这种迁移。这种方法通过对原图像进行两步变换:首先将原图像映射到目标域,然后再从目标域返回原图像得到二次生成图像,从而消除了在目标域中图像配对的要求。使用生成器网络将图像映射到目标域,并且通过鉴别器(discriminator)提高该生成图像的质量。
技术实现要素:
本发明目的是提供一种基于生成式对抗网络的书法字体自动生成算法,可以将任意一个输入到训练好的神经网络中的汉字,均能输出带书法风格的字体。
本发明采取的技术方案是:
一种基于生成式对抗网络的书法字体自动生成算法,包括以下步骤:
一:搭建两个生成式对抗网络,各自的生成器分别为g和f,其中,g的鉴别器为dy,f的鉴别器为dx;
二:分别从印刷字体数据集x和书法字体数据集y中提取minibatch(梯度下降),并分别送入g和f中生成对应的书法字体图像g(x)、印刷字体图像f(y),再分别由dy、dx鉴别生成图像为真的概率并计算损失函数,优化网络参数;
三:将g(x)输入到f中、f(y)输入到g中,经过卷积、反卷积之后输出生成的印刷体图像f(g(x)),书法图像g(f(y)),再由dy,dx鉴别图像真伪、计算损失,调整参数;
四:重复步骤一到步骤三,直至网络收敛或达到迭代次数。
本发明的有益效果:
本发明将gan的研究延伸到了中国书法领域,通过收集大量书法字体真迹作为样本,运用收集到的样本训练深度神经网络,使神经网络学习书法字体的书法风格,比如王羲之字体风格,学习到书法字体风格后,保存该神经网络模型,之后任何汉字都能通过该神经网络,输出对应的书法风格字体。
相对于现有技术,该方法在四个方面的改进:第一、任何汉字都可以转换成对应风格的字体,不再有限制;第二、节省了人力和时间,不再需要人工仿写大量的字体,以及扫描这些字体存入数据库;第三、因为转换风格的神经网络是直接提取原风格字体的风格,所以能保证输出书法字体的风格是真正需要转换的风格,第四、只需要保存一个训练好的神经网络模型,不占用大量内存。
附图说明
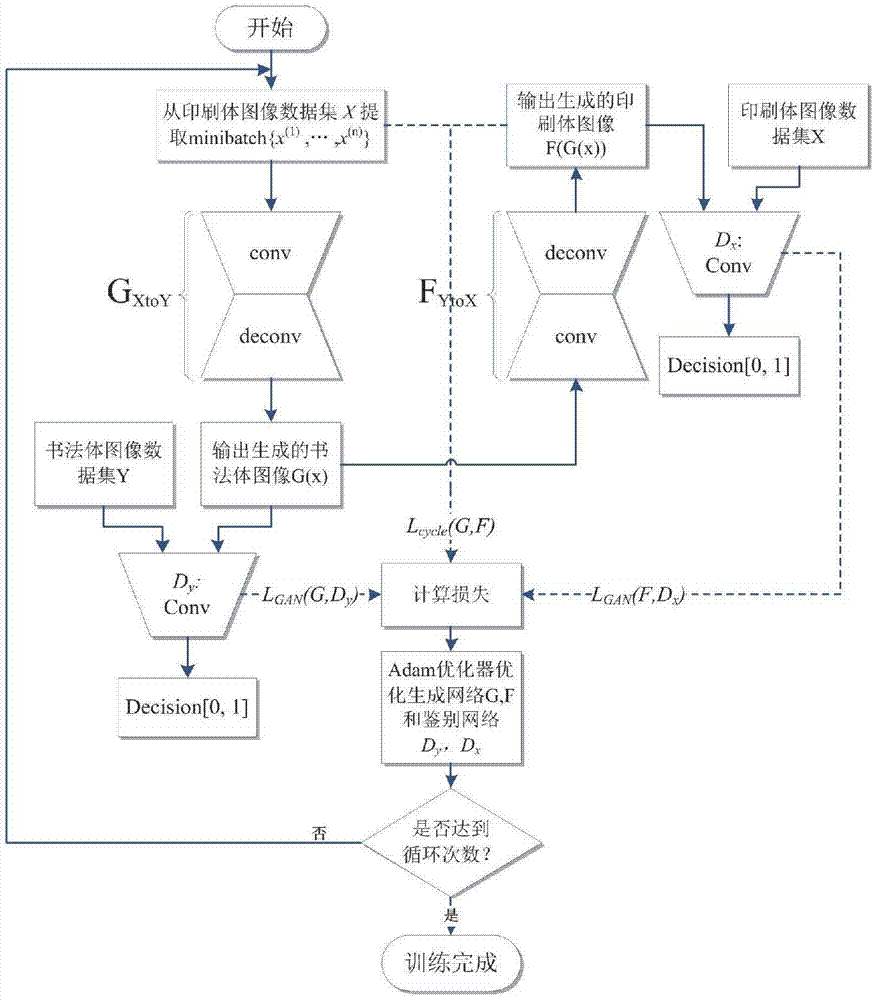
图1是本发明算法的训练流程图;
图2是本发明实施例算法结果输出图。
具体实施方式
本实施例在ubuntu16.04平台上由torch7编程实现,处理器为intelcorei7-6700,3.4ghz,8核cpu,内存为16g,显卡为nvidiageforcegtx1060,显存3g。
本实施例以正楷汉字图像为印刷体图像数据集
具体过程包括以下步骤,如图1所示:
步骤一:构建两个生成式对抗网络,他们的生成器分别为g和f,鉴别器分别为dy、dx;
步骤二:分别从印刷体图像数据集x提取minibatch{x(1),…,x(n)},从书法图像数据集y提取minibatch{y(1),…,y(m)},将x(i)送入g中,经过卷积、反卷积之后输出生成的书法字体图像g(x);提取minibatch实际上就是每迭代训练一次从数据集x中都提取一小部分数据进行训练,每次提取的数据是随机从x里面取得;
步骤三:利用公式(1)计算上一步中生成器g的损失:
步骤四:将g(x)与书法图像y(j)∈minibatch{y(1),…,y(m)}输入到鉴别器网络dy中鉴别图像真伪,若图像鉴别为真,鉴别器输出接近1的概率,反之输出接近0的概率;
步骤四:利用公式(2)计算鉴别器dy的损失,求得损失后使用adam优化器优化更新鉴别器dy的网络参数;
步骤五:将g(x)输入到生成网络f中,经过卷积,反卷积之后输出生成的印刷体图像f(g(x));
步骤六:采用公式(3)计算生成器f的损失,并利用adam优化更新其参数:
步骤七:将f(g(x))与印刷字体图像x(i)∈minibatch{x(1),…,x(n)}输入到鉴别器网络dx中鉴别真伪,若图像鉴别为真,鉴别器输出接近1的概率,反之输出接近0的概率;
步骤八:采用公式(4)计算鉴别器dx的损失,求得损失后使用adam优化器优化更新鉴别器dx的网络参数;
步骤九:采用公式(5)计算循环一致损失,公式(1)与公式(5)之和为生成器g总损失,总损失求得该损失后利用adam优化器,优化更新生成器g的网络参数;
步骤十:判断是否达到迭代次数,没达到的话重复步骤一至步骤九。
在图2中,(a)输入正楷字体“暮”,通过生成器g生成王羲之书法风格字体,再通过生成器f还原回正楷字体;(b)输入王羲之书法风格字体“懐”,通过生成器f生成正楷字体,再通过生成器g生成还原回王羲之书法字体,dx、dy分别判别正楷字体和王羲之书法字体的真伪。
- 还没有人留言评论。精彩留言会获得点赞!