Hadoop多管道数据处理分析方法与流程
本发明涉及数据处理技术领域,具体涉及一种hadoop多管道数据处理分析方法。
背景技术:
hadoop是一个由apache基金会所开发的分布式系统基础架构。hadoop实现了一个分布式文件系统,有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(highthroughput)来访问应用程序的数据,适合那些有着超大数据集(largedataset)的应用程序。hadoop分布式文件系统可以以流的形式访问(streamingaccess)文件系统中的数据。
hadoop由apachesoftwarefoundation公司于2005年秋天作为lucene的子项目nutch的一部分正式引入。它受到最先由googielab开发的map/reduce和googlefilesystem(gfs)的启发。
hadoop原本来自于谷歌一款名为mapreduce的编程模型包。谷歌的mapreduce框架可以把一个应用程序分解为许多并行计算指令,跨大量的计算节点运行非常巨大的数据集。使用该框架的一个典型例子就是在网络数据上运行的搜索算法。hadoop最初只与网页索引有关,迅速发展成为分析大数据的领先平台。
hadoop得以在大数据处理应用中广泛应用得益于其自身在数据提取、变形和加载(etl)方面上的天然优势。hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,对例如像etl这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。hadoop的mapreduce功能实现了将单个任务打碎,并将碎片任务(map)发送到多个节点上,之后再以单个数据集的形式加载(reduce)到数据仓库里。
hadoop设计之初的目标就定位于高可靠性、高可拓展性、高容错性和高效性,正是这些设计上与生俱来的优点,才使得hadoop一出现就受到众多大公司的青睐,同时也引起了研究界的普遍关注。到目前为止,hadoop技术在互联网领域已经得到了广泛的运用,例如,yahoo使用4000个节点的hadoop集群来支持广告系统和web搜索的研究;facebook使用1000个节点的集群运行hadoop,存储日志数据,支持其上的数据分析和机器学习;百度用hadoop处理每周200tb的数据,从而进行搜索日志分析和网页数据挖掘工作;中国移动研究院基于hadoop开发了″大云″(bigcloud)系统,不但用于相关数据分析,还对外提供服务;淘宝的hadoop系统用于存储并处理电子商务交易的相关数据。国内的高校和科研院所基于hadoop在数据存储、资源管理、作业调度、性能优化、系统高可用性和安全性方面进行研究,相关研究成果多以开源形式贡献给hadoop社区。
现有技术中hadoop分布式文件系统的文件是一次写入的,并且在任何时候都只有一个写入器。也就是说,hadoop分布式文件系统的文件支持一次写入多次读取,这意味着一旦写入信息,就无法修改,但可以多次读取。
技术实现要素:
为了克服现有技术中存在的问题,本发明提供一种hadoop多管道数据处理分析方法,该方法利用hadoop分布式文件系统来处理海量数据,通过hadoop用户端向命名节点发送附加命令,该附加命令具有标识要附加的现有文件的名称和要追加的数据的参数。本发明使用附加来写入文件,克服了现有技术中hadoop分布式文件系统一旦写入信息就无法修改的问题。
为实现上述目的,本发明提供一种hadoop多管道数据处理分析方法,该方法利用hadoop分布式文件系统来处理海量数据,所述的hadoop分布式文件系统包括用户节点、命名节点、块扫描模块和云端节点,所述的用户节点包括java虚拟机,所述的java虚拟机包括hadoop用户端,该hadoop用户端分别与分布式文件子系统和数据输出流交互;云端节点包括数据节点;hadoop用户端向命名节点发送具有参数的打开命令,该参数标识要读取的文件的名称;命名节点使用定位块数据结构响应hadoop用户端,该定位块数据结构包括存储的文件的所有命名节点的标识符和文件中所有块的块id;hadoop用户端通过为每个请求的块发送包含所请求块的块id,从所识别的数据节点直接请求文件的块;接收请求的数据节点使用所请求块的块id来访问它正在存储的相应块之一,并用所访问块的数据响应hadoop用户端;hadoop用户端向命名节点指示想要将数据块附加到现有文件;命名节点接收hadoop用户端发送的附加命令,该附加命令具有标识要附加的现有文件的名称和要追加的数据的参数。
优选地,所述的命名节点用定位块数据结构响应hadoop用户端,该定位块数据结构包括所有将数据块的副本附加到现有文件的数据节点标识符,hadoop用户端通过将包括数据块的id和数据的扩展块数据结构的一部分发送到所识别的数据节点,直接请求所识别的数据节点将数据块附加到现有文件。
进一步优选地,接收扩展块数据结构的数据节点使用所接收的扩展块数据结构中的数据块的id来访问现有文件的相应块和所接收的扩展块数据结构中的数据,以将数据写入所访问的块。
进一步优选地,所述的云端节点还包括文件放置优化模块,该文件放置优化模块使用户能够指定要访问的数据节点,并将数据分组为更大的块。
进一步优选地,所述的文件放置优化模块用于调整能够存储在单个数据节点或单个服务器上的数据量。
所述的块扫描模块扫描数据节点以寻找需要的文件,获得文件块的块位置,然后根据扫描内容填充元数据,从而使元数据反映块的位置和副本的数量。
进一步优选地,所述的块扫描模块获得数据节点的名称和数据块的地址,创建数据块的块id并将该块id存储在元数据中。
所述的块扫描模块从单个数据节点返回连续的块文件的位置,以向hadoop用户端提供该块文件被放置的错觉。
命名节点使用从块扫描模块接收的信息来更新块列表和每个块的每个副本的位置。
本发明具有如下优点:本发明所述的hadoop多管道数据处理分析方法与现有技术相比,采用hadoop分布式文件系统来处理海量数据,通过hadoop用户端向命名节点发送附加命令,该附加命令具有标识要附加的现有文件的名称和要追加的数据的参数。本发明使用附加来写入文件,克服了现有技术中hadoop分布式文件系统一旦写入信息就无法修改的问题。
附图说明
图1是本发明所述的服务器的整体结构示意图。
具体实施方式
以下实施例用于说明本发明,但不用来限制本发明的范围。
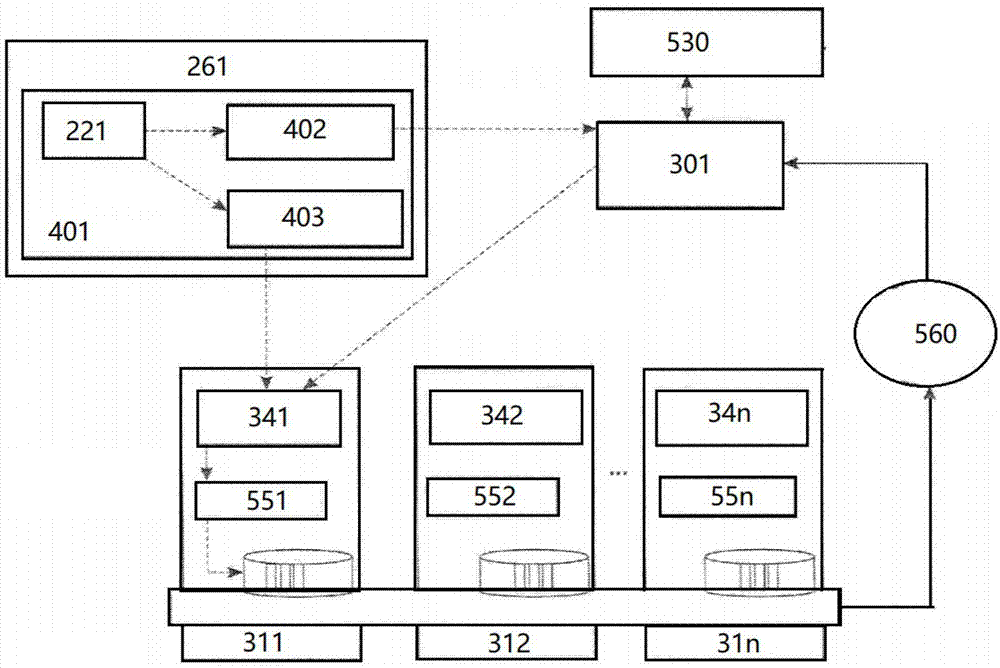
本发明提供一种hadoop多管道数据处理分析方法,该方法利用hadoop分布式文件系统来处理海量数据,如图1所示,所述的hadoop分布式文件系统包括用户节点261、命名节点301、块扫描模块560和云端节点(图1所示的实施例包括多个云端节点,即第一云端节点311、第二云端节点312......第n云端节点31n),所述的用户节点261包括java虚拟机401,所述的java虚拟机401包括hadoop用户端221,该hadoop用户端221分别与分布式文件子系统402和数据输出流403交互;云端节点包括数据节点(第一云端节点311包括第一数据节点341、第二云端节点312包括第二数据节点342......第n云端节点31n包括第n数据节点34n);hadoop用户端221向命名节点301发送具有参数的打开命令,该参数标识要读取的文件的名称;命名节点301使用定位块数据结构响应hadoop用户端,该定位块数据结构包括存储的文件的所有命名节点的标识符和文件中所有块的块id;hadoop用户端通过为每个请求的块发送包含所请求块的块id,从所识别的数据节点直接请求文件的块;接收请求的数据节点使用所请求块的块id来访问它正在存储的相应块之一,并用所访问块的数据响应hadoop用户端;hadoop用户端向命名节点指示想要将数据块附加到现有文件;命名节点接收hadoop用户端发送的附加命令,该附加命令具有标识要附加的现有文件的名称和要追加的数据的参数。
优选地,所述的命名节点301用定位块数据结构响应hadoop用户端221,该定位块数据结构包括所有将数据块的副本附加到现有文件的数据节点标识符,hadoop用户端221通过将包括数据块的id和数据的扩展块数据结构的一部分发送到所识别的数据节点,直接请求所识别的数据节点将数据块附加到现有文件。
进一步优选地,接收扩展块数据结构的数据节点使用所接收的扩展块数据结构中的数据块的id来访问现有文件的相应块和所接收的扩展块数据结构中的数据,以将数据写入所访问的块。
进一步优选地,所述的云端节点还包括文件放置优化模块(第一云端节点311包括第一文件放置优化模块551、第二云端节点312包括第二文件放置优化模块552......第n云端节点31n包括第n文件放置优化模块55n),该文件放置优化模块使用户能够指定要访问的数据节点,并将数据分组为更大的块。
进一步优选地,所述的文件放置优化模块用于调整能够存储在单个数据节点或单个服务器上的数据量。
所述的块扫描模块560扫描数据节点341-34n以寻找需要的文件,获得文件块的块位置,然后根据扫描内容填充元数据530,从而使元数据反映块的位置和副本的数量。
进一步优选地,所述的块扫描模块560获得数据节点的名称和数据块的地址,创建数据块的块id并将该块id存储在元数据530中。
所述的块扫描模块560从单个数据节点返回连续的块文件的位置,以向hadoop用户端221提供该块文件被放置的错觉。
命名节点301使用从块扫描模块560接收的信息来更新块列表和每个块的每个副本的位置。
虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!