基于OD数据感知城市动态结构演化规律的可视分析方法与流程
本发明属于信息技术领域,具体是一种基于od数据感知城市动态结构演化规律的可视分析方法。
背景技术:
感知城市动态,理解居民如何在城市中移动、他们的行为模式如何随着时间演化,是智慧城市建设必须解决的课题。传统的城市动态研究依赖于粗糙的统计数据和小范围的调查问卷,无法细粒度地从个体层面构建定量模型。随着无线通讯和移动互联网技术的快速发展,带来了丰富多样的具有个体标记和时空信息的数据集,为理解城市动态结构和人群活动模式提供了新的手段。一些具有od(origin-destination)属性的公共交通数据集,如公共自行车、公交车、出租车数据等,记录了个体时空移动信息,包括出行的起点/终点、起始/结束时间等,能用于挖掘城市动态结构。
lda(latentdirichletallocation)主题模型已被用于研究人类行为和城市模式。采用社交网络数据挖掘城市模式,个体轨迹采样频率较低、在数据代表性上有所欠缺。手机定位数据的用户位置通常由基站位置近似估算得到,精度有限。采用这两类数据只能提取城市中的热点区域,忽略了人群在区域之间的流动关系。ferrari等人基于谷歌位置数据集来发现用户的日常活动轨迹,但只能分析个体用户行为。chu等人将出租车轨迹的地理坐标转化为街道名字,将每辆出租车的轨迹看作一个文档,将转化后的街道名字看作是单词,来识别出租车轨迹中隐含的主题。提取得到的主题反映了重要街道的使用模式。他们的研究关注于街道在城市中的使用情况。
总的来说,现有的城市动态分析方法不仅缺乏对重要的流动关系和城市结构演化规律的分析,而且很难挖掘得到隐含在数据集背后的语义级别的信息。此外,数据挖掘的结果是一些复杂的数字,对于领域专家来说很难理解。因此需要设计一种可视分析方法,不仅能够从od数据集中提取隐含城市动态演化规律的主题信息,从语义层面上发现城市结构的时域变化,而且能够支持交互式地演化模式分析,基于多样化的视觉线索找到这些模式发生的原因。
技术实现要素:
为了解决现有技术中存在的上述技术问题,本发明的目的是从od数据集中挖掘得到城市动态结构的演化规律,设计基于主题模型的方法从语义层面发现城市动态结构,设计可视分析方法辅助分析者渐进式地理解演化模式,通过与丰富的可视化组件进行交互,找到促使这些模式发生的内在原因,有助于相关人员更好地进行交通管理和城市规划,促进智慧城市的构建。其具体技术方案如下:
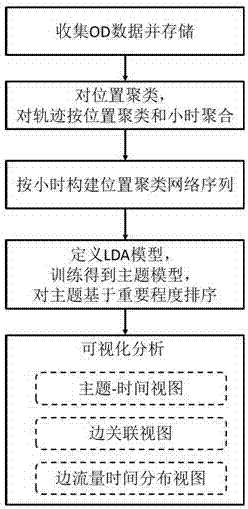
一种基于od数据感知城市动态结构演化规律的可视分析方法,包括如下步骤:
步骤1:收集od数据,并存储在数据库中;
步骤2:对位置进行聚类,对轨迹按位置聚类和小时聚合;
步骤3:按小时构建位置聚类网络序列,表征每小时内各个聚类间的流量关系;
步骤4:基于位置聚类网络序列,定义lda模型,训练得到主题模型,并对主题基于重要程度排序;
步骤5:设计主题-时间视图,可视化不同主题在每个位置网络中的概率分布,展示不同主题随着时间的演化特征;
步骤6:设计边关联视图,直观展示重要区域的空间分布和它们之间的流量关系;
步骤7:设计边流量时间分布视图,展示边关联视图中每条弧线在不同时间步下出现的概率。
进一步的,所述步骤1包括:
获取od数据集,并存储在轨迹记录表中,一条轨迹记录trajrec表示如下:
trajrec=[startloclong,startloclat,starttime,endloclong,endloclat,endtime]其中startloclong和startloclat为出发地点的经度和纬度,starttime为出发时间,endloclong和endtloclat为到达地点的经度和纬度,endtime为到达时间。
进一步的,所述步骤2包括:
步骤2.1:对所有位置进行聚类:假设locset={loclongi,loclati}(1≤i≤n)为包含所有出发地点和到达地点的位置集合,一共有n个位置点;loclongi和loclati为第i个位置点的经度和纬度;第i个位置点和第j个位置点之间的距离定义为:
步骤2.2:将轨迹按位置聚类和小时聚合,基于trajrec,以小时为单位统计某两个聚类间在单位时间内的人流量,并存储加速后续计算;聚合后的一条记录trajaggrrec表示为:
trajaggrrec=[startdate,starthour,startcluloc,endcluloc,flownum]
其中startdate表示出发日期,starthour表示出发小时,可以从startttme中提取得到;startcluloc和endcluloc表示出发和到达的位置聚类的id,flownum表示在某日(startdate)某小时(starthour)内,从startcluloc内出发到达endcluloc的人流量。
进一步的,所述步骤3包括:
按小时构建位置聚类网络序列,表征每小时内各个聚类间的流量关系;假设gτ=(clulocset,eτ)表示在时间步τ下的位置聚类网络,用一个图结构表示;其中位置聚类集合clulocset被看作是顶点集合,eτ为边集合。eijτ∈eτ表示在时间步τ内从cluloci出发到达clulocj的人流量,具体的值从trajaggrrec中查询得到;然后按小时构建位置聚类网络序列ns={g1,g2,...,gt},t为所有时间步的总数,由待分析的时间段内的日期数d决定,t=24×d。
进一步的,所述步骤4包括:
步骤4.1:基于位置聚类网络序列,定义lda模型;lda模型包含3层:文档、单词和主题;一篇文档是由一组单词构成的集合,所有的文档集构成了一个语料库;一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成;将每个时间步下的位置聚类网络gτ看作是一篇文档,从而位置聚类网络序列ns={g1,g2,...,gt}构成了一个语料库;将边集合eτ看作是一篇文档gτ中的单词集合,一条边的权重eijτ对应于一个单词在一篇文档中出现的频率;主题为网络序列中的结构信息,隐含了城市动态相关的、重要的语义信息;
步骤4.2:通过将位置聚类网络定义为文档,将网络中的边关联定义为单词,训练得到一个主题模型,推理od数据集中隐含的k个主题;采用em算法训练得到模型参数,采用gibbs采样计算得到2个概率分布:网络-主题概率分布和主题-边关联概率分布;对于网络-主题概率分布来说,每一个网络代表了一些主题所构成的一个概率分布;用θτ表示网络gτ的主题概率分布,θτ,k表示主题k在gτ网络中的概率;对于主题-边关联概率分布来说,由于每一个主题又代表了很多边所构成的一个概率分布,一条边在不同的主题上具有不同的概率;对于主题k,计算得到的边关联概率由
步骤4.3:对主题基于重要程度排序;由于每个主题在不同的位置聚类网络中具有不同的概率,一个主题在所有网络中的概率和表征了这个主题的重要程度;对于第k个主题,计算
进一步的,所述步骤5包括:
设计主题-时间视图,展示不同主题随着时间的演化特征。x轴对应于分析时间段内的每个小时,具有不同属性的日期用不同的颜色表示;红色表示节假日,蓝色表示周末,黑色表示工作日;y轴代表主题;每个主题采用一种颜色机制映射;在右上角显示颜色图例,颜色越深,表示概率值越大;图中的每个小矩形表示对于一个主题k在某个位置聚类网络gτ中的概率值,由θτ,k所提供;当鼠标移动到一个小矩形上时,显示相关的日期、小时和概率值;用户可以改变分析的时间段在更细的时间粒度上观察数据。主题1表示最重要的,主题2为第二重要的,以此类推;通过观察不同主题出现的时间段,为主题赋予相应的语义标签。
进一步的,所述步骤6包括:
设计一个边关联视图,展示对于每个主题来说重要区域的空间分布和它们之间的流量关系;当点击主题-时间视图中纵坐标上的一个标签时,显示相应的边关联视图;对于第k个主题,从位置聚类cluloci出发到达clulocj的一条边的重要程度impijk可以计算为:
其中
impijk为流量大小乘以边概率值的概率总和;
在边关联视图中,一个蓝色的点代表一个位置聚类,根据位置聚类的中心在地图上绘制。带有箭头的弧线表示位置聚类间的流动强度;由于位置聚类可能具有内部流量,也就是说人们从某个聚类内的位置点出发,到达的位置点也在该聚类内,在蓝色的点外圈加上一个圆环来表示内部流量;对于弧线来说,边的重要程序由边的颜色和粗细双编码。颜色采用“紫色-橙色-黄色-绿色”的渐变色编码。一条弧线越粗、颜色越紫代表流量越大;对于外圈圆环来说,只使用渐变色来编码内部流量的重要程度;为了更清晰地展示重要的边,对弧线根据它们的粗细进行排序。在地图上绘制弧线时,首先绘制较细的、不重要的弧线,将重要的、较粗的弧线绘制在最顶层;用户还可以根据弧线的重要程度对它们进行过滤,通过输入一个阈值,对于impijk小于阈值的弧线不予以显示。
进一步的,所述步骤7包括:
当点击边关联视图中的某条弧线时,动态显示相应的边流量时间分布视图。其中横坐标代表小时,纵坐标代表某小时内的流量概率值;由于点击某条弧线时,已经得到了该弧线对应的出发位置聚类id(i)和到达位置聚类id(j),因此每小时内的流量概率值为
本发明的方法提出了一种新的感知城市动态结构演化规律的可视分析方法。首先将od数据组织成位置聚类网络序列,包含一系列位置聚类和它们之间的关联。然后定义lda主题模型处理网络序列,创造性地将每个时间步下的位置聚类网络看作是文档,将位置聚类间的人流量看作是单词集合,从而将od数据集的时空分析类比为文档语料库分析。最终采用lda提取得到重要的主题结构,并设计交互式的可视分析组件,不仅能发现位置聚类网络的时间演化模式,而且能从语义层面挖掘得到城市居民在不同时间步下日常活动的主要区域和区域间的流动情况,从而帮助交通管理人员、城市规划人员掌握城市动态结构的演化规律,辅助决策,为智慧城市的建设提供帮助。
附图说明
图1为本发明所述可视分析方法的流程图。
图2为主题-时间视图的操作界面和显示结果。
图3为采用本发明的方法对纽约市公共自行车数据处理得到的主题时间视图。
图4a-4d为采用本发明的方法对纽约市公共自行车数据处理得到的多个边关联视图。
具体实施方式
下面结合附图对本发明作进一步说明。
本发明的基于od数据感知城市动态结构演化规律的可视分析方法,包括如下步骤:
步骤1:收集od数据,将它们存储在数据库中。
步骤2:对位置进行聚类,对轨迹按位置聚类和小时聚合。
步骤3:按小时构建位置聚类网络序列,表征每小时内各个聚类间的流量关系。
步骤4:基于位置聚类网络序列,定义lda模型,训练得到一个主题模型,并对主题基于重要程度排序。
步骤5:设计主题-时间视图,可视化不同主题在每个位置网络中的概率分布,展示不同主题随着时间的演化特征。
步骤6:设计边关联视图,直观展示重要区域的空间分布和它们之间的流量关系。
步骤7:设计边流量时间分布视图,展示边关联视图中每条弧线在不同时间步下出现的概率。
所述步骤1包括:
获取od数据集,将它们存储在轨迹记录表中。一条轨迹记录trajrec表示如下:
trajrec=[startloclong,startloclat,starttime,endloclong,endloclat,endtime]
其中startloclong和startloclat为出发地点的经度和纬度,starttime为出发时间,endloclong和endtloclat为到达地点的经度和纬度,endtime为到达时间。
所述步骤2包括:
步骤2.1:对所有位置进行聚类。假设locset={loclongi,loclati}(1≤i≤n)为包含所有出发地点和到达地点的位置集合,一共有n个位置点。loclongi和loclati为第i个位置点的经度和纬度。第i个位置点和第j个位置点之间的距离定义为:
clulocset={cluloci}(1≤i≤k)。其中k是聚类个数,一个位置聚类cluloci中包含了多个相邻的位置点。
步骤2.2:将轨迹按位置聚类和小时聚合。基于trajrec,以小时为单位统计某两个聚类间在单位时间内的人流量,并将它们存储下来加速后续计算。聚合后的一条记录trajaggrrec表示为:
trajaggrrec=[startdate,starthour,startcluloc,endcluloc,flownum]
其中startdate表示出发日期,starthour表示出发小时,可以从startttme中提取得到。startcluloc和endcluloc表示出发和到达的位置聚类的id,flownum表示在某日(startdate)某小时(starthour)内,从startcluloc内出发到达endcluloc的人流量。
所述步骤3包括:
按小时构建位置聚类网络序列,表征每小时内各个聚类间的流量关系。假设gτ=(clulocset,eτ)表示在时间步τ下的位置聚类网络,可以用一个图结构表示。其中位置聚类集合clulocset被看作是顶点集合,eτ为边集合。eijτ∈eτ表示在时间步τ内从cluloci出发到达clulocj的人流量,具体的值可以从trajaggrrec中查询得到。然后按小时构建位置聚类网络序列ns={g1,g2,...,gt}。t为所有时间步的总数,由待分析的时间段内的日期数d决定,t=24×d。
所述步骤4包括:
步骤4.1:基于位置聚类网络序列,定义lda模型。lda模型包含3层:文档、单词和主题。一篇文档是由一组单词构成的集合。所有的文档集构成了一个语料库。一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。为了能够分析od数据集的时空演化模式,如下定义lda模型中的3层。将每个时间步下的位置聚类网络gτ看作是一篇文档,从而位置聚类网络序列ns={g1,g2,...,gt}构成了一个语料库。将边集合eτ看作是一篇文档gτ中的单词集合,一条边的权重eijτ对应于一个单词在一篇文档中出现的频率。主题为网络序列中的结构信息,隐含了城市动态相关的、重要的语义信息。
步骤4.2:通过将位置聚类网络定义为文档,将网络中的边关联定义为单词,训练得到一个主题模型,推理od数据集中隐含的k个主题。采用em算法训练得到模型参数,采用gibbs采样计算得到2个概率分布:网络-主题概率分布和主题-边关联概率分布。对于网络-主题概率分布来说,每一个网络代表了一些主题所构成的一个概率分布。用θτ表示网络gτ的主题概率分布,θτ,k表示主题k在gτ网络中的概率。对于主题-边关联概率分布来说,由于每一个主题又代表了很多边所构成的一个概率分布,一条边在不同的主题上具有不同的概率。对于主题k,计算得到的边关联概率由
步骤4.3:对主题基于重要程度排序。由于每个主题在不同的位置聚类网络中具有不同的概率,一个主题在所有网络中的概率和表征了这个主题的重要程度。对于第k个主题,计算
所述步骤5包括:
设计主题-时间视图,展示不同主题随着时间的演化特征。x轴对应于分析时间段内的每个小时,具有不同属性的日期用不同的颜色表示。红色表示节假日,蓝色表示周末,黑色表示工作日。y轴代表主题。每个主题采用一种颜色机制映射。在右上角显示颜色图例。颜色越深,表示概率值越大。图中的每个小矩形表示对于一个主题k在某个位置聚类网络gτ中的概率值,由θτ,k所提供。当鼠标移动到一个小矩形上时,显示相关的日期、小时和概率值。用户可以改变分析的时间段在更细的时间粒度上观察数据。由于在步骤4.3中对主题已经进行了排序,在主题-时间视图中主题的重要程度显示得更为清晰。主题1表示最重要的,主题2为第二重要的,以此类推。通过观察不同主题出现的时间段,为主题赋予相应的语义标签。
此外,在某些情况下,2个主题可能包含相似的边关联概率分布,将相似的主题合并更易于进行模式归纳。重要度很低的主题也对分析结果没有用处。在主题-时间视图中可以进行交互式的主题优化,包括主题合并和删除。对于主题合并来说,用户可以在文本框中输入两个主题id来合并主题。若要合并主题i和主题j,则合并后的主题z的网络-主题概率为:θτ,z=θτ,i+θτ,j。对主题-边关联概率分布也进行合并,如果一条边同时出现在2个主题中,则将两个概率值相加。否则,直接将这条边和相应的概率值放入新的主题-边关联概率分布中。对于主题删除来说,用户可以通过输入多个用英文逗号连接的主题id来删除多个主题,相关的主题直接从概率分布中移除。在进行主题合并和删除操作后,可以获取优化后的主题模型结果。
所述步骤6包括:
由于每个主题可以由一组具有不同概率的单词表示,反应了不同时间步下重要的移动路线,因此设计一个边关联视图,展示对于每个主题来说重要区域的空间分布和它们之间的流量关系。当点击主题-时间视图中纵坐标上的一个标签时,显示相应的边关联视图。对于第k个主题,从位置聚类cluloci出发到达clulocj的一条边的重要程度impijk可以计算为:
其中
impijk为流量大小乘以边概率值的概率总和。
在边关联视图中,一个蓝色的点代表一个位置聚类,根据位置聚类的中心在地图上绘制。带有箭头的弧线表示位置聚类间的流动强度。由于位置聚类可能具有内部流量,也就是说人们从某个聚类内的位置点出发,到达的位置点也在该聚类内,在蓝色的点外圈加上一个圆环来表示内部流量。对于弧线来说,边的重要程序由边的颜色和粗细双编码。颜色采用“紫色-橙色-黄色-绿色”的渐变色编码。一条弧线越粗、颜色越紫代表流量越大。对于外圈圆环来说,只使用渐变色来编码内部流量的重要程度。为了更清晰地展示重要的边,对弧线根据它们的粗细进行排序。在地图上绘制弧线时,首先绘制较细的、不重要的弧线,将重要的、较粗的弧线绘制在最顶层。用户还可以根据弧线的重要程度对它们进行过滤,通过输入一个阈值,对于impijk小于阈值的弧线不予以显示。
所述步骤7包括:
当点击边关联视图中的某条弧线时,动态显示相应的边流量时间分布视图。其中横坐标代表小时,纵坐标代表某小时内的流量概率值。由于点击某条弧线时,已经得到了该弧线对应的出发位置聚类id(i)和到达位置聚类id(j),因此每小时内的流量概率值为
图3给出了基于纽约市2016年12月的公共自行车数据,处理得到的主题-时间视图。从图中可以发现城市动态的周期性演化规律。主题1出现在工作日的20:00-3:00和周末的10:00-3:00,对应于休闲时间。主题2出现在工作日的10:00-15:00和周末的8:00-19:00,对应于日间。在主题1和2主题之间有时间过渡,也就是说,在周末的10:00-19:00期间主题1和主题2同时存在。主题3主要出现在工作日的4:00-7:00,对应于晨间。主题4出现在工作日的17:00-19:00,对应于晚高峰。主题6出现在工作日的7:00-8:00,对应于早高峰。主题7出现在工作日的12:00-17:00。主题8出现在工作日的9:00-11:00。
图4a-4d给出了基于纽约市公共自行车数据,部分主题对应的边关联视图。在早高峰(图4a)和晚高峰(图4b)期间,人群流动遍布于曼哈顿的各个街区中。右侧放大的地图中过滤掉了不重要的弧线,从中可以看出,早晚高峰期间主要的流动方向是相反的。图4c展示了人们在休闲时间的活动情况。热门的线路集中于东村(ev)、格林威治村(gv)、小意大利(li)和下东区(les)。这些地点是纽约知名的夜生活娱乐区域。图4d展示了晨间活动情况,主要发生在工作日的4:00-7:00,流量从周边地区前往中城。右侧的边流量时间分布视图给出了2条弧线的结果,能更进一步地观察流量发生的主要时间。从图中可以得知,这些流量主要发生于早晨的6点至7点。由于中城包含很多世界知名的办公大楼及大型车站,推测这些流量跟人们早起上班有关。
- 还没有人留言评论。精彩留言会获得点赞!