一种基于文本说明的程序生成方法与流程
本发明涉及计算机软件工程技术领域,尤其是涉及一种基于文本说明(textspecification)的程序生成方法。
背景技术:
近些年,由于编程的困难和成本在上升,很多研究开始试图将深度学习技术应用到软件工程领域,解决例如api序列预测、代码补全、程序生成等问题。通过给定一个自然语言表示的说明文本,典型的自动生成技术可以基于说明文本的上下文逐个预测程序的字符序列。如图1所示。但是,由于从文本说明产生的程序往往会有很多不同方式,并且需要可执行性和可解释性,有效自动程序生成仍然面临巨大的挑战。
技术实现要素:
为解决以上问题,在本发明中,通过文本说明有效的产生程序。首先,基于文本说明,为双模式程序生成问题建立一个通用深度学习架构prognet;然后提出一种基于多注意力的glu-cnn2lstm模型,通过该模型能够解决从自然语言说明中产生程序的问题。本发明使用来自网页的两个大数据集来验证本发明的有效性,这两个数据集分别是c语言和java语言格式。实验结果表明,本发明的模型优于强参照基准。
具体的,本发明提供了一种基于文本说明的程序生成方法,包括:
将所述文本说明输入特征编码器,提取所述文本说明的语义信息;
所述特征编码器对所述语义信息进行编码,并将编码后的语义信息输入程序生成器中;
将所述文本说明输入注意力层,所述注意力层控制所述文本说明到所述程序生成器的信息流;
将所述信息流输入所述程序生成器;
所述程序生成器根据所述语义信息和所述信息流,生成源代码片段。
优选的,所述特征编码器包括一个或多个特征提取器。
优选的,所述程序生成器为基于循环神经网络的模块。
优选的,所述循环神经网络为长短期记忆网络。
优选的,所述循环神经网络为由粗到细的多层循环神经网络。
优选的,所述特征编码器为两层卷积神经网络,包括嵌入层和卷积层。
优选的,所述嵌入层和卷积层分别具有卷积过滤器,每个卷积过滤器具有门控线性单元。
优选的,所述注意力层为两层注意力层,其中一层注意力层设置在所述嵌入层之后,而另一个注意力层设置在所述卷积层之后。
优选的,每个所述特征提取器提取并产生一个特征图,将所有的所述特征图关联到一个单一的特征图中,以产生一个固定大小的特征向量,所述特征向量即所述语义信息。
优选的,所述关联的方式是空间权重组合。
本发明的优点在于:本发明的方案提高了程序代码生成的准确率和效率,生成的源代码质量高而且具有稳定性。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
图1为基于文本说明生成对应的c语言程序示意图。
图2为本发明基于文本说明的程序生成方法流程图。
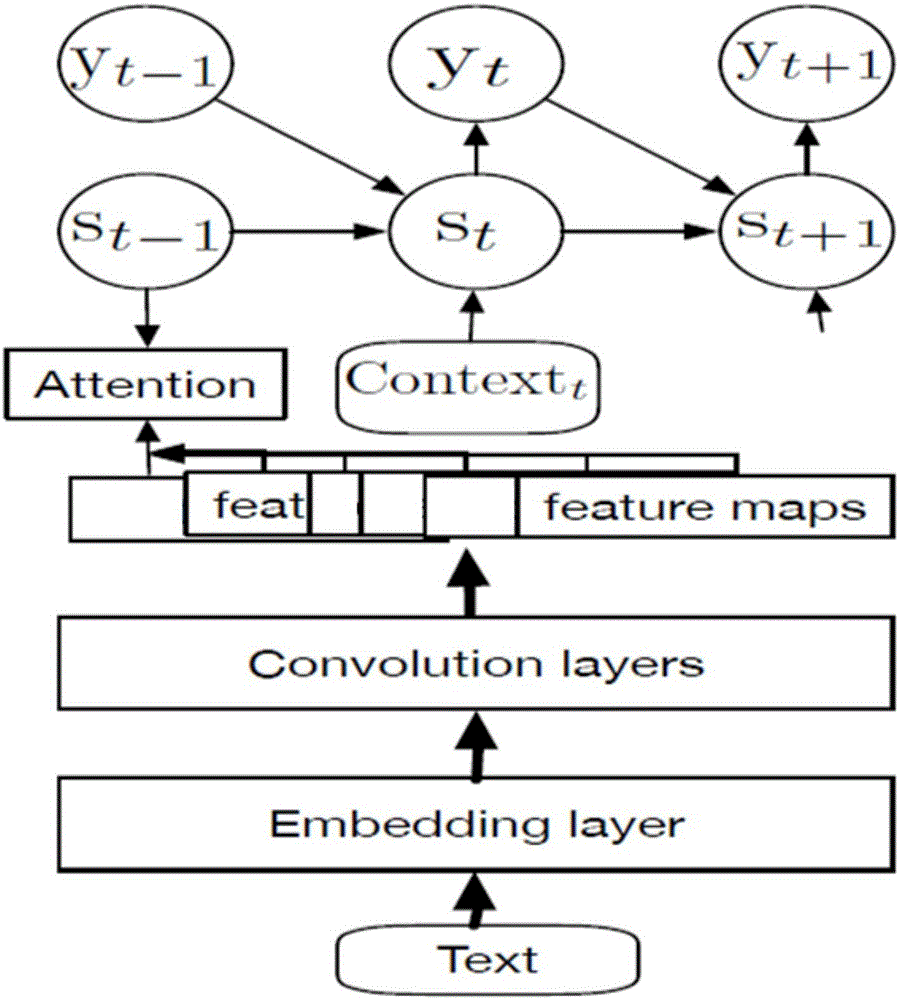
图3为本发明基于文本说明的程序生成方法原理图。
具体实施方式
下面将参照附图更详细地描述本发明的示例性实施方式。虽然附图中显示了本发明的示例性实施方式,然而应当理解,可以以各种形式实现本发明而不应被这里阐述的实施方式所限制。相反,提供这些实施方式是为了能够更透彻地理解本发明,并且能够将本发明的范围完整的传达给本领域的技术人员。
本发明设计了一种通用的深度学习架构,能够以端到端的方式根据自然语言自动生成程序。本发明的架构包括两个部分,一个部分用于编码文本说明里的语义,另一个部分用于生成源代码,其中使用了注意力机制。本发明是目前为止首次完成基于自然语言描述而进行实际的程序生成任务的。
本发明提出了一种全新的处理自然语言描述的方法,通过多注意力机制,使用基于glu的卷积神经网络(cnn),达到了最高水准的性能表现,大大优于基于长短期记忆(lstm)的具有相似数量参数的模型。
如图2所示,本发明提出一种prognet架构,用于解决双模式生成问题。具体的,本发明提出了一种于文本说明的程序生成方法,包括:
s1、将所述文本说明输入特征编码器(featureencoder),提取所述文本说明的语义信息。所述特征编码器包括一个或多个特征提取器(featureextractor)。
s2、所述特征编码器进一步对所述语义信息进行编码,并将编码后的语义信息输入程序生成器中。
s3、将所述文本说明输入注意力层,所述注意力层控制文本说明到所述程序生成器的信息流。由于注意力机制在深度神经网络模型的重要性,因此,本发明设置注意力层。
s4、将所述信息流输入程序生成器。由于要生成的程序是标识符序列,本发明通过使用基于循环神经网络(rnn)的模块作为程序生成器,例如长短期记忆网络(lstm)。特别的,为了满足程序的执行和解释需求,本发明还可以采用由粗到细的多层循环神经网络。
s5、所述程序生成器根据所述语义信息和所述信息流,生成源代码片段。
本发明的程序生成架构能有效处理不同的文本说明,这对于处理不同类型的约束非常有用。
如图3所示,为本发明的深层机制和工作原理。本发明使用嵌入层(embeddinglayer)和卷积层(convolutionlayer)作为编码器,用于文本注释序列,每个层具有不同的卷积过滤器,每个卷积过滤器应用于多个字的窗口,以产生和提取特征图(featuremap)。优选的,每个卷积过滤器具有门控线性单元(gatedlinearunit,glu),以遍历整个输入或者关注少数特别元素。
优选的,所述注意力层为两层注意力层,其中一层设置在所述嵌入层之后,而另一个层设置在所述卷积层之后。
为了解决文本说明的源代码生成问题,本发明使用了卷积神经网络(cnn)来提取特征,并通过空间注意力机制将所述特征转换为固定大小。具有固定大小的语境输入训练过的神经网络编程语言模型,以预测代码序列的下一个词或者符号。预测部分使用lstm,lstm被广泛的用作rnn架构。
图3中,每个注释都穿过cnn特征提取器,然后将所述特征图关联到一个单一的大的特征图中,以产生一个固定大小的特征向量,并将所述特征向量输入rnn网络中。所述关联的方式是空间权重组合。
实验及结果
为了展示本发明的技术效果,本发明还做了对照实验。本发明采用了两个人工数据集,均来自网页的开源平台。一种是基于c语言的人工数据集poj,另一种是基于java语言的人工数据集github。
表1
表1为使用本发明方法在两个数据集上得到的程序代码(下一个标识符平均)生成准确率结果列表。第一列表示的是各种程序生成方法,第二列表示的是基于c语言的人工数据集poj下的程序代码(下一个标识符平均)生成准确率,第三列表示的是基于java语言的人工数据集github下的程序代码(下一个标识符平均)生成准确率。从表1可以看出,第一行是没有基于文本说明的lstm,其预测准确率相对较低。第二行是使用问题id而不是自然语言描述来生成程序代码,其预测准确率相对于没有基于文本说明的lstm有所提高。第三到八行是采用本发明的技术方案的准确率结果。其中,第三行是使用cnn作为编码器的方案,其准确率获得了进一步提高,这表明cnn在捕获字的位置和语义时很有效。第四行是引入注意力机制的cnn方案(cnn+att),第五行是使用rnn作为解码器的方案,第六行是引入注意力机制的rnn方案(rnn+att),第七行是引入门控线性单元的卷积过滤器的cnn方案(glu-cnn),第八行是引入门控线性单元的卷积过滤器和注意力机制的cnn方案(glu-cnn+att)。从表中的准确率结果来看,本发明这几种方案下,程序生成的准确率均有不同程度的提高。
需要说明的是:
在此提供的算法和显示不与任何特定计算机、虚拟装置或者其它设备固有相关。各种通用装置也可以与基于在此的示教一起使用。根据上面的描述,构造这类装置所要求的结构是显而易见的。此外,本发明也不针对任何特定编程语言。应当明白,可以利用各种编程语言实现在此描述的本发明的内容,并且上面对特定语言所做的描述是为了披露本发明的最佳实施方式。
在此处所提供的说明书中,说明了大量具体细节。然而,能够理解,本发明的实施例可以在没有这些具体细节的情况下实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
类似地,应当理解,为了精简本公开并帮助理解各个发明方面中的一个或多个,在上面对本发明的示例性实施例的描述中,本发明的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。然而,并不应将该公开的方法解释成反映如下意图:即所要求保护的本发明要求比在每个权利要求中所明确记载的特征更多的特征。更确切地说,如下面的权利要求书所反映的那样,发明方面在于少于前面公开的单个实施例的所有特征。因此,遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其中每个权利要求本身都作为本发明的单独实施例。
本领域那些技术人员可以理解,可以对实施例中的设备中的模块进行自适应性地改变并且把它们设置在与该实施例不同的一个或多个设备中。可以把实施例中的模块或单元或组件组合成一个模块或单元或组件,以及此外可以把它们分成多个子模块或子单元或子组件。除了这样的特征和/或过程或者单元中的至少一些是相互排斥之外,可以采用任何组合对本说明书(包括伴随的权利要求、摘要和附图)中公开的所有特征以及如此公开的任何方法或者设备的所有过程或单元进行组合。除非另外明确陈述,本说明书(包括伴随的权利要求、摘要和附图)中公开的每个特征可以由提供相同、等同或相似目的的替代特征来代替。
此外,本领域的技术人员能够理解,尽管在此所述的一些实施例包括其它实施例中所包括的某些特征而不是其它特征,但是不同实施例的特征的组合意味着处于本发明的范围之内并且形成不同的实施例。例如,在下面的权利要求书中,所要求保护的实施例的任意之一都可以以任意的组合方式来使用。
本发明的各个部件实施例可以以硬件实现,或者以在一个或者多个处理器上运行的软件模块实现,或者以它们的组合实现。本领域的技术人员应当理解,可以在实践中使用微处理器或者数字信号处理器(dsp)来实现根据本发明实施例的虚拟机的创建装置中的一些或者全部部件的一些或者全部功能。本发明还可以实现为用于执行这里所描述的方法的一部分或者全部的设备或者装置程序(例如,计算机程序和计算机程序产品)。这样的实现本发明的程序可以存储在计算机可读介质上,或者可以具有一个或者多个信号的形式。这样的信号可以从因特网网站上下载得到,或者在载体信号上提供,或者以任何其他形式提供。
应该注意的是上述实施例对本发明进行说明而不是对本发明进行限制,并且本领域技术人员在不脱离所附权利要求的范围的情况下可设计出替换实施例。在权利要求中,不应将位于括号之间的任何参考符号构造成对权利要求的限制。单词“包含”不排除存在未列在权利要求中的元件或步骤。位于元件之前的单词“一”或“一个”不排除存在多个这样的元件。本发明可以借助于包括有若干不同元件的硬件以及借助于适当编程的计算机来实现。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。单词第一、第二、以及第三等的使用不表示任何顺序。可将这些单词解释为名称。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!