一种半结构化json数据自由解析适配方法与流程
本发明涉及计算机应用技术领域,尤其涉及一种半结构化json数据自由解析适配方法。
背景技术:
json(jacascriptobjectnatation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。json采用完全独立于语言的文本格式,但是也使用了类似于c语言家族的习惯,这些特性使得json成为理想的数据交换语言。
但是,目前,一般需要通过编写代码的方式,从大量的半结构化json数据,提取其中的一部分,如果这些待提取的数据量也比较大,而且又没有什么规律性的话,则需要针对每个数据都编写对应的代码,所以,操作起来会费时费力,尤其是当企业具有很多部门,虽然每个部门需要的数据不同,但是,也可能不同的部门需要的某些数据相同,这就导致数据工程师可能需要对相同的数据,进行多次重复性的提取,即进行多次重复性的编写相同的代码,造成资源的浪费和工作效率的下降。而且,由于需要编写代码,就需要操作人员非常熟悉json数据的结构,因此,就无形中提高了对操作人员的专业要求。
技术实现要素:
本发明的目的在于提供一种半结构化json数据自由解析适配方法,从而解决现有技术中存在的前述问题。
为了实现上述目的,本发明采用的技术方案如下:
一种半结构化json数据自由解析适配方法,包括如下步骤:
s1,批量获取同结构的json原始数据;
s2,将一条原json数据中的数组、对象均进行迭代拆分,直至拆分到每个元素,将拆分的子串以及元素进行标识id作为路由id,json数据中的每一段内容以及最终元素都有唯一的路由id;
s3,用户根据需求,利用路由id编写输出结构配置文件;
s4,根据用户编写的输出结构配置文件,获取配置文件中的路由id对应的数据,组合拼凑输出需求的半结构化json数据或结构化数据。
优选地,s2中,所述路由id以树结构的形式表示,该树结构中,树枝节点为json数据或json片段数据,叶子结点为最小粒度数据。
优选地,s2中,对于批量同结构json数据,相同位置的数据对应的路由id相同。
优选地,s3中,用户根据需求,利用路由id编写输出结构配置文件,具体包括如下步骤:
s301,用户获取所解析json的数据结构和待输出的数据结构;
s302,按照json数据结构确定需求的数据对应的路由id;
s303,利用路由id拼凑输出结构写入到输出结构配置文件。
优选地,s302具体为,将一条原json数据中的数组、对象均进行迭代拆分,直至拆分到每个元素,将拆分的子串以及元素进行标识id作为路由id,json数据中的每一段内容以及最终元素都有唯一的路由id,对于批量同结构的json数据,相同位置的数据对应的路由id相同。
优选地,s4中,所述组合输出json数据或结构化数据,包括批量json数据中一个对象或数组或一段json内容或某几个元素的内容。
本发明的有益效果是:本发明提供的半结构化json数据自由解析适配方法,通过对原json数据中的数组、对象均进行拆分,并按照json数据结构为拆分后的数组、对象一一编写路由,用户根据需求,利用路由编写输出结构配置文件,最后读取该输出结构配置文件,即可获取用户需求的json数据或结构化数据。与现有技术中通过编写代码提取数据的方式相比,对于用户而言,无需编码,省去了解析出错调试的时间。实现起来变得非常容易,对于操作人员无需很高的专业要求,能够极大的节省时间和经历,提高工作效率。而且,采用本发明提供的方法,用户可以很随意的按业务需求将半结构化的数据转化成业务需要的结构化数据、半结构化jsion数据。
附图说明
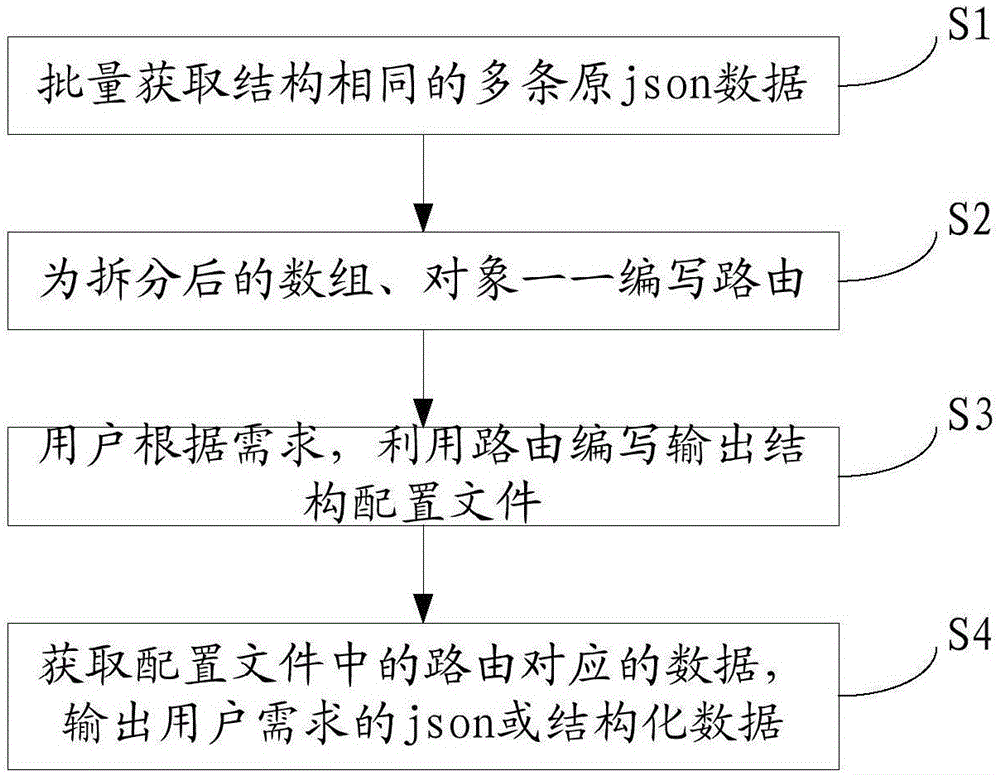
图1是本发明提供的半结构化json数据自由解析适配方法流程示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不用于限定本发明。
如图1所示,本发明提供了一种半结构化json数据自由解析适配方法,包括如下步骤:
s1,批量获取同结构的json原始数据;
s2,将一条原json数据中的数组、对象均进行迭代拆分,直至拆分到每个元素,将拆分的子串以及元素进行标识id作为路由id,json数据中的每一段内容以及最终元素都有唯一的路由id;
s3,用户根据需求,利用路由id编写输出结构配置文件;
s4,根据用户编写的输出结构配置文件,获取配置文件中的路由id对应的数据,组合拼凑输出需求的半结构化json数据或结构化数据。
采用上述方法,由于对于json数据所有的数组和对象均编写了路由,所以,在提取数据时,用户只需要通过路由编写简单的输出结构配置文件,就可以很快速的从成千上万条json数据中得到对应的数据,所以,容易实现,对于操作人员无需很高的专业要求,也能够极大的节省时间和经历,提高工作效率。
其中,s2中,所述路由id可以以树结构的形式表示,该树结构中,树枝节点为json数据或json片段数据,叶子结点为最小粒度数据。
采用上述形式,即相当与将json数据中的内容和最终元素分别放置在大树的支杆和叶片上(具体理解可参见下文中的示例),并对每个支杆和叶片进行编号,每个支杆和叶片都有唯一对应的编号,则其对应的json数据中的内容和最终元素也都有唯一的编号,那么,用户在该大树上去查询json数据中的内容和最终元素时,只需要根据该唯一的编号即可找到,而无需再使用编程的语言。
s2中,批量同结构json数据,相同位置的数据对应的路由id相同。
对于同一种json数据结构的数据,其形成的树结构相同,所以,其相同位置的数据对应的路由id是相同的。
则对于批量的该类数据,用户只需要知道其中一条json数据的结构,则可以从批量的该类数据中,获取到所有的位于相同位置的数据。
s3中,用户根据需求,利用路由id编写输出结构配置文件,具体包括如下步骤:
s301,用户获取所解析json的数据结构和待输出的数据结构;
s302,按照json数据结构确定需求的数据对应的路由id;
s303,利用路由id拼凑输出结构写入到输出结构配置文件。
s302具体为,将一条原json数据中的数组、对象均进行迭代拆分,直至拆分到每个元素,将拆分的子串以及元素进行标识id作为路由id,json数据中的每一段内容以及最终元素都有唯一的路由id,对于批量同结构的json数据,相同位置的数据对应的路由id相同。
s4中,所述组合输出json数据或结构化数据,包括批量json数据中一个对象或数组或一段json内容或某几个元素的内容。
具体实施例:
步骤一,获取如下示例的原json数据,如下示例为其中的一条json数据,在实际应用中,这种示例的json数据会有成千上万条:
{"animals":{"dog":[{"name":"rufus[ss]","age":15},{"name":"marty","age":null}],"dog1":[{"name1":"rufus1","age":15},{"name1":"marty1","age":null}]}}。
步骤二,将步骤一中的一条原json数据中的数组、对象均进行迭代拆分,直至拆分到每个元素,将拆分的子串以及元素进行标识id作为路由id,json数据中的每一段内容以及最终元素都有唯一的路由id,并将所有的路由以树结构的形式进行表示,结果如下:
(1,{},0,167,{"animals":{"dog":[{"name":"rufus[ss]","age":15},{"name":"marty","age":null}],"dog1":[{"name1":"rufus1","age":15},{"name1":"marty1","age":null}]}})
(1-1,{},13,166,{"dog":[{"name":"rufus[ss]","age":15},{"name":"marty","age":null}],"dog1":[{"name1":"rufus1","age":15},{"name1":"marty1","age":null}]})
(1-1-2,[],99,164,[{"name1":"rufus1","age":15},{"name1":"marty1","age":null}])
(1-1-2-2,{},132,162,{"name1":"marty1","age":null})
(1-1-2-1,{},101,130,{"name1":"rufus1","age":15})
(1-1-1,[],23,88,[{"name":"rufus[ss]","age":15},{"name":"marty","age":null}])
(1-1-1-2,{},58,86,{"name":"marty","age":null})
(1-1-1-1,{},25,56,{"name":"rufus[ss]","age":15})
其中,1,1-1,1-1-2,1-1-2-2,1-1-2-1,1-1-1,1-1-1-2,1-1-1-1,就是按照json数据的结构为原json数据中的对象、数组等编写的枝干节点路由。其后的数据为该路由对应的数据,比如,1-1-1-1路由对应的数据为{"name":"rufus[ss]","age":15}。同时,该数据位于该条json数据的25-56的位置处。所以,在实际应用过程中,为了在后续提取数据时,能够更加准确的定位,可以在编写路由的同时,将路由对应的数据所处的位置同时给出。
对于以上的枝干节点路由,继续编写叶子节点路由。
比如,对于以下的枝干节点:
(1-1-1-1,{"name1":"marty1","age":null})
(1-1-2-2,{"name":"rufus[ss]","age":15})
(1-1,{"dog":[{"name":"rufus[ss]","age":15},{"name":"marty","age":nu
ll}],"dog1":[{"name1":"rufus1","age":15},{"name1":"marty1","age":nu
ll}]})
可以按照如下形式编写叶子节点路由:
(1-1-2-2:map:@age,15)
(1-1-2-2:map:@name,"rufus[ss]")
(1-1-1-1:map:@age,"null")
从上述结果中,可以看出,每个节点(枝干节点和叶子节点)均包括路由和对应的数据,所以,在用户需要从一条json数据中获取对象或数组,或者从成千上万条json数据中获取相同位置的对象或数组时,只需要提供需要获取的对象或数组的路由(位置),即可获取到该路由对应的数据。
在实际应用过程中,对于成千上万条json数据,只需要找到该需求的数据在一条json数据中的路由(位置),即可获取到成千上万条json数据中的该位置的数据,从而将半结构化的json数据,转化为结构化的数据,而且能够实现批量的数据提取。
步骤三,用户根据需求,利用路由id编写输出结构配置文件。
例如,在该条json数据中:
{"animals":{"dog":[{"name":"rufus[ss]","age":15},{"name":"marty","age":null}],"dog1":[{"name1":"rufus1","age":15},{"name1":"marty1","age":null}]}},
或者与该条json数据结构相同的成千上万条json数据,用户想从该条json数据,或者与该条json数据结构相同的成千上万条json数据中获取age,则可编写如下结构的输出结构配置文件:1-1-1-1:map:@age,1-1-1-2:map:@age,1-1-2-1:map:@age,1-1-2-2:map:@age。
如果用户想从json数据中获取age和name两类数据,则可编写如下结构的输出结构配置文件:1-1-1-1:map:@age,1-1-1-2:map:@age,1-1-2-1:map:@age,1-1-2-2:map:@age,1-1-1-1:map:@name,1-1-1-2:map:@name,1-1-2-1:map:@name,1-1-2-2:map:@name。
步骤四,根据用户的输出结构配置文件,获取配置文件中的路由对应的数据,组合输出json数据或结构化数据。
根据步骤三中用户编写的输出结构配置文件,比如,1-1-1-1:map:@age,1-1-1-2:map:@age,1-1-2-1:map:@age,1-1-2-2:map:@age,读取并输出每个路由对应的数据:15,null,15,null。
可见,采用本发明提供的方法,用户只需要通过路由编写简单的输出结构配置文件,就可以很快速的从成千上万条json数据中得到对应的数据,而现有技术中,还需要经过编写代码的方式,进行数据的提取,相对于编写代码,对于用户而言,只是简单的输入路由,就显得非常容易了,所以,对于操作人员无需很高的专业要求,也能够极大的节省时间和经历,提高工作效率。而且,采用本发明提供的方法,可以将半结构化的数据转化成结构化数据。同时,可以简单的实现不同的json数据对象或数组的自由组合,提取出用户需要的数据。
通过采用本发明公开的上述技术方案,得到了如下有益的效果:本发明提供的半结构化json数据自由解析适配方法,通过对原json数据中的数组、对象均进行拆分,并按照原json数据结构为拆分后的数组、对象一一编写路由,用户根据需求,利用路由编写输出结构配置文件,最后读取该输出结构配置文件,即可获取用户需求的json数据。与现有技术中通过编写代码提取数据的方式相比,对于用户而言,实现起来变得非常容易,对于操作人员无需很高的专业要求,能够极大的节省时间和经历,提高工作效率。而且,采用本发明提供的方法,用户可以很随意的按业务需求将半结构化的数据转化成业务需要的结构化数据、半结构化jsion数据。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!