一种基于分布式的管网产销差计算调整方法与流程
本发明属于供水行业技术领域,特别涉及一种基于分布式的管网产销差计算调整方法。
背景技术:
在供水行业中,产销差的大小变化直接影响供水企业的经济效益,而计算产销差离不开各种仪器仪表上传的时间序列数据。以单位用户为例,需要记录正累计水量、反累计水量、总累计水量、瞬时流量、压力等数据,每5分钟上传一条,以一座中等城市10000个单位用户为例,一天就是5*288*10000=14400000条数据,而计算产销差还需要流量仪和居民等数据这又是一个庞大的数据集。除此之外我们还需要对这些数据进行预处理之后才能使用,这就需要我们有一定的流程编排,顺序性也亟待解决。
传统的分布式计算,例如hadoopmapreduce使用了大批量的任务集群,正式由于批量执行,时效性比较低,而且我们不能对计算的内容进行编排,没有与容器技术更好的融合,不能解决行业问题。
单节点计算可以控制计算步骤,编排计算流程,但是面对供水行业如此庞大的数据集的时候往往力不从心,不仅仅失去了时效性,更不得不占用白天时间进行计算,严重影响正常生产运行。而传统的分布式计算,以机器为节点,虽然计算速度很快,但是机器配置不一,无法充分利用资源,并且数据流程不可控,开发人员不得不花大量精力去关注流程问题,考虑先后顺序,误码率高、程序耦合性强。
技术实现要素:
发明目的:为了克服现有技术中存在的计算产销差速度慢、周期长、时效性差、容错率低等不足,本发明提供一种集群是以容器为计算节点,容器之间计算互相隔离、环境稳定,容错率高,而且支持流程编排的基于分布式的管网产销差计算调整方法。
技术方案:为实现上述目的,本发明提供一种基于分布式的管网产销差计算调整方法,包括如下步骤:
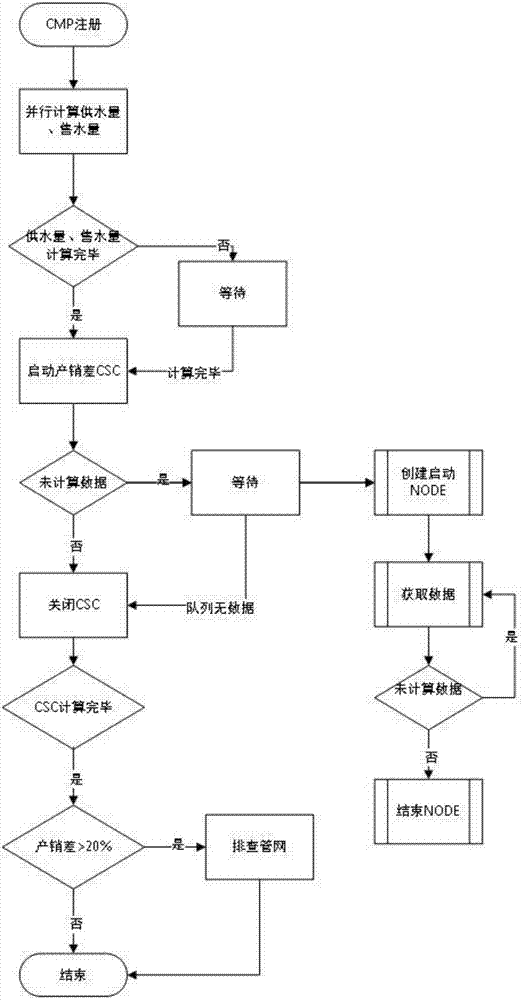
(1)供水量、售水量、产销差csc启动并向cmp注册,提交产销差计算的先决条件;
(2)cmp启动不需要先决条件的供水量、售水量csc并行计算;
(3)判断供水量和售水量是否计算完毕,如果计算完毕则进入步骤(4),如果没有计算完毕则继续等待直至计算完毕并进入步骤(4);
(4)启动产销差csc;将所需要计算的dma、站点,按dma、站点个数进行分组,并把dma、站点分组数据放入待计算的队列;
(5)判断是否有未计算数据,如果否则进入步骤(9),如果是则等待并进入步骤(6);
(6)判断队列中是否有数据,如果有数据则进入步骤(7),如果没有数据则进入步骤(9);
(7)创建启动node并获取未计算的数据,然后计算产销差;
(8)判断是否有未计算数据,如果有则返回步骤(7)重新获取数据;如果否则结束node;
(9)关闭csc,直至所有csc执行完毕;
(10)判断步骤(7)中,计算得到的产销差是否大于20%,如果是则该区域管网系统漏损严重需要排查,如果否则该区域管网系统安全。
进一步的,所述步骤(2)中计算供水量的具体步骤如下:
(2.1.1)处理原始数据时间规整:将总累积值处理成每5分钟1个点的数据,计算瞬时值;
(2.1.2)剔除异常值:流速大于10m/s的数据点认为是异常值,进行剔除;
(2.1.3)提取每分钟一条累计水量,并做线性差值,然后按天累加,计算出每个账户的日供水量。
进一步的,所述步骤(2)中计算售水量的具体步骤如下:
(2.2.1)先处理人工水表抄码数据,过滤掉水表抄码状态不为“正常”的,且水量为“0”的水表抄码记录;
(2.2.2)同月水表水表抄码1-3次,水量合并,日期和水表抄码状态取第二次;
(2.2.3)异常数据规避:进行非开账水量数据规避和极值规避;
(2.2.4)进行人工水表抄码规范化,将所有水表抄码类型为“正常”的用水量留用;
(2.2.5)若两个“正常”的水表抄码记录中间有除“正常”状态以外的记录,则将两个“正常”水表抄码记录之间的用水量[a,b)相加,并除以两个“正常”水表抄码之间的时间间隔,计算每个用户每天的用水量。
进一步的,所述步骤(2.2.3)中异常数据规避的具体步骤如下:
(2.2.3.1)对非开账水量数据规避,首先筛选开账水表:在表卡信息表中,筛选“水表功能分类”为“开账”的水表,取其水表抄码值进行人工水表抄码规整化,“水表功能分类”为“计量”的水表,不取值,不参与计算;
(2.2.3.2)然后筛选开账数据:在水表抄码信息表中,筛选“开账日期”不为空的数值,参与人工水表抄码规整化的计算;
(2.2.3.3)对极值进行规避:首先采集各个口径管道上对应的上下限绝对值,判断实时采集的流量的绝对值是否大于进水管口径所对应的流量上下限绝对值,如果大于则实时采集的流量的绝对值无效,先做标记,再采用估算值代替真实值;如果不大于则计算结果有效;
其中上下限绝对值为月度用水量的四倍;估算值为过去三次抄表水量的平均值。
进一步的,所述步骤(7)中计算产销差的具体步骤如下:
主动从当前的产销差csc中待计算的队列中请求分组数据,进行产销差的计算:
(7.1)根据供水管理所及其下属站点和dma中取出该管理区域的日供水量。
(7.2)取出供水管理所及其下属站点和dma中的日售水量进行累加,计算出供水管理所及其下属站点和dma中的售水量
(7.3)根据产销差=(供水量-售水量)/供水量,计算出产销差。
csc将已计算完成的(所、站、dma)分组数据即供水管理所及其下属站点和dma从待计算队列移除,放入正在计算的队列中加上时间和计算次数作为标记;计算完成之后把需要的结果存储下来,并通知csc该组数据计算完成,csc收到计算完成的请求之后,将数据移除正在计算队列,如果node计算抛出异常或者计算超过30分钟,csc容错机制将该组数据从正在计算队列移除,重新放入到待计算队列,并标记计算次数
有益效果:本发明与现有技术相比具有以下优点:
本发明所述的产销差计算可以按照账号、dma、站点进行划分,而且计算结果也是独立存储,并不需要传统分布式计算的mapreduce方式,这样我们可以把计算的node节点做到无状态化,而且计算存储一体式处理,容器可以互相隔离出来,达到计算性能高,并且可以做到故障转移,容错率高。
而顶层的cmp只是负责启动和流程编排,做到与底层实现又互相隔离,可以做到只关心流程并不关心具体计算实现,对于供水行业修改计算流程变得不那么困难。
附图说明
图1为本发明的流程图;
图2为现有技术中供水行业产销差计算流程图;
图3为具体实施例中cmp机制的实现结构图;
图4为具体实施例中各种口径管道流量上下限绝对值的示意图。
具体实施方式
下面结合附图对本发明作更进一步的说明。
如图1所示,本发明所述的一种基于分布式的管网产销差计算调整方法,包括如下步骤:
(1)供水量、售水量、产销差csc启动并向cmp注册,提交产销差计算的先决条件;
(2)cmp启动不需要先决条件的供水量、售水量csc并行计算;
(2.1.1)处理原始数据时间规整:将总累积值处理成每5分钟1个点的数据,计算瞬时值;
(2.1.2)剔除异常值:流速大于10m/s的数据点认为是异常值,进行剔除;
(2.1.3)提取每分钟一条累计水量,并做线性差值,然后按天累加,计算出每个账户的日供水量。
(2.2.1)先处理人工水表抄码数据,过滤掉水表抄码状态不为“正常”的,且水量为“0”的水表抄码记录;
(2.2.2)同月水表水表抄码1-3次,水量合并,日期和水表抄码状态取第二次;
(2.2.3)异常数据规避:进行非开账水量数据规避和极值规避;
(2.2.3.1)对非开账水量数据规避,首先筛选开账水表:在表卡信息表中,筛选“水表功能分类”为“开账”的水表,取其水表抄码值进行人工水表抄码规整化,“水表功能分类”为“计量”的水表,不取值,不参与计算;
(2.2.3.2)然后筛选开账数据:在水表抄码信息表中,筛选“开账日期”不为空的数值,参与人工水表抄码规整化的计算;
(2.2.3.3)对极值进行规避:首先采集各个口径管道上对应的上下限绝对值,判断实时采集的流量的绝对值是否大于进水管口径所对应的流量上下限绝对值,如果大于则实时采集的流量的绝对值无效,先做标记,再采用估算值代替真实值;如果不大于则计算结果有效;
其中上下限绝对值为月度用水量的四倍;估算值为过去三次抄表水量的平均值。
(2.2.4)进行人工水表抄码规范化,将所有水表抄码类型为“正常”的用水量留用;
(2.2.5)若两个“正常”的水表抄码记录中间有除“正常”状态以外的记录,则将两个“正常”水表抄码记录之间的用水量[a,b)相加,并除以两个“正常”水表抄码之间的时间间隔,计算每个用户每天的用水量。
(3)判断供水量和售水量是否计算完毕,如果计算完毕则进入步骤(4),如果没有计算完毕则继续等待直至计算完毕并进入步骤(4);
(4)启动产销差csc;将所需要计算的dma、站点,按dma、站点个数进行分组,并把dma、站点分组数据放入待计算的队列;
(5)判断是否有未计算数据,如果否则进入步骤(9),如果是则等待并进入步骤(6);
(6)判断队列中是否有数据,如果有数据则进入步骤(7),如果没有数据则进入步骤(9);
(7)创建启动node并获取未计算的数据,然后计算产销差;
主动从当前的产销差csc中待计算的队列中请求分组数据,进行产销差的计算(给出具体的产销差公式并对公式中涉及到的参数:
(7.1)根据供水管理所及其下属站点和dma中取出该管理区域的日供水量。
(7.2)取出供水管理所及其下属站点和dma中的日售水量进行定义),累加,计算出供水管理所及其下属站点和dma中的售水量
(7.3)根据产销差=(供水量-售水量)/供水量,计算出产销差。
(8)判断是否有未计算数据,如果有则返回步骤(7)重新获取数据;如果否则结束node;
(9)关闭csc,直至所有csc执行完毕;
(10)判断步骤(7)中,计算得到的产销差是否大于20%,如果是则该区域管网系统漏损严重需要排查,如果否则该区域管网系统安全。
供水行业产销差计算是一套复杂的流程,环环相扣,如图2,首先需要对流量仪、考核表、单位用户、远传小表、人工抄码进行规整化,通过模型计算出供水量、售水量(单位用户、居民用户)的日水量,然后对远传和人工抄码进行自动合并,最后用各个模块计算出来的的数据,进行站点和dma的产销差计算。
从图2中可以看到,从原始数据到规整化最后再到计算产销差,有的可以并行执行,但也有必须等到其他计算模块完成之后才能开始计算,如果单纯使用分布式计算肯定达不到效果,所以我们设计了cmp机制,把每个需要计算的模块组成自己的csc,通过注册机制注册到cmp。而计算模块的数量、创建和启动不由计算模块其本身定时驱动,交给每个csc控制,由平台通过csc控制各自计算模块组的生命周期。这样我们在每个csc加上标记,通过配置文件或者接口方式,设置好优先级和每个csc执行的步骤,可以做到计算模块的并行执行,充分利用系统资源,也保证了每个计算模块的顺序性。而计算服务中心通过切分账号、所站、dma对所需要计算的数据进行二次分割,在不同机器上创建多个相同的计算模块组,子计算模块从csc的数据队列拿到自己所需要计算的数据进行计算,然后各自存储。
具体实现如图3所示,关键组件:
1、cpm:主节点启动一个全局控制器,用户接收csc注册上来的服务(调用接口、地址、级别、先决执行条件等),并决定csc计算顺序。
2、csc:计算服务中心,根据账号、dma、站点数量,进行分组并在一台或者多台服务器上启动一个或者多个node。控制node的生命周期。
3、node:是一个计算容器,一个物理节点可以启动多个node,node与node之间环境相互隔离,node启动后主动向csc服务中心获取没有进行计算的分组数据,进行计算,计算完成后将数据存储到数据库中。
其中,产销差:产销差率,在国外它被称为“未计量水百分率”,指的是供水企业提供给城市输水配水系统的自来水总量与所有用户的用水量总量中收费部分的差值定义为产销差水。产销差水=免费供水量+物理漏水量+帐面漏水量。
dma:districtmeteredarea分区管理:dma分区管理是控制城市供水系统水量漏失的有效方法之一,其概念是在1980年初,由英国水工业协会在其水务联合大会上首次提出。在报告中,dma被定义为供配水系统中一个被切割分离的独立区域,通常采取关闭阀门或安装流量计,形成虚拟或实际独立区域。通过对进入或流出这一区域的水量进行计量,并对流量分析来定量泄漏水平,从而利于检漏人员更准确的决定在何时何处检漏更为有利,并进行主动泄漏控制。
node:计算节点:计算模块组中的最小计算单元,负责从未计算队列读取数据、计算并存储数据。
cmp:controlmanagementplatform控制管理平台:负责编排每个计算服务中心的流程,控制计算服务中心的启动,管理整套计算的流程。
csc:computerservicecenter计算服务中心:一个有相同计算模块组组成的计算中心,负责控制计算模块组的大小,创建,启动,消亡,管理node的生命周期。
实现流程如下:
一、供水量、售水量、产销差csc启动并向cmp注册,提交产销差计算的先决条件(产销差必须供水量、售水量计算完毕),cmp首先启动不需要先决条件的供水量、售水量csc并行计算。供水量计算先是规整化数据,然后拿到每分钟一条累计水量,做线性差值,然后按天累加,计算出每个账户的日供水量;售水量计算是先处理人工抄码数据,,然后进行人工抄码规整化;最后计算出用户、dma(dma下账户日售水量累加)、站点(站点下账户日售水量累加)的售水量。
其中供水量规整化数据的步骤为:
1.处理原始数据-时间规整:
将总累积值处理成每5分钟1个点的数据,计算瞬时值。
2.剔除异常值:
流速大于10m/s(可配)的数据点认为是异常值,进行剔除。
售水量计算先处理人工水表抄码数据的步骤为:
1.过滤掉抄码状态不为“正常”的,且水量为“0”的抄码记录。
2.同月多抄码,水量合并,日期和抄码状态取第二次。
3.异常数据规避
3.1.非开账水量数据规避:筛选同时符合以下条件的数据进行人工抄码规整化:
3.1.1.开账水表筛选
在表卡信息表中,筛选‘水表功能分类’为‘开账’的水表,取其抄码值进行人工抄码规整化,‘水表功能分类’为‘计量’的水表,不取值,不参与计算。
3.1.2.开账数据筛选
在抄码信息表中,筛选‘开账日期’不为空的数值,参与人工抄码规整化的计算。
3.2极值规避
3.2.1各种口径管道流量上下限绝对值如图4所示,若某用户绝对值大于进水管口径所对应的流量上下限绝对值,则该计算结果被判断为无效,做标记,并采用估算值代替真实值。
3.2.2上下限绝对值暂定为月水量的4倍。
3.2.3估算值为过去三次抄见水量(规整化前的水量)的平均值。
其中,进行人工抄码规整化的步骤为:
1.1将所有抄码类型为‘正常’的用水量留用;
1.2若两个‘正常’的抄码记录中间有除“正常”状态以外的记录(包含伪正常),则将两个‘正常’抄码记录之间(包尾不包头)的所有用水量相加,除以两个“正常”抄码之间的时间间隔,计算每个用户每天的用水量(m3/d)。
2、cmp定时轮询供水量、售水量、产销差csc,当供水量、售水量csc返回计算成功结果到cmp,cmp开始启动产销差csc。
3、产销差csc收到cmp计算的要求,将所需要计算的dma、站点,按dma、站点个数进行分组,并把dma、站点分组数据放入待计算的队列。同时产销差csc从中央仓库,拉取开发人员提供的产销差计算模块最新的容器镜像,在计算服务器上创建node。并监控分组数据计算情况,根据群组大小,创建或者删除node,以达到动态控制node数量。
4、node启动之后,主动从当前的产销差csc中待计算的队列中请求分组数据,进行产销差的计算,csc将该组数据从待计算队列移除,放入正在计算的队列中加上标记(时间、计算次数)。计算完成之后把需要的结果存储下来,并通知csc该组数据计算完成,csc收到计算完成的请求之后,将数据移除正在计算队列,如果node计算抛出异常或者计算超过30分钟(根据分组判断,一组数据计算时间不会超过30分钟),csc容错机制将该组数据从正在计算队列移除,重新放入到待计算队列,并标记计算次数。
5、csc定时查询待计算和正在计算队列,当待计算的数据队列和正在计算的数据队列为空时,关闭当前已经启动的node,并通知cmp产销差计算已经完成。
本发明的关键点和欲保护点为:
1、cmp机制,计算模块本身不控制计算,而交由控制平台自己自动根据先决条件自动调用。
2、csc机制,将账号、dma、所站进行分组,根据分组数量,动态创建启动node,并管理node的生命周期。
3、node计算时,主动获取所需计算分组的账号、dma、站点,达到无状态启动服务,使用容器技术达到与具体服务器无关。
- 还没有人留言评论。精彩留言会获得点赞!