目标图像检索方法及系统与流程
本发明涉及图像处理领域,尤其涉及一种目标图像检索方法及系统。
背景技术:
特征点匹配算法是实现图像拼接、图像融合以及目标识别和跟踪的关键技术之一,如何提高图像匹配的效率和正确率一直是图像处理和机器视觉研究领域的热点。
现有的基于特征点匹配算法的目标检索方法主要包括特征点提取和特征点匹配两部分内容。图像特征点提取是指检测出图像中具有代表性的关键点,并获取关键点的特征描述子,通常使用sift,surf以及orb等算法,提取图像的特征点及特征描述算子;特征点匹配通常是基于特征描述算子进行的,上述特征描述算子通常是一个向量,两个特征描述算子的之间的距离可以反应出其相似的程度,如果这两个特征点比较相似,那么两者就可以匹配。根据不同类型的描述算子,可以选择不同的距离度量,例如对于浮点类型的描述算子,可以使用其欧式距离作为度量;对于二进制类型的描述算子可以使用其汉明距离作为度量。有了计算描述算子相似度的方法,在特征点集合中寻找与待处理图像中的待处理特征点最相似的特征点,这就是特征点匹配。
关于匹配操作,一般使用暴力匹配方法,计算当前待处理特征点与图像样本库中其中一幅图像样本上所有样本特征点之间的距离,然后将得到的距离排序,取距离最近的一个特征点作为匹配点,再依次对图像样本库中的每幅图像样本作上述操作;另一种优化的匹配算法,为了排除因为图像遮挡和背景混乱而产生的无匹配关系的特征点,通常会比较待处理特征点与图像样本库中其中一幅图像样本上最近邻距离特征点与次近邻距离样本特征点的相似度,如果这个待处理特征点与上述最近和次近样本特征点都很相似,就把这个待处理样本点去除,以降低误匹配率。
但是现有方案主要存在如下问题:
1)特征点提取过量且存在冗余,导致每增加一个特征点都至少需要比较一轮,并且其中包含大量的无谓比较过程,严重降低了匹配效率。
2)比较最近邻与次近邻距离的匹配方式,虽然可以排除图像遮挡和背景混乱而产生的无匹配关系的特征点,但是图像样本库的图像样本本身也存在相似的冗余特征点,导致最近邻距离与次近邻距离样本特征点的距离变小,匹配就会产生误判的情况,错将可靠的特征点滤除。
技术实现要素:
针对上述问题,本发明的目的是提供一种目标图像检索方法及系统,以此提高匹配速度及精确度,改善图像检索效率。
本发明采用的技术方案如下:
一种目标图像检索方法,包括:
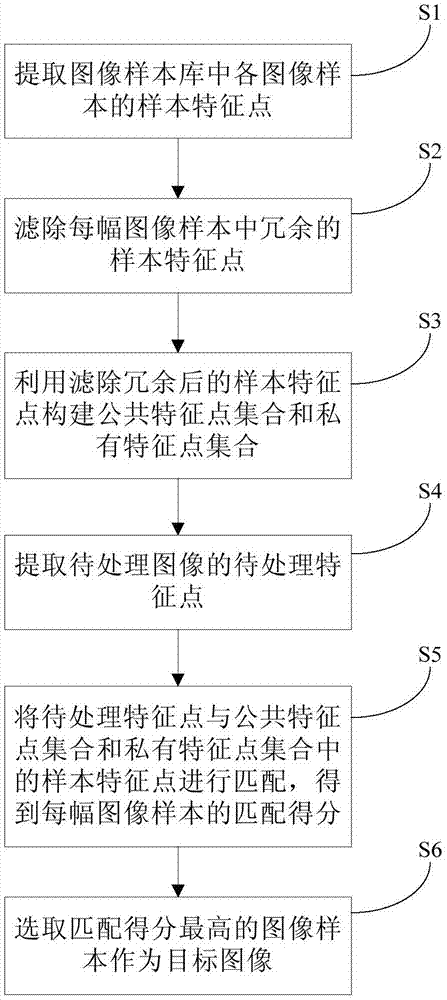
提取图像样本库中各图像样本的样本特征点;
滤除每幅图像样本中冗余的样本特征点;
利用滤除冗余后的样本特征点构建公共特征点集合和私有特征点集合;
提取待处理图像的待处理特征点;
将所述待处理特征点与所述公共特征点集合和所述私有特征点集合中的样本特征点进行匹配,得到每幅图像样本的匹配得分;
选取匹配得分最高的图像样本作为目标图像。
可选地,所述利用滤除冗余后的样本特征点构建公共特征点集合和私有特征点集合包括:
根据预设的第一相似度标准,利用滤除冗余后的样本特征点构建基于一个样本特征点的相似特征点集合;
将图像样本库中所有相似特征点集合汇集为公共特征点集合;
将不在公共特征点集合的样本特征点构建为与图像样本相对应的私有特征点集合。
可选地,所述根据预设的第一相似度标准,利用滤除冗余后的样本特征点构建基于某个样本特征点的相似特征点集合包括:
将一幅图像样本中滤除冗余后的各样本特征点分别与其余图像样本中滤除冗余后的样本特征点进行一一比对;
将符合所述第一相似度标准的样本特征点构建为基于当前样本特征点的相似特征点集合,直至在所有样本特征点比对完成后,得到多个基于不同的样本特征点的相似特征点集合。
可选地,所述将图像样本库中所有相似特征点集合汇集为公共特征点集合包括:
计算每个所述相似特征点集合内所有样本特征点的均值特征向量;
将所有相似特征点集合的均值特征向量汇集为所述公共特征点集合;
所述将所述待处理特征点与所述公共特征点集合和所述私有特征点集合中的样本特征点进行匹配包括:
依次将所述待处理特征点与所述公共特征点集合中的各均值特征向量进行匹配,并确定与所述待处理特征点相匹配的样本特征点所对应的图像样本;
将未与所述公共特征点集合中的样本特征点相匹配的所述待处理特征点,依次与所有所述私有特征点集合中的样本特征点进行匹配;
根据两次匹配结果,确定每幅图像样本中与所述待处理特征点相匹配的样本特征点的数目以及公共/私有属性。
可选地,所述方法还包括:
按照预设的图像特征标准将图像样本库中的每幅图像样本划分为多个图像区域;
所述提取图像样本库中各图像样本的样本特征点包括:
以所述图像区域为单位,提取各图像样本的样本特征点,以使每个样本特征点包含图像区域信息;
所述滤除每幅图像样本中冗余的样本特征点包括:
以所述图像区域为单位,将每个图像区域内的样本特征点进行自比较,并按照预设的第二相似度标准滤除冗余的样本特征点。
可选地,所述以所述图像区域为单位,将每个图像区域内的样本特征点进行自比较,并按照预设的第二相似度标准滤除冗余的样本特征点包括:
计算图像样本中各所述图像区域的特征中心点;
分别计算一个图像区域内符合所述第二相似度标准的两个相似样本特征点,距其他图像区域的特征中心点的距离均值;
将该两个相似样本特征点中,所述距离均值较小的样本特征点滤除掉。
可选地,所述得到每幅图像样本的匹配得分包括:
预先根据不同的图像区域内提取到的样本特征点数目,设置区域基线分数;并预先为具有私有属性的样本特征点设置第一权重系数,为具有公共属性的样本特征点设置第二权重系数,其中第一权重系数大于第二权重系数;
根据图像区域信息确定每幅图像样本中与所述待处理特征点相匹配的样本特征点所在的图像区域;
根据所述区域基线分数、所述第一权重系数、所述第二权重系统、每个图像区域内与所述待处理特征点相匹配的样本特征点的数目以及公共/私有属性,计算每个图像区域的匹配子得分;
将一幅图像样本中的所有所述匹配子得分累加,得到对应该图像样本的匹配得分。
可选地,所述方法还包括:
在进行匹配前,按照预设的第二相似度标准对提取到的所述待处理特征点进行冗余滤除操作。
一种目标图像检索系统,包括:
第一特征提取模块,用于提取图像样本库中各图像样本的样本特征点;
第一冗余滤除模块,用于滤除每幅图像样本中冗余的样本特征点;
特征集合构建模块,用于利用滤除冗余后的样本特征点构建公共特征点集合和私有特征点集合;
第二特征提取模块,用于提取待处理图像的待处理特征点;
特征匹配模块,用于将所述待处理特征点与所述公共特征点集合和所述私有特征点集合中的样本特征点进行匹配,得到每幅图像样本的匹配得分;
检索结果选取模块,用于选取匹配得分最高的图像样本作为目标图像。
可选地,所述特征集合构建模块具体包括:
相似特征点集合构建单元,用于根据预设的第一相似度标准,利用滤除冗余后的样本特征点构建基于一个样本特征点的相似特征点集合;
公共特征点集合构建单元,用于将图像样本库中所有相似特征点集合汇集为公共特征点集合;
私有特征点集合构建单元,用于将不在公共特征点集合的样本特征点构建为与图像样本相对应的私有特征点集合。
可选地,所述相似特征点集合构建单元具体包括:
比对子单元,用于将一幅图像样本中滤除冗余后的各样本特征点分别与其余图像样本中滤除冗余后的样本特征点进行一一比对;
相似特征点集合构建子单元,用于将符合所述第一相似度标准的样本特征点构建为基于当前样本特征点的相似特征点集合,直至在所有样本特征点比对完成后,得到多个基于不同的样本特征点的相似特征点集合。
可选地,所述公共特征点集合构建单元具体包括:
计算子单元,用于计算每个相似特征点集合内所有样本特征点的均值特征向量;
汇集子单元,用于将所有相似特征点集合的均值特征向量汇集为所述公共特征点集合;
所述特征匹配模块具体包括:
公共特征点匹配单元,用于依次将所述待处理特征点与所述公共特征点集合中的各均值特征向量进行匹配,并确定与所述待处理特征点相匹配的样本特征点所对应的图像样本;
私有特征点匹配单元,用于将未与所述公共特征点集合中的样本特征点相匹配的所述待处理特征点,依次与所有所述私有特征点集合中的样本特征点进行匹配;
匹配信息确定单元,用于根据两次匹配结果,确定每幅图像样本中与所述待处理特征点相匹配的样本特征点的数目以及公共/私有属性。
可选地,所述系统还包括:
图像区域分割模块,用于按照预设的图像特征标准将图像样本库中的每幅图像样本划分为多个图像区域;
所述第一特征提取模块具体用于:
以所述图像区域为单位,提取各图像样本的样本特征点,以使每个样本特征点包含图像区域信息;
所述第一冗余滤除模块具体用于:
以所述图像区域为单位,将每个图像区域内的样本特征点进行自比较,并按照预设的第二相似度标准滤除冗余的样本特征点。
可选地,所述第一冗余滤除模块具体包括:
特征中心点计算单元,用于计算图像样本中各所述图像区域的特征中心点;
距离均值计算单元,用于分别计算一个图像区域内符合所述第二相似度标准的两个相似样本特征点,距其他图像区域的特征中心点的距离均值;
自滤除单元,用于将该两个相似样本特征点中,所述距离均值较小的样本特征点滤除掉。
可选地,所述特征匹配模块还包括:
分值系数预设单元,用于预先根据不同的图像区域内提取到的样本特征点数目,设置区域基线分数;并预先为具有私有属性的样本特征点设置第一权重系数,为具有公共属性的样本特征点设置第二权重系数,其中第一权重系数大于第二权重系数;
区域确定单元,用于根据图像区域信息确定每幅图像样本中与所述待处理特征点相匹配的样本特征点所在的图像区域;
匹配子得分计算单元,用于根据所述区域基线分数、所述第一权重系数、所述第二权重系统、每个图像区域内与所述待处理特征点相匹配的样本特征点的数目以及公共/私有属性,计算每个图像区域的匹配子得分;
匹配得分计算单元,用于将一幅图像样本中的所有所述匹配子得分累加,得到对应该图像样本的匹配得分。
可选地,所述系统还包括:
第二冗余滤除模块,用于在进行匹配前,按照预设的第二相似度标准对提取到的所述待处理特征点进行冗余滤除操作。
本发明首先通过对提取到的特征点进行冗余滤除操作,不但使后续的操作过程可以减少无谓的匹配次数,同时由于消除了图像样本库中图像样本自身存在的相似特征点,还能排除图像样本中因遮挡和背景混乱而产生的无匹配关系的特征点,即能够直接使用最近匹配原则进行特征点匹配;并且,本发明提出根据图像样本之间的相似度,利用滤除冗余后的样本特征点构建公共特征点集合和私有特征点集合,再将待处理特征点与公共特征点集合和私有特征点集合中的样本特征点进行匹配,由此可见,本发明在前述滤除操作后进一步精简图像样本的特征表达,以划分公共和私有两类特征方式提升对图像样本库的遍历速度,在效率和效果上均有明显的改善。
进一步地,本发明提出对图像样本进行图像区域划分,并以划分后的图像区域作为单位进行特征提取以及冗余自滤除操作。
因此,本发明提出的技术方案使得整个图像检索过程更加简化和精准。
附图说明
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步描述,其中:
图1为本发明提供的目标图像检索方法的实施例的流程图;
图2为图1实施例中步骤s3的具体实施例的流程图;
图3为本发明提供的目标图像检索方法的较佳实施例的流程图;
图4为本发明提供的计算匹配得分的实施例的流程图;
图5为本发明提供的目标图像检索系统的实施例的方框示意图。
具体实施方式
下面详细描述本发明的实施例,实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
本发明提供了一种目标图像检索方法的实施例,如图1所示,具体可以包括如下步骤:
步骤s1、提取图像样本库中各图像样本的样本特征点。
如前,特征提取指的是检测出图像中具有代表性的特征点作为待匹配项,并把这些特征点作为图像特征,通常可以使用sift,surf以及orb等算法提取图像的特征点,并获取特征点的计算描述算子。特征提取过程有诸多现有技术可供参考,本发明不作赘述。但需说明的是,为了全文表述上的区分,此处将从图像样本库中提出的特征点命名为样本特征点。
步骤s2、滤除每幅图像样本中冗余的样本特征点。
为了保证有足够的特征点可以进行特征匹配,一般在提取图像特征点时会提取过量的特征点,因此增大了特征点集合的冗余;基于这一点本实施例提出在进行后续匹配操作之前对样本特征点进行冗余滤除操作。在实际操作中,可以是将每幅图像样本的样本特征点两两进行比较,如果两个特征点相似,则只保留其中一个特征点。假如当前图像样本提取出若干个特征点,可以但不限于以汉明距离作为相似度计算依据,通过设置取值范围在0到特征距离最大值之间任意值的阈值α,将该图像样本中的某个样本特征点与其余样本特征点依次比较,需指出,α即为下文提及的第二相似度标准的一种具体示例。如果两个样本特征点汉明距离小于阈值α(haming_distance(orb_discript_(i),orb_discript_(j))<α),则判定这两个样本特征点属于冗余特征点,则可以按照随机原则立即删除其中一个(或者也可以删除其中被动比对的样本特征点),接着再继续与其余特征点比较,以此方式直至该图像样本中的所有提取到的样本特征点均比较完成,那么保留下来的样本特征点就是除去冗余的样本特征点。本领域技术人员可以理解的是,α值决定了滤除程度,实操时可根据特征点数据分布情况自行设计α值;并且在实际二选一的筛选过程中,还可以通过计算冗余的样本特征点之间的均值向量,保留更为接近均值向量的一个样本特征点,删除另一个相对远离均值的样本特征点。
按上述利用图像特征表达的相似性滤除图像特征点集合的冗余,这样就能够减少相似特征的冗余,提高匹配的效率和效果;另外,滤除样本库中样本特征点的冗余,不仅可以排除图像遮挡和背景混乱而产生的无匹配关系的特征点,并且无需再比较最近邻和次近邻的距离,直接使用最近距离匹配原则即可。
步骤s3、利用滤除冗余后的样本特征点构建公共特征点集合和私有特征点集合。
该步骤实质上是在前述滤除单幅图像样本的冗余特征后,再通过对保留下来的样本特征点进行归类的方式,精简后续匹配处理时的操作对象。因此可以以每一幅图像样本为处理单元,比较库中所有图像样本之间的样本特征点的相似度,找出所有图像样本的相似特征点,从而建立公共特征点集合;每幅图像样本剩余的(除去公共特征点集合上的)特征点分别作为该图像样本的私有特征点集合。由此可知,经前述滤除冗余操作后的所有样本特征点被划分或标注为两类属性,即公共特征属性和私有特征属性。并且,样本特征点被整理成由公共特征点集合和每幅图像样本的私有特征点集合,这为之后匹配遍历各样本特征点的操作提供了一个便捷“通道”,即可以仅访问公共特征点集合和私有特征点集合,就可以完成对整个样本库的遍历,极大地提高了匹配的速度并能够有效降低误匹配的概率。
步骤s4、提取待处理图像的待处理特征点。
该步骤是对待处理图像的特征提取操作,具体可以参照前述提取样本库中样本特征点的方法,本发明对此不予赘述。但需指出三点,其一、此处命名待处理特征点同样仅为表述层面的区分;其二、步骤s1和步骤s4的提取次序并无先后限制,实际操作中可以同步提取,也可以类似于本实施例中一先一后执行;其三、如前,为了提供更多的特征点进行匹配,在提取待处理图像的待处理特征点时同样可能出现过量的问题,因此更为优选地,可以在进行后续匹配操作前,对提取到的待处理特征点同样进行冗余自滤除操作,其方式可以与前文相同,即待处理特征点进行自比较,滤除其中冗余的、并保留精简的待处理特征点留待后续匹配步骤。
步骤s5、将待处理特征点与公共特征点集合和私有特征点集合中的样本特征点进行匹配,得到每幅图像样本的匹配得分。
通过如上各步骤,在执行匹配操作中即可以直接访问公共特征点集合和私有特征点集合中的样本特征点,例如首先将待处理特征点与公共特征点集合进行匹配,可以统计出与其相匹配的公共特征点属于哪几幅图像样本;然后再将未匹配上的待处理特征点与私有特征点集合进行匹配。具体而言可以是依次将待处理特征点与公共特征点集合中的样本特征点匹配,并确定与待处理特征点相匹配的公共特征点集合中的样本特征点所对应的图像样本;再将未与公共特征点集合中的样本特征点相匹配的待处理特征点,依次与所有私有特征点集合中的样本特征点进行匹配;接着根据两次匹配结果,确定每幅图像样本中与待处理特征点相匹配的样本特征点的数目以及公共/私有属性,也即是匹配完成后获得每个图像样本中与待处理图像相匹配的特征点的数量以及相关信息;最后,计算出针对每幅图像样本的匹配得分,例如通过统计各图像样本中的匹配特征数量,按照一个匹配特征点得1分,进行累加计算;更优地,还可以根据相匹配特征点的公共/私有属性,为不同属性的特征设置权重等。
需说明的是,在其他实施方式中还可以考虑先使待处理特征点与私有特征点集合进行匹配,然后将剩余未匹配上的特征点再与公共特征点进行匹配。
步骤s6、选取匹配得分最高的图像样本作为目标图像。
具体可以是将每幅图像样本的匹配得分进行排序,分数最高的图像样本表明与待处理图像更为匹配,因此最后输出该得分最高的图像样本作为检索目标图像。当然,如果得分最高的图像样本为多个,则可以按照随机原则或者按照私有特征点占比,择一输出。这里需说明的是,因为公共特征点表达的是多个样本之间的共性,而私有特征点则更能示出每幅图像样本自身的特性,因此统计匹配结果通常会偏向私有特征点,在对匹配得分相同的图像样本进行筛选时可以考虑以私有属性作为主要参考因素。
上述实施例通过单幅图像自滤除及特征分类等压缩样本特征点的方式精简图像样本库,在减少匹配次数的同时能够显著加快匹配速度,进而降低误匹配概率以提升匹配的精准度,使得整个检索过程相较现有技术在效率和效果上皆具有明显的改善效果。
关于前述利用滤除冗余后的样本特征点构建公共特征点集合和私有特征点集合的方式,本发明给出如下具体的参考示例,如图2所示,其中可以包括如下步骤:
步骤s31、将一幅图像样本中滤除冗余后的各样本特征点与其余图像样本中滤除冗余后的所有样本特征点进行一一比对;
步骤s32、将符合预设的第一相似度标准的样本特征点构建为基于一个样本特征点的相似特征点集合,直至在所有样本特征点比对完成后,得到多个基于不同的样本特征点的相似特征点集合;
这里需指出的是上述步骤s31和步骤s32是一种构建相似特征点集合的方法示例,本发明不限制在其他实施例中还可以采用其他比对方式获得相似特征点集合。
步骤s33、将图像样本库中所有相似特征点集合汇集为公共特征点集合;
步骤s34、将不在公共特征点集合的样本特征点构建为与图像样本相对应的私有特征点集合。
举例来说,图像样本库中有n个图像样本,从其中第一图像样本提取到的并做了冗余滤除的样本特征点以集合表示为:i1={ai|ai∈i1,i=1,2,…n1},从第二图像样本提取到的并做了冗余滤除的样本特征点集合为:i2={bi|bi∈i2,i=1,2,…n2},其他同理可得in={xi|xi∈i2,i=1,2,…nn};并且所称预设第一相似度标准可以是指按照期望设置的特征距离阈值,如可以设置距离阈值β,其中β取值优选可以比前文中提及的α要小,以此保证图像样本之间相似度评判标准更加严苛。
具体地,首先比较a1和b1两个样本特征点的特征距离,如果distance(a1,b1)<β,判定a1和b1符合预设的第一相似度标准,以此类推继续比较a1和其他样本特征点之间的相似度,直至a1与其余所有的图像特征点都进行比较完成后,将a1及与其相似的样本特征点构建为基于当前样本特征点a1的相似特征点集合ppublic_1={a1,b1…x13},需说明的是,该集合表达式为举例示意。接着继续比较第一图像样本中的其他样本特征点,若第一图像样本中的样本特征点全部比对完成后,再将第二图像样本的未在之前比较中找到相似特征的样本特征点,继续与除了第一图像样本以外的其余所有图像样本的未找到相似特征的样本特征点进行比较。以此类推,在所有图像的样本特征点比对完成后,得到包括m个相似特征点集合的ppublic={ppublic_1,ppublic_2,…,ppublic_m},其中ppublic即为公共特征点集合。如果在前述比较过程中,各图像样本内的某一个或多个样本特征点均未找到相似的特征点,则该点可称为针对各图像样本的私有特征点,也即是该私有特征点表达出对应此副图像样本的独有特性,再将每幅图像的私有特征点构成集合
在此基础上,本发明进一步提供了一种构建公共特征点集合的方式,可通过计算求取前述每个相似特征点集合内所有样本特征点的均值特征向量,如集合ppublic_1的均值特征向量表示为
在前述各实施例及其优选方案基础上,本发明还考虑到由于图像样本中的样本特征点的分布呈现一定规律,即特征点较多的区域通常为图像主要的表征区域,而特征点较少的区域通常则为图像的背景或其他无效区域等,而现有的图像检索过程属于无差别匹配,不同区域的特征点没有区分处理,造成特征点与背景或其他无效区域进行了无谓的匹配。
据此,本发明基于前文内容,提供了一种较佳的目标图像检索方法的实施例,如图3所示,可以包括如下步骤:
步骤s100、按照预设的图像特征标准将图像样本库中的每幅图像样本划分为多个图像区域。
利用图像分割算法,例如常见的快速实现图像分割的工具有分水岭算法、grabcut(基于图论的图像分割)算法等,把每幅图像样本划分成若干个特定的、具有独特性质的图像区域(或称为子区域),一个子区域中的每个像素在某种特性的度量下或是由计算得出的特性都是相似的,例如颜色、亮度、纹理,同一个子区域的样本特征点能够反映该子区域内的图像特性,而且如前文,一般情况下,一幅图像样本的主要表征区域的样本特征点相对较多,而背景或者是其他无效区域的样本特征点相对较少。具体的划分方式可以是对图像样本中的每个像素添加标签,使得具有相同标签的像素具有某种共同视觉特性。图像分割的结果一方面可以是图像样本上全部子区域的集合(这些子区域的全体覆盖了整个图像样本),或者是从图像样本中提取的轮廓线的集合(例如边缘检测)等。
步骤s200、以图像区域为单位,提取各图像样本的样本特征点,以使每个样本特征点包含图像区域信息。
由于前述分割作用,因此在提取图像样本中的各个样本特征点时则使样本特征点附带上不同的区域信息,该区域信息可以作为后续步骤的处理依据,这样更能体现出图像样本的局部特性,使匹配结果更加准确、可靠。
步骤s300、以图像区域为单位,将每个图像区域内的样本特征点进行自比较,并按照预设的第二相似度标准滤除冗余的样本特征点。
以能够表达同一视觉特性的区域内部的各样本特征点之间进行自比对,相较于在整个图像样本中每个样本特征点依次进行比对,本步骤中滤除冗余的效率会有显著提升。需说明的是,这里所称预设的第二相似度标准同样可以是指特征距离,例如前文提及的α,当然在其他实施例中也可以采用其他相似度算法中常用的系数、角度等,对此本发明不做限定。
但可以补充的是,基于图像区域划分,可以对前述滤除每幅图像样本中冗余的样本特征点的方式做进一步改进,前文中提及在同一副图像中当比对出两个相似的样本特征点时,可以采用随机二选一的方式;而在本实施方式中,如果以图像区域为单位进行自滤除,则还可以先计算各个图像区域的特征中心点,所谓特征中心点可以是指处于该区域中所有样本特征点的相对中心位置的样本特征点,这里所称的相对中心不一定是指该图像区域的绝对中心,可以是指与样本特征点相关的中心。对于特征中心点的获取方式,可以计算该图像区域内的每个样本特征点到其他样本特征点的距离总和值,再将各个样本特征点的距离总和值排序,从中选取距离总和值最小的样本特征点作为前述特征中心点,当然在实际操作中确定特征中心点不限于此方法,例如还可以计算区域内的各个样本特征点到该图像区域的边界的距离值,选择距离值最小的作为特征中心点,如此等等;接着,再分别计算该区域内符合第二相似度的两个相似的样本特征点,距其他图像区域的中心点的距离均值,例如某个图像样本划分为三个图像区域a、b、c,现在需要对a区域内的两个相似的样本特征点a1和a2进而二选一,则计算出a1距离区域b和区域c的特征中心点的距离为db和dc(a1的距离均值则可以是(db+dc)/2),a2距离区域b和区域c的特征中心点的距离为db’和dc’(a2的距离均值则可以是(db’+dc’)/2);最后进行二选一时,滤除掉距离均值较小的样本特征点,保留距离均值较大的样本特征点,例如若(db+dc)/2小于(db’+dc’)/2,则将a1滤除掉。该二选一的原理是考虑到距离其他图像区域较远的特征才能更能代表本图像区域的图像特征。当然,利用该原理进行二选一时不限于上述方式,还可以分别获取两个相似的样本特征点到其他图像区域的特征中心点的距离,从中分别选择最小距离然后再将该最小距离进行比对。
步骤s400、利用滤除冗余后的样本特征点构建公共特征点集合和私有特征点集合。
该过程可参考前文内容,此处不再赘述。
步骤s500、提取待处理图像的待处理特征点。
该过程可参考前文内容,此处不再赘述。
步骤s600、按照预设的第二相似度标准对提取到的待处理特征点进行冗余滤除操作。
这里需要说明的是,在本步骤中引入了前文提及的第二相似度标准,作为针对待处理图像的冗余待处理特征点的滤除标准,目的是使滤除特征点冗余的判定依据与样本库中单幅图像样本的冗余标准保持一致,而在其他实施例中,也可以不限定二者在冗余滤除操作时的标准一致与否。但是无论冗余滤除操作的标准是否一致,针对多幅图像样本进行样本特征点公共/私有分类时的标准(即前文提到的第一相似度标准),建议比单幅图像内的冗余滤除标准更为严苛为佳。
步骤s700、将待处理特征点与公共特征点集合和私有特征点集合中的样本特征点进行匹配,得到每幅图像样本的匹配得分。
步骤s800、选取匹配得分最高的图像样本作为目标图像。
该过程可参考前文内容,此处不再赘述。
由于在本实施例中样本特征点附带了区域信息,因此步骤s700中关于每幅图像样本的匹配得分的获取方式还可以进一步改进,即可以根据相匹配的样本特征点所在的图像区域以及样本特征点的公共或私有属性来统计得分。每幅图像样本中不同的样本特征点对该图像样本的匹配结果能够产生程度不同的影响,通常是样本特征点较多的区域影响程度明显高于样本特征点较少的区域,因此可以以每个区域的样本特征点数量占比作为该区域特征点的得分基数,例如某一区域的占比为s,则匹配到该区域的每一个样本特征点的得分基数即为s;本领域技术人员能够理解的是,此处在考虑得分基数时所采用的样本特征点数量占比可以是基于未进行滤除冗余操作的原始样本特征点数目,即当前区域样本特征点数目占这幅图像样本的样本特征点总数目的百分比。另外,由于私有特征点更能体现出每幅图像样本的独有特性,保证图像的独有特征占据更大的权重则能够使匹配结果更加准确,因此可以考虑为具有私有属性的样本特征点设置第一权重系数,为具有公共属性的样本特征点设置第二权重系数,其中第一权重系数大于第二权重系数。
具体可以参考图4所示的计算匹配得分的实施例,其包括:
步骤s701、预先根据不同的图像区域内提取到的样本特征点数目,设置区域基线分数;并预先为具有私有属性的样本特征点设置第一权重系数,为具有公共属性的样本特征点设置第二权重系数;
这里需说明,其中第一权重系数大于第二权重系数;也可以考虑不为具有公共属性的样本特征点设置第二权重系数,此时第一权重系数应大于1。
步骤s702、根据图像区域信息确定每幅图像样本中与待处理特征点相匹配的样本特征点所在的图像区域;
步骤s703、根据区域基线分数、第一权重系数、第二权重系统、每个图像区域内与待处理特征点相匹配的样本特征点的数目以及公共/私有属性,计算每个图像区域的匹配子得分;
步骤s704、将一幅图像样本中的所有匹配子得分累加,得到对应该图像样本的匹配得分。
举例而言,一方面图像样本库中第n幅图像样本的第i个区域(假设共有q个区域)的样本特征点数目占这幅图像样本的所有样本特征点数目的比值为pi,且整幅图像样本的所有区域的比值总和为1,表达为
在计算得分之前,会得到对应每幅图像样本的匹配情况,也即是由每幅图像样本中与待处理特征点匹配的样本特征点所附带的区域信息可以指示出该特征点属于哪个区域。结合上述预设的区域基线分数,则可以由一个子区域内的匹配的样本特征点数目,得到该幅图像样本的各子区域的区域基线分数;并且根据匹配上的各样本特征点的公共或私有属性,为其中的私有特征点赋予权重μ,从而得到每个图像区域的匹配子得分。最后将该图像样本中所有的匹配子得分累加,得到该图像样本的最终的匹配得分。将上述计算分数的过程用一种简化的公式表达,则最终的匹配得分计算公式可以是in_score=scon_public+μscon_private。其中,in_score为匹配得分,scon_public为该图像样本中所有具有公共属性且匹配上的样本特征点的基线得分之和,scon_private为该图像样本中所有具有私有属性且匹配上的样本特征点的基线得分之和。当然,上述计算得分的方式仅为一种示意,本领域技术人员还可以根据本发明的启发拓展出其他的计算方案。
本发明通过增加相似特征点滤除机制以及通过相似比较将特征分类的方式,很大程度上压缩了样本库的冗余,从而能够大幅加快特征匹配的时间,并解决了图像样本自身特征点相近产生的匹配误判情况,弥补了特征点滤除方法的存在不足。
进一步地,以图像分割区域为处理单位,能够体现出图像的细节区域,使匹配更加准确。
更进一步地,对统计得分的优化更能突显出图像的特性,使目标图像的检索结果更为可靠。
相应于上述各方法实施例及优选方案,本发明还提供了一种目标图像检索系统的实施例,如图5所示,具体可以包括:
第一特征提取模块,用于提取图像样本库中各图像样本的样本特征点;
第一冗余滤除模块,用于滤除每幅图像样本中冗余的样本特征点;
特征集合构建模块,用于利用滤除冗余后的样本特征点构建公共特征点集合和私有特征点集合;
第二特征提取模块,用于提取待处理图像的待处理特征点;
特征匹配模块,用于将待处理特征点与公共特征点集合和私有特征点集合中的样本特征点进行匹配,得到每幅图像样本的匹配得分;
检索结果选取模块,用于选取匹配得分最高的图像样本作为目标图像。
进一步地,特征集合构建模块具体包括:
相似特征点集合构建单元,用于根据预设的第一相似度标准,利用滤除冗余后的样本特征点构建基于一个样本特征点的相似特征点集合;
公共特征点集合构建单元,用于将图像样本库中所有相似特征点集合汇集为公共特征点集合;
私有特征点集合构建单元,用于将不在公共特征点集合的样本特征点构建为与图像样本相对应的私有特征点集合。
进一步地,相似特征点集合构建单元具体包括:
比对子单元,用于将一幅图像样本中滤除冗余后的各样本特征点分别与其余图像样本中滤除冗余后的样本特征点进行一一比对;
相似特征点集合构建子单元,用于将符合第一相似度标准的样本特征点构建为基于当前样本特征点的相似特征点集合,直至在所有样本特征点比对完成后,得到多个基于不同的样本特征点的相似特征点集合。
进一步地,公共特征点集合构建单元具体包括:
计算子单元,用于计算每个相似特征点集合内所有样本特征点的均值特征向量;
汇集子单元,用于将所有相似特征点集合的均值特征向量汇集为公共特征点集合;
特征匹配模块具体包括:
公共特征点匹配单元,用于依次将待处理特征点与公共特征点集合中的各均值特征向量进行匹配,并确定与待处理特征点相匹配的样本特征点所对应的图像样本;
私有特征点匹配单元,用于将未与公共特征点集合中的样本特征点相匹配的待处理特征点,依次与所有私有特征点集合中的样本特征点进行匹配;
匹配信息确定单元,用于根据两次匹配结果,确定每幅图像样本中与待处理特征点相匹配的样本特征点的数目以及公共/私有属性。
进一步地,系统还包括:
图像区域分割模块,用于按照预设的图像特征标准将图像样本库中的每幅图像样本划分为多个图像区域;
第一特征提取模块具体用于:
以图像区域为单位,提取各图像样本的样本特征点,以使每个样本特征点包含图像区域信息;
第一冗余滤除模块具体用于:
以图像区域为单位,将每个图像区域内的样本特征点进行自比较,并按照预设的第二相似度标准滤除冗余的样本特征点。
进一步地,所述第一冗余滤除模块具体包括:
特征中心点计算单元,用于计算图像样本中各所述图像区域的特征中心点;
距离均值计算单元,用于分别计算一个图像区域内符合所述第二相似度标准的两个相似样本特征点,距其他图像区域的特征中心点的距离均值;
自滤除单元,用于将该两个相似样本特征点中,所述距离均值较小的样本特征点滤除掉。
进一步地,特征匹配模块还包括:
分值系数预设单元,用于预先根据不同的图像区域内提取到的样本特征点数目,设置区域基线分数;并预先为具有私有属性的样本特征点设置第一权重系数,为具有公共属性的样本特征点设置第二权重系数,其中第一权重系数大于第二权重系数;
区域确定单元,用于根据图像区域信息确定每幅图像样本中与待处理特征点相匹配的样本特征点所在的图像区域;
匹配子得分计算单元,用于根据区域基线分数、第一权重系数、第二权重系统、每个图像区域内与待处理特征点相匹配的样本特征点的数目以及公共/私有属性,计算每个图像区域的匹配子得分;
匹配得分计算单元,用于将一幅图像样本中的所有匹配子得分累加,得到对应该图像样本的匹配得分。
进一步地,系统还包括:
第二冗余滤除模块,用于在进行匹配前,按照预设的第二相似度标准对提取到的待处理特征点进行冗余滤除操作。
上述系统实施例及其优选方案,不但减少了特征点匹配的次数,提高了特征点匹配的效率,同时能够进一步压缩样本库的冗余,提高特征点匹配的效率改进,再配合图像分割技术以及计算匹配得分的改进,使得特征点匹配的结果更加精准。因此,本发明提出的系统方案在检索效率和检索效果上均会有较大的改善。
虽然上述系统实施例及优选方案的工作方式以及技术原理皆记载于前文,但仍需指出的是,本发明的各个部件实施例可以以硬件实现,或者以在一个或者多个处理器上运行的软件模块实现,或者以它们的组合实现。可以把实施例中的模块或单元组合成一个模块或单元,也可以把它们分成多个子模块或子单元予以实施。以及
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。以上所描述的系统实施例仅仅是示意性的,其中作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
以上依据图式所示的实施例详细说明了本发明的构造、特征及作用效果,但以上仅为本发明的较佳实施例,需要言明的是,上述实施例及其优选方式所涉及的技术特征,本领域技术人员可以在不脱离、不改变本发明的设计思路以及技术效果的前提下,合理地组合搭配成多种等效方案;因此,本发明不以图面所示限定实施范围,凡是依照本发明的构想所作的改变,或修改为等同变化的等效实施例,仍未超出说明书与图示所涵盖的精神时,均应在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!