一种卷积神经网络推理硬件加速方法及其装置与流程
本发明涉及人工智能数据处理技术领域,具体地说是一种卷积神经网络推理硬件加速方法及其装置。
背景技术:
作为人工智能当前发展阶段中较为重要的一个分支,卷积神经网络正在不断得到高速更新与优化。随着神经网络模型深度与复杂度的增加,训练集准确率在达到峰值饱和后甚至会出现急剧下降的现象,这是由于深度增加导致的梯度爆炸,使得神经网络无法收敛,由此提出了残差网络的概念,使得深层网络中传递的不再是单纯上一层的结果,而是当前输入与之前某层结果的残差值,使得误差梯度在网络中传输降到零值,从而可在提高深度的前提下,使得网络可收敛。
神经网络在移动端的部署仍需占用大量计算与存储资源,这是由其卷积核深度较大,数目较多引起。若能使用专用硬件电路对网络模型计算进行加速,同时在算法上减少参数数目,将使得神经网络的部署难度大大降低。
技术实现要素:
本发明的技术任务是针对以上不足之处,提供一种卷积神经网络推理硬件加速方法及其装置。
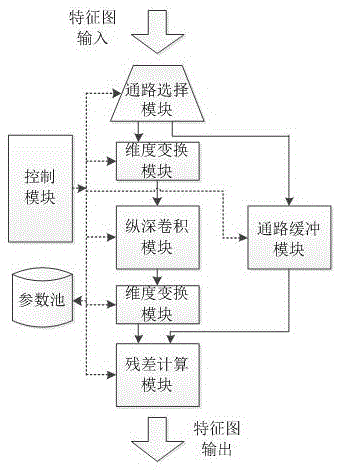
本发明解决其技术问题所采用的技术方案是:一种卷积神经网络推理硬件加速装置,包括通路选择模块、通路缓冲模块、维度变换模块、纵深卷积模块、残差计算模块及参数池和控制模块;
所述的通路选择模块,用于根据控制模块给出的残差变换信息将输入特征图数据送入维度变换模块和/或通路缓冲模块;
所述的通路缓冲模块,用于暂存输入特征图数据,并在卷积计算结束后将暂存内容送至所述的残差计算模块;
所述的维度变换模块,用于根据控制模块给出的变换通道数对输入特征图数据进行通道数变换;
所述的纵深卷积模块,用于对原始卷积进行加速优化,减少卷积核参数及计算量,卷积结果经所述维度变换模块送入所述残差计算模块;
所述的残差计算模块,用于对来自所述通路缓冲模块及维度变换模块的两组特征图数据进行同纬度求和计算;
所述的参数池,用于存储卷积操作是需要的参数;
所述的控制模块,用于控制各模块,完成卷积加速流程。
进一步的,优选的结构为,
所述的纵深卷积模块包括滤波单元和卷积计算单元;
所述的滤波单元,用于使用一定量的蒙板对输入数据进行一次或多次滤波,不对输入通道维度造成改变,仅在每个通道上对各临近输入数据进行变更;
所述的卷积计算单元,用于对结果进行一定次数卷积计算,完成纵深卷积过程。
进一步的,优选的结构为,
所述的蒙板的量等于3x3x输入通道数;所述的卷积计算单元的卷积计算次数等于1x1x通道数。
进一步的,优选的结构为,
所述的维度变换模块,用于将输入特征图数据进行若干次卷积;维度变换模块成对出现,置于纵深卷积模块前后。
进一步的,优选的结构为,
所述的维度变换模块和纵深卷积模块中的1x1的卷积操作硬件资源可复用。
一种卷积神经网络推理硬件加速方法,方法包括:
控制模块将残差变换信息发送给通路选择模块,通路选择模块将特征图数据送入维度变换模块和/或通路缓冲模块;
通路缓冲模块暂存输入特征图数据;
维度变换模块根据控制模块给出的变换通道数对输入特征图数据进行通道数变换;
纵深卷积模块对原始卷积进行加速优化,减少卷积和参数及计算量;通路缓冲模块将暂存的输入特征图数据发送至残差计算模块;
卷积结果经过维度变换模块送入残差计算模块;
残差计算模块将来自通路缓冲模块和维度变换模块的两组特征图数据进行同维度求和计算;完成卷积加速流程。
进一步的,优选的方法为,
纵深卷积模块对原始卷积进行加速优化的方法如下:
首先使用若干的蒙板对输入数据进行一次或多次滤波,不对输入通道的维度造成改变,仅在每个通道上对各临近输入数据进行变更;然后对结果进行若干次卷积计算,完成纵深卷积过程;
其中,所述的蒙板的量等于3x3x输入通道数;所述的卷积计算单元的卷积计算次数等于1x1x通道数。
进一步的,优选的方法为,
所述的维度变换模块将输入特征图数据进行若干次卷积来实现通道数的增加、减少和保持;
若卷积处理之前为通道增加,则在卷积处理之后为通道减少;若卷积处理之前为通道减少,则在卷积处理之后为通道增加;
当残差计算模块两输入通道数不一致时,对通道数较小的输入进行整通道0填充,使得二者通道数一致;当两者长宽参数不一致时,对长宽较小的进行0填充。
进一步的,优选的方法为,
当两者长宽参数不一致时,对长宽较小的进行0填充,所述的0填充包括边界填充和内部插值填充。
一种基于卷积神经网络推理硬件加速方法的服务器,包括一个或多个处理器;
存储装置,用于存储一个或多个程序;
当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现如权利要求6-9中任一所述的方法。
本发明的一种卷积神经网络推理硬件加速方法及其装置和现有技术相比,有益效果如下:
1、维度变换模块的引入,使得在移动端神经网络部署时,可实时根据资源及算法要求进行特征图数据的升维或降维操作,在保证模型表达能力的前提下,对输入数据进行精简压缩,使得模型特征信息更加集中于缩减后的通道中。
2、纵深卷积模块相较于普通卷积,更多采用1x1的卷积操作,大大减少计算和参数量,逻辑结构简单,存储资源需求降低,易于硬件实现,同时乘操作可复用,提高运算效率,使得神经网络在移动端推理时能得到更大程度的加速效果。
附图说明
下面结合附图对本发明进一步说明。
附图1为一种卷积神经网络推理硬件加速装置的原理示意图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明。
本发明为一种卷积神经网络推理硬件加速方法及其装置,使用专用硬件电路对网络模型计算进行加速,同时在算法上减少参数数目,将使得神经网络的部署难度大大降低;引入了纵深卷积模块和维度变换模块,使得神经网络在移动端推理时能得到更大程度的加速效果。
实施例1:
本发明公开了一种卷积神经网络推理硬件加速装置,包括通路选择模块,通路缓冲模块,维度变换模块,纵深卷积模块,残差计算模块,参数池与控制模块。
所述通路选择模块,用于根据控制模块给出的残差变换信息将输入特征图数据送入所述维度变换模块和/或通路缓冲模块;所述通路缓冲模块用于暂存输入特征图数据,并在卷积计算结束后将暂存内容送至所述残差计算模块;所述维度变换模块,用于根据控制模块给出的变换通道数对输入特征图数据进行通道数变换;所述纵深卷积模块,用于以特定方式对原始卷积进行加速优化,减少卷积核参数及计算量,卷积结果经所述维度变换模块送入所述残差计算模块;所述残差计算模块,用于对来自所述通路缓冲模块及维度变换模块的两组特征图数据进行同维度求和计算;所述参数池用于存储卷积操作时需要的参数;所述控制模块用于给出各模块控制信息,完成卷积加速流程;
所述纵深卷积模块,首先使用若干(3x3x输入通道数)的蒙板对输入数据进行一次或多次滤波,不对输入通道维度造成改变,仅在每个通道上对各临近输入数据进行变更;然后对结果进行若干次(1x1x通道数)卷积计算,完成纵深卷积过程;
所述维度变换模块包括通道增加、通道减少与通道数保持,变换方式为将输入特征图数据进行若干次(1x1x原始通道数)卷积;维度变换模块成对出现,置于所述纵深卷积模块前后;若卷积处理之前为通道增加,则在卷积处理之后为通道减少;反之,若卷积处理之前为通道减少,则在卷积处理之后为通道增加;
当所述残差计算模块两输入通道数不一致时,对通道数较小的输入进行整通道‘0’填充,使得二者通道数一致;当二者长宽参数不一致时,对长宽较小的进行‘0’填充,包括边界填充和内部插值填充;
维度变换模块和纵深卷积模块中的(1x1)卷积操作硬件资源可复用;
本发明还保护一种卷积神经网络推理硬件加速方法,方法包括:
控制模块将残差变换信息发送给通路选择模块,通路选择模块将特征图数据送入维度变换模块和/或通路缓冲模块;通路缓冲模块暂存输入特征图数据;
维度变换模块根据控制模块给出的变换通道数对输入特征图数据进行通道数变换;纵深卷积模块对原始卷积进行加速优化,减少卷积和参数及计算量;通路缓冲模块将暂存的输入特征图数据发送至残差计算模块;卷积结果经过维度变换模块送入残差计算模块;残差计算模块将来自通路缓冲模块和维度变换模块的两组特征图数据进行同维度求和计算;完成卷积加速流程。
其中,纵深卷积模块对原始卷积进行加速优化的方法如下:首先使用若干的蒙板对输入数据进行一次或多次滤波,不对输入通道的维度造成改变,仅在每个通道上对各临近输入数据进行变更;然后对结果进行若干次卷积计算,完成纵深卷积过程;其中,所述的蒙板的量等于3x3x输入通道数;所述的卷积计算单元的卷积计算次数等于1x1x通道数。
所述的维度变换模块将输入特征图数据进行若干次卷积来实现通道数的增加、减少和保持;若卷积处理之前为通道增加,则在卷积处理之后为通道减少;若卷积处理之前为通道减少,则在卷积处理之后为通道增加;当残差计算模块两输入通道数不一致时,对通道数较小的输入进行整通道‘0’填充,使得二者通道数一致;当两者长宽参数不一致时,对长宽较小的进行‘0’填充。所述的‘0’填充包括边界填充和内部插值填充。
一种基于卷积神经网络推理硬件加速方法的服务器,包括一个或多个处理器;存储装置,用于存储一个或多个程序;当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现如权利要求6-9中任一所述的方法。
维度变换模块的引入,使得在移动端神经网络部署时,可实时根据资源及算法要求进行特征图数据的升维或降维操作,在保证模型表达能力的前提下,对输入数据进行精简压缩,使得模型特征信息更加集中于缩减后的通道中。纵深卷积模块相较于普通卷积,更多采用1x1的卷积操作,大大减少计算和参数量,逻辑结构简单,存储资源需求降低,易于硬件实现,同时乘操作可复用,提高运算效率,使得神经网络在移动端推理时能得到更大程度的加速效果。
通过上面具体实施方式,所述技术领域的技术人员可容易的实现本发明。但是应当理解,本发明并不限于上述的几种具体实施方式。在公开的实施方式的基础上,所述技术领域的技术人员可任意组合不同的技术特征,从而实现不同的技术方案。
- 还没有人留言评论。精彩留言会获得点赞!