一种基于集成学习的线上内容热度预测方法与流程
本发明涉及自然语言处理领域,尤其涉及一种基于集成学习的线上内容热度预测方法。
背景技术:
在自然语言处理领域,线上内容的热度预测一直是一个热门领域,因为线上内容的热度往往直接影响到相关的收益。本线上内容热度预测发明收集了大量带标记(如浏览数、回复数等)的新闻语料,利用多个模型的集成学习对其热度进行预测,并将预测结果返回给媒体编辑,可有效提升媒体编辑的工作水平。
目前对线上内容的热度预测,大多采用单一预测模型,预测精度有限,且对于热度的衡量指标多考虑阅读量信息、转发量信息、点赞量信息、评论量信息和引用量信息等,过于复杂,可能引起预测的不准确。如发明专利“一种微博话题热度预测系统及方法”,申请号201410368076.x,使用小波变换结合arima回归模型进行预测,模型单一,导致可扩展性不强。发明专利“一种文章热度预测系统及预测方法”,申请号201711454719.2,使用lstm作为预测模块,同样存在模型单一的问题,同时考虑阅读量信息、转发量信息、点赞量信息、评论量信息和引用量信息导致模型过于复杂,可能不符合实际情况,容易造成预测误差。
技术实现要素:
本发明的目的在于提供一种基于集成学习的线上内容热度预测方法,从而解决现有技术中存在的前述问题。
为了实现上述目的,本发明采用的技术方案如下:
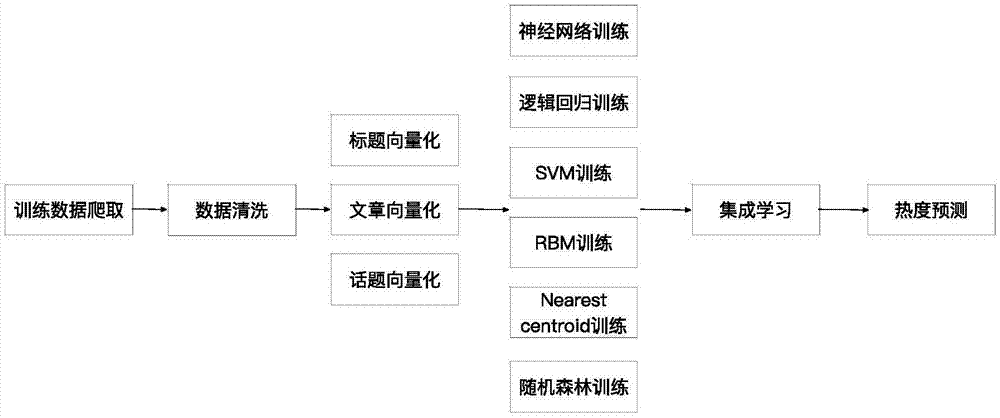
一种基于集成学习的线上内容热度预测方法,包括以下步骤:
s1,预测预料的选择与爬取;
s2,对爬取语料进行预处理;
s3,对预处理后的语料向量化,确定热度阈值;
s4,模型训练与集成。
优选地,所述步骤s1具体包括以下步骤:
s11,确定训练语料爬取的数据来源,选择数据来源时需要考虑数据来源的访问量,数据源与需要预测内容的相似度;
s12,确定需要爬取的内容框架,包括爬取标题和内容;
s13,确定用于预测热度的衡量参数;
s14,编写爬虫爬取相应的内容,并保存至相应的数据库中。
优选地,所述步骤s13中用于预测热度的衡量参数包括点击数、评论数、点赞数和转发数。
优选地,所述步骤2具体包括以下步骤:
s21,将爬取的语料采用相似哈希(simhash)法计算相似度,并删除重复的语料;
s22,利用停用词典将语料中的停用词去掉。
更优选地,步骤s22中所述的停用词为没有实际意义的连接词或语尾助词。
优选地,所述步骤s3具体包括以下步骤:
s31,根据使用场景的具体需求和数据源的数据特性确定热度阈值,选定热度的评价标准;
s32,将语料主题采用话题产生模型进行向量化,可根据语料内容自动区分语料的主题,并将所述语料向量化;采用doc2vec将语料的内容和标题进行向量化,并与主题向量联合为训练模型的输入向量。
优选地,步骤s32中话题产生模型需要根据语料指定话题的种类,包括娱乐、体育、教育和科技中的至少一个。
优选地,所述步骤s4具体包括以下步骤:
s41,选取训练模型,包括逻辑回归、支持向量机、受限玻尔兹曼机、nearestcentroid、神经网络和随机森林,根据单个模型的训练结果从中选择结果最好的两至三个模型;
s42,对选择的基础模型进行集成学习;
s43,对于需要预测的线上内容,首先向量化其标题、话题和内容,采用已训练好的模型进行预测。
优选地,步骤s42所述的集成学习包括以下内容:
当话题向量o是p维的o=[o1,o2,…,op],内容向量c是q维的c=[c1,c2,…,cq],标题向量t也是q维的t=[t1,t2,…,tq],输入变量x=[o,c,t]=[o1,o2,…,op,c1,c2,…,cq,t1,t2,…,tq],为了体现内容和标题对文章热度的贡献,使用x=[o,c’,t’]替代[o,c,t],其中c’=αc,t’=(1-α)t,其中α为贡献参数。热度阈值τ可由训练数据信息源的热度分布决定;
设定从互联网获取的线上内容数据的全集为d={d1,d2,…,dn},其中di为包含题目和内容的文章,每个基础模型的训练集相同,都为u={d1,d2,…,dm},其中m<n;相应地,测试集v=d-u;其中k个基础模型可视为k个函数f1-fk;每个函数fi都可以在训练集u上使用随机梯度下降或者其他方法得以训练;参数α和τ都需要在训练前确定。
优选地,所述训练集选自与预测内容相近的并且有热度标识的数据。
本发明的有益效果是:
本发明提供的基于集成学习的线上内容热度预测方法综合考虑了线上内容的话题、标题和内容质量,使得预测模型具有可扩展性;使用集成学习的方法预测线上内容热度,使得预测具有鲁棒性,且更加准确;性能相近的基础学习器进行集成,可得到较好的效果。
附图说明
图1是实施例1的线上内容热度预测方法示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不用于限定本发明。
实施例
本实施例以新闻类内容热度预测为例,提供一种基于集成学习的线上内容热度预测方法,包括以下步骤:
s1,预测预料的选择与爬取;
s11,确定训练语料爬取的数据来源,选择数据来源时需要考虑数据来源的访问量,数据源与需要预测内容的相似度;一般来说,访问量越大,与预测内容越近似的数据源,其作为训练语料得出的训练模型准确度越高。
s12,确定需要爬取的内容框架,包括爬取标题和内容;本实施例针对新闻类内容需要爬取标题、内容等;对于新闻类内容的热度,由于其具有时效性,只需要考虑其24小时内的热度,故需爬取其相应点击数。值的注意的是,若对于其他线上的内容,通常具有长期影响力,则需要考虑更长时间段内的热度。
s13,确定用于预测热度的衡量参数为点击数(浏览数);通常来说可供选择的参数有点击数(浏览数)、回复数(评论数)、点赞数和转发数等等,可根据具体业务选择某个参数,新闻类业务选择点击数即可。
s14,编写爬虫爬取相应的内容,并保存至相应的数据库中。
s2,爬取语料的预处理;
s21,将爬取的语料采用相似哈希(simhash)法计算相似度,并删除重复的语料;
s22,利用停用词典将语料中的停用词去掉,停用词为没有实际意义的连接词或语尾助词,如“是”、“和”、“但”、“啊”等。
s3,语料向量化及热度阈值的确定;
s31,根据使用场景的具体需求和数据源的数据特性确定热度阈值,选定热度的评价标准,本实施例因为针对新闻类内容,因此采用24小时内的点击数作为热度评价标准;若热度与非热度的比例保持在1:m,则选取数据源评测指标前1/(1+m)的新闻作为其阈值τ。
s32,将语料主题采用话题产生模型(lda)进行向量化,可根据语料内容自动区分语料的主题,并将所述语料向量化;采用doc2vec将语料的内容和标题进行向量化,并与主题向量联合为训练模型的输入向量。如果主题向量为a维,标题向量为b维,内容向量为c维,则训练模型的输入向量为a+b+c维。
s4,模型训练与集成。
s41,选取训练模型,根据单个模型的训练结果选择包括逻辑回归、支持向量机、受限玻尔兹曼机、nearestcentroid、神经网络和随机森林中结果最好的两至三个模型;
逻辑回归(lr):如上所述,将训练语料的内容、标题和主题向量合并为一个n维向量,假设此向量为x=[x1,x2,…,xn],这就是训练模型的输入向量。输出向量y标识该内容为热点新闻的概率,y∈[0,1]。因此,输入输出变量x和y的关系可表示为:
若给定一个包含m个点的训练集{(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))},我们希望对每一个点(x(i),y(i)),y(i)和hθ(x(i))的距离最小,衡量此距离的函数被称为代价函数。对于逻辑回归模型,我们选择如下凸函数:
公式(1)可由随机梯度下降(sgd)求解相应的θ。
支持向量机(svm):如上所述,训练模型的输入向量x(i)为一个n维向量,x(i)=[x1(i),x2(i),…,xn(i)]代表的是一篇文章i。该文章的pv假设为y(i)。因此,该文章可视为一个n+1维空间中的点x(i)=[x1(i),x2(i),…,xn(i),y(i)],给定一个判定新闻热度的pv值,需要找一条边界(线)来区分热度和非热度新闻两个数据集。这两个数据集的边界可定义为:
y(x)=wtx+b(2)
此问题可表示为:
s.t.yi(wxi+b)≥1-ξi,i=1,2,…,m
ξi≥0,i=1,2,…,m
其中υ是惩罚参数,ξi是松弛变量。
受限玻尔兹曼机(rbm):受限玻尔兹曼机是一种生成随机人工神经网络。受限玻尔兹曼机分为可见层单元和隐藏层单元。每个可见单元都连接到所有的隐藏单元。同类单元间没有连接。可见单元vi和隐藏单元hj之间的权值w=(wij)。参数ai和bj分别是可见单元和隐藏单元的补偿参数。(v,h)能量函数可表示为:
e(v,h;θ)=-∑ijwijvihj-∑iaivi-∑jbjhj(4)
其中θ表示受限玻尔兹曼机的参数{w,a,b},因此隐藏向量和可见向量的概率分布可定义为:
其中z(θ)=∑e-e(v,h;θ),因此,一个可见向量的边际概率为:
因此,给定一个含有m个点的训练集v,{(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))},目标是最大化概率乘积
argmaxw∏v∈vpθ(v)(7)
公式(7)可通过constrastivedivergence(cd)算法求解。需要注意的是rbm的输入是联合向量x(i)=[x1(i),x2(i),…,xn(i)],输出为一二进制向量,为了区分文章热度,我们会使用逻辑回归再对此二进制向量进行分类。
nearestcentroid(nc):nc分类器是一种使用类均值来判断点归属的分类模型,也就是将点划分为均质最接近其的一个类。给定一个含有m个点的训练集{(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))},其中x(i)是文章的联合向量,y(i)∈{0,1}为标识文章是否会热的类标签,某个类l平均的centroid为
神经网络(nn):神经网络在本发明中用来作为文章热度的分类器。用于本发明集成学习基础分类器的神经网络共有3个隐藏层,每层的节点都与下层所有的节点全连接。每个连接的权值为wij,其中i代表起始节点,j表示终止节点,如果节点i有s个输入节点,此节点的输出节点可表示为:
其中bi是节点i的偏置,f(·)是激活函数。在本发明中,联合向量x(i)=[x1(i),x2(i),…,xn(i)]是文章i的神经网络输入,假设y(i)是文章i的页面浏览量(pv),则(x(i),y(i))是一个相应的训练点,神经网络可由反向传播(bp)神经网络求解。
随机森林(rf):随机森林本身就是决策树的一个集成学习,若一篇文章可表示为联合向量x=[x1,x2,…,xn],y表示文章是否火热y∈{0,1}。已知训练集为{(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))}可构成决策树,然而,决策树可能会过拟合训练集。随机森林利用多个决策树投票的方式提升预测精度。
s42,对选择的基础模型进行集成学习;假设话题向量o是p维的o=[o1,o2,…,op],内容向量c是q维的c=[c1,c2,…,cq],标题向量t也是q维的t=[t1,t2,…,tq],输入变量x=[o,c,t]=[o1,o2,…,op,c1,c2,…,cq,t1,t2,…,tq],为了体现内容和标题对文章热度的贡献,使用x=[o,c’,t’]替代[o,c,t],其中c’=αc,t’=(1-α)t,其中α为贡献参数。热度阈值τ可由训练数据信息源的热度分布决定。
假设从互联网获取的线上内容数据的全集为d={d1,d2,…,dn},其中di为包含题目和内容的文章,每个基础模型的训练集相同,都为u={d1,d2,…,dm},其中m<n。相应地,测试集v=d-u。其中k个基础模型可视为k个函数f1-fk。每个函数fi都可以在训练集u上使用随机梯度下降或者其他方法得以训练。参数α和τ都需要在训练前确定。
对于热度预测集成学习的伪代码如下:
s43,对于需要预测的线上内容,首先向量化其标题、话题和内容,采用已训练好的模型进行预测。由于线上内容多种多样,可爬取与预测内容相近的,有热度标识(浏览量、回复数、转发数)的数据作为训练集。
经过测试,本实施例发现,对于线上内容热度预测这个任务来说,性能相近的基础学习器集成学习后,能够获得比性能相差较大的基础学习器集成更好的效果。这也就是说,在具体应用的时候,可以首先测试基础学习器的性能,然后集成性能相近的学习器,过程同上。
通过采用本发明公开的上述技术方案,得到了如下有益的效果:
本发明提供的基于集成学习的线上内容热度预测方法综合考虑了线上内容的话题、标题和内容质量,使得预测模型具有可扩展性;使用集成学习的方法预测线上内容热度,使得预测具有鲁棒性,且更加准确;性能相近的基础学习器进行集成,可得到较好的效果。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!