一种内嵌于忆阻器阵列的逻辑运算装置的计算方法与流程
本发明涉及存储器内计算技术领域,具体地说,特别涉及到一种内嵌于忆阻器阵列的逻辑运算装置的计算方法。
背景技术:
现阶段针对基于忆阻器逻辑运算的方法主要有三种,分别是imply电路,magic电路和majority电路。不同于传统cmos工艺,忆阻器利用阻值存储逻辑信息“1”和“0”,并通过改变施加在两端的电压来改变阻值状态,从而完成存储与运算操作。
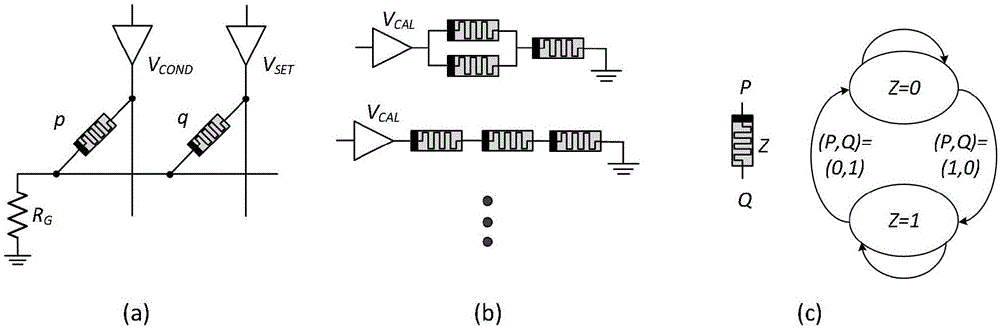
基于忆阻器的imply电路是最先提出的,它向人们展示了忆阻器具备进行逻辑运算的能力。imply电路的基本结构如图1a所示,两个忆阻器并联后共同连接到一个负载电阻。在vcond和vset两种电压的作用下,完成实质蕴涵操作(materialimplication),并将结果写到忆阻器q中,即
然而imply电路存在以下4个缺点:
1)需要额外继承负载电阻,增加了制造的开销与复杂度;2)操作电压种类繁多,增加了控制电路的难度;3)逻辑原语过于单一,在处理复杂的逻辑操作时需要繁琐的操作步骤,降低运算效率;4)imply操作是破坏性操作,即在运算发生时,存储原始输入数据的忆阻器q会被破坏并存入输出的结果。
magic电路的基本结构如图1b所示,通过不同的忆阻器的拓扑结构实现不同的逻辑功能,本质上是通过忆阻器间分压来完成相应的操作。然而对于规则的阵列结构而言,只有“或非”和“非”操作的magic电路结构满足要求,可以集成到存储阵列中。magic电路相对于imply电路的优势在于:
1)逻辑操作是非破坏性的,输入和输出分别由不同的忆阻器表示,逻辑操作不会破坏输入忆阻器的状态;2)无需额外的负载电阻;3)只需要一种控制电压。然而magic电路也存在两个问题,1)与imply类似,由于阵列结构限制了其拓扑结构,导致其逻辑原语过于单一,降低了运算效率;2)输入个数受限,由于magic电路本质上是利用阻值分压方式进行运算,因此当输入忆阻器个数过多时,会对分压结果造成影响,从而导致计算无法正确执行。
majority电路的基本结构如图1c所示,忆阻器两端电压,忆阻器原始状态及忆阻器更新后的状态构成了一个状态转换图,分析各种状态转换后得到基于majority的逻辑形式。这种逻辑运算方式同样存在三个问题:1)与imply电路一样,逻辑操作是破坏性的;2)由于施加在忆阻器两端的控制电压是由输入确定的,因此其控制方式是动态的,这无疑增加了控制难度;3)同样受逻辑原语过于单一的限制。
技术实现要素:
本发明的目的在于针对现有技术中的不足,提供一种内嵌于忆阻器阵列的逻辑运算装置的计算方法,通过差分单元结构及运算单元的引入,丰富了逻辑原语,使电路以“积之和/和之积”的方式进行运算,同时大幅减少写回操作,从而有效的提高的运算效率。
本发明所解决的技术问题可以采用以下技术方案来实现:
一种内嵌于忆阻器阵列的逻辑运算装置的计算方法,包括如下步骤:
1)互补形式的输入表示;
2)“和之积/积之和”的逻辑运算形式;
3)缓存中间计算结果。
进一步的,所述互补形式的输入表示的方法如下:
针对互补形式的输入,利用反向连接的差分单元结构实现。
进一步的,所述差分单元结构通过堆叠方式得到,而不引入额外的面积开销。
进一步的,所述“和之积/积之和”的逻辑运算形式的方法如下:
利用阵列本身在位线上的“线或”操作实现最大项;
通过将敏感放大器输出的最大项取反得到最小项;
引入运算单元cu完成最大项或最小项的合并。
进一步的,所述引入运算单元cu完成最大项或最小项的合并的方法如下:
针对“积之和”,要求使用最小项进行运算,需要在运算单元中集成或门;
针对“和之积”,要求使用最大项进行运算,需要在运算单元中集成与门。
进一步的,所述缓存中间计算结果的方法如下:
利用运算单元cu缓存迭代过程中产生的中间结果。
进一步的,所述利用运算单元cu缓存迭代过程中产生的中间结果的方法为:
复用传统存储阵列中的行缓冲,用于在运算过程中缓存迭代产生的中间结果。
与现有技术相比,本发明的有益效果在于:
本发明通过差分单元结构及运算单元的引入,丰富了逻辑原语,使电路以“积之和/和之积”的方式进行运算,同时大幅减少写回操作,从而有效的提高的运算效率。
运算步骤:相比于imply,magic和majority电路实现的“异或”功能,本发明可以分别减少约68.8%,50%,91.7%的运算步骤,这里的步骤并没有区分读写操作,事实上在这些步中,本发明的写操作的比例仅为20%,而其余三种写操作所占比例分别为100%,100%和60%;
运算占用的单元数目:相比于imply,magic和majority电路实现的“异或”功能,本发明运算占用的单元数目可以分别减少87.5%,87.5%和66.7%;
面积开销:差分单元结构并不影响单元大小,因为可以在垂直方向堆叠制造,然而为满足足够的驱动力,外围电路需要额外6.2%的开销。此外运算单元额外引入10.2%的面积开销。
附图说明
图1为本发明所述的基于忆阻器的逻辑电路示意图。
图2为本发明所述的忆阻器结构示意图。
图3为本发明所述的基于忆阻器的存储器内计算架构示意图。
图4为本发明所述的运算单元(cu)的结构示意图。
具体实施方式
为使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体实施方式,进一步阐述本发明。
忆阻器本身是一种存储器件,但是由于其特有的阻变特性,这让它在存储器内计算领域很有应用前景。图2为忆阻器的结构示意图,它有正负两个电极,电极之间是具有阻变特性的材料,当向忆阻器施加正向电压超过阈值电压von时电阻为低阻态,当向忆阻器施加负向电压超过阈值电压voff时电阻为高组态。当电压值介于两个阈值电压之间时阻值状态不会发生改变。于是可以利用忆阻器阻值变化的特性,放置在电路中以一定的拓扑结构排列,控制输出电压的高低,从而模拟常规逻辑运算。因为忆阻器既可以作为存储器件,又可以进行逻辑运算,这样不需要传统计算机中访存的操作,使得整体运算速度有了很大的提高。
本发明对传统忆阻器存储阵列结构进行改进,提出一种新的基于忆阻器的存储内计算架构,这种新的架构一方面能够在不对本身存储值破坏的前提下实现任意的布尔逻辑运算,另一方面丰富了逻辑运算原语,减少运算中写操作,提高整体运算效率。
实施例
如图3所示,新的架构以两个差分的忆阻器存储一个比特,在忆阻器阵列的末尾添加一级cu(计算单元),用于计算与暂存并迭代累加逻辑表达式的中间结果。图中左下角fsm为状态机,用于控制阵列的读写时序,从而保证存储器内计算按照规定的正确步骤进行。
对于现有的基于忆阻器的逻辑电路而言,其基本思想是不断迭代电路提供的逻辑原语以完成复杂逻辑的运算,然而逻辑原语单一性加重了运算步骤,并且产生大量的中间结果,这部分结果需要缓存,因此整个运算过程还涉及大量写操作。由于忆阻器的写操作时间普遍较长,因此进一步限制了运算效率。本发明针对这两个影响运算效率的关键因素进行改进。由于忆阻阵列本身可以通过激活多行字线在位线上实现“线或”操作,因此可以围绕忆阻阵列这一基本特性对其逻辑运算进行优化。首先,如果可以同时提供输入及输入的取反,则通过阵列本身的“线或”操作,就可以在一个运算步骤中实现任意的最大项,同时如果对“线或”的结果取反,则可以得到任意的最小项,如此便可以极大的丰富逻辑原语;其次将最大项或最小项累计起来以“和之积”或“积之和”的形式得到任意的逻辑表达式,且运算的步骤仅与最大项或最小项的个数有关,从而极大的提高了运算效率;最后,如果可以省去最大项或最小项累积过程中产生的中间变量的写回操作,则可以进一步的缩短计算延迟。
本发明所述的一种内嵌于忆阻器阵列的逻辑运算装置的计算方法,主要包括互补形式的输入表示,“和之积/积之和”的逻辑运算形式和中间结果缓存。
互补形式的输入表示
在本发明中,通过差分单元结构提供互补的输入表示,如图3所示,每个存储比特单元用两个差分的忆阻器(2r)来存储,我们分别称为ro和rd。位于上面的ro与对应的行线wlo和列线bl反向连接,用来存储该比特的原始值,位于下面的rd与对应的行线wld和列线bl正向连接,用来存储该比特的差分值。两个re忆阻器共享同一根列线并且在垂直方向堆叠而成,所以在阵列中所占面积与传统忆阻器阵列相同。通过这种差分结构,当激活wlo时,可以得到原始输入,而当激活wld时,可以得到原始输入的取反值,这样就可以在运算中灵活的选取输入的形式而无需多余的取反步骤;
“和之积/积之和”的逻辑运算形式
虽然阵列本身可以在位线上实现“线或”操作实现最大项,并可以通过将敏感放大器的输出取反得到最小项,但如果要将这些最大项或最小项合并,则需要在阵列底部引入一排运算单元(cu),cu的原理图如图4所示,其核心部件是一个寄存器,通过缓存上一次的迭代结果并与当前位线的“线或”结果累积逐步完成逻辑运算,因此其操作步骤的数目为最大项或最小项的个数。cu提供多条数据通路,用于存取或运算操作。在普通的存储器读写操作中,cu通过路径3、4作为读写数据的缓冲,类似传统存储器中的行缓冲模块。对于布尔逻辑运算,为了得到“积之和/和之积”的格式需要通过路径2反复进行迭代,并且为了实现“积之和/和之积”的“或/与”操作,需要在路径2中集成对应的“或门/与门”。借助cu的功能,可以轻松的将最大项和最小项累积起来实现“和之积/积之和”的逻辑运算形式。
缓存中间计算结果
cu内部的寄存器可以缓存迭代过程中产生的中间结果,从而可以显著的减少写回操作的数量。具体来说,“积之和/和之积”布尔逻辑运算过程中产生的n-1个中间结果都可以被cu缓存并累积,其中n表示最大项或最小项的个数,预期结果得到之后cu将驱动列线写回最终结果,这意味着,运算逻辑越复杂,cu缓存的效益越明显。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!