对称矩阵的三角部分存储装置和并行读取方法与流程
本发明实施例涉及矩阵运算技术领域,更具体地,涉及对称矩阵的三角部分存储装置和并行读取方法。
背景技术:
对称矩阵(symmetricmatrix)是对称的方阵,在数字信号处理领域有着广泛的使用。例如,许多信号检测算法需要利用实数自相关矩阵得到信号的二阶统计特征。对称矩阵的求解复杂度随着矩阵阶数增加而平方增加,为了减小计算复杂度,可以根据对称矩阵的对称特性,只计算对称矩阵的上(下)三角部分,对称矩阵的下(上)三角部分可以根据对称特性由上(下)三角部分求出。并且如果能够合理的安排对称矩阵元素在存储器中的位置,使得在不影响数据并行存取需求的条件下,存储器只需要保存上(下)三角部分元素的值,那么就可以节省接近一半的数据存储空间。
但是,对称矩阵运算,如对称矩阵乘法和对称矩阵与向量乘,通常需要并行读取对称矩阵的行向量或列向量。这些行列向量通常既包含上三角部分矩阵的元素又包含下三角部分矩阵的元素。对于只保存了上(下)三角部分元素的对称矩阵,由于上(下)三角矩阵无法包含需要读取的行列向量的全部元素,需要根据对称特性对矩阵运算进行特殊的优化才能完成运算功能。现有技术给出了多种矩阵运算优化的方案,具体包括:中国专利cn107590106a公开了一种应用于对称矩阵与向量乘法的计算方法,利用矩阵分块和对角矩阵数据扩展的方法进行矩阵向量乘法;第二种方法是根据blas(basiclinearalgebrasubprograms)库中的对称矩阵乘法算法,从算法的最内层循环进行循环展开,并映射到硬件的并行处理单元上;第三种方法是将对称矩阵分解为上三角矩阵和根据对称特性生成的下三角矩阵,分别进行矩阵乘法,再将结果矩阵相加。
以上方法均可以应用于对称矩阵运算。但是第一种方法将上(下)三角矩阵进行数据扩展成为对称矩阵的过程需要额外的数据搬移和时间开销。第二种方法通过对原始算法进行并行优化实现了矩阵运算,但是由于最内层循环的循环次数可变且通常较小,导致数据存取的并行度不高,从而降低了硬件利用效率和算法效率。第三种方法虽然有效地减少了计算复杂度,但是仍然受限于并行数据存取的速度,导致硬件利用率和算法的效率不高。
技术实现要素:
为了解决现有技术中存在的受限于三角矩阵的行列向量数据存取的并行度不高,导致硬件利用率和矩阵运算算法效率不高的问题,本发明实施例提供一种对称矩阵的三角部分存储装置和并行读取方法。
根据本发明实施例的一个方面,提供一种对称矩阵的三角部分存储装置,包括:
存储模块选择电路,用于选择待存取的对称矩阵上三角部分或下三角部分各元素对应的存储模块;
地址生成电路,用于计算所述待存取的对称矩阵上三角部分或下三角部分各元素在其对应的存储模块中的逻辑地址;
并行的m个存储模块,用于存储所述待存取的对称矩阵上三角部分或下三角部分各元素所对应的数据;
数据混洗模块,用于对从所述存储模块中读取出的数据进行混洗操作;
其中,m为所述对称矩阵的三角部分存储装置的硬件并行度。
根据本发明实施例的另一个方面,提供一种基于第一方面所提供的对称矩阵的三角部分存储装置的并行读取方法,包括:
根据对称矩阵的对称特性,将待读取的n阶对称矩阵的任一行或列元素转换为所述n阶对称矩阵上三角部分或下三角部分中所包含的n个元素;
利用所述存储模块选择电路确定所述n个元素各自对应的存储模块,利用所述地址生成电路确定所述n个元素在各自对应的存储模块中的逻辑地址,根据所述逻辑地址,从存储模块中并行读取所述n个元素所对应的数据;
在所述数据混洗模块中对读取出的所述n个元素所对应的数据进行数据混洗操作;
其中,n为正整数。
本发明实施例提出的一种对称矩阵的三角部分存储装置和并行读取方法,只存储对称矩阵的三角部分,能够充分利用simd硬件的并行计算单元,并且支持并行读取并恢复对称矩阵的任意行向量和列向量,从而可以将对称矩阵运算的算法效率提升到通用矩阵运算的算法效率层次。
附图说明
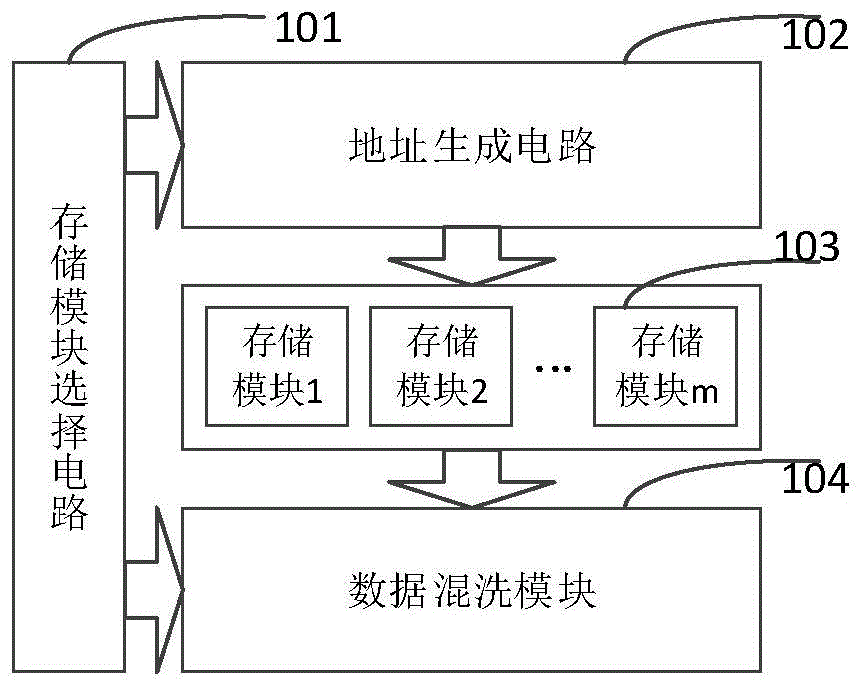
图1为根据本发明一实施例提供的对称矩阵的三角部分存储装置的结构示意图;
图2为根据本发明另一实施例提供的基于对称矩阵的三角部分存储装置的并行读取方法的流程示意图;
图3为本发明另一实施例提供的只保存上三角部分元素的对称矩阵按行读取的实现示意图;
图4为本发明另一实施例提供的只保存上三角部分元素的对称矩阵按列读取的实现示意图;
图5为本发明另一实施例提供的只保存下三角部分元素的对称矩阵按行读取的实现示意图;
图6为本发明另一实施例提供的只保存下三角部分元素的对称矩阵按列读取的实现示意图;
图7为本发明另一实施例提供的只保存上三角部分元素的对称矩阵按行读取的实现示意图;
图8为本发明另一实施例提供的只保存上三角部分元素的对称矩阵按行读取的实现示意图;
图9为本发明另一实施例提供的只保存上三角部分元素的对称矩阵按行读取的实现示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他的实施例,都属于本发明保护的范围。
为了能够并行读取对称矩阵的行列向量的全部元素,提高并行处理单元利用效率,需要开发并行无冲突存取机制,使数据存取的并行度尽可能的达到计算单元的硬件并行度,那么就可以将对称矩阵运算的算法效率提升到通用矩阵运算的算法效率层次。
对称矩阵是对称的方阵,根据对称矩阵的对称特性,n阶对称矩阵x的第i行第j列的元素与第j行第i列的元素相等。为了节省存储空间,将对称矩阵以主对角线为轴划分为上三角部分和下三角部分,可以只存储对称矩阵的上(下)三角部分元素,相应地,对称矩阵的下(上)三角部分元素可以利用对称特性得到。
如图1所示,为本发明一实施例提供的对称矩阵的三角部分存储装置的结构示意图,包括:存储模块选择电路101、地址生成电路102、并行的m个存储模块103和数据混洗模块104。
其中,存储模块选择电路101,用于选择待存取的对称矩阵上三角部分或下三角部分各元素对应的存储模块。
存储模块选择电路101的功能实现方式包括但不限于:直接硬件计算对称矩阵上三角部分或下三角部分各元素对应的存储模块bank,通过硬件查表的方式确定对称矩阵上三角部分或下三角部分各元素对应的存储模块bank,通过软件计算存储模块bank并将计算结果通过指令传递给硬件。
地址生成电路102,用于计算所述待存取的对称矩阵上三角部分或下三角部分各元素在其对应的存储模块中的逻辑地址。
其功能实现方式包括但不限于:直接硬件计算对称矩阵上三角部分或下三角部分各元素在其对应的存储模块bank中的逻辑地址addr;通过硬件查表的方式确定对称矩阵上三角部分或下三角部分各元素在其对应的存储模块bank中的逻辑地址addr,通过软件计算对称矩阵上三角部分或下三角部分各元素在其对应的存储模块bank中的逻辑地址addr并将计算结果通过指令传递给硬件。
并行的m个存储模块103,用于存储所述待存取的对称矩阵上三角部分或下三角部分各元素所对应的数据,其中,m为所述对称矩阵的三角部分存储装置的硬件并行度;
值得说明的是,若要存储对称矩阵上三角部分或下三角部分的各元素,需要利用存储模块选择电路101和地址生成电路102确定各元素存储的具体位置,这个具体位置根据存储模块bank值和逻辑地址addr值共同唯一确定,称这个具体位置为存储单元,然后将待存储的对称矩阵上三角部分或下三角部分各元素存储到相应的存储单元。n阶对称矩阵的三角部分元素的存储只需要(n+1)n/2(n为奇数)或(n+2)n/2(n为偶数)个存储单元。
当待存取的对称矩阵的阶数n小于等于硬件并行度m时,可以一次性地存取对称矩阵的一行或一列向量的全部元素;当待存取的对称矩阵的阶数n大于硬件并行度m时,每次最多可以存取m个元素。
在确定存储装置的硬件并行度时,可以参考待存取的对称矩阵的阶数。当待存取的对称矩阵的阶数n等于硬件并行度m或者是m的整数倍时,存储装置的存储单元利用率和并行处理效率最高。
数据混洗模块104,用于对从所述存储模块中读取出的数据进行混洗操作;
数据混洗操作包括但不限于对数据进行重排序,从存储模块中并行读取出的数据通常是乱序的,按照数据所在的行和列进行重排序之后才能用于进行后续的矩阵运算操作。
本发明实施例提出的对称矩阵的三角部分存储装置,只存储对称矩阵的上三角部分或下三角部分,能够充分利用simd硬件的并行计算单元,并且支持并行读取并恢复对称矩阵的任意行向量和列向量,从而可以将对称矩阵运算的算法效率提升到通用矩阵运算的算法效率层次。
基于上述实施例,所述存储模块选择电路具体用于:
根据公式(1)分别计算所述待存取的对称矩阵上三角部分或下三角部分各元素对应的存储模块;其中,所述公式(1)为:
bank=(i+j+a)modm(1),
上式中,i,j分别为所述待存取的对称矩阵上三角部分或下三角部分任一元素所在的行和列,a为预设的标量常数,mod为取余数操作,bank为该元素对应的存储模块。
公式(1)即为bank计算公式。
基于上述实施例,所述地址生成电路具体用于:
根据公式(2)分别计算所述待存取的对称矩阵上三角部分或下三角部分各元素在其对应的存储模块中的逻辑地址;其中,所述公式(2)为:
上式中,n为所述待存取的对称矩阵的阶数,i,j分别为所述待存取的对称矩阵上三角部分或下三角部分任一元素所在的行和列,b为预设的标量常数,符号
所述地址生成电路计算所述待存取的对称矩阵上三角部分或下三角部分各元素在其对应的存储模块中的逻辑地址的公式还可以为:
上式中,n为所述待存取的对称矩阵的阶数,i,j分别为所述待存取的对称矩阵上三角部分或下三角部分任一元素所在的行和列,b为预设的标量常数,符号
公式(2)和公式(3)即为addr计算公式。
在上述实施例的基础上,如图2所示,为本发明另一实施例提供的对称矩阵的三角部分存储装置的并行读取方法的流程示意图,包括:
201、根据对称矩阵的对称特性,将待读取的n阶对称矩阵的任一行或列元素转换为所述n阶对称矩阵的上三角部分或下三角部分中所包含的n个元素;其中,n为正整数。
具体地,根据对称矩阵的对称特性,有n阶对称矩阵的第i行第j列的元素与第j行第i列的元素相等,因此根据对称特性,可以从只存储对称矩阵的上(下)三角部分元素的存储装置中恢复n阶对称矩阵下(上)三角部分的元素。
对于只保存上三角部分元素的n阶对称矩阵,若需要读取该n阶对称矩阵的任一行或列,则根据对称特性将该行或列元素中属于该对称矩阵下三角部分的元素转换为上三角部分元素。例如,若要并行取第i=3行{x30,x31,x32,x33,x34}五个元素,则将下三角部分元素{x30,x31,x32}转换相对称的属于上三角部分的元素,即{x03,x13,x23}。这一步骤将待读取的n阶对称矩阵的任一行或列元素转换为n阶对称矩阵上三角部分中所包含的n个元素{x03,x13,x23,x33,x34}。
对于只保存下三角部分元素的n阶对称矩阵,若需要读取该n阶对称矩阵的任一行或列,则根据对称特性将该行或列元素中属于该对称矩阵上三角部分的元素转换为下三角部分元素。例如,若要并行取第j=3列{x03,x13,x23,x33,x43}五个元素,则将上三角部分元素{x03,x13,x23}转换为相对称的属于下三角部分的元素,即{x30,x31,x32}。这一步骤将待读取的n阶对称矩阵的任一行或列元素转换为n阶对称矩阵下三角部分中所包含的n个元素{x30,x31,x32,x33,x43}。
202、利用所述存储模块选择电路确定所述n个元素各自对应的存储模块,利用所述地址生成电路确定所述n个元素在各自对应的存储模块中的逻辑地址,根据所述逻辑地址,从存储模块中并行读取所述n个元素所对应的数据。
具体地,利用存储模块选择电路确定所述n个元素各自对应的存储模块,即利用bank计算公式通过计算获得n个元素各自对应的存储模块bank;利用地址生成电路确定所述n个元素在各自对应的存储模块中的逻辑地址,即利用addr计算公式获得n个元素在各自对应的存储模块bank中的逻辑地址addr;然后根据bank和addr,找到n个元素各自对应的存储单元,并行读出所述n各元素所对应的数据。
203、在所述数据混洗模块中对读取出的所述n个元素所对应的数据进行数据混洗操作。
具体地,数据混洗操作包括但不限于对数据进行重排序,从存储模块中并行读取出的数据通常是乱序的,按照数据所在的行和列进行重排序之后才能用于进行后续的矩阵运算操作。
本发明实施例提出的一种基于对称矩阵的三角部分存储装置的并行读取方法,支持从只保存上三角部分元素或下三角部分元素的对称矩阵中并行读取并恢复对称矩阵的任意行向量和列向量,能够充分利用simd硬件的并行计算单元,从而可以将对称矩阵运算的算法效率提升到通用矩阵运算的算法效率层次。
基于上述实施例,所述利用所述存储模块选择电路确定所述n个元素各自对应的存储模块的步骤,具体为:
根据公式(1)计算所述n个元素各自对应的存储模块;其中,所述公式(1)为:
bank=(i+j+a)modm(1),
上式中,i,j分别表示所述n个元素中任一元素所在的行和列,a为预设的标量常数,mod为取余数操作,bank为该元素对应的存储模块。通常,a的取值为零。
基于上述实施例,所述利用所述地址生成电路确定所述n个元素在各自对应的存储模块中的逻辑地址的步骤,具体为:
根据公式(2)计算所述n个元素在各自对应的存储模块中的逻辑地址;其中,所述公式(2)为:
上式中,i,j分别为所述n个元素中任一元素所在的行和列,b为预设的标量常数,符号
计算n个元素在各自对应的存储模块中的逻辑地址的步骤,还包括:
根据公式(3)计算所述n个元素在各自对应的存储模块中的逻辑地址;其中,所述公式(3)为:
上式中,i,j分别为所述n个元素中任一元素所在的行和列,b为预设的标量常数,符号
基于上述实施例,所述根据所述逻辑地址,从存储模块中并行读取所述n个元素所对应的数据的步骤具体为:
若所述待读取的对称矩阵的阶数n大于所述对称矩阵的三角部分存储装置的硬件并行度m,每次最多从存储模块中并行读取所述n个元素中的m个元素所对应的数据;或者,
若所述待读取的对称矩阵的阶数n小于等于所述对称矩阵的三角部分存储装置的硬件并行度m,一次性从存储模块中并行读取所述n个元素所对应的数据。
具体地,当对称矩阵的阶数n大于存储装置的硬件并行度m时,一次最多只能从存储模块中并行读取m个元素所对应的数据。特别地,当对称矩阵的阶数n为m的整数倍时,由于每次最多只能并行读取m个元素,因此,对称矩阵的一个行向量或列向量需要分多次进行读取。
当所述待读取的对称矩阵的阶数n小于等于所述对称矩阵的三角部分存储装置的硬件并行度m,可以一次性地读取m个数据,即可以从存储模块中并行读取所述n个元素所对应的数据。
下面结合实例对本发明实施例所提供的并行读取方法作进一步解释。为了简化说明,存储模块选择电路和地址生成电路中的常量a和常量b的取值均为0。
如图3所示,为本发明一实施例只保存上三角部分元素的对称矩阵按行读取的实现示意图(n=5,m=5)。在本实施例中,对称矩阵的三角部分存储装置的硬件并行度m=5。根据公式(1)可得数据所在的存储模块计算公式为bank=(i+j)modm,根据公式(2)可得数据所在的存储模块的存储地址计算公式为
如图4所示,为本发明另一实施例只保存上三角部分元素的对称矩阵按列读取的实现示意图(n=5,m=5)。在本实施例中,对称矩阵的三角部分存储装置的硬件并行度m=5。数据所在的存储模块计算公式为bank=(i+j)modm,数据所在的存储模块的存储地址计算公式为
如图5所示,为本发明实施例只保存下三角部分元素的对称矩阵按行读取的实现示意图(n=5,m=5)。在本实施例中,对称矩阵的三角部分存储装置的硬件并行度m=5。数据所在的存储模块计算公式为bank=(i+j)modm,数据所在的存储模块的存储地址计算公式为
如图6所示,为本发明实施例只保存下三角部分元素的对称矩阵按列读取的实现示意图(n=5,m=5)。在本实施例中,对称矩阵的三角部分存储装置的硬件并行度m=5。数据所在的存储模块计算公式为bank=(i+j)modm,数据所在的存储模块的存储地址计算公式为
如图7所示,为本发明实施例采用另一种addr计算公式的只保存上三角部分元素的对称矩阵按行读取的实现示意图(n=5,m=5)。在本实施例中,对称矩阵的三角部分存储装置的硬件并行度m=5。数据所在的存储模块计算公式为bank=(i+j)modm,数据所在的存储模块的存储地址计算公式为
如图8所示,为本发明实施例只保存上三角部分元素的对称矩阵按行读取的实现示意图(n=5,m=4)。在本实施例中,对称矩阵的上下三角部分存储装置的硬件并行度m=4。数据所在的存储模块计算公式为bank=(i+j)modm,数据所在的存储模块的存储地址计算公式为
如图9所示,为本发明实施例只保存上三角部分元素的对称矩阵按行读取的实现示意图(n=5,m=6)。在本实施例中,对称矩阵的上下三角部分存储装置的硬件并行度m=6。数据所在的存储模块计算公式为bank=(i+j)modm,数据所在的存储模块的存储地址计算公式为
最后,本发明上述各实施例仅为较佳的实施方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!