一种基于流多处理器内核独占和预留的GPU服务质量保障方法与流程
本发明涉及并发内核执行、片上资源管理和线程块调度等领域,特别是涉及一种基于流多处理器内核独占和预留的gpu服务质量保障方法。
背景技术:
在高性能计算领域,图形处理器(graphicsprocessingunits,以下简称为gpu)越来越多地被用于通用计算的加速。gpu通过大量地利用线程级并行(threadlevelparallelism,以下简称为tlp)来实现高计算能力。流多处理器(streamingmultiprocessors,以下简称为sm)负责执行gpu的计算任务,sm中包含很多计算核心(computecores)和资源,如寄存器(registers)、共享内存(sharedmemory)和l1高速缓存(l1cache)。sm间通过互连网络(interconnectnetwork)分享设备内存(devicememory)。当多个应用共享gpu时,gpu支持并发内核,内核管理器(kernelmanagementunit,以下简称为kmu)会分配内核到内核分发器(kerneldistributorunit,以下简称为kdu),kdu中的内核以先到先服务(first-come-first-serve,以下简称为fcfs)的顺序执行。但当多个应用并发执行时,线程块调度器会等待前一个内核中的线程块调度完成后再调度下一个内核,且线程块调度器会依据轮询(round-robin)策略将线程块均匀调度到所有sm中。
随着应用数量的井喷式增长,当多个并发应用共享gpu时,如何更好地提高吞吐量和能效变得尤为重要。对于gpu上的多任务并行,学术界和工业界提出了两种主要技术:空间多任务(spatialmultitasking)和同时多任务(simultaneousmultitasking)。空间多任务即gpu中sm可划分为几个互不相交的子集,每个子集分配给不同的应用同时运行;同时多任务对于sm资源进行细粒度共享(fine-grainedsharing),在单个sm上同时执行多个应用。当前的通用gpu可以在芯片级管理sm资源,从而支持空间多任务。除此之外,当应用需要保证服务质量(qualityofservice,以下简称为qos)时,必须分配足够资源满足应用的qos要求,这对gpu架构提出了更大的挑战。为了保证应用的qos要求,同时最大化gpu的吞吐量和能效,已有的解决方案主要分为以下两个方面:
(1)适应gpu架构的应用执行模型
这方面的研究是通过更改应用的默认执行模式以迎合gpu加速器的特性。如基于优先级的内核调度,即当多个内核分发到gpu时,总是先执行高优先级的内核。或者可以将要提交到gpu的所有任务抽象化为任务队列,在cpu端管理并预测每个任务的执行时长,并重排任务以满足应用的qos要求。或者利用细粒度的sm资源模型,应用类似于持久化线程(persistentthreads)的技术实现sm上的资源预留,从而限制非延迟敏感型应用的资源占用;如果当前预留资源仍不能有效满足qos指标,动态资源适应模块会被调用以抢占当前执行任务所占资源。该类方法一般以内核为粒度进行优化,不能很好地处理长时间运行的内核,除此之外内核抢占再分发的延迟和能耗也会非常大。
(2)gpu架构层次的qos执行模型
这方面的研究是基于gpu上的多任务并行,主要分为空间多任务和同时多任务。空间多任务通过运行时策略估计延迟敏感型应用的性能表现,再通过线性性能模型(linearperformancemodel)预测各应用所需sm数量。同时多任务利用细粒度的qos管理,将所有应用铺分到所有sm中,对于延迟敏感型应用和非延迟敏感型应用分配不同的配额(quota),从而对单个sm上资源进行细粒度的分配。同时多任务的不足之处在于不支持电源门控(powergating),gpu上的所有sm一直在被占用,能耗较高;而且当多个内核占用同一个sm时,l1高速缓存(l1cache)的冲突会降低性能。
综上所述,应用执行模型一般从软件角度出发,粒度为内核或其他gpu任务,使其适应gpu架构;而qos执行模型一般从gpu架构出发,使其适应各种应用。这两方面模型可以相互兼容。随着gpu的更新换代,值得注意的有两点:1)sm数量增长迅速,最新的pascal和volta架构分别有56个sm(teslap100)和80个sm(teslav100);2)单个sm上资源如寄存器文件、共享内存和l1cache大小基本没有变化。由此可见,考虑到未来gpu架构上sm数量不断增加的趋势,本发明以sm为粒度进行内核抢占和预留,可以很好地处理长期运行的内核,避免了频繁的内核抢占和分发;而且单个sm由内核独占,避免了l1cache的冲突,并支持电源门控以降低能耗。
技术实现要素:
本发明技术解决问题:克服现有技术的不足和缺陷,提供一种基于流多处理器内核独占和预留的gpu服务质量保障方法,满足多应用在gpu上执行的qos指标,充分挖掘了gpu并发内核的潜力,同时可以自适应地最大化gpu的能效或吞吐量。
本发明的技术解决方案,基于流多处理器内核独占和预留的gpu服务质量保障方法,包括如下步骤:
步骤1:多个gpu应用在cpu端启动,由用户指定需要保证服务质量qos(qualityofservice)的应用和qos指标;应用的并行部分即gpu内核通过运行时api加载到gpu(gpu应用与gpu内核是一对多的关系,一个gpu应用对应一个或多个gpu内核),gpu内核根据所属应用标识分为延迟敏感型内核和非延迟敏感型内核;
步骤2:每个gpu内核由软件工作队列swq(softwareworkqueue)id所标识,并被推入位于网格管理器gmu(gridmanagementunit)的内核等待池(pendingkernelpool);
步骤3:具有相同swqid的gpu内核将映射到同一个硬件工作队列hwq(hardwareworkqueue)中;位于每个hwq头部的gpu内核由所属应用的qos指标确定初始的流多处理器sm(streamingmultiprocessor)分配方案,基于分配方案sm有三种状态,分别为:由延迟敏感型内核占用、由非延迟敏感型内核占用、关闭并预留;
步骤4:确定sm分配方案后,每个hwq头部的gpu内核中的线程块threadblock通过线程块调度器分配给sm;
步骤5:gpu内核的执行以时间长度tepoch为单位,在每个tepoch结束后,收集各gpu内核的每周期执行指令数ipc(instructionspercycle),所述ipc包括gpi内核从最初执行开始到当前tepoch结束的总ipc,即ipctorat和当前tepoch的ipc,即ipcepoch;
步骤6:获得ipc信息后,由决策算法确定下一个tepoch期间各gpu内核的sm分配方案,sm分配方案与gpu内核类型相关,包括计算密集型ci(compute-intensive)或内存密集型mi(memory-intensive);
步骤7:由sm分配方案确定当前为止对于非延迟敏感型内核的最佳sm分配个数smeptmal,当分配为smoptmal的sm时,非延迟敏感型内核的性能和能耗达到理想平衡,从而最大限度地提高吞吐量或能效;
步骤8:获得sm分配方案后,再由决策算法确定需要换入swap-in和换出swap-out)的sm编号,即换出的sm在下一个tepoch时内不再由原gpu核占用,而换入的sm在下一个tepoch时内由目标gpu内核占用;
步骤9:当某个sm被标记为换入或换出时,有两种情况:一为该sm为预留状态,此时直接换入,由目标gpu内核所占用;二为该sm已被其它gpu内核所占用,此时要等待sm中所有线程块执行结束,再执行换出和换入操作;
步骤10:所有sm换入和换出完成后,再开始计时下一次tepoch,以确保下一次收集数据的准确性;
步骤11:若每个gpu应用只执行一次gpu内核,则重复步骤5至步骤10直到所有gpu内核执行结束;若某个应用执行多次gpu内核,则下一次gpu内核的初始sm分配编号与上一次完全相同,再重复步骤5至步骤10,直到当前分发的gpu内核执行结束;
步骤12:重复步骤11直到所有gpu应用执行结束。
所述步骤1中,由用户指定需要保证服务质量的应用和qos指标实现为:
(1)需要保证服务质量的应用表示为lsqos,具体如下:
(1-1)如果为延迟敏感型应用,则对于该延迟敏感型应用的所有gpu内核,lsqos=true;
(1-2)如果为非延迟敏感型应用,则对于该非延迟敏感型应用的所有gpu内核,lsqos=false;
(2)qos指标表示为ipcgoal,当将全部sm分配给某个延迟敏感型应用时,得到ipcsofated;定义αk为ipcgoal占ipcsofated的比例,计算方法如下:
ipcgoal=ipcisolated×αk,其中αk∈(0,1)。
所述步骤3中,确定初始的流多处理器sm,假设并发执行的延迟敏感型应用和非延迟敏感型应用的数量均为1,计算方法如下:
(1)如果为延迟敏感型内核,则
(2)如果为非延迟敏感型内核,则smk=smfofar-smqos,
其中smtotal为gpu中sm总个数,smk为某个gpu内核所占用的sm个数,smqos为延迟敏感型内核所占用的sm个数,αk为ipcgoal占ipcisolated的比例。
所述步骤6中,决策算法确定下一个tepoch期间各gpu内核的sm分配方案如下:
定义ltetal为gpu内核从最初执行开始到当前tepoch结束执行的总指令数,nepoch为从最初执行开始到当前tepoch结束时总tepoch个数,swap-in为换入一个sm,swap-out为换出一个sm,计算方法如下:
(1)对于延迟敏感型内核:
(1-1)如果itotal/[(nepoch+1)×tepoch]>ipcgoal,则标注为swap-out;
(1-2)如果ipctotal<ipcgoal,则标注为swap-in;
(2)对于非延迟敏感型内核,基于延迟敏感型内核的决策进行决策,这里有三种情况:
(2-1)延迟敏感型内核要求换入一个sm,此时优先选择预留sm,避免sm执行换出操作的开销;如果没有sm预留,则标注非延迟敏感型内核为swap-out,即换出一个sm,而该sm会被延迟敏感型内核所占用;
(2-2)延迟敏感型内核要求换出一个sm。此时根据决策算法确定非延迟敏感型内核是否需要换入一个sm,若需要换入,则标注非延迟敏感型内核为swap-in,延迟敏感型内核换出的sm会被非延迟敏感型内核所占用;否则关闭该sm并预留;
(2-3)延迟敏感性内核没有要求swap操作。此时根据决策算法确定非延迟敏感型内核是否需要换出一个sm;如需要换出,则标注非延迟敏感型内核为swap-out,非延迟敏感型内核换出的sm被关闭并预留。
所述步骤(7)中,由分配方案确定当前为止对于非延迟敏感型内核的最佳sm分配个数smoptimal,由硬件或软件定义阈值threshold,以判断sm是否要换出为预留状态,其中threshold的作用域只在非延迟敏感型内核,定义ipclast为上次tepoch期间的ipcepoch。为了在尽量短的周期内得到smoptimal的值,还需要两个标志位upperk和lowerk,其中upperk表示smoptunal是否达到上限,lowerk表示smoptunal是否达到下限。具体要求如下:
(1)如果非延迟敏感型内核执行了swap-in或swap-out操作,保存ipclast;
(2)如果上一次tepoch结束时非延迟敏感型内核换入了一个sm,具体计算方法如下:
(2-1)如果ipclast≥ipcepoch×(1-threshold),则upperk=true,smopnaf达到上限;
(2-2)如果ipclast<ipcepoch×(1-threshold),则lowerk=true,smoptmal达到下限,且smoptmal=smk;
(3)如果上一次tepoch结束时非延迟敏感型内核换出了一个sm,具体计算方法如下:
(3-1)如果ipclast>ipcepoch×(1+threshold),则lowerk=true,smoptmal达到下限;
(3-2)如果ipclast≤ipcopoch×(1+threshold),则upperk=true,smoptmal达到上限,且smoptmal=smk。
(4)若lowerk=true且upperk=true,则确定了smoptmal的值,即在gpu内核接下来的执行周期内不会改变。
所述步骤9中,要等待sm中所有线程块执行结束,再执行换入或换出操作时,线程块调度器不再分配线程块到该sm,仅等待已有线程块执行结束,这样的意义在于不会打断内核的计算,且尽量快速地完成换出操作。
所述步骤11中,所述下一次gpu内核的初始sm分配编号与上一次完全相同,这样的意义在于:1)同一个应用的不同内核一般具有相似性,这样可以充分利用sm资源,如寄存器(registers)、共享内存(sharedmemory)和一级高速缓存(l1cache);2)省去了sm的换出操作,减小内核分发的等待延迟。
所述步骤4中,hwq数量为32,gpu最多能够并发执行32个内核。
所述步骤8中,对于某个gpu内核所占据的sm,最多有一个需要换入或换出,其他将保持原状态;对于预留sm,不存在换出决策,只有换入和不变两种情况。
本发明与现有技术相比的优点在于:本发明充分挖掘了gpu并发内核的性能潜力,能够在有效实现qos指标的同时,最大限度地平衡gpu的能效和吞吐量:对于计算密集型的应用,充分提升gpu的线程级并发性;对于内存密集型的应用,充分降低gpu的能耗。
附图说明
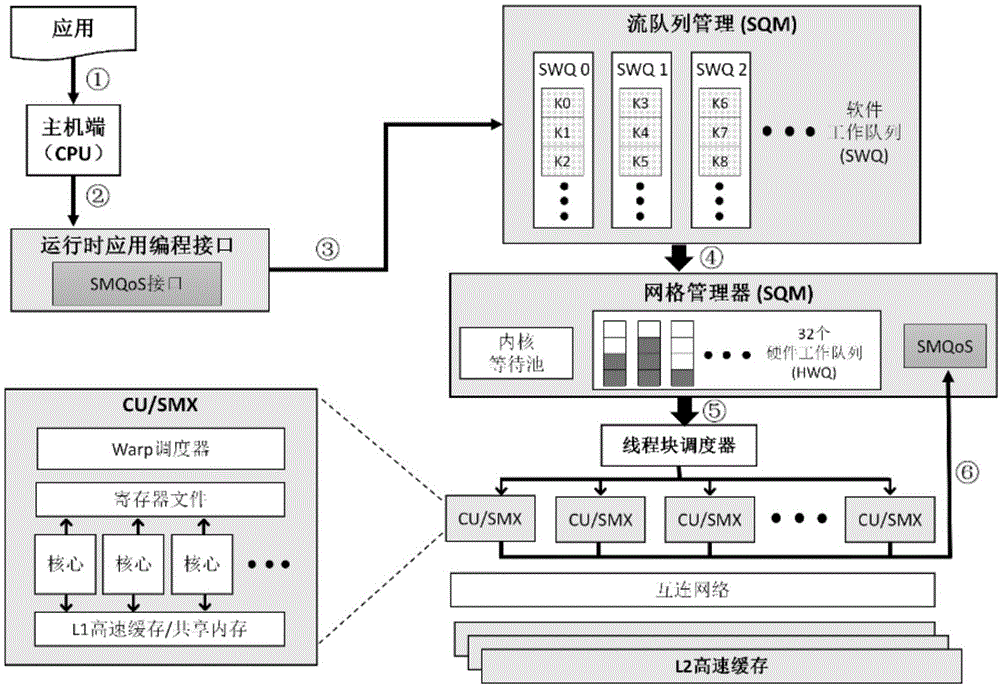
图1是实现本发明提出方法的硬件架构图;
图2是本发明提出的内核分发以及线程块调度策略的示意图;
图3是本发明提出的sm动态分配的流程示意图;
图4是本发明提出的非延迟敏感型内核确认最优sm分配个数的策略示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实例仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明的硬件架构图如图1所示,其中smqos以及smqos接口是本发明在gpu原有基础上新增的模块。
如图1所示:本发明具体实施步骤如下:
步骤1:多个gpu应用在cpu端启动,由用户指定需要保证服务质量qos(qualityofservice)的应用和qos指标;应用的并行部分即gpu内核通过运行时api加载到gpu(gpu应用与gpu内核是一对多的关系,一个gpu应用对应一个或多个gpu内核),gpu内核根据所属应用标识分为延迟敏感型内核和非延迟敏感型内核;本发明需要新增api如表1所示,cudasetqos将cpu端设置的qos参数传递到gpu,以使得gpu支持应用的服务质量需求;
表1是本发明提出方法的所需新增api;
步骤2:每个gpu内核由软件工作队列swq(softwareworkqueue)id所标识,并被推入位于网格管理器gmu(gridmanagementunit)的内核等待池(pendingkernelpool);
步骤3:具有相同swqid的gpu内核将映射到同一个硬件工作队列hwq(hardwareworkqueue)中;位于每个hwq头部的gpu内核由所属应用的qos指标确定初始的流多处理器sm(streamingmultiprocessor)分配方案。本发明提出的内核分发以及线程块调度策略如图2所示。其中单个sm由内核所独占,并支持sm的换入(swap-in)和换出(swap-out)操作,从而使得gpu支持应用的qos需求,对于计算密集型的应用,最大化gpu的吞吐量;对于内存密集型的应用,可关闭sm以降低能耗。在接下来所有步骤中,基于分配方案sm有三种状态,分别为:由延迟敏感型内核占用、由非延迟敏感型内核占用、关闭并预留;
步骤4:确定sm分配方案后,每个hwq头部的gpu内核中的线程块threadblock通过线程块调度器分配给sm;
步骤5:gpu内核的执行以时间长度tepoch为单位,在每个tepoch结束后,收集各gpu内核的每周期执行指令数ipc(instructionspercycle),所述ipc包括gpi内核从最初执行开始到当前tepoch结束的总ipc,即ipctoral和当前tepoch的ipc,即ipcepoch;
步骤6:获得ipc信息后,由决策算法确定下一个tepoch期间各gpu内核的sm分配方案,sm分配方案与gpu内核类型相关,包括计算密集型ci(compute-intensive)或内存密集型mi(memory-intensive)。本发明提出的sm动态分配的流程如图3所示。具体步骤如下:
(1)上一个tepoch执行结束。
(2)数据信息反馈到smqos。
(3)smqos依据其调度策略更新内核信息,并确定下一个tepoch期间的sm分配方案。
(4)smqos判断延迟敏感型内核是否需要换入一个sm。若需要换入一个sm则转到步骤(5),否则转到步骤(6)。
(5)smqos判断是否有sm预留。若有sm预留则转到步骤(14),否则转到步骤(13)。
(6)smqos判断延迟敏感型内核是否需要换出一个sm。若需要换出一个sm则转到步骤(7),否则转到步骤(12)。
(7)延迟敏感型内核换出一个sm。
(8)smqos判断非延迟敏感型内核所占据sm个数(smk)是否小于最优分配个数(smoptmal)。若smk<smoptmal则转到步骤(10),否则转到步骤(9)。
(9)smqos判断smoptmal是否达到上限(upperk)。若upperk=false则转到步骤(10),否则转到步骤(11)。
(10)非延迟敏感型内核换入一个sm。
(11)延迟敏感型内核换出并关闭该sm,sm状态变为预留。
(12)smqos判断smoptmal是否达到下限(lowerk)。若lowerk=false则转到步骤(13)。
(13)非延迟敏感型内核换出一个sm。
(14)延迟敏感型内核换入一个sm。
(15)smqos同步sm操作,即等待所有sm替换完成。
(16)开始执行下一次tepoch。
这里需要注意的是,当qos内核要求换入一个sm且没有sm预留时,qos内核会等待非qos内核换出一个sm。步骤(15)避免了sm替换操作过程可能带来的死锁问题;
步骤7:由sm分配方案确定当前为止对于非延迟敏感型内核的最佳sm分配个数smoptmal,当分配为smoptmal的sm时,非延迟敏感型内核的性能和能耗达到理想平衡,从而最大限度地提高吞吐量或能效。本发明提出的非延迟敏感型应用确认最优sm分配个数(smoptmal)的策略如图4所示。具体步骤如下:
(1)如果非延迟敏感型内核执行了swap-in或swap-out操作,保存ipclast。
(2)如果上一次tepoch结束时非延迟敏感型内核换入了一个sm,具体计算方法如下:
(2-1)如果ipclast≥ipcepoch×(1-threshold),则upperk=true,smoptmal达到上限;
(2-2)如果ipclast<ipcepoch×(1-threshold),则lowerk=true,smoptmal达到下限,且smoptmal=smk。
(3)如果上一次tepoch结束时非延迟敏感型内核换出了一个sm,具体计算方法如下:
(3-1)如果ipclast>ipcepoch×(1+threshold),则lowerk=true,smoptmal达到下限;
(3-2)如果ipclast≤ipcepoch×(1+threshold),则upperk=true,smoptmal达到上限,且smoptmal=smk。
(4)若lowerk=true且upperk=true,则确定了smoptmal的值,smoptmal在内核接下来的执行周期内不会改变。
步骤8:获得sm分配方案后,再由决策算法确定需要换入swap-in和换出swap-out)的sm编号,即换出的sm在下一个tepoch时内不再由原gpu核占用,而换入的sm在下一个tepoch时内由目标gpu内核占用;
步骤9:当某个sm被标记为换入或换出时,有两种情况:一为该sm为预留状态,此时直接换入,由目标gpu内核所占用;二为该sm已被其它gpu内核所占用,此时要等待sm中所有线程块执行结束,再执行换出和换入操作;
步骤10:所有sm换入和换出完成后,再开始计时下一次tepoch,以确保下一次收集数据的准确性;
步骤11:若每个gpu应用只执行一次gpu内核,则重复步骤5至步骤10直到所有gpu内核执行结束;若某个应用执行多次gpu内核,则下一次gpu内核的初始sm分配编号与上一次完全相同,再重复步骤5至步骤10,直到当前分发的gpu内核执行结束;
步骤12:重复步骤11直到所有gpu应用执行结束。
- 还没有人留言评论。精彩留言会获得点赞!