一种基于正则文法的产品族有限元模型参数化方法与流程
本发明涉及有限元模型的参数化技术、正则文法等技术领域,具体涉及一种面向产品族的基于正则文法的产品族有限元模型参数化方法。
背景技术:
有限元分析(fea,finiteelementanalysis)是利用数学近似的方法对真实物理系统(几何和载荷工况)进行模拟的过程。现代产品设计已经离不开有限元分析,它是提升产品质量和缩短设计周期的有效技术手段。随着计算机技术的快速发展,有限元分析也已经在航天、汽车、机械制造、船舶和特种装备等领域广泛使用。有限元分析过程一般包括三个步骤:前处理、加载求解和后处理。常用的有限元分析软件,如ansys、abaqus、msc等,在解决实际问题中起到了关键作用,能够有效提高了企业研发设计能力。
fea工作的主要内容是构建fea模型,fea模型包括了被分析几何模型的形状及尺寸、受力情况等信息,fea模型构建完成之后即可求解并得到分析结果。在有限元分析的过程中,有限元软件会自动记录分析人员的每个操作,形成fea脚本,每个操作都有其唯一对应的fea脚本片段。有经验的有限元分析工程师往往会通过编辑fea脚本来构建fea模型,并利用fea脚本参数化方法来达到提高分析效率的目的。常见的fea脚本参数化方法有以下几类:清华大学的曾攀(internet环境下的模板参数化有限元分析及实现,中国机械工程,2004)将已有的有限分析模型进行参数化、模板化,通过将参数传入到已有模板中,从而达到快速构建fea模型的目的;西安电子科技大学的孔宪光等(rapidintegratedparametriccaemodelingmethodoflinearvariabledifferentialtransformerbasedonascripttemplate,2015,advanceinsoftwareeginnering)将fea脚本中的变量定义为标识符,然后通过输入参数的识别和替换完成参数化fea脚本的构建,从而建立fea模型。四川大学的周丹晨等(基于web的远程有限元分析服务系统,2004,中国机械工程)构建了前处理、求解计算和后处理三个方案库,根据用户需要从三个方案库中选择方案,从而达到fea模型重用的功能;发明专(cn105q38758a一种基于数据库的有限元参数化分析系统),构建了一种基于数据库的有限元参数化分析系统,该系统能够将用户输入的数据转化成fea脚本,通过改变几何模型的参数或增减数据来构建不同的几何模型,以实现对不同几何模型的有限元分析。
然而,fea模型与几何模型紧密相关,当待分析产品几何模型的拓扑结构发生变化时,上述的fea脚本参数化方法就难以重用已有的fea模板或fea方案,从而无法快速构建fea模型。
因此,本发明将根据正则文法,提出一种面向产品族的fea模型自动生成方法。该方法在产品几何模型拓扑结构发生变化的情况下,依然能够通过产生fea脚本来自动构建fea模型。
技术实现要素:
针对现有技术中存在的上述问题,本发明提出具一种基于正则文法的产品族有限元模型参数化方法。
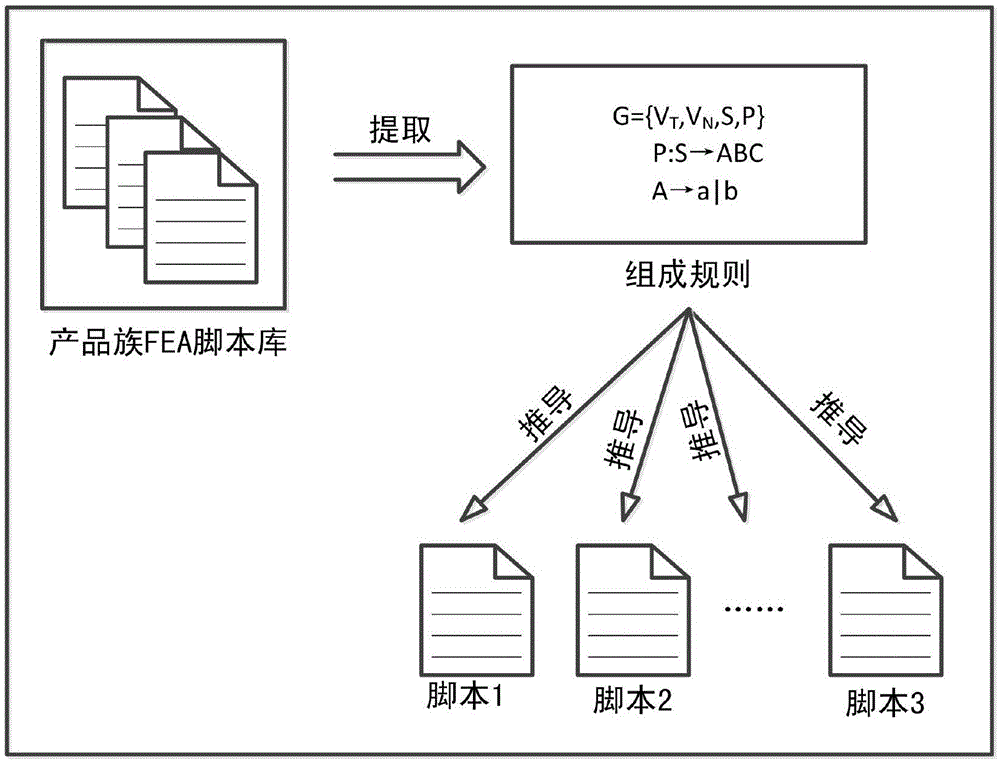
所述的一种基于正则文法的产品族有限元模型参数化方法,通过正则文法对脚本进行建模,再根据文法推导生成有限元分析模型,其特征在于包括如下步骤:
1)对产品族fea脚本库内各个产品的fea脚本进行语义拆分,得到第一fea脚本片段并构成第一fea脚本片段库;
2)利用正则文法,提取步骤1)第一fea脚本片段库内的第一fea脚本片段的组成规则;
3)根据步骤2)提取的组成规则,推导出新的fea脚本,实现产品族有限元模型参数化。
所述的一种基于正则文法的产品族有限元模型参数化方法,其特征在于具体包括如下步骤:
1)产品族fea脚本库的建立及fea脚本的语义拆分
1.1)构建产品族fea脚本库
收集产品族内的fea脚本,构建产品族fea脚本库;
1.2)fea脚本的语义拆分
按照有限元分析流程对产品族内的fea脚本进行语义拆分,得到第一fea脚本片段;所述有限元分析分过程包括:前处理、加载求解、后处理三个阶段,其中,前处理又包括单元类型、材料参数、实常数和网格划分等;
2)利用正则文法描述产生新的fea脚本的规则
完成了fea脚本的语义拆分后,利用正则文法,设计组织并提取第一fea脚本片段之间的组成规则;
2.1)正则文法
正则文法g为描述了给定语言的句子集合,该正则文法定义为四元组,即g={vn,vt,p,s},其中,vn表示非终结符集;vt表示终结符集;p是产生式集合,包含了a→α的产生式,a→α表示a用α进行替换,并且a属于vn中的一个元素,α包括了vt或vn中的若干元素,vt中的元素是语言中句子的组成要素,s为开始符号,所有脚本的推导均从s开始进行;
2.2)正则文法对有限元分析的描述,构建推导规则
将产品族fea脚本库定义成语言l,一个fea脚本为语言l中的一个句子,将fea过程的前处理、加载求解和后处理都定义为非终结符vn,前处理中的单元类型、材料参数、实常数和网格划分定义为终结符vt,每一个终结符对应着fea脚本库中的一个第一fea脚本片段;
3)采用算法推导并生成新的fea脚本
3.1)输入的设置
生成完整的fea脚本需要四种参数:几何参数、fea标签、载荷位置编码及fea参数,其中fea标签为1.2)所得的第一fea脚本片段的名称,fea参数为fea标签的输入数值,几何参数为几何模型的设计参数,载荷位置编码为用于标记fea标签的作用位置;为了生成完整的新fea脚本,在推导的过程中需要输入几何参数和载荷位置编码;
3.2)载荷位置编码的获取
利用ansys软件中坐标选择的方式,选择产品族中每个产品的同种载荷位置,并将选择的载荷位置转化成第二fea脚本片段,最后对第二fea脚本片段进行编码,构成载荷位置编码;
3.3)生成新的fea脚本
在确定了四种输入参数后,算法从输入缓存中读入四种参数,再根据步骤2.1)给定的正则文法推导生成新的fea脚本。
所述的一种基于正则文法的产品族有限元模型参数化方法,其特征在于步骤3.1)中,根据四种参数之间的结合方式,将输入分为以下几种类型:[fea标签]、[fea标签,fea参数]、[fea标签,载荷位置编码]、[fea标签,载荷位置编码,fea参数];
在推导的过程中针对不同的输入类型进行推导输出的方法如下:
a.将fea标签对应的第一fea脚本片段直接输出;
b.向fea标签对应的第一fea脚本片段中填入fea参数后输出;
c.先输出载荷位置编码的第二fea脚本片段,然后再输入fea标签对应的第一fea脚本片段;
d.先输出载荷位置编码的第二fea脚本片段,然后向fea标签对应的第一fea脚本片段中填入fea参数后输出。
所述的一种基于正则文法的产品族有限元模型参数化方法,其特征在于步骤3.2)中,构成载荷位置编码的具体过程如下:
3.2.1)设定编码对象
将产品族中每个产品的同种载荷位置设定为编码对象;
3.2.2)选择编码对象
寻找与编码对象存在集合关系的几何特征,所述几何特征为产品族内所有产品的共有特征;再为所选的几何特征匹配坐标系,确定该几何特征在坐标系中的位置,直接或间接地选择出设定的编码对象;将选择过程转化成第二fea脚本片段,对转化所得的第二fea脚本片段提取步骤3.1)所需几何参数,再为所述第二fea脚本片段添加编码,即得载荷位置编码。
所述的一种基于正则文法的产品族有限元模型参数化方法,其特征在于所述间接法为:适用于编码对象在产品族内的几何模型上处于不同位置且个数也不同。
所述的一种基于正则文法的产品族有限元模型参数化方法,其特征在于所述直接法为:适用于编码对象在产品族内的几何模型上处于相同位置且个数相同。
所述的一种基于正则文法的产品族有限元模型参数化方法,其特征在于推导过程中的非终结符和终结符利用栈暂存。
所述的一种基于正则文法的产品族有限元模型参数化方法,其特征在于3.2.2)的坐标系为直角坐标系、球坐标系或柱坐标系。
通过采用上述技术,本发明的有益效果如下:本发明提出的通过正则文法对脚本进行建模,再根据文法推导生成有限元分析模型的方法,能保证在产品几何模型拓扑结构发生变化的情况下依然能完成fea模型的自动构建,减轻有限元分析人员的工作负担,同时使得产品设计人员也能自主进行有限元分析,为企业减轻了产品设计成本,节约了人力和物理资源,有效提升了产品质量和缩短设计周期。
附图说明
图1为本发明系统总体框架示意图;
图2为本发明的工作流程示意图;
图3为有限元分析过程结构示意图;
图4为推导过程示意图;
图5为不同类型封头fea脚本对比示意图;
图6为所有终结符对应的第一fea脚本片段示意图;
图7为封头产品族内不同产品共同载荷位置示意图;
图8为球形封头耦合分析推导过程操作步骤示意图;
图9a为球形封头剖面结构示意图;
图9b为球形封头的耦合分析输入示意图;
图9c为球形封头载荷位置编码结果图;
图10为间接选择法的流程图;
图11为基本本发明文法所得的半球形封头新的fea脚本;
图12为本发明实施例的产生式集合图;
图13为算法流程图。
图中:w1-底面,w2-侧面,w3-外表面,w4-内表面。
具体实施方式
以下结合说明书附图及实施例对本发明进行进一步的说明,但本发明的保护范围并不仅限于此:
如图1-13所示,本发明的一种基于正则文法的产品族有限元模型参数化方法,通过正则文法对脚本进行建模,再根据文法推导生成有限元分析模型,首先对产品族fea脚本库内各个产品的fea脚本进行语义拆分,得到第一fea脚本片段并构成第一fea脚本片段库;利用正则文法,提取第一fea脚本片段库内第一fea脚本片段的组成规则;根据提取的组成规则,推导出新的fea脚本,实现产品族有限元模型参数化,本发明以压力容器封头产品为例,其fea脚本生成具体步骤如下:
1)产品族fea脚本库的建立及fea脚本的语义拆分
1.1)构建产品族fea脚本库
封头是压力容器的重要组成部分,按照形状可分为半球形封头、大曲率平盖、球冠形封头及焊接形平盖等,封头的受力情况以半球形封头为最好,其次为椭圆封头,其他三种受力比较差;
收集压力容器封头产品族的fea分析脚本,得到如图5所示的大曲率平盖结构、半球形封头结构、球冠型封头及焊接形平盖等的fea脚本,形成封头产品族fea脚本库;
1.2)fea脚本的语义拆分s
本发明的fea过程由图3所示的树形结构表示;fea软件会对每个有限元分析过程进行记录并形成fea脚本文件,fea过程中的每个fea操作都有其唯一对应的第一fea脚本片段,每段fea脚本都有其唯一明确的语义;图3中的灰色方框代表fea操作,白色方框代表fea阶段,每个操作都有相应的第一fea脚本片段与之对应,可通过对完整的fea脚本进行语义拆分来得到第一fea脚本片段,本发明将收集到的封头产品的fea脚本进行拆分,具体为:封头产品族有限元分析分为:前处理、加载求解、后处理三个fea阶段,其中,前处理又包括几何参数、单元类型、材料参数、实常数及网格划分,所述网格划分分为智能划分、映射划分、扫略划分;加载求解包括约束、载荷和求解,约束分为结构分析、热分析,所述结构分析包括固定约束和对称约束,所述热分析包括恒温和参考温度;载荷包括结构力和热力,结构力为压力,热力为热对流;后处理包括通用后处理、特殊后处理保存文档和读取热场,通用后处理包括图展示及列表展示,特殊后处理为路径分析;得到如几何参数、单元类型、材料参数等的第一fea脚本片段,最终结果如图6所示;
2)利用正则文法描述产生新的fea脚本的规则
完成了fea脚本的语义拆分后,利用正则文法,设计组织并提取第一fea脚本片段之间的组成规则;
2.1)正则文法
正则文法g为描述了给定语言的句子集合,该正则文法定义为四元组,即g={vn,vt,p,s},其中,vn表示非终结符集;vt表示终结符集;p是产生式集合,包含了a→α的产生式,a→α表示a用α进行替换,并且a属于vn中的一个元素,α包括了vt或vn中的若干元素,vt中的元素是语言中句子的组成要素,s为开始符号,所有脚本的推导均从s开始进行;
2.2)正则文法对有限元分析的描述,构建推导规则
将产品族fea脚本库定义成语言l,一个fea脚本为语言l中的一个句子,将fea过程的前处理、加载求解和后处理都定义为非终结符vn,前处理中的单元类型、材料参数、实常数和网格划分定义为终结符vt,每一个终结符对应着fea脚本库中的一个第一fea脚本片段;
本发明将各分析阶段(如前处理、加载求解等)设置为非终结符(标记为大写字母),将具体操作(如前处理中的单元类型、材料参数等)设置为终结符(标记为小写字母),最终形成产生式集合p,其中s为开始符号,如图12所示;
3)采用算法推导并生成新的fea脚本
3.1)输入的设置
生成完整的fea脚本需要四种参数:几何参数、fea标签、载荷位置编码及fea参数,为了生成完整的新fea脚本,在推导的过程中需要输入几何参数和载荷位置编码,其中:
1)几何参数:几何模型的设计参数,长、宽、高、半径;
2)fea标签:代表了每个fea操作,有其对应的fea脚本片段,本实施例中为1.2)所得的脚本片段的名称,如:施加压力;
3)载荷位置编码:用于标记fea中的力或约束的作用位置,如点、线、面的编号;
4)fea参数:为fea过程中的输入参数,如压力值为10mpa;
根据参数之间的结合方式,可将输入分为以下几种类型:[fea标签]、[fea标签,fea参数]、[fea标签,载荷位置编码]、[fea标签,载荷位置编码,fea参数];在推导的过程中针对不同的输入参数进行赋值的方法如下:
1)将fea标签对应的fea脚本片段直接赋值;
2)向fea标签(或几何参数)对应的fea脚本片段中填入参数后赋值;
3)先确定载荷位置编码的脚本片段,然后再确定fea标签对应的脚本片段;
4)先确定载荷位置编码的脚本片段,然后确定fea标签对应的脚本片段并填入fea参数;
本发明以球形封头的耦合分析为例,其输入的几何参数如图9a,其中r1为该几何模型的纵向高度,即r1=1.386m,r2为该几何模型的横向宽度,即r2=0.546m,r3为该几何模型的外表面圆角半径,即r3=0.546m,如图9b所示:
如图9b所示,几何参数mo、单元类型et等fea标签将作用于整体几何模型,除此外,恒温、压力将作用于几何模型的内表面w4,对称约束将作用于两个侧面w2,固定约束将作用于底面w1,热对流将作用于外表面w3;
3.2)载荷位置编码的获取
在进行推导之前,首先要准备好载荷位置编码的脚本。本发明利用ansys软件中坐标选择的方式,对产品族共同载荷位置进行选择,并将选择的过程转化成第二fea脚本片段,最后对其进行编码(即得载荷位置编码),具体过程如下:
3.2.1)设定编码对象
本发明设定编码对象为产品族共同载荷位置,由于分析需求不同,同一个载荷位置上会承受不同的载荷,具体包括如下编码对象:
1)内表面w4,承受压力或者恒温载荷;
2)封头底面w1,受到固定约束;
3)侧面w2,受到对称约束;
4)外表面w3,承受热对流载荷;
对封头产品族建立四分之一的几何模型,将其共同载荷位置作为编码对象,包括封头内表面w4、左右侧面w2、外表面w3、底面w1,具体结构见图7;
3.2.2)选择编码对象
以ansys软件为例,ansys软件提供了强大的特征选择功能,虽然产品族几何模型之间存在结构上的差异,但利用ansys软件提供的坐标选择方法,可利用同一种选择策略选择不同几何模型中的相同特征(如所有封头的内表面可用同一个选择策略来选择)。为了确保生成的fea脚本片段适用于产品族内的所有产品,本发明按照如下方法选择编码对象:1)间接选择法:寻找与编码对象存在集合关系的一组几何特征,这一组几何特征为所有产品都含有的;为这一组几何特征匹配坐标系(直角坐标系、球坐标系或柱坐标系,本发明实施例中选柱坐标系并确定该几何特征在柱标系中的位置,间接选择出编码对象;将选择过程转化成fea脚本片段,对该脚本片段提取参数、设定变量,最后为这些脚本片段添加编码,如w1、w2等,间接选择法的工作原理如图10所示;2)直接选择法:若编码对象在产品族内的几何模型上都处于相同位置,直接为该编码对象匹配坐标系选中即可。
具体如下:1)间接选择法:以选择内表面w4为例,如图7所示,因为内表面w4分段数在产品族内变化较大,所以不能直接选择内表面w4,但是外表面w3的分段数变化较小(半球形封头和球冠封头外表面有2个分段,其余产品的外表面有3个分段),又因为外表面w3轮廓线和内表面w4轮廓线同在一个侧面上、外表面轮廓线在外表面w3上,所以,将外表面轮廓线作为选择内表面w4的那组几何特征。选择过程如下:利用柱坐标系,首先选择侧面w2上的所有线,排除掉外表面轮廓线、底端横线和顶端横线,选择与内轮廓线相连的所有面,排除掉侧面,剩余的就是内表面。2)直接选择法:对于底面而言,由于所有模型的底面都只有一个,且都处于模型的最底端,利用柱坐标系,直接选择底面即可。
同样,可以按照同样的方法选择其余的编码对象,最终得到的第二fea脚本片段和编码结果如图9c所示,其中粗线条字体为各编码对象的编码,参数r1为产品族几何模型的纵向高度,r2为产品族几何模型的横向宽度,r1为封头产品族各几何模型的外表面圆角半径,其如图9a所示;
3.3)生成脚本
在确定了各类输入参数后,本发明提出按如图4所示的流程生成脚本。其中,推导程序从输入缓存中读入数据,再根据给定的正则文法推导生成脚本,为了确保推导过程不重复、不遗漏产品fea整个分析步骤,本发明将利用数据结构——栈来暂存推导过程中的非终结符和终结符。
以产生式集为例:s→b|c,b→a|b,c→c|d,且有输入串ac。推导时,本发明推导过程中的非终结符和终结符利用栈暂存,首先将产生式起始符s压入栈$,栈顶为s,将s弹出,将其产生式倒序入栈,此时栈顶为b为非终结符,将b弹出栈,此时栈顶a为终结符,且a与输入串中字符相同,弹出a,此时栈顶为b,与输入串中字符不同,放弃该步操作,之后步骤与此相同。直到栈$为空,推导结束,算法的具体过程如图13所示。
半球形封头耦合分析可分为热分析和结构分析两个阶段,以热分析为例,其算法推导过程如下:将文法的起始符s压入栈$,s为终结符,将其产生式倒序入栈,弹出栈顶pr,再将pr产生式倒序入栈,此时内里mo、et、mp、r为终结符,将它们依次弹出栈并写出相应脚本片段,之后栈顶me为非终结符,将其弹出,将其产生式倒序入栈,此时栈顶sm与输入串中的字符相同,将其填入参数后弹出,之后弹出se、sw等;此时栈顶为ls,将其弹出,将其产生式倒序入栈,之后依次弹出非终结符co、cd,弹出栈内终结符fi、sy并输出脚本,此时栈顶为hd,将hd下的符号依次弹出,之后栈顶为so,弹出so并输出脚本片段,之后栈顶为po,弹出po,弹出其栈顶sa、re。之后进入结构分析阶段,与热分析相同,将产生式的符号依次弹出,最终形成新的脚本如图11所示。
- 还没有人留言评论。精彩留言会获得点赞!