一种基于神经网络的写作辅助方法与流程
本发明涉及利用计算机对文本进行处理和生成的方法,属于信息处理技术领域。
背景技术:
写作是一种将若干词语以一定的规则组织成句子的过程,对于以母语写作的人来说,这个过程往往是非常简单而自然的。然而当使用外语写作时,由于不同语言之间表达习惯和语法的差异,如果对该种语言不够熟悉,常常面临不知如何将词语组织成句子的问题。这可能是由于不能熟练地使用某些句式,也可能是因为不知道某些领域内的常用表达。在实际写作过程中,作者当前可能只有句子原型或几个核心的单词,但不知该如何将它们组织起来,形成流畅的句子。遇到这样的问题时,作者通常会先去了解每个词语或短语的用法,然后根据这些用法将它们组织起来,但是考虑到不同的语境和不同词汇之间的搭配,这种方法较为低效。
神经网络是一种强大的机器学习模型,其通过一系列的线性或非线性转换,将输入数据映射到不同的表示空间,并基于预先定义的损失函数,自适应地更新模型参数,以降低损失。循环神经网络(rnn)是神经网络的一种,相比普通的神经网络(多层感知机),循环神经网络会维护并更新不同时间步的状态,从而更适合处理变长的序列,如文档、语音。长短期记忆(lstm)是一种循环神经网络,相比普通的神经网络(多层感知机),lstm中输入门、遗忘门、输出门等的存在使其相对于传统rnn对每个时间步的信息处理有了更强的控制,从而有助于捕获长期依赖。
生成对抗网络由goodfellow等于2014年提出,生成对抗网络包括生成器和判别器两部分,生成器生成样本,而判别器在不知道输入样本来源的情况下,判断其输入来自真实样本而非生成样本的概率。生成对抗网络交替地训练生成器和判别器,生成器的目的是生成逼真的样本骗过判别器,判别器的目的是准确区分出生成样本和真实样本之间的差异,从而判断其输入样本的来源。生成对抗网络的训练过程即为生成器和判别器的博弈过程,为了提高骗过判别器的概率,生成器需要尝试提高生成样本的质量。
技术实现要素:
本发明提供了一种写作辅助方法,对于写作者写作过程中已有的句子原型或若干关键词,本发明的模型综合考虑它们结合在一起时的语境,并在该种语境下根据这些关键词生成一个润色的句子,从而实现对写作的辅助。
技术方案:为实现上述目的,本发明采用的技术方案如下:
一种基于神经网络的写作辅助方法,包括以下步骤:
步骤1,对给定的语料库d进行预处理,得到目标序列集合y;对于任一目标序列y∈y,使用基于词性的词汇筛选方法从中筛选出相应的关键词序列x,x和y构成了训练数据的一个样本{x,y},x模拟了写作时的若干关键词,而y是关键词序列x所对应的表达更流畅且完整的句子;
步骤2,预训练一个文本生成器:对于训练样本{x,y+},使用一个基于神经网络的编码器编码关键词序列x,得到该关键词序列的摘要向量b和关键词序列中各个词语的上下文特征矩阵h;使用另一个神经网络作为解码器从b中解码出一个候选句子y-;预训练阶段的目标是最小化模型生成的候选句子y-和来自目标序列集合y的真实句子y+之间的交叉熵;
步骤3,预训练一个文本二分类器:所述文本二分类器可能的输入样本包括关键词序列-真实句子对{x,y+}和关键词序列-生成句子对{x,y-};给定样本{x,y},分类器首先使用神经网络分别提取x和y的特征得到特征向量[f1(x);f2(y)],然后利用多层感知机处理特征向量,得到样本是真实序列对的概率p;
步骤4,对抗训练文本生成器和分类器:交替地训练生成器和分类器,并利用分类器的概率输出指导生成器的训练;
步骤5,使用训练好的生成器辅助写作:以x表示写作过程中的句子原型或若干个关键词,将x作为生成器的输入,生成润色后的句子。
优选的:所述步骤1中目标文本的预处理包括句子边界检测、命名实体识别、非法句子过滤等。所述步骤1中关键词序列的生成基于词性分析,通过为不同词性和词频的词语分配不同的留存概率,筛选出包含关键语义的词语作为关键词。该过程实现的是对真实关键词的生成过程的模拟。
优选的:所述步骤2使用双向循环神经网络编码关键词序列,即在每个时间步依次读入关键词序列中的一个词语,直至整个序列都被编码到摘要向量b中;解码阶段使用了注意力机制:在每个解码步t,使用当前时间步的解码器隐层状态h′t和编码器得到的源序列的上下文矩阵h计算一个注意力向量at,该向量记录了与当前解码步相关的上下文信息,并过滤了无关的信息。
优选的:所述步骤3使用卷积神经网络提取序列特征。特征提取器首先对输入序列(关键词序列或句子序列)的词向量x∈rl×d进行卷积计算,其中l为序列长度,d为词向量维度。特征提取器包括了多个宽度为d(与词向量维度相同),高度不等的卷积核。对于一个宽度为d,高度为h的卷积核w∈rh×d,将其应用于各个高度为h的序列词向量窗口xi:i+h-1,i∈{1,2,...,l-h+1},得到该窗口的特征ci:
其中relu即线性整流函数,wj为w的第j行;利用该卷积核对整个输入序列进行卷积,得到该序列的一个特征映射c=[c1,c2,...,cl-h+1]。由于序列的长度是可变的,为了得到固定长度的特征表示,对c应用时序上的最大池化得到
优选的:所述步骤4使用对抗训练对步骤2的预训练模型进行增强。参数更新使用梯度下降算法,为了将来自判别器的梯度传递到生成器,指导生成器的训练,基于强化学习和策略梯度,将判别器得分作为对生成器策略的奖励,生成器的目标是最大化累积奖励的期望。为了获得对中间状态,即序列生成过程中的每个中间时间步的奖励,对于长度为t的候选目标序列,在其每个解码步t,利用蒙特卡罗搜索采样出未解码的最后t-t个标记,同前t个时间步生成的标记一起作为一个完整的序列提供给判别器以计算奖励,并将n次蒙特卡罗搜索得到的奖励的均值作为对第t个时间步的奖励的估计。
优选的:所述步骤5生成器生成文本的过程基于贪心搜索、随机搜索或beamsearch。
本发明的有益效果是:本发明提出了一种写作辅助方法,将写作辅助任务形式化为一个条件文本生成过程,并提出用神经网络解决这一问题。神经网络模型的训练往往需要大量的标注数据,对于本发明提出的写作辅助任务,并没有现成的数据集可用于训练。为了解决这一问题,本发明提出了一种能够从无标注的甚至包含大量噪声的原始语料中,自动地构造用于这一写作任务的数据集的方法。这种自动化的方法,也避免了本发明对特定语料的依赖,使本发明可以用于不同语言和领域的写作辅助任务。进一步地,本发明使用生成对抗网络增强预训练的生成模型,从而能提高生成文本的流畅度和真实性。
本发明不需要预先标注语料,训练数据集从文本中自动构建,能极大地降低人工标注工作量,从而可以很容易地应用到不同领域实现写作辅助任务;基于神经网络的训练,能够有效地捕获语言特征;使用对抗训练的方法增强模型性能,进一步提高了生成文本的流畅度和真实度。
附图说明
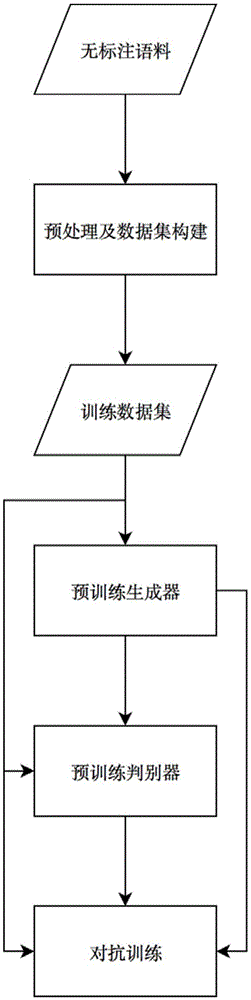
图1是本发明方法流程图;
图2是本发明的生成器示意图;
图3是本发明的生成器解码时应用的注意力机制的示意图;
图4是本发明的判别器的示意图;
图5是本发明对抗训练的示意图;
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
如图1所示,一种基于神经网络的写作辅助方法,该方法包括数据集的构造、预训练、对抗训练等步骤。
问题可以描述如下:在给定部分关键词x的情况下,生成与这些关键词相关的一个语义更丰富的表达流畅的句子y。为了实现这样的目的,本方法首先训练一个生成模型,训练数据集构造自原始语料库d。
下面介绍具体的实施方式。
一,构造训练数据集。
预处理给定的语料库d,对于每个文档,首先检测句子的边界,将文档切分为句子,并过滤掉非法的句子,得到所有句子的集合y。对于其中的每个句子y=[y1,y2,...,yj,...,yn](n为句子y中的单词数量),分析每个单词yj的词性pos(yj),以g(pos(yj))的概率将其留存下来(g为预先定义的不同词性的单词的留存概率映射),得到y对应的关键词序列x,将{x,y}作为一个训练样本。留存概率的定义基于先验知识,如名词、动词、形容词等对于语义的表达比较关键,因此其留存概率较高,而停用词等则具有较低的留存概率。
二,预训练文本生成器。
文本生成器包含一个关键词序列编码器和一个句子序列解码器,如图2所示。
关键词序列编码器使用双向的长短期记忆(lstm)网络编码输入的关键词序列x=[x1,x2,...,xs,...,xs],其中s为x中词语的数量。编码器在每个编码时间步s读入单词xs,更新当前的隐状态hs:
hs=bilstm(hs-1,xs),
其中hs-1为上个时间步的编码器隐状态。编码器编码整个序列后得到x的摘要b=hs和上下文矩阵h=[h1,h2,...,hs]。
解码器使用单向的lstm从编码器得到的摘要向量b中解码出目标序列。给定真实的与x对应的目标序列
在每个解码步对ht′和编码器得到的上下文矩阵h应用注意力机制,如图3所示:
score(hs,h′t)=vttanh(w1hs+w2h′t),
at=tanh(wc[ct;h′t]),
其中,vt、w1、w2、wc均为参数,以上各式首先计算时间步t上下文矩阵h中各个上下文向量的权重αt,αts是αt的第s个元素,随后用各个上下文向量的加权和ct和解码器隐状态ht′计算注意力向量at。at接着被用于时间步t的解码:
其中wv为参数。
预训练阶段,使用随机梯度下降更新模型参数,对于样本{x,y+}和生成的候选句子y-,其损失函数为:
其中len(y+)为句子y+中单词的数量。
三,预训练判别器
判别器为一个文本分类器,如图4所示。其可能的输入样本包括真实序列对{x,y+}和生成序列对{x,y-}。给定样本{x,y},判别器首先使用卷积神经网络分别提取两个序列的特征向量得到[f1(x);f2(y)],其后利用多层感知机处理特征向量,得到样本是真实序列对的概率p。
特征提取器首先对输入序列(关键词序列或句子序列)的词向量x∈rl×d进行卷积计算,其中l为序列长度,d为词向量维度。特征提取器包括了多个宽度为d(与词向量维度相同),高度不等的卷积核。对于一个宽度为d,高度为h的卷积核w∈rh×d,将其应用于各个高度为h的序列词向量窗口xi:i+h-1,i∈{1,2,...,l-h+1},可得到该窗口的特征ci:
利用该卷积核对整个输入序列进行卷积,得到该序列的一个特征映射c=[c1,c2,...,cl-h+1]。由于序列的长度是可变的,为了得到固定长度的特征表示,对c应用时序上的最大池化得到
判别器的训练同样使用批量随机梯度下降优化交叉熵。
四,对抗训练
对抗训练的整体过程如图5所示。对抗训练中将序列生成过程建模为一个连续的决策过程,将生成器视为一个随机化的策略,通过策略梯度直接训练策略,即生成器。对抗训练的目标是最大化期望最终奖励:
其中g为生成器,d为判别器,t是目标序列长度,v是所有词语的集合,rt是一个完整的序列获得的累积奖励,
这样的累积奖励是对整个序列而言的,为了获得序列生成过程中的每个中间时间步的奖励,在解码时间步t,利用蒙特卡罗搜索取样出未知的最后t-t个标记,同前t个时间步生成的标记一起提供给判别器以计算奖励,并将n次蒙特卡罗搜索得到的奖励的期望作为对第t个时间步的策略的奖励的估计。
对抗训练过程交替训练生成器和判别器,在这种对抗性的训练中,生成器利用判别器关于生成器输出样本的梯度更新自己的参数,从而逐渐提高生成样本的质量,而判别器也能及时适应生成器的变化,给生成器以合适的指导。
五,辅助写作
辅助写作包括编码和解码两个过程。以x表示写作过程中的句子原型或若干个关键词,训练好的编码器以x为输入编码整个序列后得到其摘要向量b和上下文矩阵h。接着,解码器从b中解码出润色后的句子y-。其中编码过程与训练阶段一致,解码过程与训练阶段有两个不同:每个解码时间步的输入来源、输出采样方式。
输入来源:解码时间步t,训练阶段解码器读入单词
输出采样方式:解码时间步t,解码器在前t-1个时间步中解码出的序列为
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!