基于深度学习的裁判结果获取方法、装置及存储介质与流程
本发明涉及深度学习技术领域,尤其涉及一种基于深度学习的裁判结果获取方法、装置及存储介质。
背景技术:
随着社会的发展和法律的完善,需要裁判的案件较多。
现有技术中,针对每一个需要裁判的案件,通常采用开庭审理的方式人工进行裁判。但是,人工裁判的方式将会造成案件的处理效率较低。可见,如何提高案件的处理效率是当下一个亟需解决的问题。
技术实现要素:
本发明提供一种基于深度学习的裁判结果获取方法、装置及存储介质,提高了案件的处理效率。
第一方面,本发明提供一种基于深度学习的裁判结果获取方法,包括:
根据待处理案件的原始文本,获取所述待处理案件的案件信息;
通过裁判模型对所述待处理案件的案件信息进行处理,获得所述裁判模型输出的裁判结果,其中所述裁判模型是以至少一个裁判文书的案件信息和裁判结果为样本,经过深度学习训练获得的。
进一步地,所述根据待处理案件的原始文本,获取所述待处理案件的案件信息之前,还包括:
识别所述原始文本中的金额信息,对所述金额信息进行整数格式的转化;
进一步地,所述根据待处理案件的原始文本,获取所述待处理案件的案件信息之前,还包括:
识别所述原始文本中的姓名信息,将所述姓名信息替换为同一姓名标识;
进一步地,所述根据待处理案件的原始文本,获取所述待处理案件的案件信息之前,还包括:
识别所述原始文本中的时间信息,将所述时间信息替换为同一时间标识。
进一步地,所述通过裁判模型对所述待处理案件的案件信息进行处理,获得所述裁判模型输出的裁判结果,包括:
根据所述待处理案件的案件信息,获得相应的第一文本词向量矩阵;
对所述第一文本词向量矩阵分别进行正向解读和反向解读,获得第一正向解读结果和第一反向解读结果;
将所述第一正向解读结果和所述第一反向解读结果进行拼接,对拼接获得的数据进行信息抽取,获得第一文本内容向量;
从所述第一文本内容向量中提取出第一裁定向量,对所述第一裁定向量进行解析,获得所述裁判结果。
进一步地,所述方法还包括:
获取所述至少一个裁判文书的案件信息和裁判结果;
根据所述至少一个裁判文书的案件信息,获得相应的第二文本词向量矩阵;
对所述第二文本词向量矩阵分别进行正向解读和反向解读,获得第二正向解读结果和第二反向解读结果;
将所述第二正向解读结果和所述第二反向解读结果进行拼接,对拼接获得的数据进行信息抽取,获得第二文本内容向量;
从所述第二文本内容向量中提取出第二裁定向量;
根据所述第二裁定向量和所述裁判文书的裁判结果对应的向量计算获得损失误差;利用所述损失误差,对所述裁判模型进行学习训练,直至所述裁判模型收敛。
第二方面,本发明提供了一种基于深度学习的裁判结果获取装置,包括:
第一获取单元,用于根据待处理案件的原始文本,获取所述待处理案件的案件信息;
第二获取单元,用于通过裁判模型对所述待处理案件的案件信息进行处理,获得所述裁判模型输出的裁判结果,其中所述裁判模型是以至少一个裁判文书的案件信息和裁判结果为样本,经过深度学习训练获得的。
进一步地,所述装置还包括:
第一处理单元,用于识别所述原始文本中的金额信息,对所述金额信息进行整数格式的转化。
进一步地,所述装置还包括:
第二处理单元,用于识别所述原始文本中的姓名信息,将所述姓名信息替换为同一姓名标识。
进一步地,所述装置还包括:
第三处理单元,用于识别所述原始文本中的时间信息,将所述时间信息替换为同一时间标识。
进一步地,所述第二获取单元,包括:
第一词向量转换模块,用于根据所述待处理案件的案件信息,获得相应的第一文本词向量矩阵;
第一解读模块,用于对所述第一文本词向量矩阵分别进行正向解读和反向解读,获得第一正向解读结果和第一反向解读结果;
第一拼接模块,将所述第一正向解读结果和所述第一反向解读结果进行拼接;
第一信息抽取模块,对拼接获得的数据进行信息抽取,获得第一文本内容向量;
第一提取模块,从所述第一文本内容向量中提取出第一裁定向量;
第一解析模块,对所述第一裁定向量进行解析,获得所述裁判结果。
进一步地,所述装置还包括:第三获取单元和模型训练单元;
所述第三获取单元,用于获取所述至少一个裁判文书的案件信息和裁判结果;
所述模型训练单元,包括:
第二词向量转换模块,用于根据所述至少一个裁判文书的案件信息,获得相应的第二文本词向量矩阵;
第二解读模块,用于对所述第二文本词向量矩阵分别进行正向解读和反向解读,获得第二正向解读结果和第二反向解读结果;
第二拼接模块,用于将所述第二正向解读结果和所述第二反向解读结果进行拼接;
第二信息抽取模块,用于对拼接获得的数据进行信息抽取,获得第二文本内容向量;
第二提取模块,用于从所述第二文本内容向量中提取出第二裁定向量;
优化模块,用于根据所述第二裁定向量和所述裁判文书的裁判结果对应的向量计算获得损失误差;利用所述损失误差,对所述裁判模型进行学习训练,直至所述裁判模型收敛。
第三方面,本发明提供了一种基于深度学习的裁判结果获取装置,包括:处理器、存储器以及计算机程序;
其中,所述计算机程序存储在所述存储器中,并被配置为由所述处理器执行以实现第一方面的任一方法。
第四方面,本发明提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行以实现第一方面的任一方法。
本发明提供了一种基于深度学习的裁判结果获取方法、装置及存储介质,根据待处理案件的原始文本获取案件信息,然后将该案件信息通过裁判模型进行处理,从而获得裁判结果。本方案基于输入的案件信息,通过深度学习训练获得的裁判模型实现智能裁判,从而有效提高案件处理效率。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。
图1为本发明实施例一提供的一种基于深度学习的裁判结果获取方法的流程图;
图2为本发明实施例二提供的一种基于深度学习的裁判结果获取方法的流程图;
图3为本发明实施例二提供的一种裁判模型的结构示意图;
图4为本发明实施例三提供的一种基于深度学习的裁判结果获取方法的流程图;
图5为本发明实施例四提供的一种基于深度学习的裁判结果获取装置的结构示意图;
图6为本发明实施例五提供的一种基于深度学习的裁判结果获取装置的结构示意图;
图7为本发明实施例六提供的一种基于深度学习的裁判结果获取装置的结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
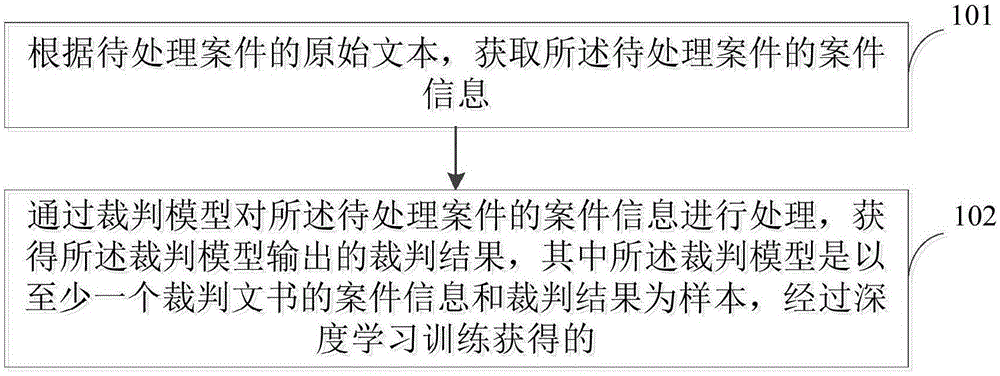
图1为本发明实施例一提供的一种基于深度学习的裁判结果获取方法的流程图,以该实施例提供的方法应用于基于深度学习的裁判结果获取装置来进行示例说明,如图1所示,该方法可以包括:
步骤101:根据待处理案件的原始文本,获取所述待处理案件的案件信息。
实际应用中,本实施例的执行主体可以为基于深度学习的裁判结果获取装置,该裁判结果获取装置可以为程序软件,也可以为存储有相关计算机程序的介质,例如,u盘等;或者,该裁判结果获取装置还可以为集成或安装有相关计算机程序的实体设备,例如,芯片、智能终端、电脑、服务器等。
结合实际场景进行示例:本方案中的原始文本指与案件相关的原始信息,其形式不限,例如可以为纸质案卷、电子案卷等。具体的,本实施例中的原始文本用于提取案件信息,因此可在不同场景,获取计算机可处理的原始文本,进一步的,获取的途径可以有多种,例如,可以根据案件材料进行原始文本的录入,该实施方式的准确性更高;或者对纸件的案件材料进行文字识别以获得原始文本,该实施方式的效率更高。
其中,本方案中的案件信息用于作为裁判模型的输入,从而对裁判模型进行深度学习训练或者通过裁判模型的处理获得输出的裁判结果。实际应用中,可以根据获取的原始文本来获得案件的所述案件信息,具体的处理方法可以有多种。可选的,在任一实施方式的基础上,101具体可以包括:
对待处理案件的原始文本进行分词处理,获得多个待处理词语;
根据不同词语对应的词语标识(wordid),获得并将多个待处理词语对应的词语标识作为待处理案件的案件信息。
具体的,可采用最大逆向匹配法进行分词处理,该分词算法的准确度较高,有利于提高裁判结果输出的准确性。
另外,当原始文本的数据量较大时,案件信息的数据量也比较大,因此,为进一步提高处理效率,所述方法还包括:
将案件信息的词语标识数量调整至预设阈值。
其中,所述阈值可以根据需要确定。调整的方式包括词语标识的增补或删减。在一种情形中,当案件信息对应的词语标识的数量小于所述阈值时,可对案件信息对应的词语标识进行增补。可选的,可以将预设标识增补至案件信息中,该预设标识可以为预定的字母标识、数字标识等,例如,可以为0。实际应用中,还可以对案件信息中的词语标识进行排序,例如,可以按照获取的顺序由前向后排列,相应的,在增补案件信息的词语标识时可以在最后一个词语标识之后补至少一个0,直至案件信息的词语标识为所述阈值。
在另一种情形中,当案件信息对应的词语标识数量大于所述阈值时,可将词语标识的数量删减至所述阈值。可选的,具体删减的方法可以有多种,例如,可以从案件信息的词语标识中删除信息量较小的词语(比如:了、的等等),以提高准确性。再例如,结合前述对词语标识进行排序的举例,在删减词语标识时,可以对超出所述阈值之后的词语标识直接进行删除,以提高效率。
值得说明的是,本方案中的词语标识用于唯一标识单个词语,该词语的长度不限,可以为至少一个字构成的词语。
步骤102:通过裁判模型对所述待处理案件的案件信息进行处理,获得所述裁判模型输出的裁判结果,其中所述裁判模型是以至少一个裁判文书的案件信息和裁判结果为样本,经过深度学习训练获得的。
实际应用中,裁判模型可以采用不同类型的模型,例如biblosan模型等。该裁判模型以至少一个裁判文书的案件信息和裁判结果为样本,经过深度学习训练获得。其中,本方案中的裁判结果可包括以下中的至少一项:犯罪嫌疑人姓名、是否死刑、是否无期徒刑、刑期长短、罚金数额、罪名及相关法条。
本实施例提供了一种基于深度学习的裁判结果获取方法,根据待处理案件的原始文本获取案件信息,然后将该案件信息通过裁判模型进行处理,从而获得裁判结果。本方案基于输入的案件信息,通过深度学习训练获得的裁判模型实现智能裁判,从而有效提高案件处理效率。另外,基于本方案还能够避免在裁判过程中主观因素的影响,提供更为客观的裁判结果,有利于提高裁判的准确性。
图2为本发明实施例二提供的一种基于深度学习的裁判结果获取方法的流程图,如图2所示,该方法可以包括:
步骤201:识别待处理案件的原始文本中的金额信息,对金额信息进行整数格式的转化。
举例来说,获取的待处理案件的原始文本为“a省b市c区人民检察院指控被告人张三于2016年7月4日到c区某超市门口,将被害人李四停放在该超市门口的一辆摩托车(经鉴定,价值人民币3086元)盗走,后因形迹可疑,被公安人员人赃并获,缴获的摩托车已发还被害人。”,通过识别,识别出待处理案件的原始文本中的金额信息为3086,那么为提高处理能力,以提高最终获得的裁判结果的效率和准确性,则对金额信息进行整数格式的转化,具体的,将金额信息转化为与之最接近的整数,也即将3086转化为3000。
步骤202:识别原始文本中的姓名信息,将姓名信息替换为同一姓名标识。
为进一步提高处理能力,以提高最终获得的裁判结果的效率和准确性,则对原始文本中出现的姓名信息进行替换处理,具体的,将原始文本中出现的所有姓名信息均替换为同一姓名标识,其中,同一姓名标识可以是用户根据实际需求预先设置的,例如,同一姓名标识可以是<name>。
通过识别,识别出原始文本中的姓名信息包括张三和李四,那么需要对这两个姓名信息进行替换处理,例如,将张三和李四均替换为<name>。
步骤203:识别原始文本中的时间信息,将时间信息替换为同一时间标识。
为进一步提高处理能力,以提高最终获得的裁判结果的效率和准确性,则对原始文本中出现的时间信息进行替换处理,具体的,将原始文本中出现的所有时间信息替换为同一时间标识,其中。
通过识别,识别出原始文本中的时间信息为2016年7月4日,那么需要对其进行替换处理,例如,将2016年7月4日替换为<time>。
经过上述对金额信息的整数格式的转化、对姓名信息的替换处理以及对时间信息的替换处理后,待处理案件的原始文本将变为“a省b市c区人民检察院指控被告人<name>于<time>到c区某超市门口,将被害人<name>停放在该超市门口的一辆摩托车(经鉴定,价值人民币3000元)盗走,后因形迹可疑,被公安人员人赃并获,缴获的摩托车已发还被害人。”。
需要说明的是,图2所示的流程图仅是本实施例的一种执行流程,其中,步骤201、步骤202和步骤203,这三个步骤之间的执行顺序不限,且也可不同时存在。另外,三个步骤之间可依赖执行,例如,首先执行的是步骤201,则执行完成后,会得到已经进行整数格式转化后的原始文本,接下来再执行步骤202时,则对已经进行整数格式转化后的原始文本进行识别,从而进行同一姓名信息的替换处理,依此类似原理在执行步骤203。
步骤204:根据处理后获得的原始文本,获取待处理案件的案件信息。
在本实施例中,可采用实施例一中的实现方式来获取待处理案件的案件信息。具体的,首先对处理后获得的原始文本进行分词处理,得到多个待处理词语‘a省’,‘b市’,‘c区’,‘人民检察院’,‘指控’,‘被告人’,‘<name>’,...,‘缴获’,‘的’,‘摩托车’,‘已’,‘发还’,‘被害人’,‘。’;然后根据不同词语对应的词语标识,将每一个待处理词语均转换为相应的词语标识,假设获得上述多个待处理词语对应的词语标识为[79,123,1824,434,1112,4978,...,65,7,45,236,426,56,21],最终判断获得的词语标识的个数是否超出预设阈值,假设阈值阈值为30,而获得的词语标识的个数为31,则按照由前向后的排列顺序,删掉第31个词语标识,也即删掉21,这样,最终将[79,123,1824,434,1112,4978,...,65,7,45,236,426,56]作为待处理案件的案件信息,并输入到下述裁判模型中。
步骤205:根据待处理案件的案件信息,获得相应的第一文本词向量矩阵。
图3为本发明实施例二提供的一种裁判模型的结构示意图,如图3所示,所采用的裁判模型为biblosan模型,在该模型中,首先待处理案件的案件信息[79,123,1824,434,1112,4978,...,65,7,45,236,426,56]输入至裁判模型的嵌入层embedding,以将输入的每一个词语标识分别转换为一个词向量,通过该层最终输出第一文本词向量矩阵,且第一文本词向量矩阵分别作为全连接层1和全连接层2的输入。
其中,将每一个词语标识分别转换为一个词向量可通过现有技术实现,此处不再具体展开描述。
步骤206:对第一文本词向量矩阵分别进行正向解读和反向解读,获得第一正向解读结果和第一反向解读结果。
在本实施例中,一方面,通过全连接层1和mbiosawithforwardmask实现对第一文本词向量矩阵的正向解读,获得第一正向解读结果;另一方面,通过全连接层2和mbiosawithbackwardmask实现对第一文本词向量矩阵的反向解读,获得第一反向解读结果,且第一正向解读结果和第一反向解读结果均输入至拼接层concatenate。
步骤207:将第一正向解读结果和第一反向解读结果进行拼接,对拼接获得的数据进行信息抽取,获得第一文本内容向量。
在本实施例中,由拼接层concatenate对输入的第一正向解读结果和第一反向解读结果进行拼接,通过concatenate层输出拼接后的数据,且拼接后的数据输入至信息抽取层sourcetotokenself-attention,通过该层实现信息的抽取,以获得第一文本内容向量,并输入至输出层。
步骤208:从第一文本内容向量中提取出第一裁定向量,对第一裁定向量进行解析,获得裁判结果。
实际应用中,可基于预设的裁判维度提取第一裁定向量,其中,裁判维度可根据裁判结果的需求设定,例如,涉及的法条、刑期、罪名、罚金等等。本实施例以预先设定法条、罪名以及刑期三个裁判维度为例。
现举例来说,第一文本内容向量的形状为{1,d},通过将第一文本内容向量与形状为{d,202}的向量相乘,得到形状为{1,202}的第一裁定向量,通过将第一文本内容向量与形状为{d,183}的向量相乘,得到形状为{1,183}的第一裁定向量,通过将第一文本内容向量与形状为{d,3}的向量相乘,得到形状为{1,3}的第一裁定向量,通过第一文本内容向量与形状为{d,1}的向量相乘,得到形状为{1,1}的第一裁定向量,其中,形状为{1,202}的第一裁定向量是针对被判的罪名这一裁判维度的,形状为{1,183}的第一裁定向量是针对所涉及的法条这一裁判维度的,形状为{1,3}的第一裁定向量是针对刑期这一维度的,形状为{1,1}的第一裁定向量是针对具体的刑期长短的,也即,根据三个裁判维度,提取出四个第一裁定向量,d为embedding层的词向量维度。
在解析罪名时,形状为{1,202}的第一裁定向量,可理解为,该向量由1行和202列组成,每一列对应的数值为相应罪名的预测值,另外,预先可根据实际需求设置一个罪名阈值,假设罪名阈值为0.5,在解析的过程中,若第1列和第3列分别对应的预测值为1,其余均小于0.5,则输出待处理案件对应的罪名为预设罪名列表中的第1个和第3个罪名。
法条解析的过程与罪名解析的过程类似,此处不再赘述。
在解析刑期时,首先解析形状为{1,3}的第一裁定向量,可理解为,该向量由1行和3列组成,3列分别对应死刑、无期、有期,若解析出是死刑或是无期,则直接输出该裁判结果,若是解析出有期,则继续解析形状为{1,1}的第一裁定向量,以将有期对应的时间输出。
本实施例通过对待处理案件的原始文本中的金额信息进行整数格式的转化处理、对姓名信息的替换处理以及对时间信息的替换处理,能够使得裁判模型在对输入的待处理案件的案件信息进行处理时,不会产生较大规模的词表,从而提高处理能力,进而能够快速的获得最终的裁判结果,而且也极大降低了处理过程中的出错率,从而也极大提高了最终输出结果的准确性。另外,本实施例可以通过裁判结果的裁判维度来提取相应的第一裁定向量,从而解析出多裁判维度的裁判结果,以为法官提供一种多裁判维度下客观的量刑参考方式。
图4为本发明实施例三提供的一种基于深度学习的裁判结果获取方法的流程图,如图4所示,该方法可以包括:
步骤401:获取至少一个裁判文书的案件信息和裁判结果。
实际应用中,需要从裁判文书中获取的数据形式可如下表1所示。
表1
首先,表1仅是一种示例说明,需要从裁判文书中获取的数据形式包含但不限于表1;其次,表1中,fact部分,也即案情描述部分,是对相应案件的具体描述,比如,什么时间、什么地点、发生了什么事情等,也即对应于本实施例中的案件信息这一部分;meta部分,共包括7项,其中倒数6项是针对相应案件的裁判结果,比如,判为有期徒刑3年等。
为提高裁判结果输出的准确性,本实施例可基于大量的裁判文书来对裁判模型进行深度学习训练,比如,按照表1的数据形式,从数十万个裁判文书中获取上述相关数据。
按照表1的数据形式,可以获取到如下表2所示的json文档形式的相关数据,其中,为便于解释说明,表2中仅以从三个裁判文书中分别获取到的相关数据为例。
表2
如表2所示,共包括3条数据。在从每一个裁判文书中获取到一条数据之后,首先可对其中的fact部分对应的案情描述进行金额信息的转化、姓名信息的替换处理、时间信息的替换处理,获得处理后的案情描述,其次,对处理后的案情描述再进行分词处理,获得多个词语,同理查找获得的每个词语对应的词语标识,然后可能还需要进行词语标识个数的限制处理,以此完成对每一条数据中案情描述的预处理,得到相应裁判文书的案件信息。
值得说明的是,在按表1的数据形式获得如表2所示的数十万条数据后,可预先对所有条数据进行如上所述的预处理,以获得数十万个裁判文书的案件信息并存储,这样,每次在训练裁判模型时,可直接从存储的数十万个裁判文书的案件信息中随机选择至少一个,直接利用选择的至少一个进行学习训练,从而能够大大提高裁判模型的训练效率。
另外,针对每一条数据中的meta部分,也即裁判结果部分,后续会根据裁判结果对应的向量计算损失误差,因此,还需将meta部分的相关数据转换成向量,这样,最终训练裁判模型所使用的数据可如下表3所示。
表3
步骤402:根据至少一个裁判文书的案件信息,获得相应的第二文本词向量矩阵。
以对图3所示的裁判模型进行深度学习训练为例,在本实施例中,图3中的第一文本词向量矩阵处应是第二文本词向量矩阵,假设本次共随机选择了64个裁判文书的案件信息,那么在预处理后,会获得每一个裁判文书的案件信息所对应的词语标识,这样,再将64个裁判文书的案件信息分别对应的词语标识输入到嵌入层后,通过嵌入层会将每一个词语标识转换为一个词向量,最终形成第二文本词向量。
步骤403:对第二文本词向量矩阵分别进行正向解读和反向解读,获得第二正向解读结果和第二反向解读结果。
步骤404:将第二正向解读结果和第二反向解读结果进行拼接,对拼接获得的数据进行信息抽取,获得第二文本内容向量。
步骤405:从第二文本内容向量中提取出第二裁定向量。
步骤403至步骤405的处理过程与实施例二类似,此处不再赘述。
步骤406:根据第二裁定向量和裁判文书的裁判结果对应的向量计算获得损失误差;利用损失误差,对裁判模型进行学习训练,直至裁判模型收敛。
在模型训练的过程中,不再对第二裁定向量进行解析,而是利用第二裁定向量和表3中的向量计算损失误差。举例来说,裁判结果共包括罪名、法条及刑期三个裁判维度,则通过上述步骤可获得针对罪名这一裁判维度的第二裁定向量,那么根据该第二裁定向量、64个裁判文书中的罪名分别对应的向量以及预设的罪名损失函数,计算获得罪名loss,同理,还可求得法条loss以及刑期loss,然后根据罪名loss、法条loss、、刑期loss以及每个裁判维度所占权重,计算获得裁判模型的损失误差,以利用该损失误差对裁判模型进行优化,重复执行步骤401至步骤406,直至裁判模型收敛,比如,在重复执行上述步骤几次之后,损失误差的波动较小,从而可认定裁判模型收敛,此处仅是一种示例,判断裁判模型是否收敛包含但不限于此。
步骤407:根据待处理案件的原始文本,获取待处理案件的案件信息。
步骤408:通过裁判模型对待处理案件的案件信息进行处理,获得裁判模型输出的裁判结果,其中裁判模型是以至少一个裁判文书的案件信息和裁判结果为样本,经过深度学习训练获得的。
在完成裁判模型的训练之后,可利用收敛的裁判模型输出待处理案件的裁判结果,而且,为提高裁判结果的准确性,在执行完成该步骤之后,还可重新执行上述步骤401至406,可对裁判模型再进行深度学习训练。
本实施例基于大量的裁判文书,具体的,以至少一个裁判文书的案件信息和裁判结果为样本数据,经过多次深度学习训练获得收敛的裁判模型,从而之后能够通过该收敛的裁判模型输出待处理案件对应的裁判结果,以此为法官提供一种客观的量刑参考方式。
图5为本发明实施例四提供的一种基于深度学习的裁判结果获取装置的结构示意图,如图5所示,包括:
第一获取单元501,用于根据待处理案件的原始文本,获取所述待处理案件的案件信息;
第二获取单元502,用于通过裁判模型对所述待处理案件的案件信息进行处理,获得所述裁判模型输出的裁判结果,其中所述裁判模型是以至少一个裁判文书的案件信息和裁判结果为样本,经过深度学习训练获得的。
在本实施例中,本实施例的基于深度学习的裁判结果获取装置可执行本发明实施例一提供的方法,其实现原理相类似,此处不再赘述。
本实施例提供了一种基于深度学习的裁判结果获取方法,根据待处理案件的原始文本获取案件信息,然后将该案件信息通过裁判模型进行处理,从而获得裁判结果。本方案基于输入的案件信息,通过深度学习训练获得的裁判模型实现智能裁判,从而有效提高案件处理效率。另外,基于本方案还能够避免在裁判过程中主观因素的影响,提供更为客观的裁判结果,有利于提高裁判的准确性。
图6为本发明实施例五提供的一种基于深度学习的裁判结果获取装置的结构示意图,在实施例四的基础上,如图6所示,
所述装置还包括:第一处理单元601,用于识别所述原始文本中的金额信息,对所述金额信息进行整数格式的转化;
进一步地,所述装置还包括:第二处理单元602,用于识别所述原始文本中的姓名信息,将所述姓名信息替换为同一姓名标识;
进一步地,所述装置还包括:第三处理单元603,用于识别所述原始文本中的时间信息,将所述时间信息替换为同一时间标识。
所述第二获取单元502,包括:
第一词向量转换模块5021,用于根据所述待处理案件的案件信息,获得相应的第一文本词向量矩阵;
第一解读模块5022,用于对所述第一文本词向量矩阵分别进行正向解读和反向解读,获得第一正向解读结果和第一反向解读结果;
第一拼接模块5023,将所述第一正向解读结果和所述第一反向解读结果进行拼接;
第一信息抽取模块5024,对拼接获得的数据进行信息抽取,获得第一文本内容向量;
第一提取模块5025,从所述第一文本内容向量中提取出第一裁定向量;
第一解析模块5026,对所述第一裁定向量进行解析,获得所述裁判结果。
在本实施例中,本实施例的基于深度学习的裁判结果获取装置可执行本发明实施例二提供的方法,其实现原理相类似,此处不再赘述。
本实施例通过对待处理案件的原始文本中的金额信息进行整数格式的转化处理、对姓名信息的替换处理以及对时间信息的替换处理,能够使得裁判模型在对输入的待处理案件的案件信息进行处理时,不会产生较大规模的词表,从而提高处理能力,进而能够快速的获得最终的裁判结果,而且也极大降低了处理过程中的出错率,从而也极大提高了最终输出结果的准确性。另外,本实施例可以通过裁判结果的裁判维度来提取相应的第一裁定向量,从而解析出多裁判维度的裁判结果,以为法官提供一种多裁判维度下客观的量刑参考方式。
图7为本发明实施例六提供的一种基于深度学习的裁判结果获取装置的结构示意图,在实施例四的基础上,如图7所示,
所述装置还包括:第三获取单元701和模型训练单元702;
所述第三获取单元701,用于获取所述至少一个裁判文书的案件信息和裁判结果;
所述模型训练单元702,包括:
第二词向量转换模块7021,用于根据所述至少一个裁判文书的案件信息,获得相应的第二文本词向量矩阵;
第二解读模块7022,用于对所述第二文本词向量矩阵分别进行正向解读和反向解读,获得第二正向解读结果和第二反向解读结果;
第二拼接模块7023,用于将所述第二正向解读结果和所述第二反向解读结果进行拼接;
第二信息抽取模块7024,用于对拼接获得的数据进行信息抽取,获得第二文本内容向量;
第二提取模块7025,用于从所述第二文本内容向量中提取出第二裁定向量;
优化模块7026,用于根据所述第二裁定向量和所述裁判文书的裁判结果对应的向量计算获得损失误差;利用所述损失误差,对所述裁判模型进行学习训练,直至所述裁判模型收敛。
在本实施例中,本实施例的基于深度学习的裁判结果获取装置可执行本发明实施例三提供的方法,其实现原理相类似,此处不再赘述。
本实施例基于大量的裁判文书,具体的,以至少一个裁判文书的案件信息和裁判结果为样本数据,经过多次深度学习训练获得收敛的裁判模型,从而之后能够通过该收敛的裁判模型输出待处理案件对应的裁判结果,以此为法官提供一种客观的量刑参考方式。
本实施例提供一种基于深度学习的裁判结果获取装置,包括:处理器、存储器以及计算机程序;
其中,所述计算机程序存储在所述存储器中,并被配置为由所述处理器执行以实现实施例一至实施例三任一提供的方法。
本实施例提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行以实现实施例一至实施例三任一提供的方法。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其它实施方案。本发明旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的权利要求书指出。
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求书来限制。
- 还没有人留言评论。精彩留言会获得点赞!