一种自动化搜索的方法与流程
发明涉及搜索的方法技术领域,具体为一种自动化搜索的方法。
背景技术:
搜索引擎可以被用来定位文档集合中的特定文档。此外,搜索引擎可以被用来定位文档中的特定关键词或短语。搜索引擎可以使用一个或多个索引来定位特定文档、关键词或短语。此外,搜索引擎可以在定位特定信息的过程中执行布尔和其它运算。为了设计一种使搜索更加快速、更加精确以及目的性较强的自动化搜索的方法显得非常必要。
技术实现要素:
发明的目的在于提供一种自动化搜索的方法,以解决上述背景技术中提出的问题。
为实现上述目的,发明提供如下技术方案:一种自动化搜索的方法,包括以下步骤:
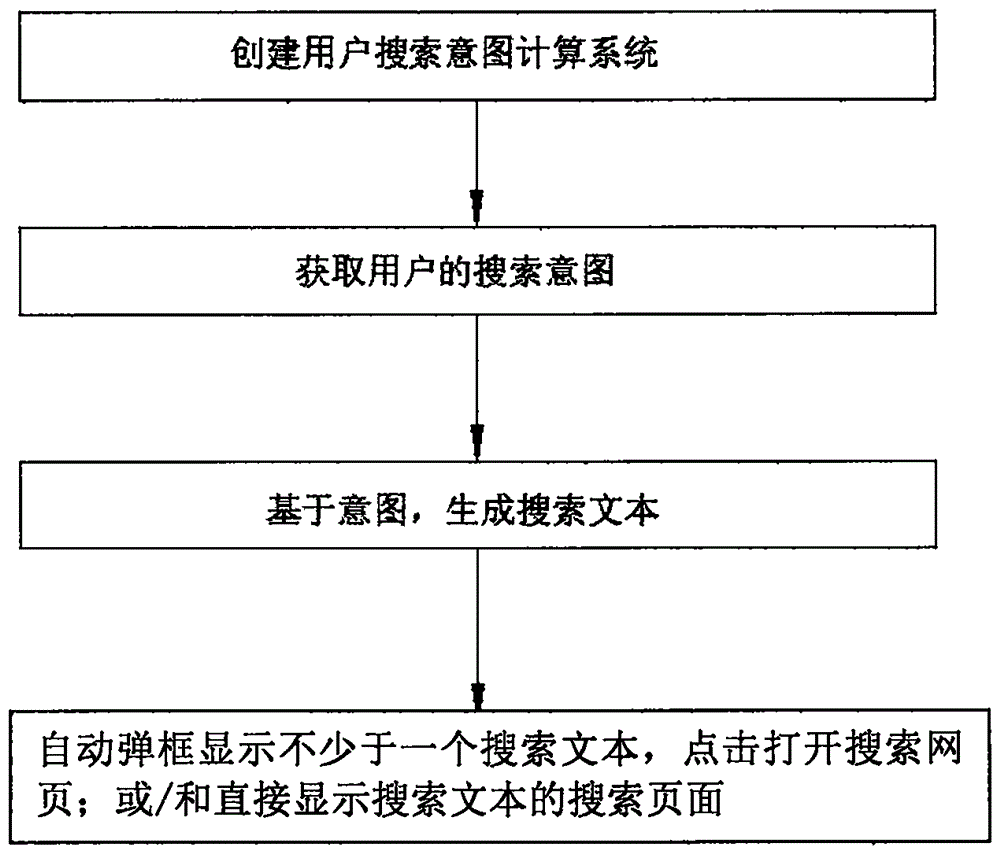
第一步:创建用户搜索意图计算系统,所述用户搜索意图计算系统,包括子系统:
(1)创建用户的个人场景事件图谱;
(2)搜索前,用户操作的复制、剪切、粘贴事件中的一种及多种组合;
(3)搜索前,用户在设备上接触的具体事件;
(4)搜索前,基于用户的消息、语音、视频、电邮通讯内容;
(5)基于用户的疑问;
(6)基于最近的热点新闻事件;
(7)基于新知识点;
(8)基于联系人、联系方式和通讯录附属信息;所述通讯录附属信息包括:单位、地址与备注信息;
(9)基于用户的拍照、视频;
(10)基于用户的个人场景搜索记录库;
(11)基于深度学习的概率预测;
(12)基于用户编辑的文档内容。
第二步:获取用户的搜索意图;
第三步:基于意图,生成搜索文本;所述生成搜索文本,包括:
(1)直接采用已有的文本;
(2)在已有的文本基础上,优化生成搜索文本;首先对已有的文本通过词条初始url进行解析,然后页面链接解析器基于定义的html规则将该页面中所包含的其它词条url保存至词条url库中,之后对解析的url发出抓取请求,将获取的数据发送至知识数据解析器,由知识数据解析器负责在每个词条页面中获取所需要的知识数据去重,最后对过滤后的知识数据进行三元组存储集合处理,达到优化生成搜索文本;
(3)智能生成搜索文本;
所述智能生成搜索文本包括:
①将图片、音频、视频、动漫转换成文本;
②将长句子、篇章文本通过文本摘要技术智能生成符合预先设定的搜索关键词的字数阈值;自动文摘过程包括三个基本步骤:
s1、文本分析过程:对长句子、篇章文本进行分析处理,识别出冗余信息;
s2、文本内容的选取和泛化过程:从文档中辨认重要信息,通过摘录式文摘和理解式文摘的方法压缩文本,形成文摘表示;摘录型文摘由原文中抽取出来的片段组成,理解型文摘是对原文只要内容重新组织后形成的;
s3、文摘的转换和生成过程:实现对原文内容的重组或根据语义表示生成文摘,并确保文摘的连贯性;
第四步:自动弹框显示不少于一个搜索文本,点击打开搜索网页;或/和直接显示基于搜索文本的搜索页面。
优选的,所述创建用户的个人场景事件图谱步骤包括:
步骤1:预设多层次场景标签库,并预设对应的场景逻辑关系、场景间的关联概率计算规则、以及场景之间的时序关系、链式串联表达关系;
步骤2:通过用户手机使用的基站与卫星定位系统动获得获取与计算用户的多层次场景标签值,对应存储到预设的多层次场景标签库中,根据预设的所述场景逻辑关系,生成用户个人场景;
步骤3:基于多个独立的用户个人场景,根据场景间的关联概率计算规则,计算预设时间段内多个独立的用户个人场景之间关联概率,根据预设的场景之间的时序关系、链式串联表达关系,生成用户个人场景图谱。
优选的,所述个人场景搜索记录库存储为区块链云服务器,包括私有区块链设备、公有区块链设备、节点服务器、中央服务器、硬件防火墙、区块链存储模块、发送模块和接收模块;其中私有区块链设备、公有区块链设备通过区块链存储模块存储个人的公有和私有的事件采集数据,实时的通过发送模块分布式发送到节点服务器中,通过接收模块接受实时采集的事件数据并通过节点服务器上传到中央服务器中,所述云服务器还包括硬件防火墙;区块链存储模块中数据划分为区块链备份模块、区块链隔离模块和区块链节点模块,将现有区块链数据按照功能隔离为单独的模块,区块链节点模块设置在节点服务器中,支持跨网络访问,在模块出现运行错误时,区块链备份模块、区块链隔离模块针对单一模块进行升级修复更新。
优选的,所述基于深度学习的猜测包括:应用于个人场景搜索记录库,对生成的数据做滤波、去除伪迹预处理操作,然后提取数据的人、时间、天气、地点、性别、职业、年龄、实时等特征参数,进行pca相关性主成分分析,提取主成分特征参数,然后训练识别模型,选择径向基函数为核函数的支持向量机作为情绪识别模型。
与现有技术相比,发明的有益效果是:通过组建预设多层次场景库,生成用户的个人场景;研究得到的用户模型的过程中主题数量丰富,解决了原始数据的稀疏性;创建个人场景数据,使得功能推荐更具针对性,提升了功能推荐的有效率,使得一些多维新特征场景信息补充通过功能推荐迅速获得大量用户大数据;通过多维度形态相关异构的信息连接在一起而得到的一个拓扑网络,信息样本全面;有效帮助用户快速发现感兴趣和高质量的信息,语义关联提供了背景知识搜索更加快速、更加精确以及目的性较强,具有超前精确的预测效果。可以精准定位文档集合中的特定文档。此外,该搜索引擎可以进一步被用来定位文档中的特定关键词或短语和使用一个或多个索引来定位特定文档、关键词或短语。快速的在定位特定信息的过程中执行布尔和其它运算。对生成的数据做滤波、去除伪迹等预处理操作,然后提取数据的人、时间、天气、地点、性别、职业、年龄、实时等特征参数,进行pca相关性主成分分析,提取主成分特征参数,然后训练识别模型,选择径向基函数为核函数的支持向量机作为情绪识别模型,不仅提高了推介效果、精确度,经过前pca主成分分析的特征前处理有利于数据的收敛。
附图说明
图1为一种自动化搜索的方法的流程示意图;
图2为一种自动化搜索的方法的优化生成搜索文本流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1:
请参阅图1和图2,发明提供一种技术方案:一种自动化搜索的方法,包括以下步骤:
第一步:创建用户搜索意图计算系统,所述用户搜索意图计算系统,包括子系统:
(1)创建用户的个人场景事件图谱;
(2)搜索前,用户操作的复制、剪切、粘贴事件中的一种及多种组合;
(3)搜索前,用户在设备上接触的具体事件;
(4)搜索前,基于用户的消息、语音、视频、电邮通讯内容;
(5)基于用户的疑问;
(6)基于最近的热点新闻事件;
(7)基于新知识点;
(8)基于联系人、联系方式和通讯录附属信息;所述通讯录附属信息包括:单位、地址与备注信息;
(9)基于用户的拍照、视频;
(10)基于用户的个人场景搜索记录库;
(11)基于深度学习的概率预测;
(12)基于用户编辑的文档内容。
第二步:获取用户的搜索意图;
第三步:基于意图,生成搜索文本;所述生成搜索文本,包括:
(1)直接采用已有的文本;
(2)在已有的文本基础上,优化生成搜索文本;首先对已有的文本通过词条初始url进行解析,然后页面链接解析器基于定义的html规则将该页面中所包含的其它词条url保存至词条url库中,之后对解析的url发出抓取请求,将获取的数据发送至知识数据解析器,由知识数据解析器负责在每个词条页面中获取所需要的知识数据去重,最后对过滤后的知识数据进行三元组存储集合处理,达到优化生成搜索文本;
(3)智能生成搜索文本;
所述智能生成搜索文本包括:
①将图片、音频、视频、动漫转换成文本;
②将长句子、篇章文本通过文本摘要技术智能生成符合预先设定的搜索关键词的字数阈值;自动文摘过程包括三个基本步骤:
s1、文本分析过程:对长句子、篇章文本进行分析处理,识别出冗余信息;
s2、文本内容的选取和泛化过程:从文档中辨认重要信息,通过摘录式文摘和理解式文摘的方法压缩文本,形成文摘表示;摘录型文摘由原文中抽取出来的片段组成,理解型文摘是对原文只要内容重新组织后形成的;
s3、文摘的转换和生成过程:实现对原文内容的重组或根据语义表示生成文摘,并确保文摘的连贯性;
第四步:自动弹框显示不少于一个搜索文本,点击打开搜索网页;或/和直接显示基于搜索文本的搜索页面。
优选的,所述创建用户的个人场景事件图谱步骤包括:
步骤1:预设多层次场景标签库,并预设对应的场景逻辑关系、场景间的关联概率计算规则、以及场景之间的时序关系、链式串联表达关系;
步骤2:通过用户手机使用的基站与卫星定位系统动获得获取与计算用户的多层次场景标签值,对应存储到预设的多层次场景标签库中,根据预设的所述场景逻辑关系,生成用户个人场景;
步骤3:基于多个独立的用户个人场景,根据场景间的关联概率计算规则,计算预设时间段内多个独立的用户个人场景之间关联概率,根据预设的场景之间的时序关系、链式串联表达关系,生成用户个人场景图谱。
优选的,所述个人场景搜索记录库存储为区块链云服务器,包括私有区块链设备、公有区块链设备、节点服务器、中央服务器、硬件防火墙、区块链存储模块、发送模块和接收模块;其中私有区块链设备、公有区块链设备通过区块链存储模块存储个人的公有和私有的事件采集数据,实时的通过发送模块分布式发送到节点服务器中,通过接收模块接受实时采集的事件数据并通过节点服务器上传到中央服务器中,所述云服务器还包括硬件防火墙;区块链存储模块中数据划分为区块链备份模块、区块链隔离模块和区块链节点模块,将现有区块链数据按照功能隔离为单独的模块,区块链节点模块设置在节点服务器中,支持跨网络访问,在模块出现运行错误时,区块链备份模块、区块链隔离模块针对单一模块进行升级修复更新。
实施例2:
创建多层次事件和场景图谱特征的方法,包括:
步骤1:预设多层次事件标签库和多层次场景标签库,并预设对应的场景事件逻辑关系、场景逻辑关系、场景间的关联概率计算规则、事件间的关联概率计算规则、以及场景图谱建立方法、事件图谱建立方法;所述多层次事件标签,包括一级事件标签和多级下属事件标签;一级事件标签包括:主体事件和客体事件;所述主体事件是指在计算机终端发生的事件;所述客体事件是指计算机终端通过视觉听觉识别系统侦测识别的外部发生的事件;
具体地,在本实施例中,对所述预设多层次事件标签库,做如下设计:
所述主体事件是指在计算机终端发生的事件,主体事件是一级事件标签,其包含二级事件标签:聊天、打电话、使用app、浏览;二级事件标签中的使用app包含三级事件标签:使用微信。
所述客体事件是指计算机终端通过视觉听觉识别系统侦测识别的外部发生的事件,客体事件是一级事件标签;其包含二级事件标签:开会、逛街、看电影、唱歌;二级事件标签中的看电影包含三级事件标签:看科幻片;三级事件标签中的看科幻片包含四级事件标签:看阿凡达。
步骤2:计算机终端通过视觉听觉识别获取和/或计算用户的多层次场景标签值,对应存储到预设的所述多层次场景标签库中,根据预设的所述场景逻辑关系,生成用户的个人场景,基于多个独立的用户个人场景,根据场景间的关联概率计算规则,计算预设时间段内多个独立的用户个人场景之间关联概率,根据预设的场景图谱建立方法,生成用户个人场景图谱;所述多层次场景标签,包括一级场景标签和多级下属场景标签,所述一级场景标签包括人、时间、地点、天气四个标签;所述场景图谱建立方法,是指一定时间内的多个独立的用户个人场景,基于正向和反向时序关系建立链式串联表达图,并在相邻的用户个人场景之间的边上标注其关联发生的概率;所述预设时间段,可由用户自定义;
所述时序关系包括:before:场景在另一个场景之前发生;after:场景在另一个场景之后发生;includes:一个场景包含另一个场景;is_included:一个场景被另一个场景包含;during:一个场景在一段时间内保持一个状态;simultane-ous:同时发生;iafter:场景紧跟另一个场景发生,且它们不重叠、不间断;ibe-fore场景在另一个场景之前发生,且它们不重叠、不间断;1iaentity:表示同一场景;begins:一个场景开始导致另一个场景开始;ends:一个场景结束导致另一个场景结束;begunby:一个场景因另一个场景开始而开始,与begins相对;ended_by:一个场景因另一个场景结束而结束,与ends相对;
所述时序关系的计算方法为:在采集场景的同时,采集场景发生的开始时间点和结束时间点,通过时间计算确定时序关系;所述正向和反向时序关系的确定方法:根据如上计算方法获得的13种时序关系,通过在时间轴表示场景相邻出现的关系;所述链式串联表达是指:基于正向和反向时序关系,建立多个独立的用户个人场景之间的链式串联表达图,并在邻接边上标注概率信息;
实施例3
时序创建个人场景多维度特征图谱的方法,包括:
步骤1:预设多层次场景标签库,并预设对应的场景逻辑关系、场景间的关联概率计算规则、以及场景之间的时序关系、链式串联表达关系,所述多层次场景标签,包括一级场景标签和多级下属场景标签,所述一级场景标签包括人、时间、地点、天气四个标签;
具体地,在本实施例中,对所述预设多层次场景标签库,做如下设计:
1.人是一级场景标签,预设对应的标签条目;其包含二级场景标签:性别/职业/婚姻状态/年龄/健康状况/心情,预设对应的标签条目;二级场景标签中的医生包含三级场景标签:职务/职位,预设对应的标签条目,所有预设的标签条目按照逻辑从属关系排列建库。
2.时间是一级场景标签;其包含二级场景标签:季节/年中状态/生日/工作日;二级场景标签中的工作日包含三级场景标签:上午上班时段/下午上班时段;三级场景标签中的上午上班时段包含四级场景标签:刚上班时段/快下班时段,预设对应的标签条目,所有预设的标签条目按照逻辑从属关系排列建库。
3.地点是一级场景标签;其包含二级场景标签:家里/公司/餐厅/电影院;二级场景标签中的餐厅包含三级场景标签:西餐厅/中餐厅;三级场景标签中的中餐厅包含四级场景标签:湘菜馆/川菜馆,预设对应的标签条目,所有预设的标签条目按照逻辑从属关系排列建库。
4.天气是一级场景标签;其包含二级场景标签:好天气/不好天气/气候灾难;二级场景标签中不好天气包含三级场景标签:气象/温度/风力,预设对应的标签条目,所有预设的标签条目按照逻辑从属关系排列建库。
步骤2:通过用户手机使用的基站或/和卫星定位系统动获得获取和/或计算用户的多层次场景标签值,对应存储到预设的多层次场景标签库中,根据预设的所述场景逻辑关系,生成用户个人场景,所述人的多层次场景标签值,由预设的用户画像数据库或/和实时计算获得,所述时间的多层次场景标签值,由系统自动获得,所述地点的多层次场景标签值,由用户手机使用的基站或/和卫星定位系统动获得,所述天气的多层次场景标签值,由系统自动获得,所述场景逻辑关系,是在多层次场景标签库的各场景标签之间,定义场景标签获得对应的场景标签值后,用于组成描述用户个人场景的规则;
实施例4
优选的,所述基于深度学习的猜测包括:应用于个人场景搜索记录库,对生成的数据做滤波、去除伪迹预处理操作,然后提取数据的人、时间、天气、地点、性别、职业、年龄、实时等特征参数,进行pca相关性主成分分析,提取主成分特征参数,然后训练识别模型,选择径向基函数为核函数的支持向量机作为情绪识别模型。
工作原理:通过组建预设多层次场景库,生成用户的个人场景;研究得到的用户模型的过程中主题数量丰富,解决了原始数据的稀疏性;创建个人场景数据,使得功能推荐更具针对性,提升了功能推荐的有效率,使得一些多维新特征场景信息补充通过功能推荐迅速获得大量用户大数据;通过多维度形态相关异构的信息连接在一起而得到的一个拓扑网络,信息样本全面;有效帮助用户快速发现感兴趣和高质量的信息,语义关联提供了背景知识搜索更加快速、更加精确以及目的性较强,具有超前精确的预测效果。可以精准定位文档集合中的特定文档。此外,该搜索引擎可以进一步被用来定位文档中的特定关键词或短语和使用一个或多个索引来定位特定文档、关键词或短语。快速的在定位特定信息的过程中执行布尔和其它运算。对生成的数据做滤波、去除伪迹等预处理操作,然后提取数据的人、时间、天气、地点、性别、职业、年龄、实时等特征参数,进行pca相关性主成分分析,提取主成分特征参数,然后训练识别模型,选择径向基函数为核函数的支持向量机作为情绪识别模型,不仅提高了推介效果、精确度,经过前pca主成分分析的特征前处理有利于数据的收敛。
该自动化搜索的方法搜索更加快速、更加精确以及目的性较强,具有超前精确的预测效果。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!