语意分析方法、语意分析系统及非暂态计算机可读取媒体与流程
本案是有关于一种语意分析方法、语意分析系统以及非暂态计算机可读取媒体,且特别是有关于一种用以分析自然语言意图的语意分析方法、语意分析系统及非暂态计算机可读取媒体。
背景技术:
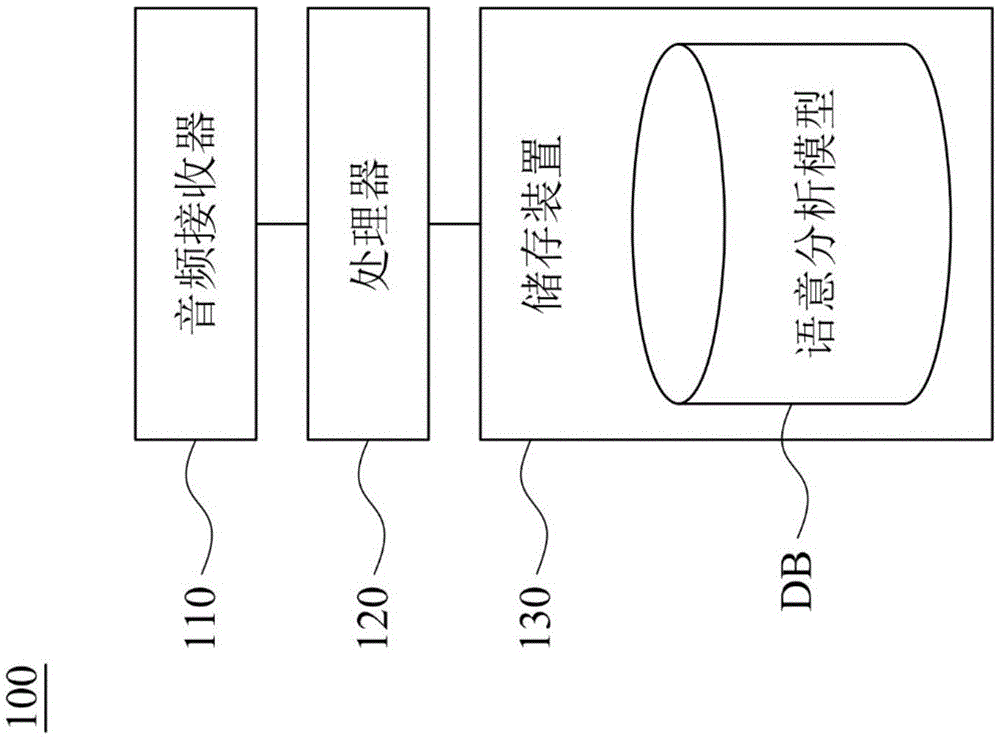
:近年来自然语言理解技术(naturallanguageunderstanding,nlu)的发展已逐渐成熟(例如:google的语音辨识或siri),使用者在操作移动装置或个人计算机等电子产品时,也越来越常使用语音输入或语音控制的功能,然而,以往进行自然语言理解技术时通常是利用标记数据或关键信息进行类神经网络的训练,但通常也耗费时间过大以及准确率的问题。因此,如何让自然语言理解技术在不花费过多处理时间的情况下,增加自然语言分析的准确率,为本领域待改进的问题之一。技术实现要素:本发明的主要目的是提供一种语意分析方法、语意分析系统以及非暂态计算机可读取媒体,其利用词汇的词性以及关联剖析找出关键词汇以及关联子句,达到提升自然语言理解技术准确率的功能。为达成上述目的,本案的第一态样是提供一种语意分析方法,此方法包含以下步骤:输入语音并辨识语音以产生输入语句;其中输入语句包含多个词汇,每一词汇具有对应的词汇向量;根据每一词汇对应的词性从词汇中选择至少一关键词汇;根据输入语句的词汇建立剖析树,并根据剖析树以及至少一关键词汇找出多个关联子句;其中,每一关联子句包含部分的词汇;计算关联子句之间的关联特征向量;串接关联特征向量与每一词汇对应的词汇向量,以产生每一词汇对应的词汇特征向量;以及利用语意分析模型分析词汇特征向量以产生分析结果;其中,分析结果包含每一词汇对应的属性分类以及输入语句对应的意图。根据本案一实施例,还包含:利用所述多个词汇、每一该词汇对应的词汇向量以及该关联特征向量作为训练数据,以产生该语意分析模型。根据本案一实施例,还包含:将该输入语句进行断词处理以产生一词汇集合;其中,该词汇集合包含所述多个词汇。根据本案一实施例,每一该关联子句包含该至少一关键词汇的一部分。根据本案一实施例,计算所述多个关联子句之间的该关联特征向量,还包含:利用每一该关联子句的部分的所述词汇对应的词汇向量进行n元语法计算以产生多个第一n元语法特征;根据所述多个第一n元语法特征进行一特征计算以产生一特征向量;以及根据该特征向量进行一权重计算,以产生该关联特征向量。根据本案一实施例,计算所述多个关联子句之间的该关联特征向量,还包含:利用所述多个词汇对应的词汇向量进行n元语法计算以产生多个第一n元语法特征;利用每一该关联子句的部分的所述词汇对应的词汇向量进行n元语法计算以产生多个第二n元语法特征;将所述多个第一n元语法特征以及所述多个第二n元语法特征分别进行一特征计算以产生一第一特征向量以及一第二特征向量;以及根据该第二特征向量进行一权重计算以产生一加权向量,将该第一特征向量与该加权向量串接,以产生该关联特征向量。根据本案一实施例,该权重计算是利用所述多个关联子句中的该至少一关键词汇的数量决定一权重值。本案的第二态样是提供一种语意分析系统,其包含:音频接收器、处理器以及储存装置。音频接收器用以接收语音。处理器与音频接收器电性连接。储存装置用以储存输入语句以及语意分析模型。处理器包含:语音辨识元件、关键词汇选择元件、关联子句产生元件、特征向量计算元件、词汇向量产生元件以及分析结果产生元件。语音辨识元件用以辨识语音以产生输入语句;其中输入语句包含多个词汇,每一词汇具有对应的词汇向量。关键词汇选择元件与语音辨识元件电性连接,用以根据每一词汇对应的词性从词汇中选择至少一关键词汇。关联子句产生元件与关键词汇选择元件电性连接,用以根据输入语句的词汇建立剖析树,并根据剖析树以及至少一关键词汇找出多个关联子句;其中,每一关联子句包含部分的词汇。特征向量计算元件与关联子句产生元件电性连接,用以计算关联子句之间的关联特征向量。词汇向量产生元件与特征向量计算元件电性连接,用以串接关联特征向量与每一词汇对应的词汇向量,以产生每一词汇对应的词汇特征向量。分析结果产生元件与词汇向量产生元件电性连接,利用语意分析模型分析词汇特征向量以产生分析结果;其中,分析结果包含每一词汇对应的属性分类以及输入语句对应的意图。根据本案一实施例,还包含:一分析模型建立元件,与该词汇向量产生元件与该分析结果产生元件电性连接,用以利用所述多个词汇、每一该词汇对应的词汇向量以及该关联特征向量作为训练数据,以产生该语意分析模型。根据本案一实施例,还包含:一断词处理元件,与该语音辨识元件与该关键词汇选择元件电性连接,用以将该输入语句进行断词处理以产生一词汇集合;其中,该词汇集合包含所述多个词汇。根据本案一实施例,每一该关联子句包含该至少一关键词汇的一部分。根据本案一实施例,该特征向量计算元件更用以利用每一该关联子句的部分的所述词汇对应的词汇向量进行n元语法计算以产生多个第一n元语法特征,根据所述多个第一n元语法特征进行一特征计算以产生一特征向量,且根据该特征向量进行一权重计算,以产生该关联特征向量。根据本案一实施例,该特征向量计算元件更用以利用所述多个词汇对应的词汇向量进行n元语法计算以产生多个第一n元语法特征,利用每一该关联子句的部分的所述词汇对应的词汇向量进行n元语法计算以产生多个第二n元语法特征,将所述多个第一n元语法特征以及所述多个第二n元语法特征分别进行一特征计算以产生一第一特征向量以及一第二特征向量,根据该第二特征向量进行一权重计算以产生一加权向量,且将该第一特征向量与该加权向量串接,以产生该关联特征向量。根据本案一实施例,该权重计算是利用所述多个关联子句中的该至少一关键词汇的数量决定一权重值。本案的第三态样是提供一种非暂态计算机可读取媒体包含至少一指令程序,由处理器执行至少一指令程序以实行语意分析方法,其包含以下步骤:输入语音并辨识语音以产生输入语句;其中输入语句包含多个词汇,每一词汇具有对应的词汇向量;根据每一词汇对应的词性从词汇中选择至少一关键词汇;根据输入语句的词汇建立剖析树,并根据剖析树以及至少一关键词汇找出多个关联子句;其中,每一关联子句包含部分的词汇;计算关联子句之间的关联特征向量;串接关联特征向量与每一词汇对应的词汇向量,以产生每一词汇对应的词汇特征向量;以及利用语意分析模型分析词汇特征向量以产生分析结果;其中,分析结果包含每一词汇对应的属性分类以及输入语句对应的意图。本发明的语意分析方法、语意分析系统及非暂态计算机可读取媒体,其利用词汇的词性以及关联剖析找出关键词汇以及关联子句,再利用n元语法计算特征向量后,根据语意分析模型计算出输入语句对应的意图以及每一词汇对应的属性分类,达到提升自然语言理解技术准确率的功能。附图说明为让本发明的上述和其他目的、特征、优点与实施例能更明显易懂,所附附图的说明如下:图1是根据本案的一些实施例所绘示的语意分析系统的示意图;图2是根据本案的一些实施例所绘示的处理器的示意图;图3是根据本案的一些实施例所绘示的语意分析方法的流程图;图4是根据本案的一些实施例所绘示的剖析树的示意图;图5是根据本案的一些实施例所绘示的步骤s350的流程图;以及图6是根据本案的一些实施例所绘示的步骤s350的流程图。具体实施方式以下揭示提供许多不同实施例或例证用以实施本发明的不同特征。特殊例证中的元件及配置在以下讨论中被用来简化本揭示。所讨论的任何例证只用来作为解说的用途,并不会以任何方式限制本发明或其例证的范围和意义。此外,本揭示在不同例证中可能重复引用数字符号且/或字母,这些重复皆为了简化及阐述,其本身并未指定以下讨论中不同实施例且/或配置之间的关系。请参阅图1。图1是根据本案的一些实施例所绘示的语意分析系统100的示意图。如图1所绘示,语意分析系统100包含音频接收器110、处理器120以及储存装置130。处理器120电性连接至音频接收器110以及储存装置130,音频接收器110用以接收语音,储存装置130用以储存输入语句以及语意分析模型db。处理器120用以针对输入语句进行语意分析,并计算出输入语句的词汇对应的属性分类以及输入语句的意图。于本发明各实施例中,音频接收器110可以实施为麦克风或是音频收发器等装置。处理器120可以实施为集成电路如微控制单元(microcontroller)、微处理器(microprocessor)、数字信号处理器(digitalsignalprocessor)、特殊应用集成电路(applicationspecificintegratedcircuit,asic)、逻辑电路或其他类似元件或上述元件的组合。储存装置130可以实施为记忆体、硬盘、随身盘、记忆卡等,本揭露不以此为限。请参阅图2。图2是根据本案的一些实施例所绘示的处理器120的示意图。处理器120包含语音辨识元件121、关键词汇选择元件122、关联子句产生元件123、特征向量计算元件124、词汇向量产生元件125、分析结果产生元件126、分析模型建立元件127以及断词处理元件128。关键词汇选择元件122与语音辨识元件121以及关联子句产生元件123电性连接,断词处理元件128与关键词汇选择元件122以及语音辨识元件121电性连接,特征向量计算元件124与关联子句产生元件123以及词汇向量产生元件125电性连接,词汇向量产生元件125与分析结果产生元件126电性连接,并且分析模型建立元件127与词汇向量产生元件125以及分析结果产生元件126电性连接。请参阅图3。图3是根据本案的一些实施例所绘示的语意分析方法300的流程图。于一实施例中,图3所示的语意分析方法300可以应用于图1的语意分析系统100上,处理器120根据下列语意分析方法300所描述的步骤对输入语句进行语意分析,并计算出输入语句的词汇对应的属性分类以及输入语句的意图。语意分析方法300首先执行步骤s310输入语音并辨识语音以产生输入语句,以及步骤s320将输入语句进行断词处理以产生词汇集合。于一实施例中,词汇集合包含多个词汇,每一个词汇具有对应的词汇向量。举例而言,输入语句为「我想要看搭配学生方案的samsung手机」,经由断词处理后输入语句可以分成词汇v1(即「我」)、词汇v2(即「想要」)、词汇v3(即「看」)、词汇v4(即「搭配」)、词汇v5(即「学生方案」)、词汇v6(即「的」)、词汇v7(即「samsung」)及词汇v8(即「手机」),上述断词处理后的8个词汇可以形成词汇集合。接着,每个词汇都具有对应的词汇向量,举例而言,词汇v1对应的词汇向量是(1,2,1),词汇v2对应的词汇向量是(1,0,9),词汇v3对应的词汇向量是(2,3,4),词汇v4对应的词汇向量是(2,6,7),词汇v5对应的词汇向量是(5,4,3),词汇v6对应的词汇向量是(7,8,9),词汇v7对应的词汇向量是(1,7,8),词汇v8对应的词汇向量是(3,0,4)。接着,语意分析方法300执行步骤s330根据每一词汇对应的词性从词汇中选择至少一关键词汇。值得注意义的是,一般名词与专有名词通常是自然语言中比较重要的词汇,因此至少一关键词汇通常都是词汇的一部分,于上述的实施例中,词汇v7、词汇v6以及词汇v4是此范例中的关键词汇。接着,语意分析方法300执行步骤s340根据输入语句的词汇建立剖析树,并根据剖析树以及至少一关键词汇找出多个关联子句。其中,每一关联子句包含部分的词汇。请一并参考图4,图4是根据本案的一些实施例所绘示的剖析树的示意图。如图4所示的实施例,利用词汇v1、词汇v2、词汇v3、词汇v4、词汇v5、词汇v6、词汇v7及词汇v8建立剖析树。在本实施例中,剖析树可以利用中央研究院提供的中文句结构树数据库(sinicatreebank)建立,本揭露不以此为限。剖析树建立完毕后,分别将词汇v4、词汇v6及词汇v7三个关键词汇作为起始点,回推到根部r,经过的词汇将形成为关联子句。举例而言,从词汇v4开始经由路径p1会经过词汇v3及词汇v1,因此词汇v1、词汇v3及词汇v4将作为第一个关联子句。接着从词汇v6开始经由路径p2会经过词汇v4、词汇v3及词汇v1,因此词汇v1、词汇v3、词汇v4及词汇v6将作为第二个关联子句。接着从词汇v7开始经由路径p3会经过词汇v5、词汇v4、词汇v3及词汇v1,因此词汇v1、词汇v3、词汇v4、词汇v5及词汇v7将作为第三个关联子句。在此实施例中,由于关键词汇有三个因此会形成三个关联子句,由此可知,关联子句的数量与关键词汇有关。而三个关联子句中的词汇都来自于词汇集合中的部分词汇,并且每一关联子句也会包含至少一关键词汇的一部分。接着,语意分析方法300进一步执行步骤s350计算关联子句之间的关联特征向量。步骤s350还包含步骤s351a~s353a。请一并参考图5,图5是根据本案的一些实施例所绘示的步骤s350的流程图。语意分析方法300进一步执行步骤s351a利用每一关联子句的部分的词汇对应的词汇向量进行n元语法(n-gram)计算以产生多个第一n元语法特征。举例而言,请一并参考表一及表二,第一个关联子句的词汇向量如表一所示,首先进行二元语法计算,利用2×1大小的矩阵针对词汇v1、词汇v3以及词汇v4对应的词汇向量进行卷积(convolution)运算,因此可以得出表二所示第一关联子句的二元语法计算结果。举例而言,如果2×1大小的矩阵为[1,2]t,利用此矩阵对第1栏的行向量(1,2)进行卷积运算计算出的结果为5,再利用此矩阵对第1栏的行向量(2,2)进行卷积运算计算出的结果为6。其余第2栏以及第3栏的行向量计算与上述相同,在此不再赘述。表一:第一个关联子句的词汇向量表二:第一个关联子句的二元语法计算结果第1栏第2栏第3栏58961518接着,再进行三元语法计算,利用3×1大小的矩阵针对词汇v1、词汇v3以及词汇v4对应的词汇向量进行卷积(convolution)运算,因此可以得出表三所示第一个关联子句的三元语法计算结果。举例而言,如果3×1大小的矩阵为[1,1,1]t,利用此矩阵对第1栏的行向量(1,2,2)进行卷积运算计算出的结果为5。其余第2栏以及第3栏的行向量计算与上述相同,在此不再赘述。第一n元语法特征即为第一个关联子句的二元语法计算结果以及三元语法计算结果,在此实施例中仅以二元语法以及三元语法的计算作为范例,也可以使用四元语法或五元语法,本揭露不限于此。表三:第一个关联子句的三元语法计算结果第1栏第2栏第3栏51112接着,再举例而言,请一并参考表四及表五,第二个关联子句的词汇向量如表四所示,首先进行二元语法计算,利用2×1大小的矩阵针对词汇v1、词汇v3、词汇v4以及词汇v6对应的词汇向量进行卷积运算,因此可以得出表五所示第二个关联子句的二元语法计算结果。根据上述的实施例,2×1大小的矩阵为[1,2]t,利用此矩阵对第1栏的行向量(1,2)进行卷积运算计算出的结果为5,利用此矩阵对第1栏的行向量(2,2)进行卷积运算计算出的结果为6,再利用此矩阵对第1栏的行向量(2,7)进行卷积运算计算出的结果为16。其余第2栏以及第3栏的行向量计算与上述相同,在此不再赘述。表四:第二个关联子句的词汇向量表五:第二个关联子句的二元语法计算结果第1栏第2栏第3栏58961518162225接着,再进行三元语法计算,利用3×1大小的矩阵针对词汇v1、词汇v3、词汇v4以及词汇v6对应的词汇向量进行卷积运算,因此可以得出表六所示第二个关联子句的三元语法计算结果。根据上述实施例,如果3×1大小的矩阵为[1,1,1]t,利用此矩阵对第1栏的行向量(1,2,2)进行卷积运算计算出的结果为5,再利用此矩阵对第1栏的行向量(2,2,7)进行卷积运算计算出的结果为11。其余第2栏以及第3栏的行向量计算与上述相同,在此不再赘述。表六:第二个关联子句的三元语法计算结果第1栏第2栏第3栏51112111720承上述,第三个关联子句的计算方式与第一个关联子句以及第二个关联子句的计算方式相同,故在此不再赘述。第三个关联子句的二元语法计算结果如表七所示,第三个关联子句的三元语法计算结果如表八所示。第二n元语法特征即为第二个关联子句的二元语法计算结果以及三元语法计算结果。表七:第三个关联子句的二元语法计算结果第1栏第2栏第3栏5896151812141371819表八:第三个关联子句的三元语法计算结果第1栏第2栏第3栏511129131481718接着,语意分析方法300执行步骤s352a根据第一n元语法特征进行特征计算以产生特征向量。于一实施例中,计算出第一n元语法特征后,会进行特征计算。请一并参考表二以及表三,首先针对第一个关联子句的二元语法计算结果进行最大值筛选,从表二的第1栏所示的结果中选择最大值,在此即为6;从表二的第2栏所示的结果中选择最大值,在此即为15;从表二的第3栏所示的结果中选择最大值,在此即为18。因此在经过最大值筛选后的第一个关联子句的二元语法计算结果为(6,15,18)。接着针对第一个关联子句的三元语法计算结果进行最大值筛选,因此在经过最大值筛选后的第一个关联子句的三元语法计算结果为(5,11,12)。接着,将最大值筛选后的第一个关联子句的二元语法计算结果与最大值筛选后的第一个关联子句的三元语法计算结果相加为第一个关联子句的特征向量,在此第一个关联子句的特征向量为(11,26,30)。承上述,第二个关联子句的特征向量的计算方式与上述第一个关联子句的特征向量的计算方式相同,故在此不再赘述。经过最大值筛选后的第二个关联子句的二元语法计算结果为(6,22,25),经过最大值筛选后的第二个关联子句的三元语法计算结果为(11,17,20)。接着,将最大值筛选后的第二个关联子句的二元语法计算结果与最大值筛选后的第二个关联子句的三元语法计算结果相加即为第二个关联子句的特征向量,在此第二个关联子句的特征向量为(27,39,45)。承上述,第三个关联子句的特征向量的计算方式与上述第一个关联子句的特征向量及第二个关联子句的特征向量的计算方式相同,同样在此不再赘述。经过最大值筛选后的第三个关联子句的二元语法计算结果为(12,18,19),经过最大值筛选后的第三个关联子句的三元语法计算结果为(9,17,18)。接着,将最大值筛选后的第三个关联子句的二元语法计算结果与最大值筛选后的第三个关联子句的三元语法计算结果相加即为第三个关联子句的特征向量,在此第三个关联子句的特征向量为(21,35,37)。接着,语意分析方法300进一步执行步骤s353a根据特征向量进行权重计算,以产生关联特征向量。其中,权重计算是根据关联子句中的该至少一关键词汇的数量决定,接续上方实施例,在第一个关联子句中具有词汇v4一个关键词汇,第二个关联子句中具有词汇v4以及词汇v6两个关键词汇,以及第三个关联子句中具有词汇v4以及词汇v7两个关键词汇。总共有五个关键词汇,故第一个关联子句对应的权重为1/5,第二个关联子句对应的权重为2/5,第三个关联子句对应的权重为2/5。因此,关键特征向量=第一个关联子句的特征向量×(1/5)+第二个关联子句的特征向量×(2/5)+第三个关联子句的特征向量×(2/5)。于另一实施例中,语意分析方法300进一步执行步骤s350计算关联子句之间的关联特征向量。步骤s350还包含步骤s351b~s353b。请一并参考图6,图5是根据本案的一些实施例所绘示的步骤s350的流程图。语意分析方法300进一步执行步骤s351b利用词汇对应的词汇向量进行n元语法计算以产生多个第一n元语法特征,以及利用每一关联子句的部分的词汇对应的词汇向量进行n元语法计算以产生多个第二n元语法特征。步骤s351b的计算方式与步骤s351a相同,在此不再赘述。步骤s351b与步骤s351a的差异在于,步骤s351b更用以计算输入语句的n元语法特征,即为第一n元语法特征。接着,语意分析方法300执行步骤s352b第一n元语法特征以及第二n元语法特征分别进行特征计算以产生第一特征向量以及第二特征向量。承上述,步骤s352b的计算方式与步骤s352a的计算方式相同,故在此不再赘述。步骤s352b与步骤s352a的差异在于,步骤s352b更用以计算输入语句的n元特征向量,即为第一特征向量。接着,语意分析方法300进一步执行步骤s353b根据第二特征向量进行权重计算以产生加权向量,将加权向量与第一特征向量串接,以产生关联特征向量。于此实施例中,第二特征向量的权重计算方式与前述相同,在此不再赘述。第二特征向量经过权重计算后会得到加权向量,加权向量再与第一特征向量串接,即可得到关联特征向量。举例而言,第二特征向量经过权重计算得到的加权向量为(20,33,38),如果第一特征向量为(29,35,44),经过串接后的关联特征向量为(29,35,44,20,33,38)。接着,语意分析方法300进一步执行步骤s360串接关联特征向量与每一词汇对应的词汇向量,以产生每一词汇对应的词汇特征向量。于一实施例中,将步骤s350计算出的关联特征向量与每一词汇对应的词汇向量串接,以产生每一词汇对应的词汇特征向量。举例而言,词汇v7对应的词汇向量为(1,7,8),如果关联特征向量为(20,33,38),词汇v7对应的词汇特征向量即将对应的词汇向量(1,7,8)与关联特征向量(20,33,38)串接为(1,7,8,20,33,38)。经过上述的计算后,词汇特征向量可以包含关键词汇的信息,加强词汇之间的关联强度,使得语意分析模型db可以在对词汇进行属性分类时可以更准确。接着,语意分析方法300执行步骤s370利用语意分析模型db分析词汇特征向量以产生分析结果。于一实施例中,在执行步骤s370之前需要先建立语意分析模型db。意即,根据这些词汇、每一个词汇对应的词汇向量以及上述产生的关联特征向量作为训练数据产生语意分析模型db。更进一步来说,将这些词汇、每一词汇对应的词汇向量以及上述产生的关联特征向量输入至bi-lstm模型(bidirectionallstm)进行运算,以据此产生语意分析模型db。经过语意分析模型db计算之后会得出每一词汇对应的属性分类以及输入语句对应的意图的分析结果,语意分析模型db计算后可以将输入的属性分类为b-type、i-type以及o-type,b-type表示为一个词汇的开始,i-type则是接续在b-type后方的词汇,o-type则是属于未事先定义的其它词汇。接续上方实施例,词汇v1-v8经过上述计算词汇特征向量并将计算结果输入至语意分析模型db后,将可以得出词汇v7以及词汇v6是属于b-type的属性分类,词汇v2、词汇v1、词汇v3、词汇v5、词汇v8及词汇v4是属于o-type的属性分类,且输入语句「我想要看搭配学生方案的samsung手机」的意图为「选择手机」。由上述本案的实施方式可知,主要是改进以往自然语言理解的技术,利用词汇的词性以及关联剖析找出关键词汇以及关联子句,再利用n元语法计算特征向量后,根据语意分析模型计算出输入语句对应的意图以及每一词汇对应的属性分类,达到提升自然语言理解技术准确率的功能。另外,上述例示包含依序的示范步骤,但这些步骤不必依所显示的顺序被执行。以不同顺序执行该些步骤皆在本揭示内容的考量范围内。在本揭示内容的实施例的精神与范围内,可视情况增加、取代、变更顺序及/或省略这些步骤。虽然本案已以实施方式揭示如上,然其并非用以限定本案,任何熟悉此技艺者,在不脱离本案的精神和范围内,当可作各种的更动与润饰,因此本案的保护范围当视所附的权利要求书所界定的范围为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1