对等式数据运算与存储架构构建方法与流程
本发明涉及数据湖服务器群架构,特别涉及一种对等式数据运算与存储架构构建方法。
背景技术:
大规模集团级企业的数据运算和存储应用的特点在于,尽管总公司与其所属子公司之间是管理与被管理的关系,在实际集团级公司的运营中,总公司与子公司之间是事实上的合作关系,总公司对子公司的管理是宏观的,子公司需要保留自己运营的独立性。因而,在数据分享方面,总公司与各个子公司之间是存在利益博弈的,这时,双方之间的关系是对等的,子公司有权保留或者可以私下保留自己的数据,仅仅共享与自己利益无损害的数据,总公司也能够接受这种状态。当前亟需一种权限对等的架构,来满足这种集团级企业应用的数据运算和存储需要。
技术实现要素:
本发明提供一种对等式数据运算与存储架构构建方法,各个拓扑节点拥有完全自主的控制权限,适用于满足集团级企业在数据运算和存储方面的需求。
为了达到上述目的,本发明的一个技术方案是提供一种对等式数据运算与存储架构构建方法:
多个数据湖服务器节点构成权限对等的拓扑结构;
其中,每一个数据湖服务器作为一个节点,采用分布式运算和存储架构,支持对关系型数据库数据、文档型数据库数据、文件型数据以及图数据之中的任意一种或其任意组合进行存储和管理;
节点内部用户之间,或者各个节点的用户之间进行点对点的安全通信,且通信时各节点的用户之间拥有对等的权限。
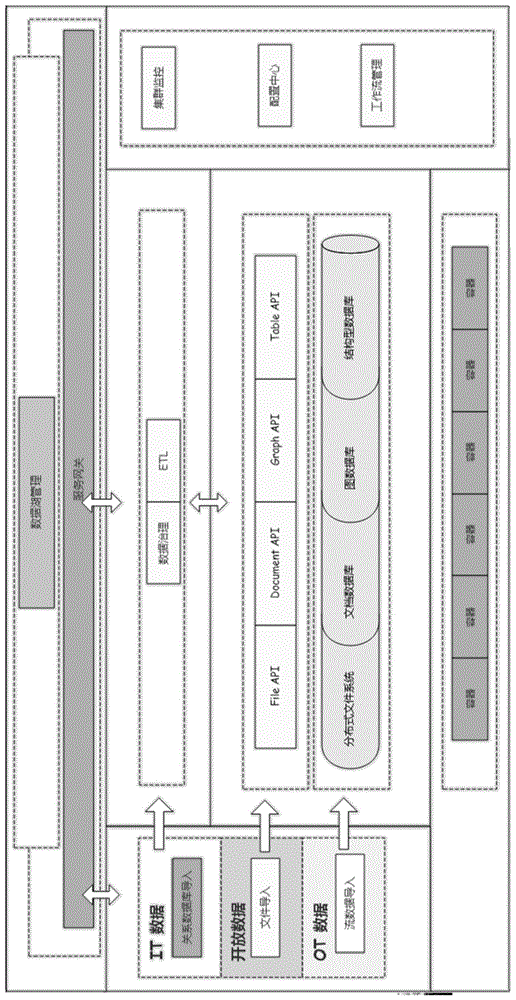
可选地,所述数据湖服务器,是包含关系型数据库、文档型数据库、分布式文件系统以及图数据库的一种数据存储和管理服务平台,这个平台采用分布式运算和存储架构,集成了具有数据存储以及运算功能的各类计算机单机、服务器以及计算机集群或者服务器集群,并提供包括数据管理、数据存储、算法开发的各类功能组件。
可选地,所述“各节点的用户之间拥有对等的权限”,是指:
每个节点对自己节点的数据和运算资源,拥有完全自主的管理权限;
每个节点的用户向其他节点的用户发送请求并获得授权后,被允许访问其他节点用户拥有的数据资源,或者使用其他节点的运算资源;
每个节点的用户有权同意或者拒绝其他节点用户发出的任何操作请求。
可选地,每个节点拥有与之对应的一个或多个用户,当前节点支持每个用户对自己导入的数据进行无权限限制的任意操作,和/或对于当前节点的其他用户或其他节点的用户所分享的数据执行与权限相符的处理。
可选地,任意两个用户之间的每次通信,是通过网络专线或者公开网络进行的一对一连接;所述的任意两个用户属于同一个节点或者属于不同的节点;用户身份有安全验证,且用户之间的数据通信内容有安全加密保障。
可选地,任意多个用户组成一个用户组;所述的任意多个用户,属于同一个节点或属于不同的节点;用户组内任意两个用户之间的每次通信,是通过网络专线或者公开网络进行的一对一连接。
可选地,用户身份由当前节点的管理员建立,或者由拓扑结构内与当前节点有通信连接的其他节点的管理员建立;
各个节点的管理员,具有以下的权限:对当前节点的用户和用户组、和/或与之通信连接的其他节点的用户和用户组,进行创建、删除、查看、修改、权限设置;
组管理员,具有以下权限:对用户组进行创建、删除、信息修改,对组信息、组内用户数及组内用户权限进行统计,以及向组内或组外各节点的管理员或数据所有者申请访问数据或使用运算资源的权限。
可选地,所述拓扑结构包含网状拓扑、或树状拓扑、或星型拓扑。
可选地,所述的分布式运算和存储架构,是指:通过使用paas云计算平台提供计算资源的分配,将业务容器分配到集群中各个节点,提供分布式计算资源。
可选地,所述数据存储和管理服务平台通过日志文件和元数据文件,对数据文件及其存储、交换进行组织管理;
其中,所述日志文件包含的日志记录数据,以键值对的形式存在,包含对应以下内容的字段:
当前操作的操作者名称;
当前操作的类型;
当前操作的内容,即操作动作的执行对象;其中,当操作类型是修改、或创建、或追加时,是指保存对应数据源的位置;当操作类型是查询时,是指保存对应的查询语句;
当前操作的日期时间;
当前操作的状态,用来判断当前操作是否成功;
当前操作的数据类型;
其中,所述元数据文件包含的文件元数据,以键值对的形式存在,其包含对应以下内容的字段:
正在处理的数据的名称;
对当前数据的描述;
当前数据所属的用户;
当前数据所属的组;
存储的目的地,其与数据库类型相匹配;
数据生成的资源描述框架;
元数据创建时间;
元数据更新时间。
本发明的另一个技术方案是提供一种对等式数据运算与存储架构的应用方法,使用上述任意一种对等式数据运算与存储架构,针对类似于集团企业管理架构的组织机构,进行数据管理、处理及存储;
集团内的总公司及各个子公司、供应商、客户,各自作为权限对等的拓扑结构内的一个节点,构建与之对应的数据湖服务器,来收集内部数据;
称任意一个节点为本地节点;所述本地节点通过与其他节点建立信息连接,收集其他节点向该本地节点分享的数据,并在提取数据字段、整合数据、清洗数据之后,保存到本地节点。
可选地,所述本地节点发出请求并在其他节点允许后,将其他节点添加到该本地节点的用户组;
所述本地节点对来自其他节点的整合数据进行分析,并将分析结果以文件的形式对其他节点发布;和/或,其他节点向该本地节点请求获取分析结果。
本发明构建了权限对等的多节点扩展与通信的架构,对等拓扑中的每一个节点,就是一个数据湖服务器,该数据湖服务器是一种综合了典型的4种常见数据/文档类型存储形态,集中接受外部三种数据源的混合数据的存储服务器架构。
本发明的各个拓扑节点拥有完全自主的控制权限,可以将其用来解决子公司与总公司在数据分享过程中的利益博弈,达成双方都能够接受的方案。
附图说明
图1是本发明的数据湖服务器架构示意图;
图2、图3、图4是本发明中服务器群节点拓扑典型结构,分别是网状、树状、星型的拓扑架构示意图;
图5是本发明的实施例中节点与数据流向的示意图。
具体实施方式
配合参见图1与图2-图4所示,本发明提供一种用于数据存储、运算以及分享的数据湖服务器群架构,其群架构可以由任意多个数据湖服务器节点构成,根据数据湖服务器使用者组织架构的不同,每一台数据湖服务器作为一个节点,与其他同类型数据湖服务器节点构成权限对等的网状拓扑(图2),或者构成其他权限类型的拓扑,比如树状拓扑结构(图3)或者星型拓扑结构(图4)。
每一台数据湖服务器作为拓扑中的一个节点,采用分布式运算和存储架构,支持关系型数据库数据、文档型数据库数据、文件型数据以及图数据的存储和管理,从而解决待保存数据的多元异构问题,使各类数据都可以在数据湖中保存。所述的“分布式运算和存储架构”,是指:通过使用paas云计算平台提供计算资源的分配,将业务容器分配到集群中各个节点,提供分布式计算资源。
节点内部用户之间,或者各个节点上的用户之间可以进行点对点的安全通信,通信时各节点的用户之间拥有对等的权限。所述“拥有对等的权限”是指:首先,各个数据湖服务器节点对自己节点的数据和运算资源,拥有完全的管理权限,也就是说,每个节点在管理自己的资源时,拥有完全自主的管理权限,并不需要经过其他任何节点的许可或者授权;其次,每个节点的用户要访问其他节点用户拥有的数据资源,或者使用其他节点的运算资源,需要向该节点用户发送请求并获得该用户的授权;同时,每个节点用户也有权同意或者拒绝其他节点用户发出的任何操作请求。
所述“进行点对点的安全通信”,是指:来自一个或多个服务器数据湖节点的任意两个用户可以通过网络专线或者公开网络相互连接;来自一个或多个服务器数据湖节点的任意多个用户可以组成一个用户组;任意两个用户之间,或者用户组内各个用户之间的每次通信都是一对一的连接;并且,用户身份是有安全验证的,采用包括面部识别、指纹识别、静脉图像识别、虹膜识别、声纹识别等等方法;用户之间的数据通信内容是有安全加密保障的,至少采用https协议以及其他安全措施。
数据湖服务器节点的管理员负责设置、管理用户,用户可以处理自己导入的数据或者被分享的数据。用户身份可以是由本地节点的管理员建立的;或者,用户身份也可以是由拓扑内与当前节点有通信连接的其他数据湖服务器节点建立的。
数据湖服务器的管理员有以下权限:可以创建和删除用户和组,可以查看所有的用户和组,可以修改用户和组的信息,比如重置密码、设置标签,可以查看用户信息以及登录日期时间、用户的ip地址、登录平台的浏览器、系统、版本等信息等;进一步,组管理员可以修改组信息,删除组,创建组,可以统计组信息、人数和权限,可以向数据湖服务器管理员申请权限。
所述的“用户可以处理自己导入的或者被分享的数据”,是指:用户可以对自己导入的数据做各种无权限限制的操作,进一步,也可以访问其他用户分享给自己的数据,具体操作权限取决于数据分享者对该分享的权限设置;数据所有者和数据管理员对该资源拥有完整的权限,被分享的接收者只能看或者复刻,复刻也可以被拥有者关闭。所谓复刻,是指一个用户a的应用或者数据可以被另一个用户b复制一份以方便使用或者修改;同时,用户a对这个应用或者数据的修改会通知用户b,由用户b决定是否将用户a的这个修改应用到自己之前复制的应用或者数据中。
本发明所述的“数据湖服务器”,是由关系型数据库(如mariadb、mysql等),文档型数据库(如mongodb、couchdb等),分布式文件系统(如hdfs、pvfs、panfs等),以及图数据库(如neo4j、cayley、grapgdb等)这四类数据库构成的一种数据存储和管理服务平台,这个平台采用分布式运算和存储架构,集成了具有数据存储以及运算功能的各类计算机单机、服务器以及计算机集群或者服务器集群,并提供包括数据管理、数据存储、算法开发的各类功能组件。图1示出了数据湖架构及其具体功能,其中“it数据”是指既有数据;“开放数据”例如是来自各种网络的数据;“ot数据”是指生成过程中的数据;以上三种数据均是指数据的来源,不属于数据湖本身。
整个数据湖的数据交换管理是基于保存在文档型数据库mongodb中的日志记录和文件元数据:
(a)日志记录数据以键值对的形式存在,其字段名称和内容是:
字段"user":保存当前操作的操作者名称;
字段"operation_type":保存当前操作的类型,比如创建,修改,追加等;
字段"operation_record":用来保存当前操作的内容即操作动作的执行对象。当操作类型是修改、创建、追加时,保存对应数据源的位置;当操作类型是查询时,保存对应的查询语句;
字段"operation_time":保存当前操作的日期时间,比如:"2018-06-28t03:18:58.91;
字段"operation_statue":保存当前操作的状态,是辅助字段,用来判断当前操作是否成功;
字段"operation_source":保存当前操作的数据类型,比如:"hdfs"表示文件型数据。
(b)文件元数据以键值对的形式存在,其字段名称和内容主要是:
数据名称:正在处理的数据的名称
描述:对当前数据的描述
所属者:当前数据所属的用户
所属组:当前数据所属的组
存储后端:存储的目的地,指某种数据库类型
辅助标签:数据生成的rdf
元数据创建时间:元数据的创建时间
元数据更新时间:元数据的更新时间。
上述的rdf,是“资源描述框架”的英文简称,其本质是一个数据模型(datamodel),它提供了统一的标准,用于描述实体和资源。简单来说,就是表示事物的一种方法和手段,其形式上表示为“主语-谓语-宾语”三元组。如在图数据库中,rdf由节点和边组成,节点表示实体/资源、属性,边则表示了实体和实体之间的关系以及实体和属性的关系。
上述的“存储后端”字段,又根据数据类型(文件类型,文档类型,表格类型,图类型)的不同,包含不同的字段。
对于文件类型的数据,有以下字段:文件物理路径,文件物理名称,hdfs占用空间大小,真实文件所有者,真实文件所属组,前端显示文件路径,前端显示文件名称,文件扩展名,文件的mine类型,文件真实大小,停词表(用于rdf处理)。
对于文档类型的数据(json型数据),有以下字段:物理数据库位置,物理集合名称,显示数据库名称,显示集合名称,文档结构(json数据结构),停词表(用于rdf处理)。
对于表格类型的数据(比如来mysql的数据),有以下字段:物理数据库名称,物理表名称,显示数据库名称,显示表名称,列名表,停词表(用于rdf处理)。
对于图形类型的数据(比如来neo4j的数据),有以下字段:neo4jid,前端显示名称,停词表(用于rdf处理)。
通过上述的日志文件和元数据文件,数据管理服务平台可以高效、安全地组织管理数据文件、加快数据存储的速度。
所述的“关系型数据库数据、文档型数据库数据、文件型数据以及图数据”中,“关系型数据库数据”是指:在数据结构上具有规整结构的传统类型的数据库数据,比如来自oracle,mysql,sqlserver等传统关系型数据库的数据;“文档型数据库数据”是指:与传统关系型数据库不同,可以保存到文档数据库;“文件型数据”,是指:以文件格式保存的数据,比如pdf文件、图片文件以及其他各类工程设计文件等等;图数据是指基于图数据库,比如neo4j,graphdb等的数据信息。
本发明采用的权限对等的架构,能够满足集团级企业应用的数据管理、处理及存储需求。当然,其实用性具体体现于基于架构之上的具体数据转移权限以及实施细节。
以下基于一个具体的实施例,来详细说明本发明的特点:
如图5所示,某集团公司a有三家下属子公司a1、a2、a3以及两家供应商s1、s2和三家客户c1、c2、c3,现在拟建立了对等式的数据运算与存储架构,用于促进企业内外的信息流动,进而提升企业效益。
首先,以每一家单位为一个数据湖服务器节点,在这些单位内部构建数据湖服务器,收集企业内部数据。在总体上,这些单位之间构成网状拓扑结构,每个节点内有多个用户身份,节点内每一个用户都可以在节点管理员许可的前提下与其他节点的用户建立连接。为简化起见,在本实施例中假设每个节点仅有一个可以与外部节点连接交互的用户身份——虽然实际上每个节点的管理员可以添加多个具有不同权限的用户。
假设,集团公司用户a(我们以公司名称代替用户名称,以下同)对子公司a1、a2、a3以及供应商s1、s2和客户c1有收集数据、分析数据的需求,因此,与a1、a2、a3、s1、s2、c1建立节点连接,发出请求。经a1、a2、a3、s1、s2、c1允许,各自将a添加到本节点用户组,并分享a需要的数据。这时,a可以针对收集来自a1、a2、a3、s1、s2、c1的数据,经提取数据字段、整合数据、清洗数据之后,保存到本地节点。进一步,可以对来自多个节点的整合数据做分析,辅助业务发展;进一步地,可以将分析结果以文件的形式对相关节点a1、a2、a3、s1、s2、c1、c2、c3发布;进一步,节点a1、s2、c1、c2、c3可以根据自身的需要,向a请求分析结果;a以小组的方式,添加a1、s2、c1、c2为小组成员,从而将自己的分析结果文件分享给组内成员;由于未添加c3,因此视作拒绝了c3的请求。此次操作的数据流及其拓扑结构如下图5所示,图中节点间的连线表示存在数据的流向。
尽管本发明的内容已经通过上述优选实施例作了详细介绍,但应当认识到上述的描述不应被认为是对本发明的限制。在本领域技术人员阅读了上述内容后,对于本发明的多种修改和替代都将是显而易见的。因此,本发明的保护范围应由所附的权利要求来限定。
- 还没有人留言评论。精彩留言会获得点赞!