一种结合同义词词典和词嵌入向量的问句相似度计算方法与流程
本发明涉及金融领域服务机器人的自动问答,特别是涉及一种结合同义词词典和词嵌入向量的问句相似度计算方法。
背景技术:
随着人工智能技术在金融自助领域的应用不断加深,越来越多的银行使用基于语音交互技术的机器人来辅助工作人员进行业务的咨询、办理。语音交互技术主要是对用户语音进行识别,转换成相应文字,然后在此基础上对文字的语义进行分析,通过搜索银行内部问题库,提取与用户问题最接近问题的答案。最后,将答案通过语音合成技术(tts)转换为语音信号,发给机器人并通过扬声器发声。
这其中,对用户问题的理解,一般表现为用户所提问题与银行内部数据库中预制问题的匹配,是当前技术的一个难点。该问题的难度主要体现在:(1)用户对同一个问题往往有不同的表达方式(句法结构不同)。(2)用户对同一事物采用不同的词语进行表达(同义词替换)。(3)口语一般采用缩略语,如使用“卡”来代替“银行卡”。对于第一种情况,往往使用预制多个问句模板来解决,即定义一个问题的多种句式,分别进行匹配;对于后两种情况,一般通过计算同义词之间的相似度来解决。
对于同义词相似度的计算,存在两种方法,一种是传统的基于查字典的方法,典型的就是使用哈工大的“同义词词林”。该方法通过搜索“同义词词林”中的对应词语所处的位置来计算词语之间的相似度。其缺点是:“同义词词林”为人工编纂,所涉及的词语大多为日常生活中涉及到的词,对于银行领域的专业词,或者生僻词往往存在缺失。此外,由于人工词典编写的滞后性,一些流行词也存在缺失。
第二种方法是基于词嵌入向量的方法。该方法首先在互联网上爬取特定领域的相关文字资料,形成语料库,然后借助word2vec、glove、fasttext等词向量计算工具,自动生成每个词语的词向量,最后通过计算词语对应词向量的余弦距离得出词语的语义相似度。该方法的优点是:只要语料库足够大,几乎可以计算所有词语之间的相似度,有效避免了人工编写词典词汇缺失的问题。该方法的缺点是:由于词向量是算法自动生成,因此该方法估计出的词语相似度不如人工词典方法准确。
技术实现要素:
针对上述存在的技术问题,本发明的目的是:本发明提出了一种结合同义词词典和词嵌入向量的问句相似度计算方法,该方法首先利用同义词词典方法和词向量方法分别计算词语之间的相似度,然后对两种方法计算的结果进行融合。
本发明的技术解决方案是这样实现的:一种结合同义词词典和词嵌入向量的问句相似度计算方法,包括句子级别的相似度融合方法和词语级别的相似度融合方法;
(一)句子级别的相似度融合方法:
待计算相似度的两个问句分别为s1、s2,对其进行分词处理,可得
第一步,计算问句之间的词典相似度simdict(s1,s2),对于问句s1、s2中的任意词语对
第二步,计算问句之间的词向量相似度,首先使用词向量计算工具计算语料库中所含词语的词向量,对得出的词向量进行归一化处理,然后对问句s1、s2中的每一个词语对
第三步,融合上述两个相似度,将上述计算结果进行加权平均,计算公式如下:sim(s1,s2)=ω1simdict(s1,s2)+ω2simvec(s1,s2),其中ω1、ω2为权重系数;
(二)词语级别的相似度融合方法:
其计算步骤如下:第一步,计算问句s1、s2中每个词语
第二步,计算问句s1、s2中每个词语
第三步,针对mdict和mvec的每一个元素,生成融合后的相似性矩阵mf,计算公式为:
第四步,取mf每一行的最大值和每一列的最大值相加,然后取平均,得到问句s1、s2的相似度sim(s1,s2);
将句子级别的相似度融合方法和词语级别的相似度融合方法进行结合计算,步骤如下,步骤1,使用切词工具对要进行相似度计算的问句s1、s2进行分词,得到s1对应的词语集合
步骤2,计算问句s1、s2中每个词语之间词典相似度
在相似度的计算步骤如下所示:
第一步,获取词语
第二步,计算词林距离n,定义为:n=5-h,即词林的最大层次减去深度h,此时,词语对
针对词汇缺失的情况,采用句子级别的融合方法,则将
第三步,按照上述计算结果,将相似度按行、列排列,形成m行n列的相似性矩阵mdict,形式如下:
第四步,取mdict每一行的最大值mdict_max(i)和每一列的最大值mdict_max(j),累加取平均得到问句s1、s2的相似度,计算公式为:
采用词语级别的融合方法,忽略第四步,直接转步骤s3;
步骤s3,计算问句s1、s2中每个词语之间词向量相似度
第一步,利用python语言编写网络爬虫,爬取百度百科、wiki百科中文版、新浪、搜狐相关网站的相关文字信息,形成训练语料;
第二步,利用词嵌入计算工具计算训练语料中出现词汇的词向量;
第三步,采用句子级别的融合方法,则问句s1、s2的词向量相似度可按如下公式计算:
第四步,计算问句s1、s2中每个词语
步骤s4,采用句子级别的融合方法,利用公式sim(s1,s2)=ω1simdict(s1,s2)+ω2simvec(s1,s2)计算得到问句s1、s2的融合相似度sim(s1,s2),算法结束;采用词语级别的融合方法,转步骤s5。
步骤s5,计算词汇级别的问句相似度。
第一步,根据上述步骤获得的词典相似性矩阵mdict和词向量相似性矩阵mvec,利用公式
第二步,取mf每一行的最大值mf_max(i)和每一列的最大值mf_max(j),累加取平均得到问句s1、s2的相似度。计算公式为:
由于上述技术方案的运用,本发明与现有技术相比具有下列优点:
本发明的一种结合同义词词典和词嵌入向量的问句相似度计算方法,(1)相对于单纯使用词向量的方法,该方法充分利用了人工编写的同义词词典,保证了词语相似度计算的准确性。
(2)对于词典缺失的流行词和专业词汇,该方法使用词向量方法计算相似度,有效的避免了单一使用词典方法,在词汇缺失的情况下相似度无法计算的问题。
(3)该方法融合了同义词词典和词向量两种相似度计算方法,考虑的因素更多,结果更加准确。
附图说明
下面结合附图对本发明技术方案作进一步说明:
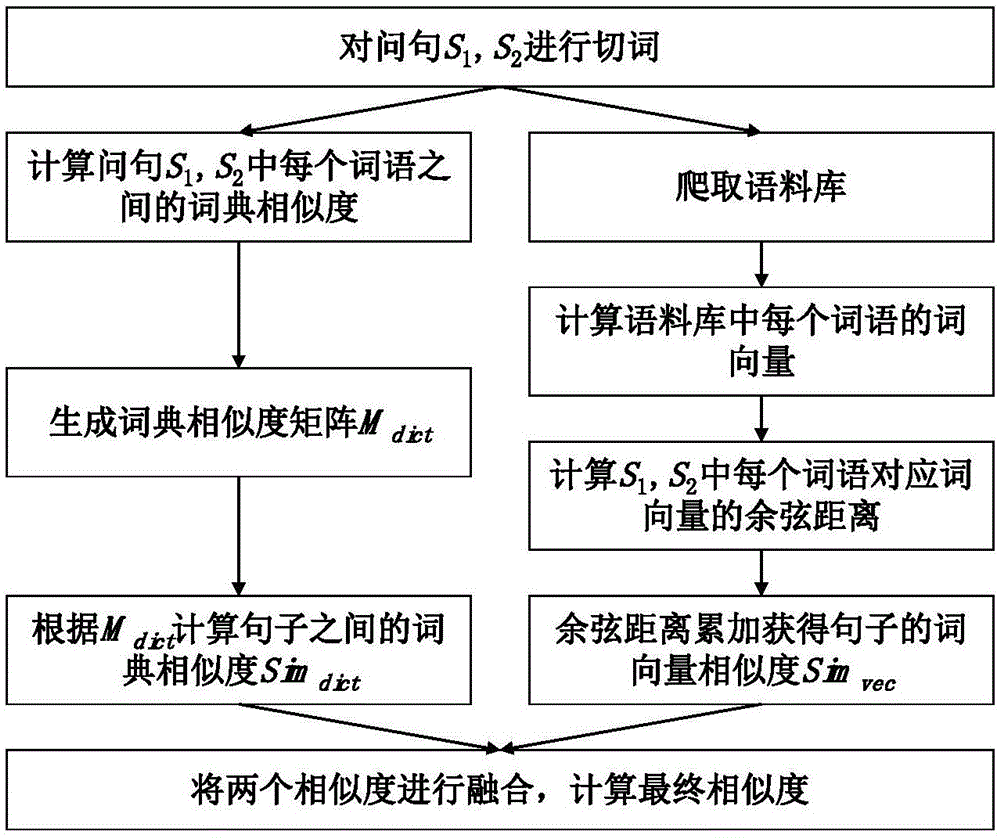
附图1为本发明的句子级别的相似度融合方法流程图;
附图2为本发明的词语级别的相似度融合方法流程图。
具体实施方式
下面结合附图来说明本发明。
如附图1、2所示为本发明所述的一种结合同义词词典和词嵌入向量的问句相似度计算方法,其特征在于:包括句子级别的相似度融合方法和词语级别的相似度融合方法;
(一)句子级别的相似度融合方法:
待计算相似度的两个问句分别为s1、s2,对其进行分词处理,可得
第一步,计算问句之间的词典相似度simdict(s1,s2),对于问句s1、s2中的任意词语对
第二步,计算问句之间的词向量相似度,首先使用词向量计算工具计算语料库中所含词语的词向量,对得出的词向量进行归一化处理,然后对问句s1、s2中的每一个词语对
第三步,融合上述两个相似度,将上述计算结果进行加权平均,计算公式如下:sim(s1,s2)=ω1simdict(s1,s2)+ω2simvec(s1,s2),其中ω1、ω2为权重系数;
(二)词语级别的相似度融合方法:
其计算步骤如下:第一步,计算问句s1、s2中每个词语
第二步,计算问句s1、s2中每个词语
第三步,针对mdict和mvec的每一个元素,生成融合后的相似性矩阵mf,计算公式为:
第四步,取mf每一行的最大值和每一列的最大值相加,然后取平均,得到问句s1、s2的相似度sim(s1,s2);
将句子级别的相似度融合方法和词语级别的相似度融合方法进行结合计算,步骤如下,步骤1,使用切词工具对要进行相似度计算的问句s1、s2进行分词,得到s1对应的词语集合
步骤2,计算问句s1、s2中每个词语之间词典相似度
在相似度的计算步骤如下所示:
第一步,获取词语
第二步,计算词林距离n,定义为:n=5-h,即词林的最大层次减去深度h,此时,词语对
针对词汇缺失的情况,采用句子级别的融合方法,则将
第三步,按照上述计算结果,将相似度按行、列排列,形成m行n列的相似性矩阵mdict,形式如下:
第四步,取mdict每一行的最大值mdict_max(i)和每一列的最大值mdict_max(j),累加取平均得到问句s1、s2的相似度,计算公式为:
采用词语级别的融合方法,忽略第四步,直接转步骤s3;
步骤s3,计算问句s1、s2中每个词语之间词向量相似度
第一步,利用python语言编写网络爬虫,爬取百度百科、wiki百科中文版、新浪、搜狐相关网站的相关文字信息,形成训练语料;
第二步,利用词嵌入计算工具计算训练语料中出现词汇的词向量;
第三步,采用句子级别的融合方法,则问句s1、s2的词向量相似度可按如下公式计算:
第四步,计算问句s1、s2中每个词语
步骤s4,采用句子级别的融合方法,利用公式sim(s1,s2)=ω1simdict(s1,s2)+ω2simvec(s1,s2)计算得到问句s1、s2的融合相似度sim(s1,s2),算法结束;采用词语级别的融合方法,转步骤s5。
步骤s5,计算词汇级别的问句相似度。
第一步,根据上述步骤获得的词典相似性矩阵mdict和词向量相似性矩阵mvec,利用公式
第二步,取mf每一行的最大值mf_max(i)和每一列的最大值mf_max(j),累加取平均得到问句s1、s2的相似度。计算公式为:
本发明的一种结合同义词词典和词嵌入向量的问句相似度计算方法,(1)相对于单纯使用词向量的方法,该方法充分利用了人工编写的同义词词典,保证了词语相似度计算的准确性。
(2)对于词典缺失的流行词和专业词汇,该方法使用词向量方法计算相似度,有效的避免了单一使用词典方法,在词汇缺失的情况下相似度无法计算的问题。
(3)该方法融合了同义词词典和词向量两种相似度计算方法,考虑的因素更多,结果更加准确。
上述实施例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人士能够了解本发明的内容并加以实施,并不能以此限制本发明的保护范围,凡根据本发明精神实质所作的等效变化或修饰,都应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!