基于机器学习与大数据分析的电容器故障预测方法与流程
本发明设计电力设备故障分析领域,尤其涉及一种基于机器学习与大数据分析的电容器故障预测方法。
背景技术:
电容器组在电力系统中是最常用的改善功率因数的方法。电容器组的运行经济且可靠,故障率低。安装电容器可以补偿无功功率,满足感性负载的需求,从而提高电气系统的功率因数。但是电力系统的运行状况可能会影响电容器的正常运行,并造成电容器的故障。
常规的电容器故障的预测方法有如下三种:1.通过监测电容器内部的局部放电,来判断放电的严重程度,从而分析并预测绝缘劣化的状况和其发展趋势;2.通过电容器的极间绝缘检测技术,对电容器做耐压实验,但这种方法是一种离线实验,不能及时有效的发现电容器运行时的状态变化,具有很大的局限性;3.监测电容器内部的温度变化,考察电容器在不同工作状况下的温度变化,建立电容器工况和温度变化的模型,从而能够预测电容器的故障发生;上述几种方式没有对电容器故障的历史数据进行充分的利用,也没有对影响电容器故障的参数进行综合的考虑,这几个参数包括电力电容器故障的地理信息,设备厂商,运行状况,故障原因,寿命以及检测方法等,因此,现有技术无法准确的对电容器的故障进行准确预测。
技术实现要素:
有鉴于此,本发明的目的是提供一种基于机器学习与大数据分析的电容器故障预测方法,能够对电容器的故障进行准确预测,从而利于电力系统的稳定运行。
本发明提供的一种基于机器学习与大数据分析的电容器故障预测方法,包括如下步骤:
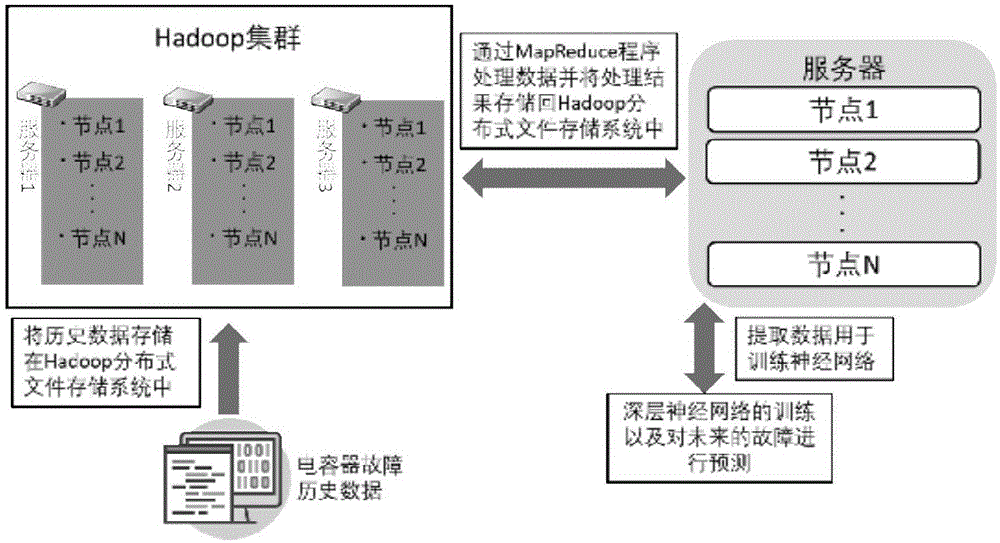
s1.获取电容器的历史数据,并通过hadoop集群算法将电容器的历史数据存储在分布式服务器中;
s2.对电容器的历史数据进行预处理,然后将预处理后的电容器的历史数据进行特征量提取;
s3.对提取的特征量进行归一化处理;
s4.将归一化处理后的特征量输入到深层神经网络中进行指导性训练,并对电容器故障进行预测。
进一步,步骤s2中,对电容器的历史数据进行预处理如下:
s21.hadoop框架中的mapper首先将输入数据分解为具有相同数据大小的n个块,然后将其分别储存在hadoop集群中;
s22.hadoop集群的主节点将寻找m个空闲工作节点并将n个数据块的工作任务分配给他们,当mapper的分类任务完成后,会产生中间输出结果;
s23.执行mapper任务的工作节点解析数据块并发送给用户定义的mapper函数每对(key,value)作为输入,mapper函数处理后的中间输出结果也以(key,value)对的形式,并由执行它们的工作节点提供内存空间进行存储,mapper工作任务完成;
s24.主服务器寻找相应数量的空闲节点作为reducer,并向它们通知上述mapper任务完成后的存储位置,reducer将远程调用并读取mapper工作节点所存储的数据,读取所有中间输出结果数据后,reducer节点对数据进行格式化、排序和分组操作,并对中间输出结果数据进行分类;其中,分类数据依据包括故障类型、故障时间、故障地点或者故障发生时的工作环境。
进一步,步骤s3中,通过如下算法对特征量进行归一化处理:
vnor=vvalue·nf
nf=vmax/f;
其中,vnor是归一化的结果,vvalue是需要归一化处理的数值,nf为归一化因子,vmax为分类数据中的最大值,f为归一化常数。
进一步,步骤s4中通过深层神经网络进行故障预测,包括以下步骤:
s41.将分布式文件系统中的归一化数据分成两个子集,并提取出来进行人工神经网络的指导性训练,第一个子集包含了90%的数据量。该子集被当作已知数据,用来训练人工神经网络,第二个子集包含了10%的数据量。该子集被当作未知数据,用来校验人工神经网络的误差;
s42.设置目标误差;
s43.初始化并对深层神经网络进行训练;
s44.将每一次的误差加入到总误差中,并评估总误差的大小;
s45.结束训练后判断总误差是否小于目标误差,若不小于,则返回步骤s41,重新设置目标误差;若小于,结束训练。
本发明的有益效果:通过本发明能够实现如下有益效果:
对电容器故障的历史数据进行充分的利用,也对影响电容器故障的参数进行了综合考虑,这几个参数包括电力电容器故障的地理信息,设备厂商,运行状况,故障原因,寿命以及检测方法等;
对海量数据中的冗余信息,数据格式和结构不统一等问题进行处理,有效的解决了原始数据的复杂性问题;
将处理后的数据以分布式的方式存储在hadoop集群内的分布式文件系统中,采用分布式算法进行数据处理,大大提升了数据处理的速度和准确度;
采用深层神经网络对电容器故障进行预测,综合考虑了影响电容器故障的各种参数,大大提升了故障预测的准确性。
附图说明
下面结合附图和实施例对本发明作进一步描述:
图1为本发明所述基于机器学习与大数据分析的电容器故障预测方法的框图;
图2为本发明所述mapreduce的算法流程图;
图3位本发明所述深层神经网络进行故障预测的方法流程图。
具体实施方式
以下结合说明书附图对本发明做出进一步的详细说明,如图所示:
本发明提供的一种基于机器学习与大数据分析的电容器故障预测方法,包括如下步骤:
s1.获取电容器的历史数据,并通过hadoop集群算法将电容器的历史数据存储在分布式服务器中;
s2.对电容器的历史数据进行预处理,然后将预处理后的电容器的历史数据进行特征量提取;
s3.对提取的特征量进行归一化处理;
s4.将归一化处理后的特征量输入到深层神经网络中进行指导性训练,并对电容器故障进行预测,通过上述方法能够实现如下有益效果:
对电容器故障的历史数据进行充分的利用,也对影响电容器故障的参数进行了综合考虑,这几个参数包括电力电容器故障的地理信息,设备厂商,运行状况,故障原因,寿命以及检测方法等;
对海量数据中的冗余信息,数据格式和结构不统一等问题进行处理,有效的解决了原始数据的复杂性问题;
将处理后的数据以分布式的方式存储在hadoop集群内的分布式文件系统中,采用分布式算法进行数据处理,大大提升了数据处理的速度和准确度;
采用深层神经网络对电容器故障进行预测,综合考虑了影响电容器故障的各种参数,大大提升了故障预测的准确性。
本实施例中,步骤s2中,通过低级机器语言mapreduce从分布式存储在hadoop集群分布式文件系统中的原始数据提取需要的特征量,首先通过mapper将原始数据在hadoop集群中归类,然后通过reducer将归类后的数据聚合并格式化以及分类,具体过程如下:
s21.hadoop框架中的mapper首先将输入数据分解为具有相同数据大小的n个块,然后将其分别储存在hadoop集群中;
s22.hadoop集群的主节点将寻找m个空闲工作节点并将n个数据块的工作任务分配给他们,当mapper的分类任务完成后,会产生中间输出结果;
s23.执行mapper任务的工作节点解析数据块并发送给用户定义的mapper函数每对(key,value)作为输入,mapper函数处理后的中间输出结果也以(key,value)对的形式,并由执行它们的工作节点提供内存空间进行存储,mapper工作任务完成;
s24.主服务器寻找相应数量的空闲节点作为reducer,并向它们通知上述mapper任务完成后的存储位置,reducer将远程调用并读取mapper工作节点所存储的数据,读取所有中间输出结果数据后,reducer节点对数据进行格式化、排序和分组操作,并对中间输出结果数据进行分类;其中,分类数据依据包括故障类型、故障时间、故障地点或者故障发生时的工作环境。
本实施例中,步骤s3中,通过如下算法对特征量进行归一化处理:
vnor=vvalue·nf
nf=vmax/f;
其中,vnor是归一化的结果,vvalue是需要归一化处理的数值,nf为归一化因子,vmax为分类数据中的最大值,f为归一化常数,通过上述方法对特征量进行归一化处理,从而能够确保深层神经网络进行学习、预测的稳定性和准确性。
本实施例中,步骤s4中通过深层神经网络进行故障预测,包括以下步骤:
s41.将分布式文件系统中的归一化数据分成两个子集,并提取出来进行人工神经网络的指导性训练,第一个子集包含了90%的数据量。该子集被当作已知数据,用来训练人工神经网络,第二个子集包含了10%的数据量。该子集被当作未知数据,用来校验人工神经网络的误差;
s42.设置目标误差;
s43.初始化并对深层神经网络进行训练;
s44.将每一次的误差加入到总误差中,并评估总误差的大小;
s45.结束训练后判断总误差是否小于目标误差,若不小于,则返回步骤s41,重新设置目标误差;若小于,结束训练。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!