一种基于注意力卷积神经网络的用户评论情感分析系统及方法与流程
本发明涉及一种互联网用户评论情感分析方法,主要结合词嵌入技术和卷积神经网络来进行用户评论的特征学习,并结合注意力机制来提高情感分类的准确率,属于自然语言处理和人工智能交叉领域。
背景技术:
近年来,越来越多的用户习惯在网络上发自己对某一事物的看法与评论。如何快速、准确地从互联网海量评论信息中分析所包含的用户情感已经成为当前信息科学与技术领域研究的热点。用户评论情感分析中最基本的任务是对用户的情感倾向进行分类,其中包括二元情感分类和多元情感分类。由于在互联网上可以获得大量的评论数据用于训练模型,基于机器学习的情感分析方法逐渐成为主流,并取得了较好的效果。然而,基于传统机器学习的情感分类方法提取的特征仅考虑文本中单词出现的频次,而忽略了语法结构和单词顺序,这使得评论中的语意和结构信息丢失,影响情感分类的准确率。此外,传统的机器学习方法依赖人工设计的特征,耗时费力。
由于互联网上数据的快速增长和计算机性能的提升,使基于神经网络的深度学习成为可能。深度学习最早用于计算机视觉与语言识别领域,通过训练神经网络模型来从输入数据中提取更好的特征表达来完成图像分类,语音识别等任务。由于深度学习模型在图像和语言识别领域显示出卓越的性能,也逐渐应用于自然语言处理(naturallanguageprocessing,nlp)领域,并取得了良好的效果。在nlp领域,深度学习方法首先将文本转化为一组向量序列表示,然后将该向量序列输入神经网络模型提取特征,最后将特征输入分类器进行情感分类。基于卷积神经网络的特征提取方法使用一个滑动窗口来提取输入的局部特征,并通过池化(pooling)技术将这些局部特征组合起来;而基于循环神经网络的特征提取方法将输入编码为一个定长的特征。这两种特征提取方法没有考虑到用户评论中不同部分对评论的最终情感的贡献程度不同,虽然对单个句或短语效果较好,但在面对较长的用户评论时会降低情感分析的准确性。
技术实现要素:
本发明为了克服传统神经网络模型特征提取方法的不足,将注意力机制加入到神经网络模型中。通过大量数据训练后,注意力机制可以判断评论中不同词语的重要程度,使得模型可以“注意到”评论中对情感影响最大的部分,提高模型情感分类的准确率。
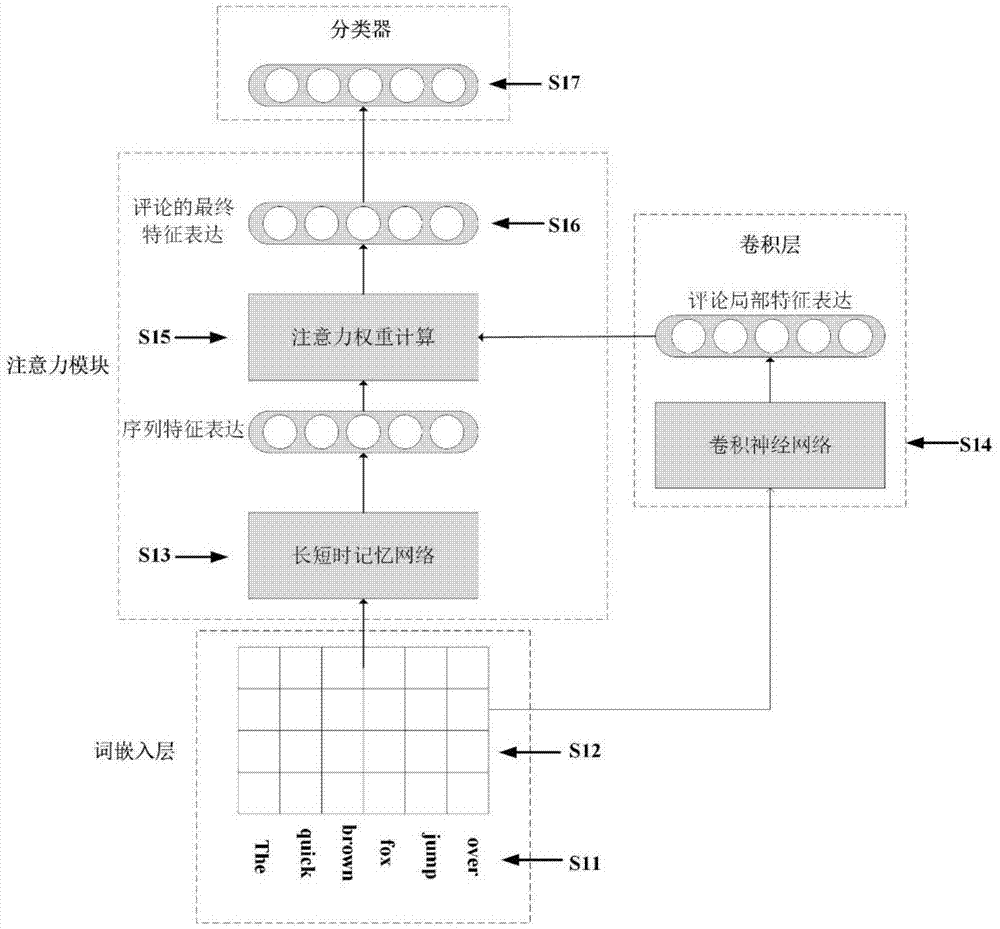
本发明中词嵌入层用于将输入的评论文本向量化,即将文字转换为向量形式。词嵌入方法将每个单词使用一个低维向量进行表示,将每条评论中所有单词的向量表示拼接起来,就能构成一条评论的向量表示形式。卷积层通过空间结构关系学习输入中的局部特征,以减少模型需要学习的参数数量。本发明使用卷积层来提取评论的局部特征,这通过将一定的窗口大小的卷积核应用在输入序列上来实现。注意力模块首先使用一个长短时记忆网络对输入的评论进行编码,然后和卷积层提取的局部特征进行相似度比较计算出注意力权重,局部特征的加权和送至分类器进行情感分类。分类器使用全连接神经网络和softmax分类器实现,整个模型使用逆向传播误差进行优化。
鉴于此,本发明采用的技术方案是:一种基于注意力卷积神经网络的用户评论情感分析系统,包括词嵌入模块、卷积模块、注意力模块以及分类器模块,其中所述词嵌入模块将评论文本使用向量表示;所述卷积模块通过卷积操作提取评论的局部特征;所述注意力模块接收卷积模块的输出,通过比较相似度来决定局部特征的权重,并通过加权计算评论的最终特征表达,并作为分类器模块的输入;分类器模块根据最终特征表达进行情感分类。所述词嵌入模块的输出同时作为卷积模块和注意力模块的输入。
进一步,所述词嵌入模块包含一个词嵌入矩阵和一个单词表,将清洗后的评论文本转换成低维向量表示,维度由用户设定,且在100到300维之间。具体地,注意力模块中包含一个长短时记忆网络,该长短时记忆网络对词嵌入模块的结果进行编码,生成与卷积模块获取的评论局部特征向量维度相同的序列特征向量。使用所述序列特征向量和评论局部特征向量的余弦相似度作为注意力权重,将注意力权重应用在局部特征向量上,获得局部特征的权重。
所述分类器模块采用全连接神经网络与softmax分类器层叠的方式构成,训练的误差使用交叉熵定义,模型的训练方法为逆向传播算法。
一种基于注意力卷积神经网络的用户评论情感分析方法,包括以下步骤:
s1:对用户评论文本数据进行数据清洗;例如包括分词,去除标点符号,字母转换为小等。
s2:把清洗后的评论数据输出词嵌入模块获得评论的向量表达;
s3:将评论的向量表达输入长短时记忆网络和卷积神经网络提取特征,分别获得序列特征向量和评论的局部特征向量;
s4:结合序列特征向量和评论的局部特征向量计算注意力权重,并在评论的局部特征向量上通过注意力权重计算加权和作为评论的最终特征表达。
s5:将评论的最终特征表达输入分类器进行分类,并根据模型的预测结果和真实数据标签计算误差,模型的误差函数代表了模型预测的值和训练数据真实值之间的差距;分类器输出对应输入的情感类型,例如正面情感或负面情感。
s6:采用梯度下降法训练模型,并在达到预定的训练轮数后停止训练;
s7:将待情感分类的新数据输入训练好的模型,进行情感分析预测。
本发明的有益技术效果如下:
本发明提供了一种结合了注意力机制的卷积神经网络模型来分析用户评论情感,由于结合了注意力机制,该模型能够通过学习数据中的特征来判断输入中不同词语对评论情感倾向的贡献程度,从而克服了传统神经网络网络模型的缺陷,提升了情感分类的性能。通过大量数据训练后,注意力机制可以判断评论中不同词语的重要程度,使得模型可以“注意到”评论中对情感影响最大的部分,提高模型情感分类的准确率。该模型同时具有收敛速度较快,只需要相对较小的训练数据集训练的优点。相比于传统nlp分析方法,本发明可以充分利用和学习输入用户评论中的情感信息,且无需使用句法分析或语义依存分析等外部知识。相比于传统机器学习方法,本发明无需依赖人工设计特征,极大的减少了特征工程所需的时间和人力成本。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1是本发明的模型整体架构图;
图2是本发明进行用户评论情感分析工作的流程图。
具体实施方式
下面结合附图对本发明的具体实施方法做进一步阐释。本发明主采用模块化设计,主要由4个部分构成,包括:词嵌入层,卷积层,注意力模块以及分类器。图1是本发明的系统结构图。其中,词嵌入层用于将输入的评论文本向量化,即将文字转换为向量形式。词嵌入方法将每个单词使用一个低维向量进行表示,将每条评论中所有单词的向量表示拼接起来,就能构成一条评论的向量表示形式。卷积层通过空间结构关系学习输入中的局部特征,以减少模型需要学习的参数数量。本发明使用卷积层来提取评论的局部特征,这通过将一定的窗口大小的卷积核应用在输入序列上来实现。注意力模块首先使用一个长短时记忆网络(longshort-termmemory,lstm)对输入的评论进行编码,然后和卷积层提取的局部特征进行相似度比较计算出注意力权重,局部特征的加权和送至分类器进行情感分类。分类器使用全连接神经网络和softmax分类器实现,整个模型使用逆向传播误差进行优化。
图1是本发明的模型整体架构图。每部分的工作流程详细描述如下:
s11:经过数据清洗后的用户评论文本,数据清洗包括分词,去除标点符号,字母转换为小写等工作。
s12:词嵌入矩阵,对用户评论文本中的每个单词可以被低维向量x表示:
x=lw(1-1)
其中
s13:使用lstm对每条评论进行编码,生成一个中间的序列特征表达
其中,xt为当前结点的输入向量,i、f、o和c分别代表输入门、遗忘门、输出门和激活向量,它们和隐层向量h维度相同,当下标为t-1时代表上一个结点的输出,而下标为t时代表当前结点的输出。例如,ht-1是上一个结点的隐层向量输出,而it、ft、ot、ct分别代表当前结点中输入门,遗忘门,输出门和激活向量的输出。w代表权重矩阵,其下标表示其对应的输入向量和门。例如,wxi代表当前结点输入向量在输入门上的权重矩阵,whf代表隐层向量输入在遗忘门上的权重矩阵。wco代表激活向量输入在输出门上的权重矩阵。b代表lstm结点中各个门的偏置量(bias),例如,bi代表输入门的偏置量,bf代表遗忘门的偏置量。σ(·)为sigmoid函数,g(·)和h(·)为转换函数,定义如公式(1-3),(1-4)所示。取最后一个结点的输出ht作为序列特征表达s′。
s14:卷积层包含一个卷积神经网络,用于提取用户评论的局部特征表达。卷积层的输入是由词嵌入得到一系列词向量
ci=φ(w*xi:i+k+b)(1-5)
其中,w的权值即为模型所要训练的参数,*为卷积操作,xi:i+k表示输入中一个长度为k的词向量序列。b为模型的偏置(bias)参数,φ是应用在卷积结果上的非线性函数,本发明使用relu作为非线性函数。卷积运算后得到整个输入的特征序列c={c1,c2,...,cn},每个元素ci代表用户评论某一局部的特征。
s15:使用中间特征s′与卷积层提取的每个局部特征ci进行比较,通过衡量两个特征之间的相似度来对局部特征赋予注意力权重值。相似度越高,则赋予注意力权重值越大,权值αi由下式给出:
其中
ei=sim(ci,s′)(1-7)
sim()函数用来衡量两个输入向量之间的相似度,t表示局部特征的数量。本发明中使用的是余弦相似度。
s16:当获得注意力权重后,评论的最终特征表达s通过下式计算:
s17:s作为每条评论最终表达送至分类器进行情感分类。本发明的分类器包含两层全连接前向传递神经网络与一个softmax分类器。在全连接前向传递神经网络上应用了dropout方法以减少模型在训练集上过拟合。softmax分类器由k个神经元组成,k为分类类别的数量(例如,二分类问题含两个神经元)。softmax分类器的输出结果由(1-9)定义:
其中hj是第j个神经元的原始输出(j=1,2...,k),k代表情感分类的类别数量。设模型最终输出向量output={output1,...,outputk},则模型对评论情感的预测结果
图2是使用本发明的进行用户评论情感分析的工作流程图,具体步骤如下:
s21:对用户评论文本数据进行数据清洗,包括分词,去除标点符号,字母转换为小写等操作。
s22:把清洗后的评论数据输出词嵌入层获得评论的低维向量表达。
s23:将评论的低维向量表达输入长短时记忆网络和卷积神经网络提取特征。
s24:结合序列特征表达和评论的局部特征表达计算注意力权重,并在评论的局部特征表达上通过注意力权重计算加权和作为评论的最终特征表达。
s25:将评论的最终特征表达输入分类器进行分类,并根据模型的预测结果和真是数据标签计算误差,模型的误差函数代表了模型预测的值和训练数据真实值之间的差距。本发明使用交叉熵误差函数作为代价函数,该函数由式(2-1)定义:
其中w代表模型中所有参数的向量,
s26:采用梯度下降法训练模型,并在达到一定的训练轮数后停止训练。
s27:将待情感分类的新数据输入训练好的模型,进行情感分析预测。
- 还没有人留言评论。精彩留言会获得点赞!