一种过滤垃圾用户和抽取短文本话题的方法与流程
本发明涉及文本处理算法领域,更具体地,涉及一种过滤垃圾用户和抽取短文本话题的方法。
背景技术:
突发性话题检测是近年来网络信息处理和自然语言处理领域的一个热门研究方向,突发性话题又被称之为新兴话题或趋势话题,泛指一类即将爆发或广为流传的话题,通常将伴随有重大新闻热点事件发生。而且,微博社交网络平台属于开放型平台,其上信息传播速度快,传播范围广,突发性话题可能会产生重大社会影响。因此,以微博文本作为研究对象,在数据中的话题或事件演变为热点事件以前或演变早期将其检测出来具有非常重要的理论价值和现实意义。对于个人而言,可以帮助用户对信息进行过滤,减少用户从海量杂乱无章的数据进行信息搜索与整理所耗时间和精力,并帮助用户了解当前被广泛和讨论的热点话题。目前现有的话题检测的方法有很多,大致可以分为两大类:基于文本聚类的话题检测方法和基于主题模型的话题检测方法。在基于文本聚类的方法中,先将文本预处理为某种表示形式,然后采用聚类算法对文本进行聚类,形成多个聚类簇,每个聚类簇就表示为一个独立的话题。而在基于主题模型的方法中,一般是对文本中隐藏的话题进行建模,最常用的建模方法是lda(latentdirichletallocation)。lda等主题模型具有非常清晰严谨的概率表示形式,在主题模型当中,话题被看做词汇集合上的概率分布,话题检测则是一个从词汇集合中进行概率推断的问题。现有的一种有效的突发话题检测的方法是一种基于sketch的话题模型以及基于哈希的降维方法实时检测推文流中的突发话题。
由于微博数据中存在一些用户在短时间内发布大量相似微博,这些用户被称为垃圾用户,从而造成模型所检测出来的话题都是一些没有意义的垃圾话题;模型中提取话题的方法是基于svd(singularvaluedecomposition,奇异值分解)的lsa(latentsemanticanalysis,潜在语义分析)方法来提取相关突发性话题,但是这种方法缺乏严谨的数理统计基础,且svd分解特别耗时。
技术实现要素:
本发明提供一种过滤垃圾用户和抽取短文本话题的方法,该方法利用计算微博数据中词对的突发性过滤一般话题而只保留突发性话题,再使用主题模型抽取对应的突发性话题,最后输出微博数据流上的突发性话题。
为了达到上述技术效果,本发明的技术方案如下:
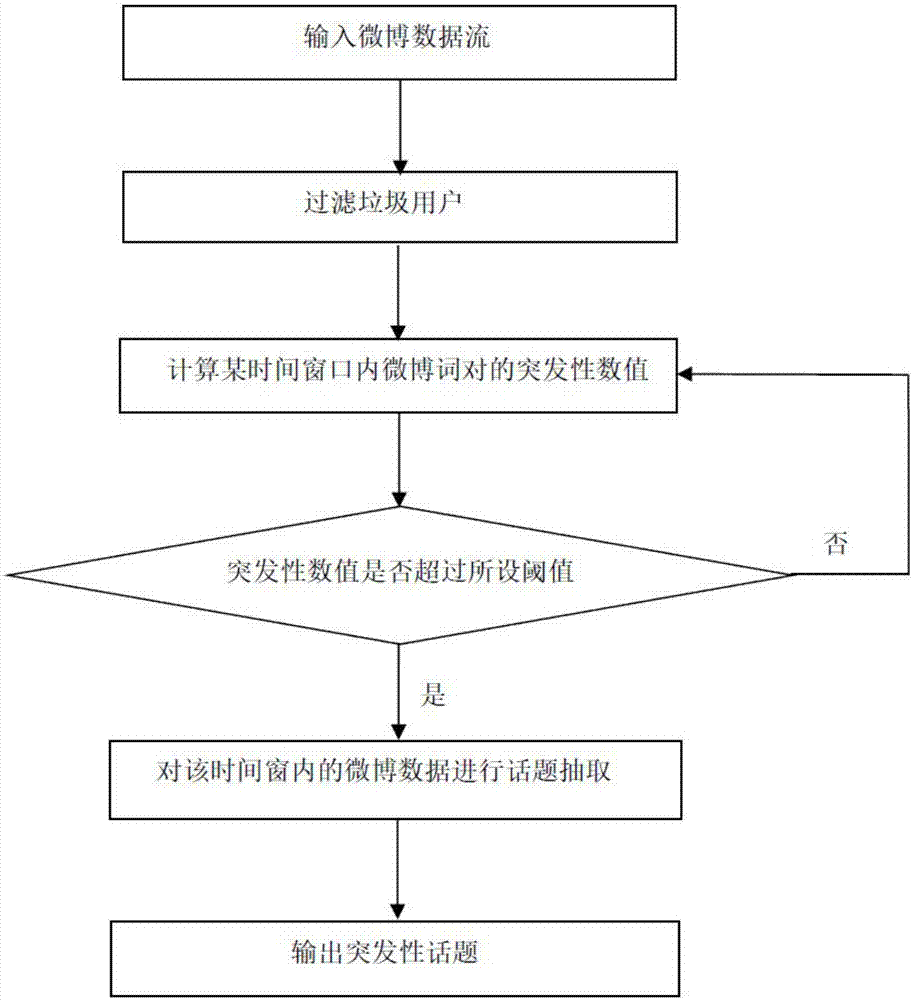
一种过滤垃圾用户和抽取短文本话题的方法,包括以下步骤:
s1:对微博数据流进行垃圾用户过滤处理,过滤掉在短时间内发布大量相似微博的用户及其所发微博数据;
s2:在进行过步骤s1处理后的数据上,计算某个时间窗口内微博数据词对的突发性数值;
s3:用步骤s2所计算的突发性数值跟所设阈值进行比较;若大于所设阈值,则进入步骤s4,若小于所设阈值,则进入下一个时间窗口,进入步骤s2;
s4:使用btm模型对该时间窗口内的微博数据进行主题抽取并输出突发性主题。
进一步地,所述步骤s1的具体过程是:
s11:输入原始微博数据流,对每条微博w进行分词、去除停用词处理后,得到对应微博的词袋模型{w1,w2,…,wm};
s12:对于某个时间窗口内,统计每个用户所发相似微博数量;
s13:若该时间窗口内,某用户所发相似微博数量超过所设阈值,则将此用户和所发微博剔除出去。然后选择下一个时间窗口,重复步骤s12,直至数据处理完毕。
进一步地,所述步骤s11的具体过程是:
在python3的环境中,输入原始微博数据流,使用jieba分词工具对微博数据流进行分词、去除停用词处理。
进一步地,所述步骤s12的具体过程是:
在处理过后的数据流上,选择时间窗口δt=1天,对于某个用户u,对于其所发的任意两条微博a,b对应的词袋模型{a1,a2,…,am}和{b1,b2,…,bm},然后统计词袋中出现的相同单词个数χ,便可根据的公式(1)计算两条微博的相似度:
若两条微博的相似度超过所设阈值sim=0.5,则该用户所发相似微博数量加一,根据此方法统计该时间窗口内每个用户所发相似微博数量。
进一步地,所述步骤s13的具体过程是:
用步骤s12所计算的用户所发相似微博数量跟所设最大阈值maxw=20比较,若大于该阈值,则判定此用户为垃圾用户,并将其所发微博剔除,然后选择下一个时间窗口,重复步骤s12,直至数据处理完毕。
进一步地,所述步骤s2的具体过程是:
在进行过步骤s1过滤垃圾用户数据后的数据流上,选择时间窗口大小为1天,使用公式(2)、(3)计算此时间窗口内微博数据词对的突发性,模仿物理学中加速度的概念,使用“加速度”来描述词对的突发性:
在公式(2)中,xi是第i条微博词对的频数,ti对应此微博的时间戳,其中指数函数的作用是赋予时间t近的词对比较高的权重,而赋予离t远的词对比较小的权重,时间窗口δt选为15min,为了量化速度的变化快慢,使用公式(3)来定义两个不同的时间窗δt1,δt2的速度变化情况,这作为量化词对突发性的一个方法,一般话题词对的突发性数值基本接近0,而突发性话题词对的突发性数值会远大于0,通过突发性数值大小,就可以从微博数据流中辨别出突发性话题。
进一步地,所述步骤s3的具体过程是:
从步骤s2中计算某时间窗口内微博数据词对的突发性数值,然后跟所设突发性阈值比较,若大于所设阈值,则说明在此时间窗口内有突发性话题出现,进入步骤s4进行话题抽取,若小于所设阈值,则说明此时间窗口内没有突发性话题出现,然后选择下一个时间窗口,进入步骤s2。
进一步地,所述步骤s4的具体过程是:
s41:获取步骤s3中检测到突发性话题的时间窗口内的微博数据的词对集合c;
s42:设置btm主题模型的话题数k和模型超参数α,β,使用gibbs采样算法推断出模型的主题分布参数θ和词分布参数φk。
进一步地,所述步骤s41的具体过程是:
若此时间窗口内有nd条微博,这些微博有nc个词对,则词对集合c表示为
进一步地,所述步骤s42的具体过程是:
1)、产生话题分布θ~dirichlet(α),分布为狄利克雷分布;
2)、对于每个话题k∈[1,k]产生词分布φk~dirichlet(β);
3)、对于每一个词对ci∈c产生多项分布zi~multinomial(θ)、
其中,z为k个话题的指示变量,z∈[1,k],θ表示话题分布参数其是一个k维概率分布,
根据参数θ和φ,根据公式(4)计算词对ci的条件概率:
为得到模型中的主题分布参数θ和对应的词分布参数φ,通过gibbs采样可以推断出这两个参数:根据如下条件概率分布计算话题分布zi:
其中,z-i表示除了ci以外所有词对的话题分布,n-i,k表示除了ci以外话题k的词对数量,
参数θ和φ的计算公式为:
与现有技术相比,本发明技术方案的有益效果是:
本发明方法对原始数据进行垃圾用户过滤处理,很大程度上避免了检测出来的突发性话题为没有实际意义话题这个问题;采用btm(bitermtopicmodel)主题模型进行话题抽取,模型清晰易懂,并且抽取话题的效率高效。
附图说明
图1:基于微博的突发话题检测方法;
图2:bitermtopicmodel模型图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
如图1所示,一种过滤垃圾用户和抽取短文本话题的方法,包括以下步骤:
s1:对微博数据流进行垃圾用户过滤处理,过滤掉在短时间内发布大量相似微博的用户及其所发微博数据;
s2:在进行过步骤s1处理后的数据上,计算某个时间窗口内微博数据词对的突发性数值;
s3:用步骤s2所计算的突发性数值跟所设阈值进行比较;若大于所设阈值,则进入步骤s4,若小于所设阈值,则进入下一个时间窗口,进入步骤s2;
s4:使用btm模型对该时间窗口内的微博数据进行主题抽取并输出突发性主题。
步骤s1的具体过程是:
s11:输入原始微博数据流,对每条微博w进行分词、去除停用词处理后,得到对应微博的词袋模型{w1,w2,…,wm};
s12:对于某个时间窗口内,统计每个用户所发相似微博数量;
s13:若该时间窗口内,某用户所发相似微博数量超过所设阈值,则将此用户和所发微博剔除出去。然后选择下一个时间窗口,重复步骤s12,直至数据处理完毕。
步骤s11的具体过程是:
在python3的环境中,输入原始微博数据流,使用jieba分词工具对微博数据流进行分词、去除停用词处理。
步骤s12的具体过程是:
在处理过后的数据流上,选择时间窗口δt=1天,对于某个用户u,对于其所发的任意两条微博a,b对应的词袋模型{a1,a2,…,am}和{b1,b2,…,bm},然后统计词袋中出现的相同单词个数χ,便可根据的公式(1)计算两条微博的相似度:
若两条微博的相似度超过所设阈值sim=0.5,则该用户所发相似微博数量加一,根据此方法统计该时间窗口内每个用户所发相似微博数量。
步骤s13的具体过程是:
用步骤s12所计算的用户所发相似微博数量跟所设最大阈值maxw=20比较,若大于该阈值,则判定此用户为垃圾用户,并将其所发微博剔除,然后选择下一个时间窗口,重复步骤s12,直至数据处理完毕。
步骤s2的具体过程是:
在进行过步骤s1过滤垃圾用户数据后的数据流上,选择时间窗口大小为1天,使用公式(2)、(3)计算此时间窗口内微博数据词对的突发性,模仿物理学中加速度的概念,使用“加速度”来描述词对的突发性:
在公式(2)中,xi是第i条微博词对的频数,ti对应此微博的时间戳,其中指数函数的作用是赋予时间t近的词对比较高的权重,而赋予离t远的词对比较小的权重,时间窗口δt选为15min,为了量化速度的变化快慢,使用公式(3)来定义两个不同的时间窗δt1,δt2的速度变化情况,这作为量化词对突发性的一个方法,一般话题词对的突发性数值基本接近0,而突发性话题词对的突发性数值会远大于0,通过突发性数值大小,就可以从微博数据流中辨别出突发性话题。
步骤s3的具体过程是:
从步骤s2中计算某时间窗口内微博数据词对的突发性数值,然后跟所设突发性阈值比较,若大于所设阈值,则说明在此时间窗口内有突发性话题出现,进入步骤s4进行话题抽取,若小于所设阈值,则说明此时间窗口内没有突发性话题出现,然后选择下一个时间窗口,进入步骤s2。
步骤s4的具体过程是:
s41:获取步骤s3中检测到突发性话题的时间窗口内的微博数据的词对集合c;
s42:设置btm主题模型的话题数k和模型超参数α,β,使用gibbs采样算法推断出模型的主题分布参数θ和词分布参数φk。
步骤s41的具体过程是:
若此时间窗口内有nd条微博,这些微博有nc个词对,则词对集合c表示为
如图2所示,步骤s42的具体过程是:
1)、产生话题分布θ~dirichlet(α),分布为狄利克雷分布;
2)、对于每个话题k∈[1,k]产生词分布φk~dirichlet(β);
3)、对于每一个词对ci∈c产生多项分布zi~multinomial(θ)、
其中,z为k个话题的指示变量,z∈[1,k],θ表示话题分布参数其是一个k维概率分布,
根据参数θ和φ,根据公式(4)计算词对ci的条件概率:
为得到模型中的主题分布参数θ和对应的词分布参数φ,通过gibbs采样可以推断出这两个参数:根据如下条件概率分布计算话题分布zi:
其中,z-i表示除了ci以外所有词对的话题分布,n-i,k表示除了ci以外话题k的词对数量,
参数θ和φ的计算公式为:
本方法对原始数据进行垃圾用户过滤处理,很大程度上避免了检测出来的突发性话题为没有实际意义话题这个问题;采用btm(bitermtopicmodel)主题模型进行话题抽取,模型清晰易懂,并且抽取话题的效率高效。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用于仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!