一种基于图数据库的微博用户转发关系导入及可视化方法与流程
本发明涉及微博舆情大数据的分析领域,尤其涉及一种基于neo4j图数据库的微博用户转发关系导入及可视化方法。
背景技术:
随着自媒体时代的到来,社交网络服务(socialnetworkingservice,sns)已融入到大众日常生活中。个人将自己的信息上传到各种各样的社会化媒体平台如微博、论坛、博客、在线社区、微信、qq等即时通讯软件、社交网站(facebook、twitter)等,并通过社交平台管理自己的社交圈子,由此造成大量的个人信息在互联网上被公开。这些信息中包含大量有用的信息,为公安情报信息工作提供了无数有价值的情报。公安情报工作的重点就是关注人物、组织、账号之间的关系,在实际案件的侦查中往往需要通过一个姓名获得与之相关的所有信息,例如某人的户籍信息、车辆信息、社交关系、出行记录等。以上信息的关联和查询,以前通常需要公安情报信息工作人员在海量的历史信息中人工查看、搜索,现今虽然通过关联分析技术,可以将多个数据库内的海量历史数据中隐含的关联关系挖掘出来,但是结合互联网上的社交数据,针对海量关系数据的存储、特定人物关系的挖掘及可视化的应用研究还不是很成熟。
社交网络数据是由数亿人在互联网上随机产生的,导致数据杂乱无章,面对海量的社交关系数据,还用以往的关系型数据库进行存储、查询和分析的速度会很慢,不利于公安机关办案效率的提升。例如公安机关在调查某一犯罪嫌疑人时,侦查人员希望能够对海量历史数据和互联网上的社交数据进行关联分析,快速地找到嫌疑人的个人基本情况以及人物关系等重要信息,并且能够将这些信息通过可视化软件直观地展现在侦查人员面前,缩短对于嫌疑人的摸排调查时间,提升工作效率的同时节省办案成本。
对海量信息进行存储和管理,需要处理大量的数据,离不开数据库技术。数据库技术发展过程中,出现过众多的数据模型,比较常用的有3种,分别为关系模型、层次模型和图模型。
关系模型建立在严格的数学基础上,具有较高的数据独立性和安全性,使用简单。关系数据库是目前应用最为广泛的数据技术,主流的关系数据库有oracle,sqlsever,mysql等。但是大数据环境下,数据规模的爆炸式增长与数据复杂性的增加,关系模型已经无法满足领域需要,正如社交网络为例,采用关系数据库将导致数据冗余,并且不能适应社交数据的动态性,也不能很好地支持类似“好友的好友”这样的多层复杂查询。
层次模型类似于“树”的结构,代表两个记录型之间一对多的关系,由于“树”结构的延伸方向的单向性,不能很好向各个方向发散的数据关系。而公安机关在办案过程中,经常需要摸底排查犯罪人员的多层复杂人际关系。
针对数据内在关系复杂且动态变化的问题,文献[1]唐德权,张悦,贺永恒,etal.基于图数据挖掘算法的犯罪规律研究及应用[j].计算机技术与发展,2011,21(11):89-91,95.将图结构数据挖掘技术应用于犯罪规律研究,解决犯罪活动之间或内部的复杂关系难以用简单的数据结构表示的难题。唐德权等人在文献[1]中提出了基于相同犯罪特征频繁子图结构的挖掘犯罪规律算法gdmcr(graphdataminingcrimerule),利用gdmcr算法得到的频繁子图关联知识分析犯罪规律及网络核心成员。实验结果表明基于图数据挖掘复杂关系数据的有效性和实用性,但是研究过程中并未涉及复杂关系数据的可视化。在现实生活中,公安机关侦查人员面对复杂的社交关系数据时,尽管采用图结构数据表示了数据间错综复杂的关系,更希望能够通过可视化软件直观地将这些关系数据显示出来,缩短对于特定个体的社交关系查询时间,提升工作效率的同时节省办案成本。文献[2]宫法明,李翛然.基于neo4j的海量石油领域本体数据存储研究[j].计算机科学,2018,45(6a):549-554提出了一种基于图形数据库neo4j的大规模本体数据存储和检索问题的解决方案,实验结果表明该方案与基于关系数据库的方法相比,在数据存储和信息检索方面具有较大的性能提升。
图形数据库能够有效的存储、管理、更新数据及其内在关系,并可以通过关系能够包含属性这一功能来提供更为丰富的关系展现方式,从而执行多层节点查询等复杂操作,提高复杂关系数据的查询效率。采集社交平台转发关系数据时,为了提升爬虫性能,需要采用多线程的爬虫技术,然而多线程爬虫爬取的转发关系随机、零乱、不连续难以获取转发顺序,导致在向图形数据库导入关系数据构建微博转发关系网络时存在问题。
技术实现要素:
发明目的:针对以上不足之处,本发明的目的是提供一种基于neo4j图数据库的微博用户转发关系导入及可视化方法,能够在仅仅知道部分转发节点的情况还原出真实的转发关系,并在后续随着爬虫获取节点数量的增加而不断完善直至构建出整体的转发关系网络。
技术方案:一种基于neo4j图数据库的微博用户转发关系导入及可视化技术方法,利用多线程爬虫获取源微博及其所有多层的转发消息,将微博的所有转发关系,包括源微博和所有多层转发的微博内容以及转发微博的用户基本信息导入neo4j图数据库中。
基于neo4j图数据库的微博用户转发关系导入及可视化技术方法,包括以下步骤:
步骤(1),采用多线程微博爬虫获取源微博和后续转发微博,若获取到,则进入步骤(2),否则程序结束;
步骤(2),查看“用户名:评论内容”是否存在于节点列表中,若不存在,则进入步骤(3);若存在,则在图数据库中更新该节点的属性,回到步骤(1);
步骤(3),将该节点的“用户名:评论内容”添加到节点列表中,进入步骤(4);
步骤(4),判断该节点的评论内容是否含有“//@”,若含有,则进入步骤(5);否则根据微博转发的评论内容产生规则,认定该节点为一层转发节点,并将该节点连接到原始节点上,回到步骤(1);
步骤(5),以评论内容中的“//@”为分隔符对评论内容进行切分,划分转发层次,从最后一个节点开始添加上层节点并建立连接,直到连接到已存在的节点为止,回到步骤(1)。
步骤(1)中,爬虫获取原始微博节点,添加该原始节点及其所有属性到图数据库,并将a节点的“用户名:评论内容”作为a节点的唯一标识添加进节点列表;其中的多线程运行爬虫获取的微博顺序和转发顺序不受限制。
步骤(2)中,判断所述节点是否存在于节点列表中,若不存在则进入步骤(3),若已存在,则根据爬虫爬取的该节点其他属性更新图数据库中该节点的缺省属性,返回步骤(1)。其中,判断所述节点是否存在于节点列表中的判断方式为,提取节点的用户名和评论内容两个属性,将两个属性内容组合起来在节点列表中查找。
步骤(3)中,提取该节点的用户名和评论内容两个属性的值并组合起来,将该节点的“用户名:评论内容”添加进节点列表。
步骤(5)包括以下步骤:
步骤(5.1),对评论内容以“//@”符号进行切分,划分出转发层次;
步骤(5.2),从最后一个节点d开始依次创建节点并建立连接,同时将每个节点的“用户名:评论内容”添加进节点列表,根据微博转发评论内容生成规则,回到步骤(1)。
工作原理:neo4j是一个高性能的nosql(非关系型)图形数据库,它将结构化数据存储在网络上而不是在表中,它可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。neo4j提供了大规模可扩展性,在一台机器上可以处理数十亿节点/关系/属性的图,可以扩展到多台机器并行运行。不同于关系数据库中频繁查询导致大量的表连接影响查询效率,图数据库善于处理大量复杂、互连接、低结构化的数据,这些数据动态变化往往需要频繁查询,提高了查询效率。
本发明通过微博多线程爬虫获取杂乱且不连续的微博转发关系,并使用本方法还原真实转发顺序并构建转发关系网络,使用neo4j图数据库显示用户转发关系网络。具体实现的功能是利用多线程爬虫技术获取某一源微博及其所有多层的转发消息,将该微博的所有转发关系,包括源微博和所有多层转发的微博内容以及转发微博的用户基本信息导入neo4j图数据库中,以用户为节点,转发关系为有向连边的形式可视化。
本发明提出一种对多线程微博爬虫爬取的杂乱,不连续的微博转发节点内容进行分析,还原其真实转发顺序,并构建转发关系网络的方法,克服了多线程爬虫获取的用户转发关系数据并不是按照真实转发路径递进难以获取用户转发顺序的问题;并且能在爬虫系统24小时不间断运行的情况下,一旦有新产生的转发消息就能够实时将用户的个人信息和用户之间的转发关系导入图数据库,实现了节点添加,节点去重,节点内容及节点间的转发关系更新等功能。
有益效果:与现有技术相比,本发明解决了在构建微博转发关系网络时,多线程爬虫爬取的转发关系随机、零乱、不连续难以获取转发顺序的问题,能够在仅仅知道部分转发节点的情况还原出真实的转发关系,并在后续随着爬虫获取节点数量的增加而不断完善直至构建出整体的转发关系网络。实现了节点添加,节点去重,节点内容及节点间的转发关系更新等功能。本发明方法具有导入数据效率高,可扩展性好,易修改等特点,方便后期的不断完善;适用于节点有先后顺序,节点间关系是有方向性的一切复杂关系数据,有广阔的应用前景。
附图说明:
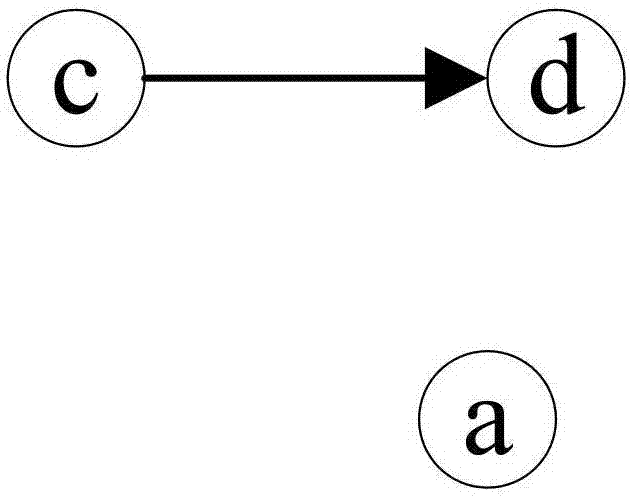
图1为本发明的步骤(5.2)中节点及节点间关系导入图数据库:节点c导入图数据库,并建立c—>d的连接;
图2为本发明的步骤(5.2)中节点及节点间关系导入图数据库:节点b导入图数据库,并建立b—>c的连接;
图3为本发明的步骤(5.2)中节点间关系导入图数据库:建立a—>b的连接;
图4为本发明的算法执行流程图。
具体实施方式
本发明的代码实现了面向节点相互连接的节点创建,修改功能。代码依据节点的content属性的内容不同将节点分为以下几种情况:原始节点,一层转发节点和多层转发节点,即转发的层数大于1层的节点。
首先,受爬虫算法限制,导入的节点有几个前提:
1、由于爬虫是多线程爬取,所以节点的爬取顺序是未知的。例如,先进数据库的节点极有可能是后转发的,后进数据库的节点极有可能是先转发的,第一个原始节点除外。
2、由于查找节点的程序功能的限制,只能通过一个属性,此处我们选用户名作为查找节点的索引。
我们在程序里用一个列表存放所有的节点的简略信息,包含节点的用户名和评论内容,用以判断爬虫传来的节点是否已经存在。
本发明包括以下几个步骤:
步骤(1),采用多线程微博爬虫获取源微博和后续转发微博,获取所有微博对应的用户个人信息和微博转发内容,若能够获取到,则进入步骤(2),否则程序结束;
步骤(1)中,爬虫获取微博节点,通过辨认节点的method属性是否为“原创”或“转发”来判断节点为原始节点还是转发节点,本爬虫程序第一个获取的为原始节点,之后为转发节点。节点内容包括获取的所有微博对应的用户个人信息和微博转发内容。具体步骤为,首先爬虫获取第一条原始微博a,通过辨认节点的method属性为“原创”,然后添加该原始节点及其所有属性(如a的“昵称”、“评论内容”等属性)到图数据库,并且将a节点的“用户名:评论内容”作为a节点的唯一标识添加进节点列表。该步骤完成将原始节点a及其所有属性导入图数据库,实现了节点添加,节点内容更新等功能。具有导入数据效率高,可扩展性好的特点,方便后期的不断完善。
由于爬虫是多线程运行,之后获取的微博顺序和转发顺序不一定相同,假设真实的转发顺序为a—>b—>c—>d(b转发原始节点a,c转发b,d转发c),但爬虫获取节点的顺序可能是d,c,b或c,b,d,在此以d,c,b为例。
步骤(2),查看“用户名:评论内容”是否存在于节点列表中,若不存在,则进入步骤(3);若存在,则在图数据库中更新该节点的属性,回到步骤(1);其中,判断该节点是否存在于节点列表中时,判断方式为:提取节点的用户名和评论内容两个属性,将两个属性内容组合起来在节点列表中查找,若不存在则进入步骤(3),若已存在,则根据爬虫爬取的该节点其他属性更新图数据库中该节点的缺省属性,即除用户名和评论内容以外的其他属性,返回步骤(1);实现了节点去重,节点内容更新等功能,具有可扩展性好,易修改的特点,方便后期的不断完善。
步骤(3),提取该节点的用户名和评论内容两个属性的值并组合起来,将该节点的“用户名:评论内容”添加到节点列表中,进入步骤(4);实现了节点添加功能,具有导入数据效率高,可扩展性好的特点,方便后期的不断完善。
步骤(4),判断该节点的评论内容是否含有“//@”符号,若含有,则进入步骤(5);若不含有,则根据微博转发的评论内容产生规则,认定该节点为一层转发节点,并将该节点连接到原始节点上,即第一个发布微博消息的节点,回到步骤(1);
步骤(5),以评论内容中的“//@”为分隔符对评论内容进行切分,划分转发层次,从最后一个节点开始添加上层节点并建立连接,直到连接到已存在的节点为止,回到步骤(1)。解决了多线程爬虫爬取的转发关系随机、零乱、不连续,难以获取转发顺序的问题,能够在仅仅知道部分转发节点的情况还原出真实的转发关系,并在后续随着爬虫获取节点数量的增加而不断完善直至构建出真实的转发关系网络。适用于节点有先后顺序,节点间关系是有方向性的一切复杂关系数据,有广阔的应用前景。
步骤(5.1),对评论内容以“//@”符号进行切分,划分出转发层次,如节点d的评论内容为”d_content//@c:c_content//@b:b_content”,以”//@”为分隔符,将d的评论内容切分成列表d_content,c:c_content,b:b_content的形式,得知实际转发顺序为b—>c—>d(c转发b,d转发c);
步骤(5.2),从最后一个节点d开始依次创建节点并建立连接,依次建立c—>d(d转发c),b—>c(c转发b),依次建立d节点,c节点,最后建立b节点。同时将每个节点的“用户名:评论内容”添加进节点列表,直到建立到b时,根据微博转发评论内容生成规则,得知b为一层转发节点,其直接上层节点是原始节点a(通过节点列表查询已存在),直接建立a—>b(b转发a)的连接即可(由于c,b节点微博爬虫并没有真正获取到,除了用户名和评论内容外其他属性为空,等爬虫获取到以后再对其节点属性进行更新),回到步骤(1)。
上述步骤首先完成将节点d及其所有属性导入图数据库,实现了节点添加,节点内容更新等功能,具有导入数据效率高,可扩展性好的特点,方便后期的不断完善。
如图1所示,步骤(5.2)中节点及节点间关系导入图数据库:节点c导入图数据库,并建立c—>d的连接。
如图2所示,步骤(5.2)中节点及节点间关系导入图数据库:节点b导入图数据库,并建立b—>c的连接。
如图3所示,步骤(5.2)中节点间关系导入图数据库:建立a—>b的连接。
接着如图1所示,将节点c导入图数据库,建立c—>d(d转发a)的连接;如图2所示,将节点b导入数据库,并建立b—>c(c转发b)的连接;如图3所示,将一层转发节点b直接连接到a建立a—>b(b转发a)的连接;实现了节点添加,节点去重,节点间的转发关系更新等功能,解决了在构建微博转发关系网络时,多线程爬虫爬取的转发关系随机、零乱、不连续难以获取转发顺序的问题,能够在仅仅知道部分转发节点的情况还原出真实的转发关系,并在后续随着爬虫获取节点数量的增加而不断完善直至构建出整体的转发关系网络。
通过如图4所示的算法执行流程图及相应步骤操作,便可以建立起针对某一源微博的有向的转发关系网络图。本发明方法具有导入数据效率高,可扩展性好,易修改的特点,适用于节点有先后顺序,节点间关系是有方向性的一切复杂关系数据,有广阔的应用前景。
- 还没有人留言评论。精彩留言会获得点赞!