本发明涉及时序数据查询排序领域,尤其是一种多时空条件下查询排序方法、装置、设备和存储介质。
背景技术:
目前有较多的时序数据计算模型,包括tsdb时序数据库等,很多监控系统都采用了tsdb作为数据库系统来存储海量的、严格按时间递增的、在一定程度来说结构非常简单的各种指标数据,存储的数据结构简单指,某一度量指标在某一时空点只会有一个值,没有复杂的结构(嵌套、层次等)和关系(关联、主外键等),现有的基于时序数据库的目标查询,都是对单一时空的数据进行查询排序,比如查找一个指定的mac地址出现的时间空间,或者对其指标进行排序,并没有涉及多时空状态下对不确定目标特征值的查询,而且查询过程也没有综合考虑空间相似度和空间多样性,因此需要提出一种综合的评价方法,实现对查询结果的排序,从而获知不确定目标的目标特征值数据信息。
技术实现要素:
本发明旨在至少在一定程度上解决相关技术中的技术问题之一。为此,本发明的一个目的是提供一种综合考虑空间相似度和空间多样性的多时空条件下查询排序方法、装置、设备和存储介质。
本发明所采用的技术方案是:
第一方面,本发明提供一种多时空条件下查询排序方法,包括步骤:
采集查询目标特征值对应的至少一个时空点信息;
将每一个时空点信息进行对应的时空段数据扩充,得到待查询数据;
根据不同的目标特征值将待查询数据分类,在不同预设评价指标下,计算每一个目标特征值在不同查询日期内对应的多个指标量值;
根据综合排序规则得到查询值,并对所述查询值进行排序;
所述预设评价指标包括:第一评价指标、第二评价指标和第三评价指标;
所述综合排序规则指,合并不同目标特征值在不同查询日期对应的同一类指标量值,对每一个目标特征值合并后的多个指标量值进行无量纲化并求平均,得到每一个目标特征值对应的查询值;
所述合并指对不同查询日期的同一类指标量值求和。
进一步地,所述第一评价指标为自信息量指标,具体是:
其中,x表示目标特征值,p(x)表示目标特征值出现的概率,cnt表示目标特征值在一天内出现的次数,n表示基准数,ib表示目标特征值的自信息量指标量值。
进一步地,所述第二评价指标为jaccard相似度指标,具体是:
其中,nmatch表示目标特征值x一天内匹配到的次数,ntotal表示目标特征值x出现的总次数,nquery表示查询的时间段中所有的时空点数,sim(x)表示目标特征值x的相似度指标量值。
进一步地,所述第三评价指标为空间多样性指标,具体是:
其中,si表示目标特征值x在站点i出现的次数,s表示目标特征值x在所有站点出现的总次数,j(x)表示目标特征值x的空间多样性指标量值。
进一步地,所述合并具体为:
所述无量纲化是使用z-score方法进行无量纲化,具体为:
其中,d表示总的查询天数,hi(x)m表示第m天目标特征值x的第i个指标量值,xi表示目标特征值x合并后的第i个指标量值,meani表示第i个指标量值的均值,msei表示第i个指标量值的均方差,zi表示目标特征值x的第i个指标量值的无量纲化指标量值;
所述综合排序规则具体为:
其中,n表示3个预设评价指标,zscore表示目标特征值x的查询值。
进一步地,所述目标特征值包括:终端信息,智能ic卡和身份证id,所述终端信息包括:终端mac地址和终端imsi数据。
进一步地,当所述目标特征值为终端mac地址时,得到待查询数据后还包括数据采样,所述数据采样具体包括:去掉mac地址里面包含‘048c’的数据和/或去掉信号强度为-1的数据。
第二方面,本发明还提供一种多时空条件下查询排序装置,包括:
数据采集模块:用于采集查询目标特征值对应的至少一个时空点信息;
数据扩充模块:用于将每一个时空点信息进行对应的时空段数据扩充,得到待查询数据;
获取指标量值模块,用于根据不同的目标特征值将待查询数据分类,在不同预设评价指标下,计算每一个目标特征值在不同查询日期内对应的多个指标量值;
排序模块:用于根据综合排序规则得到查询值,并对所述查询值进行排序。
第三方面,本发明还提供一种多时空条件下查询排序的控制设备,包括:
至少一个处理器;以及,
与所述至少一个处理器通信连接的存储器;其中,
所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行如第一方面所述的方法。
第四方面,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机可执行指令,所述计算机可执行指令用于使计算机执行如第一方面任一项所述的方法。
本发明的有益效果是:
本发明通过综合考虑空间相似度和空间多样性,结合自信息量指标、相似度指标和空间多样性指标,并通过z-score评价方法对不同目标特征值的指标量值进行无量纲化,得到每一个目标特征值对应的查询值,实现多时空状态下目标特征的查询排序,即通过排序检索到满足时空查询条件的目标特征值,在不同评价指标下的指标量值,对其进行无量纲化后,进一步确定最为匹配的查询结果,本发明广泛适用于多种目标特征值查询,如终端信息、智能ic卡信息和身份证id信息等,综合空间相似度和空间多样性,查询匹配的结果更准确。
附图说明
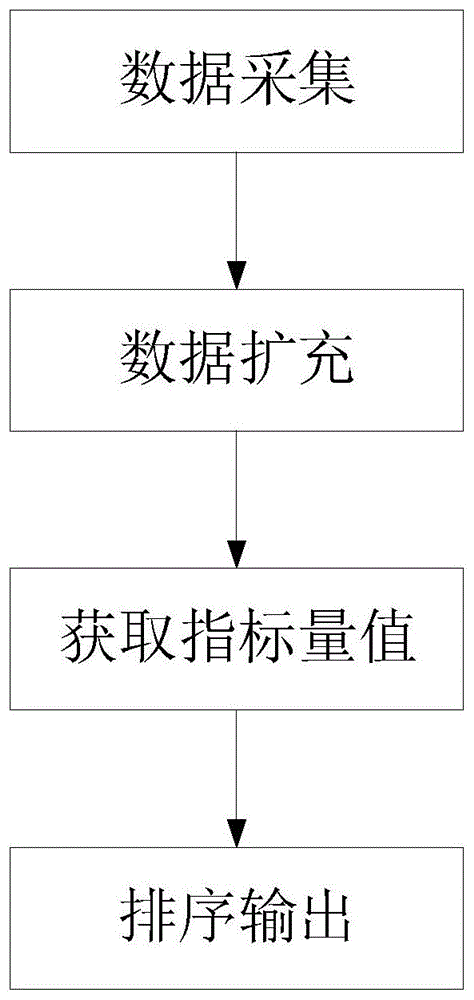
图1是本发明一种实施方式的多时空条件下查询排序方法流程图;
图2是本发明一种实施方式的多时空条件下查询排序装置结构框图。
具体实施方式
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对照附图说明本发明的具体实施方式。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,并获得其他的实施方式。
本方法的应用场景主要是在多个时空条件下,对终端信息、智能ic卡和身份证id的定位,比如场景一:拿到一个特定人物的照片,需要找出该目标人物的手机号,通过先验信息通过视频锁定了目标人物,从历史的视频中找到了该目标出现过的多个时间空间信息,即出现在某些地点的时间,即可通过本发明的多时空条件下查询排序方法找到最匹配的手机号。场景二:需要寻找一个特定人物,如其在地铁站出现过刷卡信息,划定大致的时空范围,在采集库中查询排序,可通过本发明的多时空条件下查询排序方法找到最匹配的智能ic卡号,同理也可以通过身份证id号信息在数据库中进行查询查找,本发明不限于上述示例场景的应用,下面以实施例来详细描述本发明的技术实现过程。
实施例一:
本实施例以查询目标的终端mac信息的查询排序过程为例。
如图1所示,为本实施例中多时空条件下查询排序方法流程图,包括步骤:
s1:数据采集:采集查询目标特征值对应的至少一个时空点信息,例如确定目标不同时间出现在不同的地点的信息,目标特征值包括:终端信息,智能ic卡和身份证id,所述终端信息包括:终端mac地址和终端imsi数据等。
s2:数据扩充:将每一个时空点信息进行对应的时空段数据扩充,得到待查询数据,采集时间不能精确到某一个点,而是目标出现一段时间内(如前后10分钟)都可能有采集到,因此需要将时空点扩充成时空段,数据扩充以分钟为单位,如采集每分钟出现的mac信息,一分钟以内的mac数据需要进行去重。
还包括对当目标特征值为终端mac地址时,得到待查询数据后需要数据采样,采样的目的是为了去除伪mac,数据采样具体包括:(1)去掉mac地址里面包含‘048c’的数据;(2)去掉信号强度为-1的数据。
s3:获取指标量值,计算所述待查询数据中每一项数据在不同预设评价指标下的对应的多个指标量值,并对每一个指标量值进行无量纲化,其中预设评价指标包括:第一评价指标、第二评价指标和第三评价指标。
s4:排序输出:根据综合排序规则得到每一项待查询数据的查询值,并对所述查询值进行排序,综合排序规则指,将每一项待查询数据对应的多个无量纲的指标量值进行求平均。
下面是具体的不同的预设评价指标。
假设一个场景,例如,采集三个时空点信息:
时空点1:日期(第一天):2018-10-24时间:14:20:00地点:a;
时空点2:日期(第二天):2018-09-19时间:21:40:00地点:b;
时空点3:日期(第三天):2018-10-19时间:11:55:00地点:c;
由于目标不一定精确出现在上述三个时空点,目标可能出现在上述时空点前后的一段时间内,因此将上述三个时间点分别以前后10分钟扩展成时间段,如时空点1可以扩展为:日期:2018-10-24时间:14:10:00~14:30:00,地点:a等,查询上述时间范围内采集到的所有的mac信息,一般有上万的mac信息或者手机号信息,本场景假设有500个mac信息,其中某一个mac出现的次数以天为单位计算,如第一天出现5次,第二天出现0次,第三天出现3次等。
1)第一评价指标为自信息量指标,自信息量指目标特征值出现的概率越小,其信息量越大,即计算目标特征值出现的有效信息量,如目标特征值在同一天出现的时空点越多,其信息量越低,具体是:
其中,x表示目标特征值,p(x)表示目标特征值出现的概率,cnt表示目标特征值在一天内出现的次数,n表示基准数,ib表示目标特征值的自信息量指标量值。
例如mac1在不同日期出现的总次数分别为:5次、0次和3次,则x表示目标特征值mac1,p(x)表示mac1出现的概率,cnt表示mac1在一天内出现的次数,不同日期分别对应5次、0次和3次,n表示基准数,取值为60*24,ib表示mac1的自信息量指标量值。
2)第二评价指标为jaccard相似度指标,将输入的查询条件看作是一段时空序列,则查询结果的评价标准可以看作是衡量两个时空序列的相似性,因此引入jaccard相似度系数进行时空相似性衡量,具体是:
其中,nmatch表示目标特征值x一天内匹配到的次数,ntotal表示目标特征值x出现的总次数,nquery表示查询的时间段中所有的时空点数,sim(x)表示相似度指标量值。
例如mac1在不同日期出现的总次数分别为5次、0次和3次,数据扩充后查询序列有500个mac信息,则nmatch表示mac1一天内匹配到的次数,不同日期分别对应5次、0次和3次,ntotal表示mac1出现的总次数,为5+0+3=8次,nquery表示查询的时间段中所有的时空点数,以分钟为单位,由于上述三个时间段分别以前后10分钟扩展成时间段,即nquery表示20*3=60(分钟),sim(x)表示mac1的相似度指标量值。
3)第三评价指标为空间多样性指标,即衡量空间多样性,指查询结果是否包含足够多的站点,引入香农维纳均匀度指数来评价空间多样性,具体是:
其中,si表示目标特征值x在站点i出现的次数,s表示目标特征值x在所有站点出现的总次数,j(x)表示目标特征值x的空间多样性指标量值。
例如在所有查询条件中,mac1可能在a点的查询条件中出现了2次,在b点出现了3次,在c点出现5次,即si表示mac1在站点i出现的次数,三个站点a\b\c分别对应2次、3次和5次,s表示mac1在所有站点出现的总次数,即3+3+5=10次,j(x)表示mac1的空间多样性指标量值。
例如5次匹配中,{a:1次,b:2次,c:2次}的结果优于{a:3次,b:2次},第一种情况站点分布更均匀。
本实施例中对不同目标特征值不同查询日期对应的上述三个指标量值进行合并,具体为:
其中,d表示总的查询天数,hi(x)m表示第m天目标特征值x的第i个指标量值,例如包括5天的查询条件,目标特征值mac1在每一天均有3个指标量值,分别是day1~day5的自信息量指标量值、相似度指标量值和空间多样性指标量值,合并指将day1~day5的自信息量指标量值相加得到mac1的自信息量指标量值,同理得到mac1的相似度指标量值和空间多样性指标量值。
接着对mac1的3项指标量值进行无量纲化,无量纲化是使用z-score方法进行无量纲化,具体为:
其中,d表示总的查询天数,hi(x)m表示第m天目标特征值x的第i个指标量值,xi表示目标特征值x合并后的第i个指标量值,meani表示第i个指标量值的均值,msei表示第i个指标量值的均方差,zi表示目标特征值x的第i个指标量值的无量纲化指标量值。
例如查询条件中,存在mac1~mac5共5个不同的目标特征值,每个目标特征值均对应3个合并后的指标量值,对mac1的自信息量指标量值来说,无量纲化过程中的meani为day1~day5不同的目标特征值的自信息量指标量值的均值,msei为day1~day5不同的目标特征值的自信息量指标量值的均方差,同理可得其他两项指标量值无量纲化过程参数。
对指标量值进行无量纲化后,需要根据综合排序规则得到不同目标特征值对应的查询值,综合排序规则具体为:
其中,n表示3个预设评价指标,zscore表示目标特征值x的查询值。
例如对目标特征值mac1,上述过程得到mac1对应得3个无量纲化得指标量值,对其求和取平均即可得到目标特征值mac1的查询值。
对不同目标特征值对应的查询值按照从大到小进行排序,选定第一位的目标特征值为要查找的目标mac值。
下面就一个具体实施例进行结果分析。
场景:知道一个目标人物的出现的时空范围,想找出该人物的手机mac地址。
整理这些时空范围点如下:
1):12680070002018-09-1921:50:00->扩充为->21:40:00~22:00:00
2):12600190002018-10-1912:00:00->扩充为->11:50:00~12:10:00
3):12610290002018-08-0814:40:00->扩充为->14:30:00~14:50:00
4):12680120002018-08-0221:40:00->扩充为->21:30:00~22:00:00
一共四个出现的地点和时间段,最前面为地铁站的编号,出现的时间范围约为20分钟左右,在这些时空段内,可能采集到许多不同的手机号或者mac信息,通常是上万的mac或者手机号,有可能并没有采集到该用户的数据,同时还有一些在这些地点经常出现的人携带的手机带来的干扰信息,导致从这些时空段出现的设备找出目标人物的mac很难,
本实施例中使用这些时空范围在采集库里查找出现的mac,一共有8636个mac在这些时间被采集到,对出现的手机号进行查询并排序,排序值最靠前的手机号则最可能是目标人物的手机号,分别对这些mac按本排序法进行打分如下表1所示。
其中:bits:表示自信息量指标量值;jaccard:表示相似度指标量值;shannonwiener:表示空间多样性指标量值;zscore:表示排序值。
经过排序后,排序值(zscore)排名前三的分别为:
mac1:4040a7e5abea;zscore:0.692217353835432;
mac2:fc4203c1a4e8;zscore:0.5710468790679801;
mac3:5cf7e6bf8839;zscore:0.5419621587618433。
最后经过验证,查询目标人物mac的轨迹,确认排名第一的mac确实为该目标人物所持手机的mac地址。
实施例二:
如图2所示,为本实施例的多时空条件下查询排序装置结构框图,包括:数据采集模块:用于采集查询目标特征值对应的至少一个时空点信息;数据扩充模块:用于将每一个时空点信息进行对应的时空段数据扩充,得到待查询数据;获取指标量值模块,用于根据不同的目标特征值将待查询数据分类,在不同预设评价指标下,计算每一个目标特征值在不同查询日期内对应的多个指标量值;排序模块:用于根据综合排序规则得到查询值,并对所述查询值进行排序。
另外,本发明还提供一种多时空条件下查询排序的控制设备,包括:至少一个处理器;以及,与至少一个处理器通信连接的存储器;其中,存储器存储有可被至少一个处理器执行的指令,指令被至少一个处理器执行,以使至少一个处理器能够执行如实施例一所述的方法。
另外,本发明还提供一种计算机可读存储介质,计算机可读存储介质存储有计算机可执行指令,计算机可执行指令用于使计算机执行如实施例一所述的方法。
本发明通过综合考虑空间相似度和空间多样性,结合自信息量指标、相似度指标和空间多样性指标,并通过z-score评价方法对不同目标特征值的指标量值进行无量纲化,得到每一个目标特征值对应的查询值,实现多时空状态下目标特征的查询排序,即通过排序检索到满足时空查询条件的目标特征值,在不同评价指标下的指标量值,对其进行无量纲化后,进一步确定最为匹配的查询结果,本发明广泛适用于多种目标特征值查询,如终端信息、智能ic卡信息和身份证id信息等,综合空间相似度和空间多样性,查询匹配的结果更准确。
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。