一种基于遗传算法的支持向量机在线电压稳定性监测方法与流程
本发明属于电力系统领域,具体涉及一种基于遗传算法的支持向量机在线电压稳定性监测方法。
背景技术:
随着电网技术的飞速发展,今天的电网连接已经构成了一个高度互联的大系统。这样使得大型电力系统在监控和操作中更具复杂性。因为系统的某一部分的干扰可能影响整个电力系统。电力系统可观测性是电力系统实时监测、保护和控制的必要条件,它影响整个广域监测保护和控制系统(wideareamonitoringprotectionandcontrolsystems,wampc)的有效执行。近年来,电压崩溃是全球许多电力系统停电的主要原因。传统的电压稳定分析方法依赖于使用常规的潮流计算比如高斯-赛德尔(gauss-seidel)或者牛顿-拉夫森(newton-raphson)等静态分析方法。这些技术方法的主要缺陷是在最大负载点处的雅克比矩阵的奇异性。另外,诸如人工神经网络(artificialneuralnetwork,ann)、模糊逻辑、模式识别、支持向量机(supportvectormachine,svm)等机器学习技术已经被用来进行电力系统分析。比如将ann模型应用在在线电压安全评估中,使用了径向基函数(radialbasisfunction,rbf)网络来估算突发情况下电力系统电压稳定等级,hashemi运用小波变换来提取电压波形特性以估算电压稳定裕度等等。
技术实现要素:
针对传统的电压稳定分析方法最大的缺陷在于最大负载点处的雅克比矩阵的奇异性,并且计算量大、在线应用能力差;而新的机器学习技术比如anns在处理非线性回归问题时,受限于训练时间量和学习参数值,本发明提出了一种基于遗传算法的支持向量机在线电压稳定性监测的方法。
发明的目的是这样实现的:
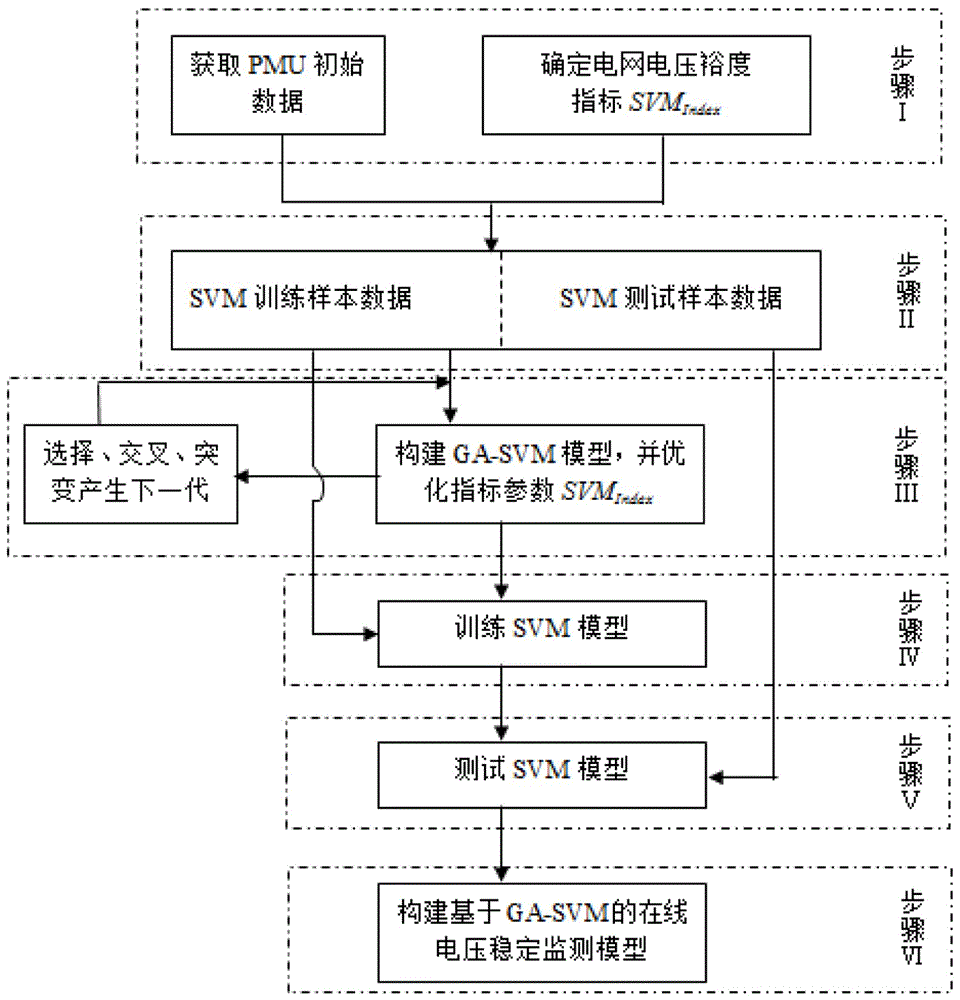
一种基于遗传算法的支持向量机在线电压稳定性监测方法,包括以下步骤:
步骤一:通过电网系统向量测量单元(phasormeasurementunit,pmu)装置获取初始的数据,并利用这些数据通过常规潮流计算以确定电网电压稳定裕度指标;
步骤二:结合pmu获取的初始数据和电网电压稳定裕度指标生成支持向量机的样本数据,并将样本数据分成训练样本数据和测试样本数据;
步骤三:构建基于遗产算法的支持向量机模型,并运用遗传算法(geneticalgorithm,ga)寻找最优的电网电压稳定裕度指标参数;
步骤四:通过寻找到的最优电网电压稳定裕度指标参数构建支持向量机(supportvectormachine,svm)模型,并结合训练样本对svm模型进行训练;
步骤五:训练结束后,运用测试样本数据对训练后的svm模型进行测试;
步骤六:测试通过后,运用所得svm模型构建基于遗传算法的支持向量机(geneticalgorithmbasedsupportvectormachine,ga-svm)模型的在线电网电压稳定监测模型。
在步骤一中,包括电压稳定裕度指标的获取以及pmu不确定性建模。
pmu测量的数据主要包括电压幅值和相角。
在步骤二中,进行常规潮流计算得到当前工作点的电压幅值、电压相角、有功功率、无功功率,然后利用这些计算得到的新的数据,构成vsm所需要的样本数据,并将样本数据按一定比例分成训练样本数据和测试样本数据。
在步骤三中,具体包括以下步骤:
(1)将ga-svm的参数分别包括正则化参数c,rbf核函数带宽σ2,以及不敏感损耗函数管半径ε,进行编码生成染色体x,则染色体x表示为:x={x1,x2,x3},其中x1、x2和x3分别表示ga-svm参数c、σ2和ε。(请问此处标红意思是?)
(2)运用交叉验证技术来进行优化的svm参数选择,在k-折交叉验证中,将数据集随机分成k份等量的子集,并用其中(k-1)份子集数据作为训练集来建立svm回归模型,svm参数的性能通过第k子集来测试,不断重复上述过程,使得每一个子集都作为测试子集进行一次测试。
(3)初始种群有20个随机产生的染色体组成,基于收敛时间和种群多样性之间的平衡性选择初始种群大小,并且计算每一个随机产生的染色体的适应值。
(4)运用选择、交叉和突变等方式创造新的种群以代替现有的种群,再通过旋轮线的方式将适应值更好的新染色体投入到重组池中。父本和母本染色体的基因进行交换,获取新的后代;
(5)重复第(3)步骤到第(4)步骤,这个过程一直重复直到基因数量达到限定值。
在步骤四中,具体包括以下步骤:运用步骤三中得到的最优ga-svm参数c、σ2和ε,构建ga-svm模型,并利用训练样本数据进行训练,对于不同的电网系统的样本数据,得到不同的ga-svm拟合模型。
在步骤五中,利用测试样本数据检验构建的ga-svm模型的适应度。
在步骤六中,基于ga-svm模型的在线电网电压稳定监测模型通过实际电网样本数据的检验,并完成对电网电压稳定裕度的预测。
采用上述技术方案,能带来以下技术效果:
1)本发明依托的电力系统是具有各种形式的电力能源接入的大区域电网系统,采样数据来自于整个大区域电网系统的所有pmus单元,还充分考虑了pmus采集数据的不确定性对ga-svm模型在线电网电压稳定性监测的影响,建立了pmu不确定性模型。按照ieee标准c37-118-1测量规范,利用tve同步向量标准来保证pmu的同步测量误差小于1%。
2)本发明提供的方法中采用svm机器学习技术,支持向量机(svm)是一种新的功能强大的机器学习技术,它基于统计学习理论的vc维理论和结构风险最小化原理,svm建立了最优网络结构,可以很好的在经验误差和vc置信区间找到平衡点。本发明很好的将svm技术应用在电力系统的在线电压监测系统中,具有很好的时效性,并且计算时间得到进一步的优化。
3)本发明提供的方法中,优点在于采用ga遗传算法来实现对svm建模参数的最优化,相较于网格搜寻(gridsearch,gs)方法和多层中枢感知的bp神经网络(multilayerperceptron-backpropagationneuralnetwork,mlp-bpnn),ga方法在回归接收机工作特性曲线(regressionreceiveroperatingcharacteristic,rroc)和过rroc曲域曲线(areaovertherroc-aoc)具有更为优越的性能,以及更短的计算时间。
附图说明
下面结合附图和实施例对本发明作进一步说明:
图1是本发明中基于ga-svm的在线电网电压稳定监测模型流程图;
图2是本发明具体实施例中实际的p-v曲线图。
具体实施方式
一种基于遗传算法的支持向量机在线电压稳定性监测方法,包括以下步骤:
步骤一:通过电网系统向量测量单元(phasormeasurementunit,pmu)装置获取初始的数据,并利用这些数据通过常规潮流计算以确定电网电压稳定裕度指标;
步骤二:结合pmu获取的初始数据和电网电压稳定裕度指标生成支持向量机的样本数据,并将样本数据分成训练样本数据和测试样本数据;
步骤三:构建基于遗产算法的支持向量机模型,并运用遗传算法(geneticalgorithm,ga)寻找最优的电网电压稳定裕度指标参数;
步骤四:通过寻找到的最优电网电压稳定裕度指标参数构建支持向量机(supportvectormachine,svm)模型,并结合训练样本对svm模型进行训练;
步骤五:训练结束后,运用测试样本数据对训练后的svm模型进行测试;
步骤六:测试通过后,运用所得svm模型构建基于遗传算法的支持向量机(geneticalgorithmbasedsupportvectormachine,ga-svm)模型的在线电网电压稳定监测模型。
步骤一中,包括电压稳定裕度指标、pmu不确定性建模两个方面,分别描述如下:
(1)电压稳定裕度指标,电网电压稳定分析的主要目标是确定电网系统当前工作点是否稳定,是否满足各个操作标准。而电压功率曲线(如图2所示)可以用来获取电网稳定裕度。假设当前工作点传递给负载的有功功率为pc,而最大有功功率为pm,则电压稳定裕度(vsm)可以表示为:
vsmi=pm,i-pc,i,i=1,2,…,l(1)
其中:l表示该电网系统的总的负载支路,i表示其中第i条支路。
则电网电压稳定裕度指标可以转化为:
vsmindex在0-1之间变化,如图2所示。当工作点移向电压崩溃点时,由公式2所定义的vsmindex接近于0。为了确定电压崩溃点,pv曲线由连续潮流技术(cpf)得来,因为连续潮流技术可以包含pv曲线工作尖点(即电压崩溃点)。
(2)pmu不确定性建模,pmu测量的数据主要包括电压幅值和相角,用来对vsmindex进行预测。尽管pmu的测量精度很高,但是在测量过程中总是存在测量误差的可能,依据ieee标准c37-118-1测量规范,这些不确定性在同步向量测量中,必须考虑向量总误差(totalvectorerror),向量总误差(tve)在同步向量测量中是一个非常重要的标准,其值在稳定状态时应小于1%。这里向量总误差tve可以表示为:
其中:xr*和xi*分别表示测量值的实部和虚部,xr和xi表示理想值的实部和虚部。
将实际的电压幅值误差δvi和向量误差δθi导入向量总误差公式tve,这样选择δvi和δθi使得tve≤1%。
图1所示步骤二中,所述的样本数据,首先通过图1所示步骤ⅰ中pmus获得的数据,进行常规潮流计算得到当前工作点的电压幅值、电压相角、有功功率以及无功功率。然后利用这些计算得到的新的数据,构成vsm所需要的样本数据,并将样本数据按一定比例分成训练样本数据和测试样本数据。
图1所示步骤三中,所述的ga-svm模型构建以及ga-svm参数优化,分下面几步完成:
(1)将ga-svm的参数分别包括正则化参数c,rbf核函数带宽σ2,以及不敏感损耗函数管半径ε,进行编码生成染色体x,则染色体x表示为:
x={x1,x2,x3},其中x1、x2和x3分别表示ga-svm参数c、σ2和ε。
(2)为了防止ga-svm模型的过拟合或者欠拟合,运用交叉验证技术来进行优化的svm参数选择,在k-折交叉验证中,将数据集随机分成k份等量的子集,并用其中(k-1)份子集数据作为训练集来建立svm回归模型。svm参数的性能通过第k子集来测试。不断重复上述过程,使得每一个子集都作为测试子集进行一次测试。本发明中采用5-折交叉验证,其拟合函数可以表示为:
minf=mapecross_val(4)
其中:m是样本数据训练集,ai实际值和pi是预测值,mapecross_val的解越小,越有机会在下一代中存活。
(3)初始种群有20个随机产生的染色体组成,基于收敛时间和种群多样性之间的平衡性选择初始种群大小,且由公式(4)和(5)计算每一个随机产生的染色体的适应值。
(4)运用选择、交叉和突变等方式创造新的种群以代替现有的种群,再通过旋轮线的方式将适应值更好的新染色体投入到重组池中。父本和母本染色体的基因进行交换,获取新的后代以期得到更好的解决方案,每一组染色体创造新的染色体的可能性设定为0.8,通过突变来改变染色体编码的几率设定为0.05。
(5)第(3)步到第(4)步,这个过程一直重复直到基因数量达到限定值。
为了全面检验ga-svm模型的性能,前述的mape、nmse和wia作为衡量指标,mape的值越小,表示预测值与实际值越接近;wia表征回归度,它在0-1之间变化,越接近于1表示预测值越精确。
图1所示步骤四中,运用图1所示步骤三中得到的最优ga-svm参数c、σ2和ε,构建ga-svm模型,并利用训练样本数据进行训练,使得ga-svm模型具有更好的适应度。对于不同的电网系统的样本数据,可以得到不同的ga-svm拟合模型如表1所示。
表1
图1所示步骤五中,利用测试样本数据检验构建的ga-svm模型的适应度,检验情况如表2所示。
表2
图1所示步骤六中,基于ga-svm模型的在线电网电压稳定监测模型通过实际电网样本数据的检验,并完成对电网电压稳定裕度的预测,通过表3和表4中的表的比较可以看出所构建的基于ga-svm模型的在线电网电压稳定监测模型优于现有的其他电压监测模型。
表3
表4
- 还没有人留言评论。精彩留言会获得点赞!