列车运行实绩数据驱动的运行图冗余时间布局获取方法与流程
本发明属于铁路交通技术领域,具体涉及一种列车运行实绩数据驱动的运行图冗余时间布局获取方法。
背景技术:
铁路列车运行图(以下简称列车运行图)是用以表示列车在铁路区间运行及在车站到发或通过时刻的技术文件,是全路组织列车运行的基础。
规定各车次列车占用区间的程序,列车在每个车站的到达和出发(或通过)时刻,列车在区间的运行时间,列车在车站的停站时间以及机车交路、列车重量和长度等。是列车运行时刻表的图解,规定各次列车按一定的时刻在区间内运行及在车站到、发和通过。列车运行图是列车运行的时间与空间关系的图解,它表示列车在各区间运行及在各车站停车或通过状态的二维线条图。
列车运行图中预留的车站及区间缓冲时间、运行线间冗余时间(统称冗余时间)是调度员可以用来恢复晚点的资源。目前冗余时间布局主要依靠对历史布局方案的简单统计或按照区间运行时长或车站停站时长比例设置冗余时间,缺乏对其晚点恢复能力的系统研究,难以为实时调度指挥提供支撑。根据国际铁路联盟2009年发布的指南“uiccode451-1or”,冗余时间的布局需根据列车运行距离或行程时间平均设定,采用[min/km]或[%]计算冗余时间布局方案。在已有研究中,单列车的区间冗余时间(撒点时间)布局被普遍认为应当与列车的区间距离成比例,平均加权距离(weightedaveragedistance,wad)被提出来作为冗余时间的布局依据,但这种统计方案不区分列车、车站、区间等,得到的方案不具有针对性;现有技术中,由于列车每次晚点时间和情况不同,对于一张计划运行图,很难找到各区间、车站预先分配的冗余时间值,使得各次晚点列车无法进行恢复最大化。
技术实现要素:
为了解决现有技术存在的上述问题,本发明目的在于提供一种列车运行实绩数据驱动的运行图冗余时间布局获取方法,根据列车运行晚点数据找到路网的关键车站和区间即冗余时间利用率大、晚点发生频率高的区间、车站,发现影响冗余时间运用效率的关键参数,能够据此实现冗余时间的进一步优化,增强运行图的鲁棒性,用于找到各区间、车站预先分配的冗余时间值,使得各次晚点列车进行恢复,用于解决现有技术存在的难以为实时调度指挥提供支撑,方案不具有针对性以及晚点列车无法进行恢复最大化的问题。
本发明所采用的技术方案为:
列车运行实绩数据驱动的运行图冗余时间布局获取方法,包括:
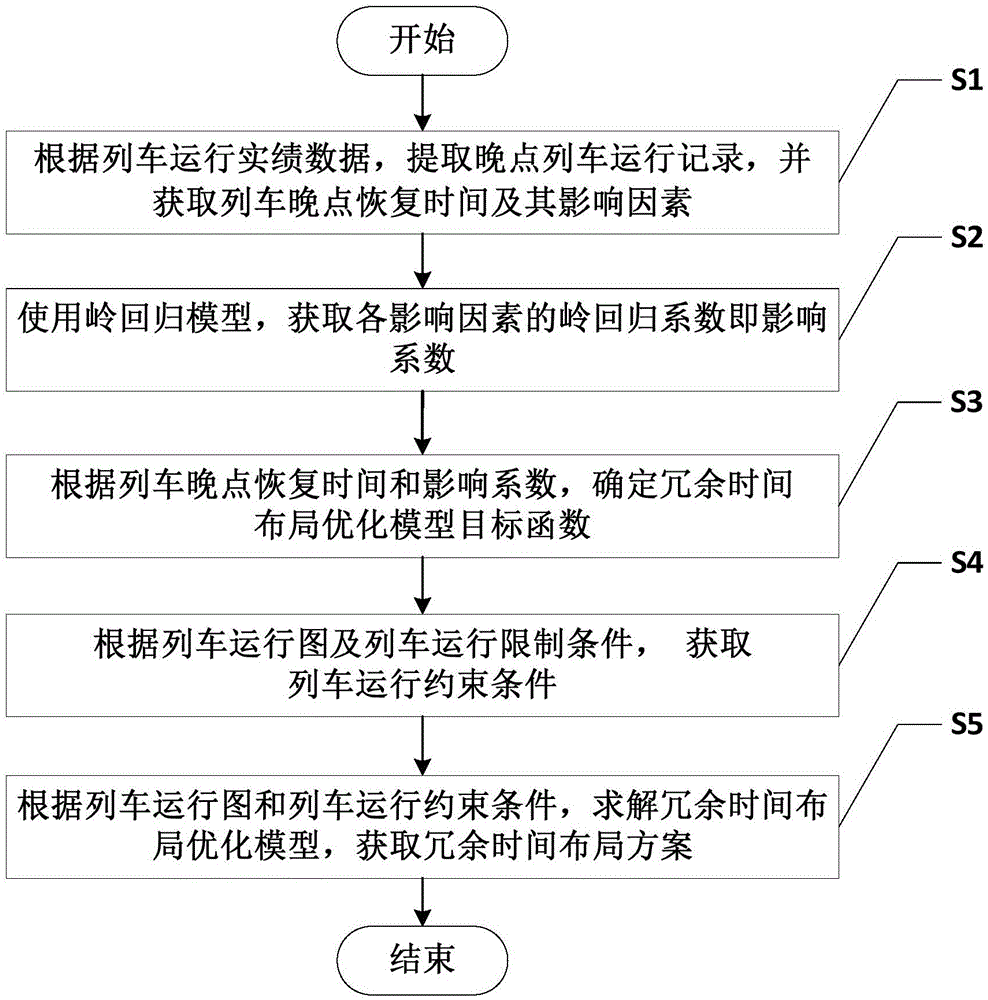
s1:根据列车运行实绩数据,提取晚点列车运行记录,并获取列车晚点恢复时间及其影响因素;
s2:使用岭回归模型,获取各影响因素的岭回归系数即影响系数;
s3:根据列车晚点恢复时间和影响系数,确定冗余时间布局优化模型的目标函数;
s4:根据列车运行图及列车运行限制条件,获取列车运行约束条件;
s5:根据列车运行图和列车运行约束条件,求解冗余时间布局优化模型,获取冗余时间布局方案。
进一步地,步骤s1中,列车晚点恢复时间的公式为:
式中,rt为晚点恢复时间;rq、rs分别为各区间、车站被利用的冗余时间;rq、rs分别为各区间、车站预先分配的冗余时间值;i、q、s分别为当前、区间以及车站变量;n为车站总数。
进一步地,步骤s1中,列车晚点恢复时间的影响因素包括:
总区间冗余时间bte,公式为:
式中,btem为列车m的总区间冗余时间;
总车站冗余时间bta;
式中,btam为列车m的总车站冗余时间;
列车初始晚点时间pd。
进一步地,步骤s2中包括如下步骤:
s2-1:根据岭回归模型的损失函数,使用随机梯度下降法对惩罚项的权重模型训练,得到最优岭回归模型;
s2-2:根据最优岭回归模型和影响因素,获取岭回归系数即影响系数。
进一步地,岭回归模型的损失函数的公式为:
式中,j(β)为岭回归模型的损失函数;
进一步地,步骤s3中,冗余时间布局优化模型的目标函数为最大化晚点恢复时间,其公式为:
max(rtm)=max(a·btam+b·btem)
式中,max(rtm)为最大化晚点恢复时间;btem、b分别为列车m的总区间冗余时间和区间冗余时间岭回归系数;btam、a分别为列车m的总车站冗余时间和车站冗余时间岭回归系数。
进一步地,步骤s4中,列车运行约束条件包括:
列车各站停站时间约束:
式中,btam为列车m的总车站冗余时间;
列车速度约束:
式中,btem为列车m的总区间冗余时间;
列车总旅行时间约束:
式中,tstart、tstop为列车启动、停止时分;
追踪间隔约束和车站不同时发车间隔约束:
式中,s为车站顺序,i,j∈{1,2,...,|s|};r为列车运行顺序;xm-1,k、xm,k为列车m-1,m在车站k的停车指示值,停车为1,不停为0;i1、i2分别为最小区间追踪、最小车站不同时到发间隔时间;
进一步地,步骤s4中,列车运行限制条件包括当前列车运行的最大速度及当前列车最小追踪间隔时间。
进一步地,步骤s5包括如下步骤:
s5-1:确定列车运行车站,将运行车站视作到发时间点不改变的车站;
s5-2:根据列车运行约束条件和历史列车运行数据,得到列车参数;
s5-3:将得到的列车参数输入冗余时间布局优化模型,得到列车的区间、车站冗余时间分配总和,并将其作为冗余时间布局方案进行输出。
进一步地,步骤s5-3中,冗余时间布局方案的获取方法,包括如下步骤:
a-1:在旅行时间不超过最大运行时间条件下将区间总冗余时间按照其前一车站的出发晚点频率分配至各区间;
a-2:判断是否存在余下的冗余时间,若是则将余下的冗余时间按照同样的方法分配至未达到最大运行时间的区间,并进入步骤a-3,否则直接进入步骤a-4;
a-3:判断是否存在残余的冗余时间,若是则将残余的冗余时间按各站的到达晚点频率分配至各车站,并进入步骤a-4,否则直接进入步骤a-4;
a-4:将列车的区间、车站冗余时间分配总和作为冗余时间布局方案进行输出。
本发明的有益效果为:
(1)本方案避免了现有分配方案未考虑各区间、车站的冗余时间利用特征,未对区间、车站做区分,造成线路能力或列车运行速度不必要的损失的问题;
(2)本方案针对任一既有列车计划运行图,基于其历史冗余时间利用和晚点频率,在不改变列车始发、终到时间的情况下局部优化各区间、车站冗余时间布局方案,实现晚点列车的恢复,提高了方案的适用性和实用性;
(3)经过本方案优化后的运行图,列车开行对数不变,但其可以针对不同列车、区间、车站的冗余时间需求分配不同的冗余时间值,提高了方案的针对性;
(4)在我国现阶段,随着高速铁路网络化逐渐形成,各干线线路能力趋于饱和即列车开行数趋于上限,提出的冗余时间布局方案由于不会造成能力损失,在能力饱和的高速铁路线路上实施优势尤为明显,为铁路运行的实时调度指挥提供支撑。
附图说明
图1是列车运行实绩数据驱动的运行图冗余时间布局获取方法流程图;
图2是获取各影响因素的岭回归系数即影响系数的方法流程图;
图3是求解冗余时间布局优化模型的方法流程图;
图4是冗余时间布局方案的获取方法图;
图5是武广高速铁路图;
图6是晚点列车实际恢复情况图;
图7是各区间平均运行时间对比图;
图8是各车站停站时间对比图;
图9是各区间、车站冗余时间利用率图;
图10是不同惩罚项权重下的岭回归模型训练结果图;
图11是各区间晚点发生频率分布图;
图12是各车站晚点发生频率分布图;
图13是原列车运行图和冗余时间布局方案的优化后列车运行图对比图;
图14是优化后晚点恢复提升情况图。
具体实施方式
下面结合附图及具体实施例对本发明做进一步阐释。
实施例1:
如图1所示,列车运行实绩数据驱动的运行图冗余时间布局获取方法,包括:
s1:根据列车运行实绩数据,提取晚点列车运行数据,并获取列车晚点恢复时间及其影响因素;
本实施例所用的列车运行实绩数据来源于中国铁路广州局集团有限公司(以下简称广铁集团)所管辖的武广高速铁路,如图5所示,武广高速铁路全长1069km,共设18个车站,设计时速350km/h,运营速度310km/h,所有列车运行实绩数据均从广铁集团高铁调度中心列车监督系统获得,该系统记录了每天各次列车的车次、到发通过车站、每次列车在每个车站的图定与实际到发通过时刻、最高列车运行速度、平均行车速度等,实施例中使用的数据包括武广高速铁路广州南站至长沙南站共12个车站、11个区间,从2015年3月到2016年11月的列车运行记录,该时段内,武广高速铁路开行列车64547列,该线路最小列车追踪间隔时间为3分钟,车站列车不同时到发时间为5分钟,如图6所示的三列晚点列车实际恢复情况图,如列车g6014从gzn到css总共恢复11分钟晚点时间。
列车晚点恢复时间的公式为:
式中,rt为晚点恢复时间;rq、rs分别为各区间、车站被利用的冗余时间;rq、rs分别为各区间、车站预先分配的冗余时间值;i、q、s分别为当前、区间以及车站变量;n为车站总数;
运行图预留冗余时间被认为是列车晚点恢复的资源,如图7和图8所示的数据中晚点列车在各区间、车站的计划所用时间和实际所用时间情况,各区间和车站图定和实际利用时间对比显示:晚点列车在区间和车站的实际运行时间和停留时间均小于图定时间,即区间冗余时间和车站冗余时间得到利用。为了进一步分析各区间、车站的冗余时间利用情况,计算了各区间、车站的冗余时间利用率,其结果如图9所示,图9结果表明:区间冗余时间利用率明显高于车站冗余时间利用率,基于图7、图8与9的结果发现:武广高速铁路列车运行图预留车站冗余时间多余预留区间冗余时间,但区间冗余时间利用与明显高于车站冗余时间利用率;
冗余时间利用率的计算公式为:
其中,
基于以上统计分析及已有知识,对于任一列车m,确定总区间冗余时间bte以及总车站冗余时间bta为晚点恢复的影响因素,rt与列车晚点时间pd大小直接相关,其决定了列车晚点恢复的上限;
列车晚点恢复时间的影响因素包括:
总区间冗余时间bte,公式为:
式中,btem为列车m的总区间冗余时间;
总车站冗余时间bta;
式中,btam为列车m的总车站冗余时间;
列车初始晚点时间pd;
基于确定的rt影响因素,从列车运行实绩中提取得到3074个样本,样本示例如表1rt及其影响因素示例表所示;
表1
s2:使用岭回归模型,获取各影响因素的岭回归系数即影响系数,如图2所示,包括如下步骤:
s2-1:根据岭回归模型的损失函数,使用随机梯度下降法对惩罚项的权重模型训练,得到最优岭回归模型;
岭回归模型的损失函数的公式为:
式中,j(β)为岭回归模型的损失函数;
岭回归模型中,不同的自变量共线性程度对α的需求不同,因此,建立岭回归模型最重要的工作就是确定其惩罚项的权重,为了找到适合的α,基于交叉验证利用随机梯度下降法对模型进行了不同α的训练,其结果如图10所示,选择α=2.7×103为惩罚项的权重;
s2-2:根据最优岭回归模型和影响因素,获取岭回归系数即影响系数,如表2变量岭回归系数表所示;
表2
s3:根据列车晚点恢复时间和影响系数,确定冗余时间布局优化模型的目标函数;
冗余时间布局优化模型的目标函数为最大化晚点恢复时间,其公式为:
max(rtm)=max(a·btam+b·btem)
式中,max(rtm)为最大化晚点恢复时间;btem、b分别为列车m的总区间冗余时间和区间冗余时间岭回归系数;btam、a分别为列车m的总车站冗余时间和车站冗余时间岭回归系数;
s4:根据列车运行图及列车运行限制条件,获取列车运行约束条件;其中,列车运行限制条件包括当前列车运行的最大速度及当前列车最小追踪间隔时间;列车最小追踪间隔时间为追踪运行列车之间的最小间隔时间,在铁路自动闭塞(高速铁路均采用该模式)区段,一个站间区间内同方向可有两列或两列以上列车,以闭塞分区间隔运行,称为追踪运行。
列车运行约束条件包括:
列车各站停站时间约束:
式中,btam为列车m的总车站冗余时间;
列车速度约束:
式中,btem为列车m的总区间冗余时间;
列车总旅行时间约束:
式中,tstart、tstop为列车启动、停止时分;
追踪间隔约束和车站不同时发车间隔约束:
式中,s为车站顺序,i,j∈{1,2,...,|s|};r为列车运行顺序;xm-1,k、xm,k为列车m-1,m在车站k的停车指示值,停车为1,不停为0;i1、i2分别为最小区间追踪、最小车站不同时到发间隔时间;
s5:根据列车运行图和列车运行约束条件,求解冗余时间布局优化模型,获取冗余时间布局方案,如图3所示,包括如下步骤:
s5-1:确定列车运行车站,将运行车站视作到发时间点不改变的车站;
s5-2:根据列车运行约束条件和历史列车运行数据,得到列车参数;
表3为各站停站时间标准表,表4为各区间运行时间标准表,选择武广高速铁路gzs-css区段为研究对象,其中包含12个车站与11个区间,该区段日行列车112列,所有列车均为crh3型动车组。选择计划运行图中早高峰24列车作为优化对象,表5为列车运行数据表;
表3
表4
表5
s5-3:将得到的列车参数输入冗余时间布局优化模型,得到列车的区间、车站冗余时间分配总和,并将其作为冗余时间布局方案进行输出;
冗余时间布局方案的获取方法,如图4所示,包括如下步骤:
a-1:在旅行时间不超过最大运行时间条件下将区间总冗余时间按照其前一车站的出发晚点频率分配至各区间,列车晚点频率如图11和图12所示;
a-2:判断是否存在余下的冗余时间,若是则将余下的冗余时间按照同样的方法分配至未达到最大运行时间的区间,并进入步骤a-3,否则直接进入步骤a-4;
a-3:判断是否存在残余的冗余时间,若是则将残余的冗余时间按各站的到达晚点频率分配至各车站,并进入步骤a-4,否则直接进入步骤a-4;
a-4:将列车的区间、车站冗余时间分配总和作为冗余时间布局方案进行输出,如图13所示,优化后列车晚点恢复提升值如图14所示,计算结果显示优化后24列车平均晚点恢复提升12.9%。
本发明提供了一种列车运行实绩数据驱动的运行图冗余时间布局获取方法,根据列车运行晚点数据找到路网的关键车站和区间即冗余时间利用率大、晚点发生频率高的区间、车站,发现影响冗余时间运用效率的关键参数,据此实现冗余时间的进一步优化,增强运行图的鲁棒性,找到各区间、车站预先分配的冗余时间值,使得各次晚点列车进行恢复,解决了现有技术存在的难以为实时调度指挥提供支撑,方案不具有针对性以及晚点列车无法进行恢复最大化的问题。
- 还没有人留言评论。精彩留言会获得点赞!