一种文献自动分类方法与流程
本发明涉及文献分类领域,特别是涉及一种文献自动分类方法。
背景技术:
随着期刊电子化的发展,针对数字文献的分类标引工作长期以来都是由编目人员手工去完成,既费时又费力。且由于信息的模糊性以及数字文献种类、数量的剧增,仅靠提高编目人员的业务素质来保证文献分类标引的准确性是不现实的。而通过计算机直接对文献信息进行过滤、分类,把用户真正需要的部分提交给用户,就能把用户从烦琐的文献处理工作中解放出来,更加快捷地区分不同类型文献,使大量的无序的文献系统化,极大地提高信息的利用率。通过文献自动分类系统,能够很好地帮助用户整理、获取信息,在提高信息检索速度和准确率方面意义重大,且具有很重要的研究价值。
目前,中图法框架下的文献自动分类方法主要分为两种,一种是基于知识库的分类方法,一种是基于机器学习的分类方法。
其中,基于知识库的分类方法,王爽以已有的标引经验数据为基础,从构建知识库,自动分词,特征项选取,特征项权重计算,分类算法几个方面进行论述,最后设计并实现了一个基于知识库的文档自动分类系统。张玉芳以数据库中标引经验数据为基础,结合《中图法》的类目层次结构,构建了一个多层次知识库,并基于该知识库实现了自顶向下的多层次文档自动分类。何琳等人,在知识库方法的基础之上,通过引进机器学习的方法测定关键词和类目概念之间的关联度,构建关键词、分类号、归属度三元组矩阵的方法进行分类匹配。这项研究也标示着单靠知识库的方法已经不能完全解决《中图法》分类体系下的自动分类问题。基于机器学习的分类方法,中国知网的孙雄勇等,利用cnki海量的己经经过人工标注的期刊语料,对近20万的短语词汇进行训练,为每一个短语赋予相应的一个或多个中图分类号,并训练获得每一个短语的相应权重。然后在此基础上,计算新文献的中图分类号,并引入了置信度概念,实现了分离出高准确率结果集。赵纪元等人研究了基于中图法的学术文献自动分类方法,该方法结合了chi特征选择、后验概率训练以及tf-idf概率加权等方法,实现了对50余万篇学术期刊的自动分类。同时研究了以二元词汇作为特征进一步修正上述结果,在保证正确率基本不变的情况下,使分类的输出比例大大提升。在《中图法》分类体系下应用机器学习方法进行自动分类的研究,较早的有文献,但试验材料中使用的文本分别是新闻稿、网页和期刊论文。直到2010年以后才有文献针对图书进行自动分类研究。王昊等人尝试将bp神经网络和支持向量机等机器学习算法引入到书目分类中,建立了面向中图法的基于机器学习的书目层次分类系统模型,提出了采用特征加权方式描述书目和浅层次分类体系构建的设计思路,并通过大规模实验验证了该模型的可行性和合理性,基本上解决了没有主题标注情况下书目的自动分类问题。但是机器学习方法存在词-文本矩阵维度较高、不易计算等缺陷。
技术实现要素:
本发明的目的是提供一种文献自动分类方法,实现对文献的自动快速分类。
为实现上述目的,本发明提供了如下方案:
一种文献自动分类方法,所述方法包括:
构建词典数据库;
获取待分类文献的关键词;
根据所述待分类文献的关键词在所述词典数据库中进行查找,得到待分类文献关键词的分类号信息;
根据所述待分类文献的关键词的分类号信息确定待分类文献的分类号,实现文献的自动分类。
可选的,所述构建词典数据库具体包括:
获取文献,提取文献中的关键词以及分类号;
对所述文献中的关键词进行数据清洗;
将所述文献中的关键词以及分类号一一对应;
对所述数据清洗后的文献中的关键词进行位置标记;
对所述分类后的文献中的关键词进行关键词位置权重赋值,得到文献中的关键词位置权重;
根据所述文献中的关键词、所述文献中的关键词对应的分类号以及所述文献中的关键词的位置权重构建词典数据库。
可选的,所述数据清洗具体包括:
剔除与文献类别无关的所述文献中的关键词;
根据所述文献类别相关性对剔除后的所述文献中的关键词进行排序,并采用符号分隔相邻两所述关键词;
剔除经排序后的前5个以外的所述文献中的关键词;
将前5个所述文献中的关键词中的繁体字转换为简体字。
可选的,采用数字序号方式对所述数据清洗后的文献中的关键词进行位置标记。
可选的,将所述所述数据清洗后的文献中的关键词位置标记为①、②、③、④、⑤。
可选的,所述对所述分类后的文献中的关键词进行关键词位置权重赋值,得到文献中的关键词位置权重具体包括:
对处于位置①至⑤的关键词,分别赋予不同的位置权重,得到多组位置权重值;
任取其中5组位置权重值;
采用样本量实验法对多组权重值的分类准确率进行检验,得到检验结果;
根据所述检验结果,选取准确率最高的一组关键词位置权重。
可选的,所述根据所述待分类文献的关键词的分类号信息确定待分类文献的分类号,实现文献的自动分类具体采用以下公式:
对于关键词w,在m篇文献中出现,所对应的分类号有n种,分别为c1,c2,…cn,关键词w对应分类号c1的权重计算公式为:
其中weight(w,c1)表示待分类文献中关键词w对于分类号c1的权重,posweight(w)表示关键词w的位置权重,m表示待分类文献的数量,k表示文献,j表示关键词;
分类号c1的权重为:
weight(c1)表示待分类文献对于分类号c1的权重,weight(wi,c1)表示待分类文献中第i个关键词wi对于分类号ci的权重,posweight(wi)表示关键词wi的位置权重;
分别计算其余分类号的权重,选取权重最大的作为待分类文献的分类号。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明中的文献自动分类方法,首先获取文献关键词,并对所述关键词进行数据清洗,数据清洗后的关键词能够剔除与关键词无关的词句,大大加快了了后续对关键词的分类速度和准确度;然后再对所述清洗后的关键词进行分类;对所述分类后的关键词进行位置标记;对所述分类后的关键词进行位置权重赋值以及分类号权重赋值,最终得到词典数据库,将待分类的文献以及关键词在词典数据库中进行查找,进而实现了文献的自动分类。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例文献自动分类方法流程图;
图2为本发明实施例关键词位置权重比较结果图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种文献自动分类方法,实现对文献的自动快速分类。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
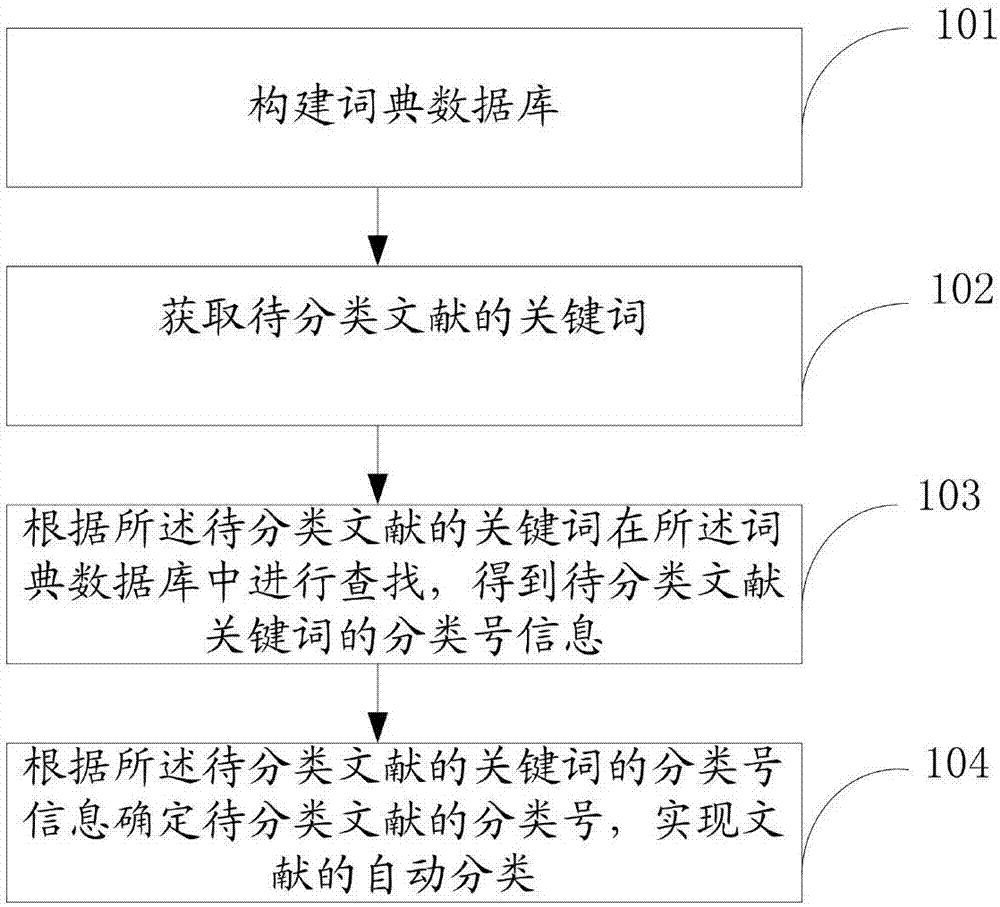
图1为本发明实施例文献自动分类方法流程图,如图1所示,所述方法包括:
步骤101:构建词典数据库;
步骤102:获取待分类文献的关键词;
步骤103:根据所述待分类文献的关键词在所述词典数据库中进行查找,得到待分类文献关键词的分类号信息;
步骤104:根据所述待分类文献的关键词的分类号信息确定待分类文献的分类号,实现文献的自动分类。
具体的步骤101中,所述构建词典数据库具体包括:
获取文献,提取文献中的关键词以及分类号;
对所述文献中的关键词进行数据清洗;
将所述文献中的关键词以及分类号一一对应;
对所述数据清洗后的文献中的关键词进行位置标记;
对所述分类后的文献中的关键词进行关键词位置权重赋值,得到文献中的关键词位置权重;
根据所述文献中的关键词、所述文献中的关键词对应的分类号以及所述文献中的关键词的位置权重构建词典数据库。
其中,所述数据清洗具体包括:
剔除与文献类别无关的所述文献中的关键词;
根据所述文献类别相关性对剔除后的所述文献中的关键词进行排序,并采用符号分隔相邻两所述关键词;
剔除经排序后的前5个以外的所述文献中的关键词;
将前5个所述文献中的关键词中的繁体字转换为简体字。
具体的,剔除与文献类别无关的所述关键词,例如,文献中“围手术期%抗菌药物%调查分析”其中,“研究”“分析”“报告”等词语,无法判断出到底属于哪一类的关键词。
按照与所述文献类别相关性对剔除后的所述关键词进行排序,并采用符号分隔相邻两所述关键词;例如,最能够体现某一类文献的词,按照疾病名称>疾病人群>药物名称>疾病监测方法>疾病治疗目的进行排序,如果没有包含在内的该类别中的词语,则按照自身的医学知识进行排序。
再例如,“学龄前儿童%龋齿%护理”,在r78(口腔科学)下,龋齿为能体现该类别的词,应将其提前,剩下的词按疾病名称>疾病人群>药物名称>疾病监测方法>疾病治疗目的进行排序。
再例如,“机械通气%呼吸衰竭%人机对抗”这组关键词在r5内科学大类下,呼吸衰竭应该放在最前面。
具体的,剔除经排序后的前5个以外的所述关键词可解释为,一般情况下,为了节省计算量,一篇文献的关键词不超过5个,在进行排序后,只保留前5个关键词。
可选的,采用数字序号方式对所述数据清洗后的文献中的关键词进行位置标记,具体是将所述所述数据清洗后的文献中的关键词位置标记为①、②、③、④、⑤。
可选的,所述对所述分类后的文献中的关键词进行关键词位置权重赋值,得到文献中的关键词位置权重具体包括:
对处于位置①至⑤的关键词,分别赋予不同的位置权重,得到多组位置权重值;
任取其中5组位置权重值;
采用样本量实验法对多组权重值的分类准确率进行检验,得到检验结果;
根据所述检验结果,选取准确率最高的一组关键词位置权重。
例如,如图2所示,图2为本发明实施例关键词位置权重比较结果图,对于位置①到⑤,分别赋予不同的位置权重值,经多组比较,选取最具代表性的5组位置权重取值,(1)5,4,3,2,1;(2)5、4、1.5、1、0.5;(3)5、3、1.5、1、0.5;(4)5、4.5、1.5、1、0.5;(5)5、5、1.5、1、0.5。通过采取样本试验的方法,可确定,第(2)组的准确率最高,为71.52%,即对于位置①到⑤,位置权重取值为5、4、1.5、1、0.5。
具体的步骤104中,根据所述待分类文献的关键词的分类号信息确定待分类文献的分类号,实现文献的自动分类,具体采用以下公式:
对于关键词w,在m篇文献中出现,所对应的分类号有n种,分别为c1,c2,…cn,关键词w对应分类号c1的权重计算公式为:
其中weight(w,c1)表示待分类文献中关键词w对于分类号c1的权重,posweight(w)表示关键词w的位置权重,m表示待分类文献的数量,k表示文献,j表示关键词;
分类号c1的权重为:
weight(c1)表示待分类文献对于分类号c1的权重,weight(wi,c1)表示待分类文献中第i个关键词wi对于分类号ci的权重,posweight(wi)表示关键词wi的位置权重;
分别计算其余分类号的权重,选取权重最大的作为待分类文献的分类号。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!