一种基于图模型的词义消歧方法和系统与流程
本发明涉及自然语言处理技术领域,具体地说是一种基于图模型的词义消歧方法和系统。
背景技术:
词义消歧是指根据歧义词所处的特定上下文环境确定其具体词义,它是自然语言处理领域的一项基础性研究,对机器翻译、信息抽取、信息检索、文本分类、情感分析等上层应用有着直接影响。无论是中文还是英文等其他西方语言,一词多义的现象是普遍存在的。
传统的基于图模型进行中文词义消歧任务处理的方法主要利用了一种或多种中文知识资源,受知识资源不足问题的困扰,词义消歧性能较低。故如何结合多种中英文资源,优势互补,实现充分挖掘资源中的消歧知识,提升词义消歧性能是目前急需解决的技术问题。
专利号为cn105893346a的专利文献公开了一种基于依存句法树的图模型词义消歧方法,其步骤为:1.对句子进行预处理并提取待消歧的实词,主要包括规范化处理、断词及词形还原等;2.对句子进行依存句法分析,构建其依存句法树;3.获得句子中词语在依存句法树上的距离,即最短路径的长度;4.根据知识库,为句子中词语的词义概念构建消歧知识图;5.根据消歧知识图中词义结点之间的语义关联路径长度、关联边的权重、路径端点在依存句法树上的距离,计算各个词义结点的图评分值;6.为每个歧义词,选择图评分值最大的词义作为正确词义。但是该技术方案利用babelnet中蕴含的语义关联关系,而不是hownet中的语义知识;其适用于英文词义消歧工作,但对于中文并不适用,且不能解决如何结合多种中英文资源,优势互补,实现充分挖掘资源中的消歧知识,提升词义消歧性能的问题。
技术实现要素:
本发明的技术任务是提供一种基于图模型的词义消歧方法和系统,来解决如何结合多种中英文资源,优势互补,实现充分挖掘资源中的消歧知识,提升词义消歧性能的问题。
本发明的技术任务是按以下方式实现的,一种基于图模型的词义消歧方法,包括如下步骤:
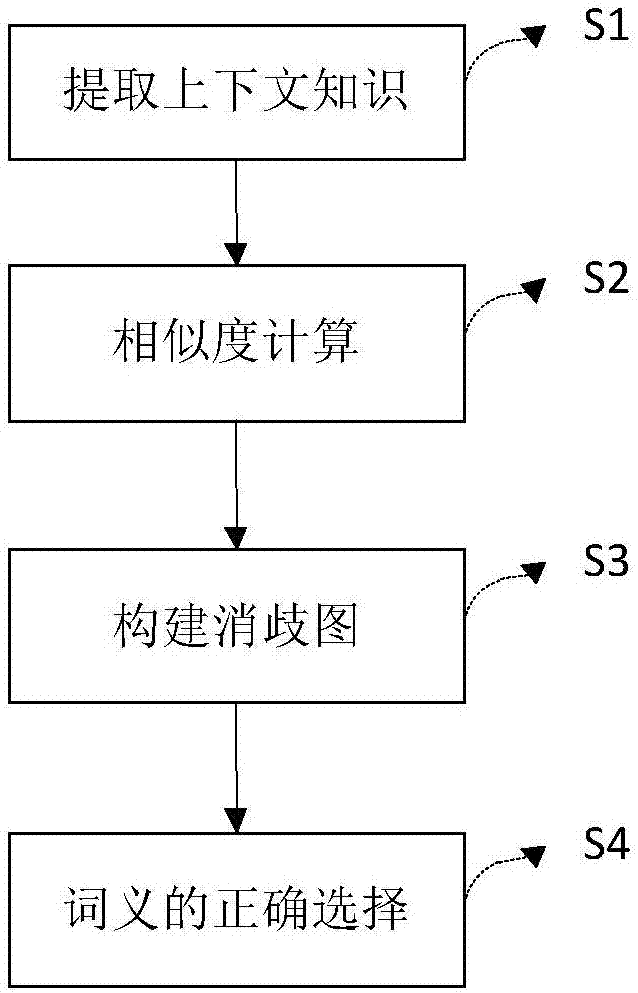
s1、提取上下文知识:对歧义句进行词性标注,提取实词作为上下文知识,实词指名词、动词、形容词、副词;
s2、相似度计算:分别做基于英文的相似度计算、基于词向量的相似度计算和基于hownet的相似度计算;
s3、构建消歧图:利用模拟退火算法对相似度进行权重优化,得到融合后的相似度,进而以词语概念为顶点,概念间的语义关系为边,边的权重为融合后的相似度,构建出消歧图;
s4、词义的正确选择:通过图评分对图中候选词义进行打分,进而得到候选词义的得分列表,选择得分最高者作为正确词义。
作为优选,所述步骤s2中相似度计算具体步骤如下:
s201、基于英文的相似度计算:对上下文知识进行hownet词义信息标注,并做词义映射处理,得到英文词语集合;再利用基于词向量和知识库的词语相似度计算算法,对所得英文词语进行相似度计算;另,考虑到hownet是双语的,这里词义映射处理直接获取hownet中的英文词语信息;
s202、基于词向量的相似度计算:sogou全网新闻语料共计1.43gb,使用google的word2vec工具包在该语料上训练词向量,得到词向量文件,根据词向量文件获取给定两个词语对应的词向量,计算词向量间的余弦相似度作为两者的相似度;
s203、基于hownet的相似度计算:利用hownet对上下文知识进行词义信息标注,采用词语词汇和概念编号的形式,利用hownet提供的概念相似度工具包计算各词义间的相似度。
更优地,所述步骤s201中基于词向量和知识库的词语相似度计算算法具体如下:
s20101、判断给定的是词语还是短语:
①、若给定是两个英文词语,则通过计算两词语向量的cosine相似度得到两个词语之间的相似度;
②、若给定词语为短语,则需要将短语中的词语对应的词向量相加,得到短语的向量表示,求得短语的相似度,公式如下:
其中,|p1|和|p2|表示短语p1和p2所含词语的个数;wi和wj分别表示p1中的第i个词语,p2中的第j个词语;
s20102、迭代地搜索与两个英文词语相关的同义词集,直到迭代步数超过γ;
s20103、以两个英文词语以及与两个英文词语相关的同义词集为基础构建同义词集图;
s20104、在图中设定距离范围内,计算与两个英文词语相关的同义词集的重合度,公式如下:
simlap(wi,wj)=d*count(wi,wj)/(count(wi)+count(wj))
式中,count(wi,wj)表示词语wi和wj共同具有的同义词集个数;count(wi)和count(wj)分别为wi和wj各自具有的同义词集个数;d表示设定距离范围的取值;
s20105、使用dijkstra算法计算图中wi和wj之间的最短路径,得到wi和wj的相似度,公式如下:
simbn(wi,wj)=α*1/(δpath)+(1-α)simlap(wi,wj)
其中,path是wi和wj之间的最短路径;δ用以调节相似度的取值;simlap(wi,wj)表示wi和wj之间的重合度;参数α是一个调节因子,调节公式中两个部分的相似度值;
s20106、将步骤s20101中基于词向量方法得到的相似度simvec和步骤s20105中基于知识库方法得到的相似度simbn,进行线性相加结合,得到最终的相似度,公式如下:
simfinal(wi,wj)=β*simvec+(1-β)*simbn
其中,simbn和simvec分别表示基于知识库方法得到的相似度和基于词向量方法得到的相似度;参数α是一个调节因子,调节基于知识库方法和基于词向量方法得到的相似度结果;
s20107、返回相似度simfinal。
作为优选,所述步骤s3中构建消歧图的具体步骤如下:
s301、权重优化:基于模拟退火的权重优化算法,对步骤s2中的三种相似度值进行自动优化,得到最优权重参数;
s302、相似度融合:权重优化之后,词义间最终融合的相似度公式为:
sim(ws,ws′)=αsimhow+βsimen+γsimvec
其中,ws和ws’表示两个词义,simhow表示基于hownet的相似度计算结果,权重为α;simen表示基于词向量和知识库的词语相似度计算结果,权重为β;simvec表示基于词向量的相似度计算结果,权重为γ;其中,α+β+γ=1,α≥0,β≥0,γ≥0;
s303、构建消歧图:消歧图以词义为顶点,词义间的语义关系为边,利用基于模拟退火的权重优化算法,整合三种相似度值作为词义间的边权重。
更优地,所述步骤s301中的模拟退火算法进行参数优化的公式为:
其中,result(x)表示目标函数,指的是消歧准确率;δ表示冷却速率;t表示当前所处温度;xnew表示新取参数;xold表示原参数;
模拟退火算法进行参数优化的公式表示的含义包括如下两种情况:
(a)、若新取参数xnew的目标函数取值不小于原参数xold的目标函数取值,则以概率p为1选择新取参数xnew;
(b)、若新取参数xnew的目标函数取值小于原参数xold的目标函数取值,则以概率p为exp((result(xnew)-result(xold))/(δt))作为选取参数xnew的依据,随机生成一个概率值,并判断随机生成的概率值与概率p的大小:
①、若随机生成的概率值不大于p时,则选择新取参数xnew;
②、若随机生成的概率值大于p时,则舍弃新取参数xnew;
所述步骤s303中的词义指的是一个三元组,表示为:word(no.,sword,enword);其中,no.表示的是概念编号;sword表示第一义原词语;enword表示英文词语;no.、sword、enword三者是有机统一的整体,描述同一个词义概念;在hownet中一个词义概念编号唯一标识一个词义,在其概念定义中可以获取到第一义原词语,进而映射该词义为英文词语。
作为优选,所述步骤s4中选择正确词义具体步骤如下:
s401、图评分:调用图评分方法对消歧图中词义概念顶点的重要度进行评分;完成图评分后,将候选词义概念按照得分从大到小进行排列,构成候选词义概念列表;
s402、选择正确词义:在消歧结果中选择正确词义,包括如下两种情况:
①、若消歧结果中仅有一个词义概念,则将仅有的一个词义概念作为正确词义;
②、若消歧结果是由多个词义概念构成的词义列表,则以词义概念得分最高者为正确词义。
更优地,所述步骤s401中图评分采用pagerank算法,pagerank算法是基于马尔科夫链模型对图中结点进行评估,一个结点的pagerank得分取决于与其链接的所有结点的pagerank得分;一个结点的具体pagerank得分计算公式为:
其中,1-α表示在随机游走过程中,跳出当前马尔可夫链随机选择一个结点的概率;α是指继续当前马尔可夫链的概率;n为总的结点数量;|out(u)|表示结点u的出度;in(v)为链接到结点v的所有结点。
一种基于图模型的词义消歧系统,该系统包括,
上下文知识提取单元,对歧义句进行词性标注,提取实词作为上下文知识,实词指名词、动词、形容词、副词;
相似度计算单元,用于分别做基于英文的相似度计算、基于词向量的相似度计算以及基于hownet的相似度计算;
消歧图构建单元,用于利用模拟退火算法对相似度进行权重优化,得到融合后的相似度,进而以词语概念为顶点,概念间的语义关系为边,边的权重为融合后的相似度,构建消歧图;
词义正确选择单元,用于通过图评分对图中候选词义进行打分,进而得到候选词义的得分列表,选择得分最大者为正确词义。
作为优选,所述相似度计算单元包括:
英文相似度计算单元,用于对上下文知识进行hownet词义信息标注,并做词义映射处理,得到英文词语集合;再利用基于词向量和知识库的词语相似度计算算法,对所得英文词语进行相似度计算;考虑到hownet是双语的,这里词义映射处理直接获取hownet中的英文词语信息;
词向量相似度计算单元,用于使用google的word2vec工具包在该语料上训练词向量,得到词向量文件,根据词向量文件获取给定两个词语对应的词向量,计算词向量间的余弦相似度作为两者的相似度;需要注意的是,歧义词的词义较多,训练好的词向量文件很可能倾向于该歧义词的某个较为常用的词义;
hownet相似度计算单元,用于利用hownet对上下文知识进行词义信息标注,采用词语词汇和概念编号的形式,利用hownet提供的概念相似度工具包计算各词义间的相似度;
所述消歧图构建单元包括,
权重优化单元,用于基于模拟退火的权重优化算法,对基于英文的相似度计算、基于词向量的相似度计算以及基于hownet的相似度计算的三种相似度值进行自动优化,得到最优权重参数;模拟退火算法进行参数优化的公式为:
其中,result(x)表示目标函数,指的是消歧准确率;δ表示冷却速率;t表示当前所处温度;xnew表示新取参数;xold表示原参数;
模拟退火算法进行参数优化的公式表示的含义包括如下两种情况:
(a)、若新取参数xnew的目标函数取值不小于原参数xold的目标函数取值,则以概率p为1选择新取参数xnew;
(b)、若新取参数xnew的目标函数取值小于原参数xold的目标函数取值,则以概率p为exp((result(xnew)-result(xold))/(δt))作为选取参数xnew的依据,随机生成一个概率值,并判断随机生成的概率值与概率p的大小:
①、若随机生成的概率值不大于p时,则选择新取参数xnew;
②、若随机生成的概率值大于p时,则舍弃新取参数xnew;
相似度融合单元:权重优化之后,词义间最终融合的相似度公式为:
sim(ws,ws′)=αsimhow+βsimen+γsimvec
其中,ws和ws’表示两个词义,simhow表示基于hownet的相似度计算结果,权重为α;simen表示基于词向量和知识库的词语相似度计算结果,权重为β;simvec表示基于词向量的相似度计算结果,权重为γ;其中,α+β+γ=1,α≥0,β≥0,γ≥0;
构建消歧图单元,用于消歧图以词义为顶点,词义间的语义关系为边,利用基于模拟退火的权重优化算法,整合三种相似度值作为词义间的边权重;其中,词义指的是一个三元组,表示为:word(no.,sword,enword);其中,no.表示的是概念编号;sword表示第一义原词语;enword表示英文词语;no.、sword、enword三者是有机统一的整体,描述同一个词义概念;在hownet中一个词义概念编号唯一标识一个词义,在其概念定义中可以获取到第一义原词语,进而映射该词义为英文词语。
更优地,所述词义正确选择单元包括,
图评分单元,用于调用图评分方法对消歧图中词义概念顶点的重要度进行评分;完成图评分后,将候选词义概念按照得分从大到小进行排列,构成候选词义概念列表;图评分采用pagerank算法,pagerank算法是基于马尔科夫链模型对图中结点进行评估,一个结点的pagerank得分取决于与其链接的所有结点的pagerank得分;一个结点的具体pagerank得分计算公式为:
其中,1-α表示在随机游走过程中,跳出当前马尔可夫链随机选择一个结点的概率;α是指继续当前马尔可夫链的概率;n为总的结点数量;|out(u)|表示结点u的出度;in(v)为链接到结点v的所有结点;
选择正确词义单元,用于在消歧结果中选择正确词义,包括如下两种情况:
①、若消歧结果中仅有一个词义概念,则将仅有的一个词义概念作为正确词义;
②、若消歧结果是由多个词义概念构成的词义列表,则以词义概念得分最高者为正确词义。
本发明的基于图模型的词义消歧方法和系统具有以下优点:
(一)、本发明通过结合多种中英文资源,优势互补,充分挖掘资源中的消歧知识,有助于词义消歧性能的提升;
(二)、本发明分别做基于英文的相似度计算、基于词向量的相似度计算以及基于hownet的相似度计算,确保能够有效整合多种知识资源,提高消歧准确率;
(三)、本发明利用模拟退火算法对相似度进行权重优化,得到融合后的相似度,进而以词语概念为顶点,概念间的语义关系为边,边的权重为融合后的相似度,构建消歧图,确保能够自动优化多种知识资源的相似度值;
(四)、本发明进行英文相似度计算时,对上下文知识进行hownet词义信息标注,并做词义映射处理,得到英文词语集合,确保能够自动对齐中英文知识资源;
(五)、本发明通过图评分对图中候选词义进行打分,进而得到候选词义的得分列表,选择得分最大者为正确词义,能够自动实现对目标歧义词的正确词义选择。
附图说明
下面结合附图对本发明进一步说明。
附图1为基于图模型的词义消歧方法的流程框图;
附图2为相似度计算的流程框图;
附图3为构建消歧图的流程框图;
附图4为正确词义选择的流程框图;
附图5为基于图模型的词义消歧的结构框图;
附图6为举例中医词语的词义信息图;
附图7为基于词向量和知识库的词语相似度计算算法中构建的同义词集图。
具体实施方式
参照说明书附图和具体实施例对本发明的一种基于图模型的词义消歧方法和系统作以下详细地说明。
实施例:
如附图1所示,本发明的基于图模型的词义消歧方法和系统,包括如下步骤:
s1、提取上下文知识:对歧义句进行词性标注,提取实词作为上下文知识,实词指名词、动词、形容词、副词;
举例:以对“围绕《指导意见》的贯彻落实,结合中医药工作的实际,各地要加大力度,积极而稳妥地推进中医医疗机构改革。”的处理为例,其中“中医”待消歧词语。词性标注处理使用中科院分词系统nlpir-ictclas。词性标注后得,“围绕/v《/wkz指导/v意见/n》/wky的/ude1贯彻/vn落实/vn,/wd结合/v中医药/n工作/vn的/ude1实际/n,/wd各地/rzs要/v加大/v力度/n,/wd积极/a而/cc稳妥/a地/ude2推进/vi中医/n医疗/n机构/n改革/vn。/wj”,对其提取实词并进行格式整理,以方便后续处理,得到“中医_n_25:围绕_v_0指导_vn_2意见_n_3贯彻_v_6落实_v_7结合_v_9中医药_n_10工作_vn_11实际_n_13要_v_16加大_v_17力度_n_18积极_a_20稳妥_a_22推进_v_24中医_n_25医疗_n_26机构_n_27改革_vn_28”,其中冒号前为待消歧词,词性后的编号为单词在句子中所处的位置。
s2、相似度计算:分别做基于英文的相似度计算、基于词向量的相似度计算和基于hownet的相似度计算;
如附图2所示,相似度计算具体步骤如下:
基于英文的相似度计算:对上下文知识进行hownet词义信息标注,并做词义映射处理,得到英文词语集合;再利用基于词向量和知识库的词语相似度计算算法,对所得英文词语进行相似度计算,另,考虑到hownet是双语的,这里词义映射处理直接获取hownet中的英文词语信息。基于词向量和知识库的词语相似度计算算法的部分主要代码如下:
在基于词向量和知识库的词语相似度计算算法中,行1,给定两个英文词语,它们之间的相似度,通过计算两者词向量的cosine相似度得到,若给定词语为短语,由于训练所得的词向量中没有短语,需要对短语进行进一步处理,通过将短语中的词语对应的词向量相加,得到短语的向量表示,进而求得短语的相似度,公式如下:
其中,|p1|和|p2|表示短语p1和p2所含词语的个数;wi和wj分别表示p1中的第i个词语,p2中的第j个词语。
行2-4,迭代地搜索与词语w1和w2相关的同义词集,直到迭代步数step超过γ,由于节点过多时图计算的代价较大,故将最大迭代步数γ设置为10;行5,以w1、w2以及它们之间相关联的同义词集为基础构建图;行6,在图中一定距离范围内,计算与w1和w2相关的同义词集的重合度,设定距离为2,公式如下:
simlap(w1,w2)=2*count(w1,w2)/(count(w1)+count(w2))
式中,count(w1,w2)表示词语w1和w2共同具有的同义词集个数;count(w1)和count(w2)分别为w1和w2各自具有的同义词集个数。
行7,使用dijkstra算法计算图中w1和w2之间的最短路径,进一步得到w1和w2的相似度,公式如下:
simbn(w1,w2)=α*1/(δpath)+(1-α)simlap(w1,w2)
其中,path是w1和w2之间的最短路径;δ用以调节相似度的取值,设置为1.4;simlap(w1,w2)表示w1和w2之间的重合度;参数α是一个调节因子,用来调节公式中两个部分的相似度值。
行8,将上述基于词向量的方法和基于知识库(babelnet)的方法,进行线性相加结合,得到最终的相似度,公式如下:
simfinal(w1,w2)=β*simvec+(1-β)*simbn
simbn和simvec分别表示基于知识库的方法和基于词向量的方法得到的相似度;参数α是一个调节因子,用来调节两种方法得到结果,具体设置为0.6。
行9,返回相似度simfinal。
基于词向量和知识库的词语相似度计算算法中有关词向量的处理为,利用word2vec工具包,在无标注英文wikipedia语料库上,训练词向量。在训练之前,对数据进行了预处理,将文件格式由unicode转换为utf-8。训练窗口设置为5,默认向量维度设置为200,模型选择skip-gram。训练结束之后,得到一个词向量文件,在文件中,每个词语被映射为一个具有200维的向量,向量的每一维为一个双精度数值。
知识库选取babelnet,babelnet提供了丰富的概念和命名实体,并通过大量的语义关系进行相互链接,这里的语义关系指同义词关系,上下位关系,整体部分关系等。给定两个词语(概念或命名实体),借助于babelnetapi可以获取各自的同义词集,以及通过语义关系链接的同义词集。同义词集是指一个同义词集合,在babelnet中具有唯一的标识符,表示具体的一个词义。例如“bn:00021464n”指示同义词集“computer,computingmachine,computingdevice,dataprocessor,electroniccomputer,informationprocessingsystem”,表示具体的一个词义“电脑、计算机”。基于词向量和知识库的词语相似度计算算法中构建的同义词集图,如附图7所示。
举例:对上下文知识进行hownet词义信息标注,具体为词义编号,得“中医_n_25:围绕_v_0:124932围绕_v_0:124933指导_vn_2:155807意见_n_3:143264意见_n_3:143267贯彻_v_6:047082落实_v_7:081572落实_v_7:081573落实_v_7:081575结合_v_9:064548结合_v_9:064549中医药_n_10:157339工作_vn_11:044068实际_n_13:109077实际_n_13:109078要_v_16:140522要_v_16:140530要_v_16:140532要_v_16:140534加大_v_17:059967加大_v_17:059968加大_v_17:059969力度_n_18:076991积极_a_20:057562积极_a_20:057564稳妥_a_22:126267稳妥_a_22:126269推进_v_24:122203推进_v_24:122206推进_v_24:122211中医_n_25:157332中医_n_25:157329机构_n_27:057323机构_n_27:057325机构_n_27:057326改革_vn_28:041189”。
做词义映射处理之后,得“中医_n_25:围绕_v_0:124932|revolveround围绕_v_0:124933|centreon指导_vn_2:155807|direct意见_n_3:143264|complaint意见_n_3:143267|idea贯彻_v_6:047082|carryout落实_v_7:081572|feelatease落实_v_7:081573|ascertain落实_v_7:081575|fulfil结合_v_9:064548|beunitedinwedlock结合_v_9:064549|combination中医药_n_10:157339|traditionalchinesemedicineanddruds工作_vn_11:044068|work实际_n_13:109077|reality实际_n_13:109078|practice要_v_16:140522|wantto要_v_16:140530|ask要_v_16:140532|askfor要_v_16:140534|take加大_v_17:059967|widen加大_v_17:059968|enhance加大_v_17:059969|enlarge力度_n_18:076991|dynamics积极_a_20:057562|active积极_a_20:057564|positive稳妥_a_22:126267|safe稳妥_a_22:126269|reliable推进_v_24:122203|moveforward推进_v_24:122206|advance推进_v_24:122211|pushinto中医_n_25:157332|traditional_chinese_medical_science中医_n_25:157329|practitioner_of_chinese_medicine机构_n_27:057323|institution机构_n_27:057325|internalstructureofanorganization机构_n_27:057326|mechanism改革_vn_28:041189|reform”。
对上述所得任意两个英文词语(每个hownet词义概念对应的英文词语)间做英文相似度计算,得“中医_n_25:围绕_v_0:124932|revolveroundand指导_vn_2:155807|directis0.292围绕_v_0:124932|revolveroundand意见_n_3:143264|complaintis0.3085围绕_v_0:124932|revolveroundand意见_n_3:143267|ideais0.3742围绕_v_0:124932|revolveroundand贯彻_v_6:047082|carryoutis0.4015围绕_v_0:124932|revolveroundand落实_v_7:081572|feelateaseis0.3575围绕_v_0:124932|revolveroundand落实_v_7:081573|ascertainis0.3215围绕_v_0:124932|revolveroundand落实_v_7:081575|fulfilis0.3541围绕_v_0:124932|revolveroundand结合_v_9:064548|beunitedinwedlockis0.3299围绕_v_0:124932|revolveroundand结合_v_9:064549|combinationis0.3487围绕_v_0:124932|revolveroundand中医药_n_10:157339|traditionalchinesemedicineanddrudsis0.3520围绕_v_0:124932|revolveroundand工作_vn_11:044068|workis0.3478围绕_v_0:124932|revolveroundand实际_n_13:109077|realityis0.3664围绕_v_0:124932|revolveroundand实际_n_13:109078|practiceis0.3907围绕_v_0:124932|revolveroundand要_v_16:140522|wanttois0.3375围绕_v_0:124932|revolveroundand要_v_16:140530|askis0.3482”,由于篇幅有限,这里只展示了部分相似度结果。
基于词向量的相似度计算:sogou全网新闻语料共计1.43gb,使用google的word2vec工具包在该语料上训练词向量,得到词向量文件,根据词向量文件获取给定两个词语对应的词向量,计算词向量间的余弦相似度作为两者的相似度;
需要注意的是,歧义词的词义较多,训练好的词向量文件很可能倾向于该歧义词的某个较为常用的词义。为此,利用hownet将歧义词转换成它所具有的词义,也就是每个概念定义中的第一义原,如附图5所示,将歧义词“中医”转换为“人”和“知识”。
举例:利用hownet对歧义词进行处理后,得“中医_n_25:围绕_v_0:124932|围绕围绕_v_0:124933|包围指导_vn_2:155807|命令意见_n_3:143264|语文意见_n_3:143267|念头贯彻_v_6:047082|实施落实_v_7:081572|安心落实_v_7:081573|决定落实_v_7:081575|实现结合_v_9:064548|结婚结合_v_9:064549|合并中医药_n_10:157339|知识_药物工作_vn_11:044068|做实际_n_13:109077|实体实际_n_13:109078|事情要_v_16:140522|期望要_v_16:140530|要求要_v_16:140532|谋取要_v_16:140534|花费加大_v_17:059967|变形状加大_v_17:059968|优化加大_v_17:059969|扩大力度_n_18:076991|强度积极_a_20:057562|积极积极_a_20:057564|正面稳妥_a_22:126267|当稳妥_a_22:126269|稳固推进_v_24:122203|前进推进_v_24:122206|发动推进_v_24:122211|推中医_n_25:157332|知识中医_n_25:157329|人机构_n_27:057323|机构机构_n_27:057325|部件机构_n_27:057326|部件改革_vn_28:041189|改良”。
对所得任意两个中文词语(对应于具体的hownet词义概念)做基于词向量的相似度计算,得“中医_n_25:围绕_v_0:124932|围绕and指导_vn_2:155807|命令is-0.0145围绕_v_0:124932|围绕and意见_n_3:143264|语文is-0.0264围绕_v_0:124932|围绕and意见_n_3:143267|念头is-0.0366围绕_v_0:124932|围绕and贯彻_v_6:047082|实施is0.2071围绕_v_0:124932|围绕and落实_v_7:081572|安心is-0.0430围绕_v_0:124932|围绕and落实_v_7:081573|决定is0.1502围绕_v_0:124932|围绕and落实_v_7:081575|实现is0.2254围绕_v_0:124932|围绕and结合_v_9:064548|结婚is-0.0183围绕_v_0:124932|围绕and结合_v_9:064549|合并is0.0745围绕_v_0:124932|围绕and中医药_n_10:157339|知识_药物is0.0866围绕_v_0:124932|围绕and工作_vn_11:044068|做is0.1434围绕_v_0:124932|围绕and实际_n_13:109077|实体is0.1503围绕_v_0:124932|围绕and实际_n_13:109078|事情is-0.0571围绕_v_0:124932|围绕and要_v_16:140522|期望is0.1009围绕_v_0:124932|围绕and要_v_16:140530|要求is0.2090围绕_v_0:124932|围绕and要_v_16:140532|谋取is0.0496围绕_v_0:124932|围绕and要_v_16:140534|花费is0.0176围绕_v_0:124932|围绕and加大_v_17:059967|变形状is0.0000围绕_v_0:124932|围绕and加大_v_17:059968|优化is0.2410围绕_v_0:124932|围绕and加大_v_17:059969|扩大is0.1911围绕_v_0:124932|围绕and力度_n_18:076991|强度is0.0592围绕_v_0:124932|围绕and积极_a_20:057562|积极is0.3089围绕_v_0:124932|围绕and积极_a_20:057564|正面is0.0554围绕_v_0:124932|围绕and稳妥_a_22:126267|当is0.0245围绕_v_0:124932|围绕and稳妥_a_22:126269|稳固is0.0490围绕_v_0:124932|围绕and推进_v_24:122203|前进is0.1917围绕_v_0:124932|围绕and推进_v_24:122206|发动is0.0277围绕_v_0:124932|围绕and推进_v_24:122211|推is0.1740围绕_v_0:124932|围绕and中医_n_25:157332|知识is0.2205围绕_v_0:124932|围绕and中医_n_25:157329|人is-0.0686围绕_v_0:124932|围绕and机构_n_27:057323|机构is0.0945围绕_v_0:124932|围绕and机构_n_27:057325|部件is0.0582围绕_v_0:124932|围绕and机构_n_27:057326|部件is0.0582”。由于篇幅有限,这里只展示了部分相似度结果。
基于hownet的相似度计算:利用hownet对上下文知识进行词义信息标注,采用词语词汇和概念编号的形式,利用hownet提供的概念相似度工具包计算各词义间的相似度。
举例:对上下文知识进行hownet词义信息标注,具体为词义编号,得“中医_n_25:围绕_v_0:124932围绕_v_0:124933指导_vn_2:155807意见_n_3:143264意见_n_3:143267贯彻_v_6:047082落实_v_7:081572落实_v_7:081573落实_v_7:081575结合_v_9:064548结合_v_9:064549中医药_n_10:157339工作_vn_11:044068实际_n_13:109077实际_n_13:109078要_v_16:140522要_v_16:140530要_v_16:140532要_v_16:140534加大_v_17:059967加大_v_17:059968加大_v_17:059969力度_n_18:076991积极_a_20:057562积极_a_20:057564稳妥_a_22:126267稳妥_a_22:126269推进_v_24:122203推进_v_24:122206推进_v_24:122211中医_n_25:157332中医_n_25:157329机构_n_27:057323机构_n_27:057325机构_n_27:057326改革_vn_28:041189”。
利用hownet提供的概念相似度工具包计算各词义间的相似度,得“中医_n_25:围绕_v_0:124932and指导_vn_2:155807is0.015094围绕_v_0:124932and意见_n_3:143264is0.000624围绕_v_0:124932and意见_n_3:143267is0.010256围绕_v_0:124932and贯彻_v_6:047082is0.013793围绕_v_0:124932and落实_v_7:081572is0.010256围绕_v_0:124932and落实_v_7:081573is0.013793围绕_v_0:124932and落实_v_7:081575is0.013793围绕_v_0:124932and结合_v_9:064548is0.016667围绕_v_0:124932and结合_v_9:064549is0.018605围绕_v_0:124932and中医药_n_10:157339is0.000624围绕_v_0:124932and工作_vn_11:044065is0.000624围绕_v_0:124932and工作_vn_11:044067is0.000624围绕_v_0:124932and工作_vn_11:044068is0.015094围绕_v_0:124932and实际_n_13:109077is0.000624围绕_v_0:124932and实际_n_13:109078is0.000624围绕_v_0:124932and要_v_16:140522is0.010959围绕_v_0:124932and要_v_16:140530is0.015094围绕_v_0:124932and要_v_16:140532is0.018605围绕_v_0:124932and要_v_16:140534is0.015094围绕_v_0:124932and加大_v_17:059967is0.013793围绕_v_0:124932and加大_v_17:059968is0.015094围绕_v_0:124932and加大_v_17:059969is0.013793围绕_v_0:124932and力度_n_18:076991is0.000624围绕_v_0:124932and积极_a_20:057562is0.000624围绕_v_0:124932and积极_a_20:057564is0.000624围绕_v_0:124932and稳妥_a_22:126267is0.000624围绕_v_0:124932and稳妥_a_22:126269is0.000624”。
s3、构建消歧图:利用模拟退火算法对相似度进行权重优化,得到融合后的相似度,进而以词语概念为顶点,概念间的语义关系为边,边的权重为融合后的相似度,构建出消歧图;如附图3所示,构建消歧图的具体步骤如下:
s301、权重优化:基于模拟退火的权重优化算法,对步骤s2中的三种相似度值进行自动优化,得到最优权重参数;模拟退火算法进行参数优化的公式为:
其中,result(x)表示目标函数,指的是消歧准确率;δ表示冷却速率;t表示当前所处温度;xnew表示新取参数;xold表示原参数;
模拟退火算法进行参数优化的公式表示的含义包括如下两种情况:
(a)、若新取参数xnew的目标函数取值不小于原参数xold的目标函数取值,则以概率p为1选择新取参数xnew;
(b)、若新取参数xnew的目标函数取值小于原参数xold的目标函数取值,则以概率p为exp((result(xnew)-result(xold))/(δt))作为选取参数xnew的依据,随机生成一个概率值,并判断随机生成的概率值与概率p的大小:
①、若随机生成的概率值不大于p时,则选择新取参数xnew;
②、若随机生成的概率值大于p时,则舍弃新取参数xnew。
基于模拟退火的权重优化算法的部分代码如下表所示:
基于模拟退火的权重优化算法中,行1为初始化操作,设置初始温度值t为100,温度下界值t_min为0.001,冷却速率delta置为0.98,最大迭代步数k设为100;行2-3为温度以及迭代步数的控制;行4-5,随机选择0到1-y的双精度值为x赋值,并为z赋值1-x-y;行6,函数getevalresult(x,y,z)为目标函数,函数返回值为给定权重参数x、y、x时所得的消歧准确率;行7,在x的邻域内选择新值赋给x_new;行8-18,决定x_new是否保留以取代x,具体见模拟退火算法进行参数优化的公式;行20,以delta的冷却速率更改t;行22,返回x、y、z的最优参数组合。
其中,x、y、z表示三种相似度结果的权重变量,第一次执行算法时,将y设为1/3,此时算法结束后得到x、y的权重优化参数,这时将min(x,y)固定下来,继续执行第二次算法,在算法结束后,其他两个权重参数可得到确定。
s302、相似度融合:权重优化之后,词义间最终融合的相似度公式为:
sim(ws,ws′)=αsimhow+βsimen+γsimvec
其中,ws和ws’表示两个词义,simhow表示基于hownet的相似度计算结果,权重为α;simen表示基于词向量和知识库的词语相似度计算结果,权重为β;simvec表示基于词向量的相似度计算结果,权重为γ;其中,α+β+γ=1,α≥0,β≥0,γ≥0;
举例:权重优化后,根据词义间最终融合的相似度公式对三种相似度值进行融合,“中医_n_25:围绕_v_0:124932|revolveround|围绕and指导_vn_2:155807|direct|命令is0.015094|0.2929|-0.0145围绕_v_0:124932|revolveround|围绕and意见_n_3:143264|complaint|语文is0.000624|0.3085|-0.0264围绕_v_0:124932|revolveround|围绕and意见_n_3:143267|idea|念头is0.010256|0.3742|-0.0366
围绕_v_0:124932|revolveround|围绕and贯彻_v_6:047082|carryout|实施is0.013793|0.4015|0.2071围绕_v_0:124932|revolveround|围绕and落实_v_7:081572|feelatease|安心is0.010256|0.3575|-0.0430围绕_v_0:124932|revolveround|围绕and落实_v_7:081573|ascertain|决定is0.013793|0.3215|0.1502围绕_v_0:124932|revolveround|围绕and落实_v_7:081575|fulfil|实现is0.013793|0.3541|0.2254围绕_v_0:124932|revolveround|围绕and结合_v_9:064548|beunitedinwedlock|结婚is0.016667|0.3299|-0.0183围绕_v_0:124932|revolveround|围绕and结合_v_9:064549|combination|合并is0.018605|0.3487|0.0745围绕_v_0:124932|revolveround|围绕and中医药_n_10:157339|traditionalchinesemedicineanddruds|知识_药物is0.000624|0.3520|0.0866围绕_v_0:124932|revolveround|围绕and工作_vn_11:044068|work|做is0.015094|0.3478|0.1434围绕_v_0:124932|revolveround|围绕and实际_n_13:109077|reality|实体is0.000624|0.3664|0.1503围绕_v_0:124932|revolveround|围绕and实际_n_13:109078|practice|事情is0.000624|0.3907|-0.0571围绕_v_0:124932|revolveround|围绕and要_v_16:140522|wantto|期望is0.010959|0.3375|0.1009围绕_v_0:124932|revolveround|围绕and要_v_16:140530|ask|要求is0.015094|0.3482|0.2090围绕_v_0:124932|revolveround|围绕and要_v_16:140532|askfor|谋取is0.018605|0.3648|0.0496”,这里为了展示过程没有进一步计算,例如“0.018605|0.3648|0.0496”表示三种相似度值,它们融合后为α0.018605+β0.3648+γ0.0496。
s303、构建消歧图:消歧图以词义为顶点,词义间的语义关系为边,利用基于模拟退火的权重优化算法,整合三种相似度值作为词义间的边权重;其中,词义指的是一个三元组,表示为:word(no.,sword,enword);其中,no.表示的是概念编号;sword表示第一义原词语;enword表示英文词语;no.、sword、enword三者是有机统一的整体,描述同一个词义概念;在hownet中一个词义概念编号唯一标识一个词义,在其概念定义中可以获取到第一义原词语,进而映射该词义为英文词语。
这三元组形式的词义使得上述三种相似度计算方法能够被整合为一个整体,以“中医”为例,“中医”有两个词义,分别对应于两个词义三元组,具体如下:“中医(157329,人,practitionerofchinesemedicine)”,“中医(157332,知识,traditionalchinesescience)”,此时在消歧图中任意两个顶点间的边权重,也就是词义间的语义相似度,可以由词义间最终融合的相似度计算得到。
s4、词义的正确选择:通过图评分对图中候选词义进行打分,进而得到候选词义的得分列表,选择得分最高者作为正确词义。如附图4所示,选择正确词义具体步骤如下:
s401、图评分:调用图评分方法对消歧图中词义概念顶点的重要度进行评分;完成图评分后,将候选词义概念按照得分从大到小进行排列,构成候选词义概念列表;图评分采用pagerank算法,pagerank算法是基于马尔科夫链模型对图中结点进行评估,一个结点的pagerank得分取决于与其链接的所有结点的pagerank得分;一个结点的具体pagerank得分计算公式为:
其中,1-α表示在随机游走过程中,跳出当前马尔可夫链随机选择一个结点的概率;α是指继续当前马尔可夫链的概率;n为总的结点数量;|out(u)|表示结点u的出度;in(v)为链接到结点v的所有结点。
举例:图评分后,得到候选词义概念列表,
中医_n_25:1573322.1213090873827947e58;
中医_n_25:1573291.8434688340823378e58。
s402、选择正确词义:在消歧结果中选择正确词义,包括如下两种情况:
①、若消歧结果中仅有一个词义概念,则将仅有的一个词义概念作为正确词义;
②、若消歧结果是由多个词义概念构成的词义列表,则以词义概念得分最高者为正确词义。
举例:选择词义概念得分最高者为正确词义,也即“中医_n_25:157332”。
实施例2:
如附图5所示,本发明基于图模型的词义消歧系统,该系统包括,
上下文知识提取单元,对歧义句进行词性标注,提取实词作为上下文知识,实词指名词、动词、形容词、副词;
相似度计算单元,用于分别做基于英文的相似度计算、基于词向量的相似度计算以及基于hownet的相似度计算。相似度计算单元包括:
英文相似度计算单元,用于对上下文知识进行hownet词义信息标注,并做词义映射处理,得到英文词语集合;再利用基于词向量和知识库的词语相似度计算算法,对所得英文词语进行相似度计算;考虑到hownet是双语的,这里词义映射处理直接获取hownet中的英文词语信息;
词向量相似度计算单元,用于使用google的word2vec工具包在该语料上训练词向量,得到词向量文件,根据词向量文件获取给定两个词语对应的词向量,计算词向量间的余弦相似度作为两者的相似度;需要注意的是,歧义词的词义较多,训练好的词向量文件很可能倾向于该歧义词的某个较为常用的词义;为此,利用hownet将歧义词转换成它所具有的词义,也就是每个概念定义中的第一义原,如图6所示,将歧义词“中医”转换为“人”和“知识”。
hownet相似度计算单元,用于利用hownet对上下文知识进行词义信息标注,采用词语词汇和概念编号的形式,利用hownet提供的概念相似度工具包计算各词义间的相似度。
消歧图构建单元,用于利用模拟退火算法对相似度进行权重优化,得到融合后的相似度,进而以词语概念为顶点,概念间的语义关系为边,边的权重为融合后的相似度,构建消歧图;消歧图构建单元包括,
权重优化单元,用于基于模拟退火的权重优化算法,对基于英文的相似度计算、基于词向量的相似度计算以及基于hownet的相似度计算的三种相似度值进行自动优化,得到最优权重参数;模拟退火算法进行参数优化的公式为:
其中,result(x)表示目标函数,指的是消歧准确率;δ表示冷却速率;t表示当前所处温度;xnew表示新取参数;xold表示原参数;
模拟退火算法进行参数优化的公式表示的含义包括如下两种情况:
(a)、若新取参数xnew的目标函数取值不小于原参数xold的目标函数取值,则以概率p为1选择新取参数xnew;
(b)、若新取参数xnew的目标函数取值小于原参数xold的目标函数取值,则以概率p为exp((result(xnew)-result(xold))/(δt))作为选取参数xnew的依据,随机生成一个概率值,并判断随机生成的概率值与概率p的大小:
①、若随机生成的概率值不大于p时,则选择新取参数xnew;
②、若随机生成的概率值大于p时,则舍弃新取参数xnew;
相似度融合单元:权重优化之后,词义间最终融合的相似度公式为:
sim(ws,ws′)=αsimhow+βsimen+γsimvec
其中,ws和ws’表示两个词义,simhow表示基于hownet的相似度计算结果,权重为α;simen表示基于词向量和知识库的词语相似度计算结果,权重为β;simvec表示基于词向量的相似度计算结果,权重为γ;其中,α+β+γ=1,α≥0,β≥0,γ≥0;
构建消歧图单元,用于消歧图以词义为顶点,词义间的语义关系为边,利用基于模拟退火的权重优化算法,整合三种相似度值作为词义间的边权重;其中,词义指的是一个三元组,表示为:word(no.,sword,enword);其中,no.表示的是概念编号;sword表示第一义原词语;enword表示英文词语;no.、sword、enword三者是有机统一的整体,描述同一个词义概念;在hownet中一个词义概念编号唯一标识一个词义,在其概念定义中可以获取到第一义原词语,进而映射该词义为英文词语。
词义正确选择单元,用于通过图评分对图中候选词义进行打分,进而得到候选词义的得分列表,选择得分最大者为正确词义。词义正确选择单元包括,
图评分单元,用于调用图评分方法对消歧图中词义概念顶点的重要度进行评分;完成图评分后,将候选词义概念按照得分从大到小进行排列,构成候选词义概念列表;图评分采用pagerank算法,pagerank算法是基于马尔科夫链模型对图中结点进行评估,一个结点的pagerank得分取决于与其链接的所有结点的pagerank得分;一个结点的具体pagerank得分计算公式为:
其中,1-α表示在随机游走过程中,跳出当前马尔可夫链随机选择一个结点的概率;α是指继续当前马尔可夫链的概率;n为总的结点数量;|out(u)|表示结点u的出度;in(v)为链接到结点v的所有结点;
选择正确词义单元,用于在消歧结果中选择正确词义,包括如下两种情况:
①、若消歧结果中仅有一个词义概念,则将仅有的一个词义概念作为正确词义;
②、若消歧结果是由多个词义概念构成的词义列表,则以词义概念得分最高者为正确词义。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!