基于大数据的风控方法、装置、计算机设备及存储介质与流程
本发明涉及业务安全领域,具体涉及基于大数据的风控方法、装置、计算机设备及存储介质。
背景技术:
风控即风险控制,指风险管理者采取各种措施和方法,消灭或减少风险事件发生的各种可能性,减少风险事件发生时造成的损失。风险控制的四种基本方法是:风险回避、损失控制、风险转移和风险保留,风险回避是投资主体有意识地放弃风险行为,完全避免特定的损失风险;损失控制不是放弃风险,而是制定计划和采取措施降低损失的可能性或者是减少实际损失;风险转移是指通过契约,将让渡人的风险转移给受让人承担的行为;风险自留,即风险承担,如果损失发生,经济主体将以当时可利用的任何资金进行支付。目前较成熟的风控系统需通过人工分析并处理运营过程中各种高风险交易,同时寻找更多新的攻击,开发人员开发模型需要的数据,从数据库里面计算出来,形成统一的变量接口,分析师通过数据仓库做模型、做规则,但大部分模型、规则较简单。
目前市场上的风控系统的数据来源单一,数据的准确性对风控系统影响很大,风控系统对数据源数据准确性的依赖程度较高,风控模型和风控规则较固定,不可实时更新,报告数据格式固定,不可定制化输出。
技术实现要素:
基于此,有必要针对目前市场上的风控系统的数据来源较单一,风控系统对数据源的依赖性较大等问题,提供一种基于大数据的风控方法、装置、计算机设备及存储介质。
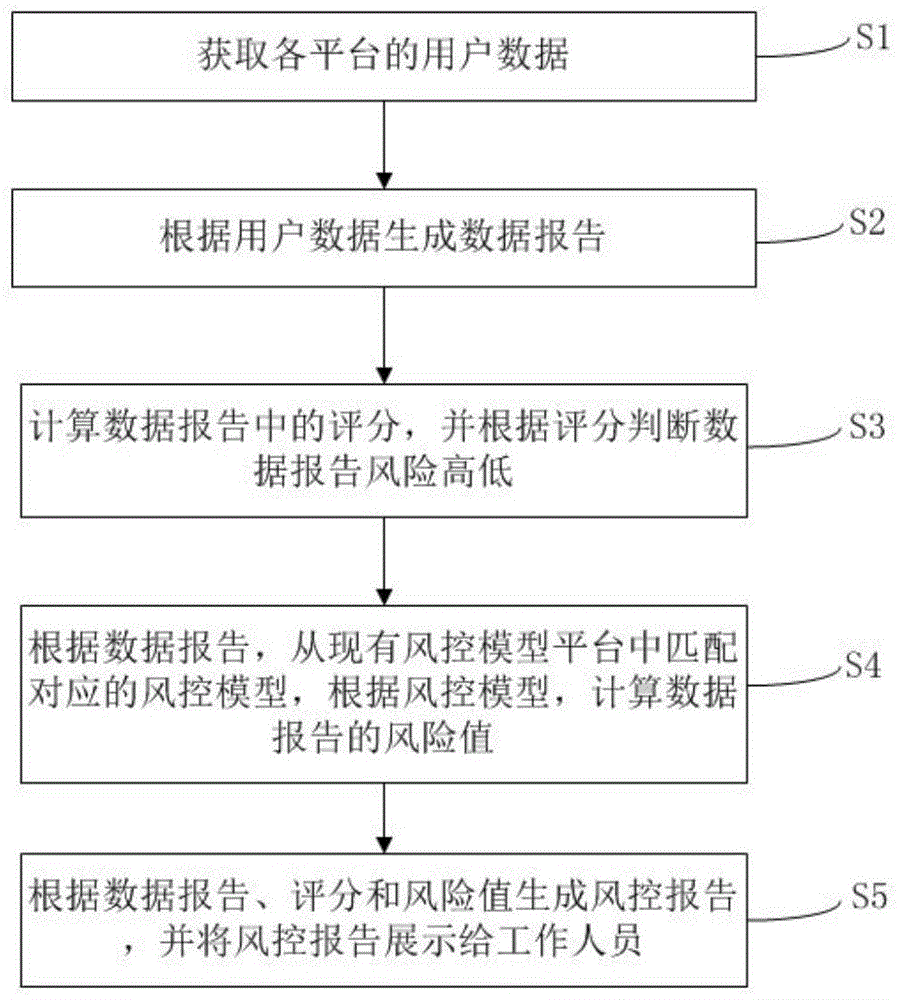
一种基于大数据的风控方法,所述基于大数据的风控方法,包括如下步骤:
获取各平台的用户数据;
根据所述用户数据生成数据报告;
计算所述数据报告中的评分,并根据所述评分判断所述数据报告风险高低;
根据所述数据报告,从现有风控模型平台中匹配对应的风控模型,根据所述风控模型,计算所述数据报告的风险值;
根据所述数据报告、所述评分和所述风险值生成风控报告,并将所述风控报告展示给工作人员。
在一个实施例中,所述获取各平台的用户数据,包括:
根据网络爬虫从现有各平台爬取用户数据,所述用户数据包括个人数据和企业数据;
根据所述用户数据的数据源及类别进行分类整理,并将所述用户数据存储于数据库中,所述数据源指获取所述用户数据的来源。
在一个实施例中,所述根据所述用户数据生成数据报告,包括:
根据所述用户数据的数据源的数量,将所述用户数据分为单数据源数据和多数据源数据;
对于所述单数据源数据,根据所述用户数据生成对应的所述数据报告,所述数据报告中包含从所述数据源获取到的各项数据,以及所述各项数据中包含的违约次数和正常次数;
对于所述多数据源数据,将来自多个所述数据源中相同的数据项目中所包含的所述违约次数和所述正常次数进行合并,不同的数据项目则进行罗列的方式,生成对应的所述数据报告。
在一个实施例中,所述计算所述数据报告中的评分,并根据所述评分判断所述数据报告风险高低,包括:
获取所述数据报告中各项数据的违约次数和正常次数,根据所述违约次数和所述正常次数计算所述各项数据的评分,计算公式如公式(1)所示,
公式(1)中si表示数据i的评分,mi表示数据i包含的正常次数,ni表示数据i包含的违约次数,ti表示数据i包含的总次数,即正常次数与违约次数之和;
将所述评分与阈值进行比较,根据比较结果判断所述评分对应的所述用户数据的风险高低,当所述评分高于所述阈值时,判断为低风险,当所述评分低于所述阈值时,判断为高风险。
在一个实施例中,所述根据所述数据报告,从现有风控模型平台中匹配对应的风控模型,包括:
获取所述数据报告中的所述用户数据所属类别的关键词;
根据所述关键词从现有风控模型平台中匹配对应的风控模型;
根据所述风控模型,计算所述数据报告中各项数据的风险值。
在一个实施例中,所述根据所述风控模型,计算所述数据报告中各项数据的风险值,包括:
获取所述数据报告中的各项数据的违约次数,计算得到各项数据的违约率,所述违约率的计算公式如公式(2)所示,
公式(2)中pi表示数据i的违约率,ni表示数据i的违约次数,ti表示数据i在数据报告中包含的总次数;
根据所述违约率计算得到所述数据报告中各项数据的风险值,计算公式如公式(3)所示,
公式(3)中,ni表示数据i的风险值,pi表示数据i的违约率,a、b为常数,a表示补偿常数,b表示刻度。
在一个实施例中,所述根据所述数据报告、所述评分和所述风险值生成风控报告,包括:
获取所述数据报告中各项数据的所述评分和所述风险值;
将所述数据报告中的各项数据与相应的所述评分与所述风险值进行一一对应整理后生成对应的风控报告;
将所述风控报告通过模板引擎向后续工作人员进行展示。
基于相同的构思,本申请还提供了一种基于大数据的风控装置,所述基于大数据的风控装置包括:
获取模块,设置为获取各平台的用户数据;
生成模块,设置为根据所述用户数据生成数据报告;
评分模块,设置为计算所述数据报告中的评分,并根据所述评分判断所述数据报告风险高低;
匹配模块,设置为根据所述数据报告,从现有风控模型平台中匹配对应的风控模型,根据所述风控模型,计算所述数据报告的风险值;
展示模块,设置为根据所述数据报告、所述评分和所述风险值生成风控报告,并将所述风控报告展示给工作人员。
基于相同的构思,本申请实施例还提供一种计算机设备,所述计算机设备包括存储器和处理器,所述存储器中存储有计算机可读指令,所述计算机可读指令被一个或多个所述处理器执行时,使得一个或多个所述处理器执行上述基于大数据的风控方法的步骤。
基于相同的技术构思,本申请实施例还提供了一种存储有计算机可读指令的存储介质,所述计算机可读指令被一个或多个处理器执行时,使得一个或多个所述处理器执行如上述基于大数据的风控方法的步骤。
上述基于大数据的风控方法、装置、计算机设备及存储介质,通过获取各平台的用户数据;根据所述用户数据生成数据报告;计算所述数据报告中的评分,并根据所述评分判断所述数据报告风险高低;根据所述数据报告,从现有风控模型平台中匹配对应的风控模型,根据所述风控模型,计算所述数据报告的风险值;根据所述数据报告、所述评分和所述风险值生成风控报告,并将所述风控报告展示给工作人员。因此,本申请中获取数据的数据源灵活多变,降低了对单一数据源的依赖性,通过数据类别的关键词所匹配的风控模型可灵活更新,能够针对不同客户定制化生成其风控报告。
附图说明
图1为本申请在一个实施例中基于大数据的风控方法的流程图;
图2为本申请在一个实施例中生成数据报告的流程图;
图3为本申请在一个实施例中计算数据报告评分的流程图;
图4为本申请在一个实施例中基于大数据的风控装置的结构框图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
图1为本申请在一个实施例中提供的基于大数据的风控方法的流程图,如图所示,包括:
s1、获取各平台的用户数据;
本步骤中通过网络爬取的方式从各平台中爬取用户数据,获取所述用户数据的平台包括前海征信、启信宝等平台,将获取到的所述用户数据根据其来源及类别进行整理后存储于数据库中。
s2、根据所述用户数据生成数据报告;
本步骤中将获取到的所述用户数据按照其数据源分成单数据源数据和多数据源数据,对于所述单数据源数据,可根据所述用户数据直接生成数据报告,对于多数据源数据,将相同的数据项目进行合并,不同的数据项目进行罗列的方式生成数据报告。
s3、计算所述数据报告中的评分,并根据所述评分判断所述数据报告风险高低;
本步骤中根据所述用户数据中各数据项目中包含的违约次数和正常次数,计算各数据项目的评分,再将所述评分与阈值进行比较,根据所述评分与所述阈值的比较结果评判数据项目的风险高低,最后综合各数据项目的风险高低结果来判断所述数据报告的风险高低。
s4、根据所述数据报告,从现有风控模型平台中匹配对应的风控模型,根据所述风控模型,计算所述数据报告的风险值;
本步骤中根据所述数据报告中所包含的所述用户数据所述类别的关键词,根据所述关键词从现有风控模型平台中进行搜索,搜索与所述关键词相匹配的风控模型,再根据公式计算所述数据报告中各数据项目的风险值的大小,最后综合各数据项目的风险值大小结果,判断所述数据报告的风险值。
s5、根据所述数据报告、所述评分和所述风险值生成风控报告,并将所述风控报告展示给工作人员;
本步骤中获取已生成的所述数据报告已经经过计算得到的所述数据报告中的各数据项目对应的所述评分和所述风险值,生成对应的风控报告,并将所述风控报告展示给工作人员,供后续操作人员对所述风险报告对应的个人用户或企业用户作出风险评估。
本实施例中通过获取各平台的用户数据并生成数据报告,对所述数据报告进行评分和风险值计算,最后可针对客户定制化生成一份风控报告,且从多渠道去获取用户数据,降低了对于单一数据源的依赖性,且通过线上匹配风控模型,使得所述风控模型可灵活更新。
在一个实施例中,所述获取各平台的用户数据,包括:
根据网络爬虫从现有各平台爬取用户数据,所述用户数据包括个人数据和企业数据;
本步骤中所述个人数据包含个人常贷客、好信一鉴通、黑名单、人行征信,所述企业数据包含企业三类工商数据、企业诉讼信息、企业税务负面信息、行业信息、发票数据、税务数据。
根据所述用户数据的数据源及类别进行分类整理,并将所述用户数据存储于数据库中,所述数据源指获取所述用户数据的来源;
本步骤中根据所述用户数据的来源和所属类别进行id标识后存储于数据库中,比如用户张三,关于其贷款的数据来自前海征信平台,关于其话费缴费记录来自启信宝平台,则张三包含两个id标识,分别为“张三-贷款数据-前海征信”、“张三-话费缴费数据-启信宝”。
本实施例中通过对爬取到的所述用户数据根据其来源和类别进行标识,为后续获取所述用户数据的数据源和所述用户数据所述类别的关键词提供了基础。
图2为本申请在一个实施例中提供的生成数据报告的流程图,如图所示,包括:
s201、根据所述用户数据的数据源的数量,将所述用户数据分为单数据源数据和多数据源数据;
本步骤根据所述用户数据的id标识将其分为单数据源数据和多数据源数据,当所述用户数据只有一个id标识时其为所述单数据源数据,有两个或以上的id标识时则为多数据源数据。
s202、对于所述单数据源数据,根据所述用户数据生成对应的所述数据报告,所述数据报告中包含从所述数据源获取到的各项数据,以及所述各项数据中包含的违约次数和正常次数;
本步骤中将单数据源数据直接生成对应的数据报告,比如用户张三的数据全部来自启信宝,其中包含贷款还款记录、话费缴费记录、信用卡还款记录,其中所生成的数据报告中包含张三的各项数据项目的违约次数和正常次数,比如张三的话费缴费记录一共是1000条,其中违约次数600条,正常次数400条,均罗列在所述数据报告中。
s203、对于所述多数据源数据,将来自多个所述数据源中相同的数据项目中所包含的所述违约次数和所述正常次数进行合并,不同的数据项目则进行罗列的方式,生成对应的所述数据报告;
本步骤中将多数据源数据采取同类项合并,异项罗列的方式生成数据报告,比如用户张三有来自启信宝的贷款还款记录10条,其中违约次数5次,话费缴费记录1000条,其中违约次数600条,信用卡还款记录500条,其中违约次数300条;同时还有来自前海征信的贷款还款记录6条,其中违约次数2次,信用卡还款记录300条,其中违约次数120条,缴税记录200条,其中违约次数60条;则用户张三的数据报告里的贷款还款记录为16条,违约次数7次,话费缴费记录1000条,违约次数600条,信用卡还款记录8000条,违约次数420条,缴税记录200条,违约次数60条。
本实施例通过根据所述用户数据的来源生成对应的数据报告,降低了风控报告对于单一数据源的依赖性,同时也为后续计算各数据项目的评分提供了基础。
图3为本申请在一个实施例中提供的计算数据报告评分的流程图,如图所示,包括:
s301、获取所述数据报告中各项数据的违约次数和正常次数,根据所述违约次数和所述正常次数计算所述各项数据的评分,计算公式如公式(1)所示,
公式(1)中si表示数据i的评分,mi表示数据i包含的正常次数,ni表示数据i包含的违约次数,ti表示数据i包含的总次数,即正常次数与违约次数之和;
本步骤中获取所示数据报告中各数据项目的违约次数和正常次数,再根据公式(1)计算该数据项目的评分,比如缴税记录200条,其中违约次数60条,正常次数140条,计算可得其评分为0.4。
s302、将所述评分与阈值进行比较,根据比较结果判断所述评分对应的所述用户数据的风险高低,当所述评分高于所述阈值时,判断为低风险,当所述评分低于所述阈值时,判断为高风险;
本步骤将所述评分与阈值进行比较,根据其比较结果判断各数据项目的风险高低,比如阈值设置为0.6,缴税记录的评分结果为0.4,则缴税记录评判为高风险,若用户张三的数据报告中包含,10个数据项目,其中有7个数据项目为高风险项目,3个为低风险项目,计算可得其高风险比率为0.7,则评判张三的数据报告为高风险。
本实施例通过对所述数据报告进行评分计算且对其进行风险评判,为后续生成风控报告提供了基础。
在一个实施例中,所述根据所述数据报告,从现有风控模型平台中匹配对应的风控模型,包括:
获取所述数据报告中的所述用户数据所属类别的关键词;根据所述关键词从现有风控模型平台中匹配对应的风控模型;根据所述风控模型,计算所述数据报告中各项数据的风险值;
本步骤中获取所述数据报告中的所述用户数据所述类别的关键词,调用配置在后台的旗正规则引擎,所述旗正规则引擎根据所述关键词从现有模型平台中进行自动匹配,根据匹配到的风控模型,结合所述数据报告计算各项数据项目的风险值。
本实施例中通过旗正规则引擎匹配所述数据报告的风控模型,为后续计算所述数据报告中的各数据项目的风险值提供了基础。
在一个实施例中,所述根据所述风控模型,计算所述数据报告中各项数据的风险值,包括:
获取所述数据报告中的各项数据的违约次数,计算得到各项数据的违约率,所述违约率的计算公式如公式(2)所示,
公式(2)中pi表示数据i的违约率,ni表示数据i的违约次数,ti表示数据i在数据报告中包含的总次数;
本步骤中根据所述数据报告中各数据项目所包含的违约次数计算其违约率,比如缴税记录200条,其中违约次数60条,则计算可得缴税记录的违约率为0.3。
根据所述违约率计算得到所述数据报告中各项数据的风险值,计算公式如公式(3)所示,
公式(3)中,ni表示数据i的风险值,pi表示数据i的违约率,a、b为常数,a表示补偿常数,b表示刻度;
本步骤中根据所述数据报告中各数据项目的违约率结果,计算得到其风险值,其中,a、b为根据人为经验设置的具体值,通常a取值为6.78,b取值为14.43,比如缴税记录的违约率pi为0.3,由公式(3)计算可得其风险值为12.09。
本实施例通过对所述数据报告中各数据项目进行违约率计算后,再根据违约率结果计算风险值,为后续生成风控报告提供了基础。
在一个实施例中,所述根据所述数据报告、所述评分和所述风险值生成风控报告,包括:
获取所述数据报告中各项数据的所述评分和所述风险值;
本步骤中获取根据所述用户数据生成的所述数据报告,以及所述数据报告中各数据项目经过计算后得到的评分及风险值。
将所述数据报告中的各项数据与相应的所述评分与所述风险值进行一一对应整理后生成对应的风控报告;
本步骤中采用罗列的方式将所述数据报告中各数据项目以及其对应的违约次数、正常次数、总次数、评分、违约率、风险值进行一一对应后生成对应的风控报告。
将所述风控报告通过模板引擎向后续工作人员进行展示;
本步骤中将生成的所述风控报告通过freemark引擎在后台进行展示,供后续工作人员根据所述风控报告对用户作出风险控制判断。
本实施例通过计算所得评分及风险值并结合所述数据报告生成所述风控报告,为后续工作人员对用户进行风险判断提供了依据。
基于相同的构思,本申请还提供了一种基于大数据的风控装置,如图4所示,所述基于大数据的风控装置包括获取模块、生成模块、评分模块、匹配模块和展示模块,其中:获取模块,设置为获取各平台的用户数据;生成模块,设置为根据所述用户数据生成数据报告;评分模块,设置为计算所述数据报告中的评分,并根据所述评分判断所述数据报告风险高低;匹配模块,设置为根据所述数据报告,从现有风控模型平台中匹配对应的风控模型,根据所述风控模型,计算所述数据报告的风险值;展示模块,设置为根据所述数据报告、所述评分和所述风险值生成风控报告,并将所述风控报告展示给工作人员。
在一个实施例中,所述获取模块包括:
爬取单元,设置为根据网络爬虫从现有各平台爬取用户数据,所述用户数据包括个人数据和企业数据;
存储单元,设置为根据所述用户数据的数据源及类别进行分类整理,并将所述用户数据存储于数据库中,所述数据源指获取所述用户数据的来源。
在一个实施例中,所述生成模块包括:
分类单元,设置为根据所述用户数据的数据源的数量,将所述用户数据分为单数据源数据和多数据源数据;
直接生成单元,设置为对于所述单数据源数据,根据所述用户数据生成对应的所述数据报告,所述数据报告中包含从所述数据源获取到的各项数据,以及所述各项数据中包含的违约次数和正常次数;
合并生成单元,设置为对于所述多数据源数据,将来自多个所述数据源中相同的数据项目中所包含的所述违约次数和所述正常次数进行合并,不同的数据项目则进行罗列的方式,生成对应的所述数据报告。
在一个实施例中,所述评分模块包括:
评分计算单元,设置为获取所述数据报告中各项数据的违约次数和正常次数,根据所述违约次数和所述正常次数计算所述各项数据的评分;
比较单元,设置为将所述评分与阈值进行比较,根据比较结果判断所述评分对应的所述用户数据的风险高低,当所述评分高于所述阈值时,判断为低风险,当所述评分低于所述阈值时,判断为高风险。
在一个实施例中,所述匹配模块包括:
获取关键词单元,设置为获取所述数据报告中的所述用户数据所属类别的关键词;
匹配单元,设置为根据所述关键词从现有风控模型平台中匹配对应的风控模型;
运算单元,设置为根据所述风控模型,计算所述数据报告中各项数据的风险值。
在一个实施例中,所述运算单元包括:
违约率计算单元,设置为获取所述数据报告中的各项数据的违约次数,计算得到各项数据的违约率;
风险值计算单元,设置为根据所述违约率计算得到所述数据报告中各项数据的风险值。
在一个实施例中,所述展示模块包括:
获取单元,设置为获取所述数据报告中各项数据的所述评分和所述风险值;
生成单元,设置为将所述数据报告中的各项数据与相应的所述评分与所述风险值进行一一对应整理后生成对应的风控报告;
展示单元,设置为将所述风控报告通过模板引擎向后续工作人员进行展示。
基于相同的技术构思,本申请实施例还提供一种计算机设备,所述计算机设备包括存储器和处理器,存储器中存储有计算机可读指令,计算机可读指令被一个或多个处理器执行时,使得一个或多个所述处理器执行计算机可读指令时实现上述各实施例中的基于大数据的风控方法的步骤。
基于相同的技术构思,本申请实施例还提供一种存储有计算机可读指令的存储介质,所述计算机可读指令被一个或多个处理器执行时,使得一个或多个所述处理器执行所述计算机可读指令时实现上述各实施例中的基于大数据的风控方法的步骤。其中,所述存储介质可以为非易失性存储介质。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器(rom,readonlymemory)、随机存取存储器(ram,randomaccessmemory)、磁盘或光盘等。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明一些示例性实施例,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!