本发明涉及到图像处理领域,更具体地,涉及一种更快的基于深度学习的密集目标计数方法。
背景技术:
由于近年来深度学习技术研究地飞速发展,越来越多的问题在利用到深度学习技术之后获得了新的机遇。而在本发明所涉及到的密集目标计数领域中,涉及到多种复杂的场景,包括商场的人群,街道的车流,草原的牛群,工厂里的密集钢筋等等。若能快速的统计数目,不仅可以及时调节商场和街道的秩序防止安全事故发生,也可以提高工厂等企业的工作效率来增大效益。
传统的目标计数方法往往基于检测的方法,根据目标的运动特征和纹理特征准确识别出每个目标的具体位置信息来进行计数,但是由于密集目标的重叠遮挡情况非常严重,无法进行检测。后来基于全局特征的回归方法首先建立图像特征和图像人数的回归模型,通过测量图像特征从而估计场景中的人数,但是由于密集图像特征复杂依旧效果不好。
而基于深度学习的技术不再考虑复杂的特征处理操作,借助复杂多样且高效的卷积操作对图片进行处理,而且将密度图作为转换的中介大大增强了整体系统的鲁棒性,使不同复杂场景的密集目标的计数准确性得到了进一步地提升。
技术实现要素:
本发明的主要优势是在基于强大的深度学习技术上提出一种全新的网络结构组合,能够克服传统图像处理在密集目标计数上的不足。不仅无需对图像本身进行前景背景分割等复杂过程,而且还能利用新的特征网络让密集目标的密度特征信息得到更多的保留,大大增加了最终的计数准确率。同时由于设计的神经网络结构所需参数量大幅度地降低,使计算速度变得更快,将具备加载到移动手持等轻便设备的可能。而且整合了不同场景的密集目标数据,一起训练处理后得到的测试结果依旧稳定,这样便可以同时处理多种场景的密集目标计数问题。为了达到以上目的,本发明将采取以下步骤:
(1)预处理
由于目前公开数据集有限,于是自主制作了一些相关的密集目标图片,为了保持一致性,所拍摄的图像的实际目标所占比例较小,且重合率较大,最终添加到公开数据集里一起。
首先为原始图像生成相应的密度图。对图像上所有目标位置进行人工标记,一般认定为该目标所占像素点区域的重心位置为标记点。使某一个目标的标记记作pi(xi,yi),并将其表示为δ(x-xi),这样对于具有n个目标的的图像i,这样对于具有n个目标的的图像i,为了使密度图具有连续性,进行归一化高斯处理。接着引入高斯核函数gσ(x),但是由于在复杂场景中目标之间的关联性较大,而且由于透视失真导致某个目标点与周围目标在不同复杂场景区域的尺度不一致,所以为了更加精准地估计,利用k近邻算法的思想,使用该目标与周围目标距离的平均距离作为参照量,来估计高斯函数中σ参数。
对于每一个目标点,求去其于周围k个目标的平均欧式距离而对于不同区域的高斯核的σ参数也是随着区域的改变而改变,所以需要设置一个自适应的高斯核,那么由于目标区域的半径与存在线性比例关系,则通过实验经验设置(β=0.3),则最终的密度图转换函数可表示为式1:
(2)创立训练样本
将每一张图片平均分为大小一致、无重叠部分的9份子图片。而对于标签文件,在经过同样操作的处理之后,还需主要保持每一小块密度矩阵的积分值与原图真实数目一致。
(3)神经网络构建
构建的网络主要分为前后相连的两个部分组成,第一个部分是前期特征提取器,第二个为多尺度特征学习器。
对于第一部分由conv-pooling-conv-pooling组成,第一个卷积层为24个大小为5*5的卷积核,第一个池化层是大小为2*2,步长为1的最大值池化层,第二个卷积层为48个大小为3*3的卷积核,第二个池化层同样为大小为2*2,步长为1的最大值池化层。
紧接着第二部分主要由一个多孔空间金字塔池化结构组成,由并行的4个空洞卷积层组成,相比于传统的卷积,加入了采样比率参数rate,代表着在计算中被采集的像素点相邻之间的距离为rate,这样便可以保留了内部数据结构和重要层级信息,以便对不同目标的密度图重建。但是由于不同场景下的目标大小不同,大的rate对大的目标包容性更强,小的rate对小的目标更为贴切。本发明所采用的采样率参数分别为2,4,6,8,卷积核大小为3×3。最后再接一个1×1的卷积生成预测密度图,且所有的卷积函数适用relu函数进行非线性激活。
首先前期特征提取器只是为了对图像做初步的学习筛选,为了让最后生成的密度图更能准确地反应实际的数目,所以也只采用两个池化层,保证了足够大的特征分辨率。而多尺度特征学习器则是聚焦到了特征的更深的尺度和语义信息,将不同感受野的学习结果进行整合,增强了系统的鲁棒性。综合其两者便可以更加关注对图像的具体语义信息的提取,从而使其具有网络具有更准确的表达。而且在每一层的卷积层使用较少的滤波器,大大缩减了网络的规模,使工作速度变得更快。
训练:首先定义目标函数为带有正则化的均方误差函数如下所示:
然后采用k-折叠交叉验证方法进行训练。将数据集分为k份,一次epoch一共训练k次,每次以k-1份作为训练集,1份作为验证集。最后在网络构建完成之后开始进行对训练图像的自动学习,直到收敛后停止训练,并生成相应的模型文件。
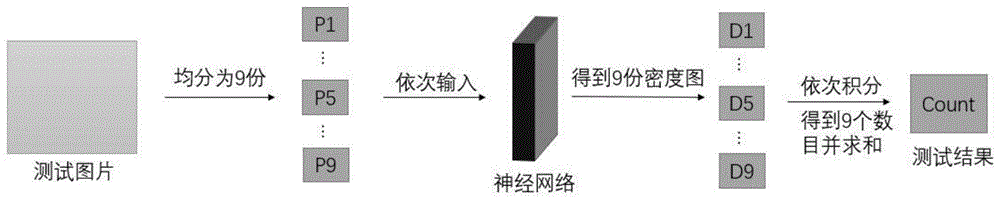
测试:将待测试图片同样平均分为大小一致、无重叠部分的9份子图片,再依次输入到已训练好的网络,并输出相应的密度图,对其数值矩阵进行求和得到测试数目,并将9份数值之和作为最终的测试数目。
评价指标:利用求取平均绝对误差(mae)和均方误差(mse)来评估,mae来评估模型的准确性,mse来评估模型的鲁棒性,具体计算公式如式3和式4:
n指图片总数目,zi和分别代表的真实数目和预测数目。
与现有技术相比,本发明具有以下有益效果:本发明为了解决密集目标计数问题提出一种更快的基于深度学习的密集目标计数方法,利用传统卷积和空洞卷积的结合有效地学习到了图片的深层语义和尺度信息,增强了系统的鲁棒性。传统的卷积有效地学习到了图像地特征信息,而且在保证足够大的特征分辨率值只进行两次池化缩小为原图的1/4;新的不同采样率的空洞卷积学习不同感受野下的特征信息,整合起来之后便支撑了更准确的语义信息。最终在保证了一定准确率的同时,还大大降低了网络的规模,加快了检测速度,具备了搭载到手持移动等轻便设备的条件,为能快速地对不同场景的密集目标计数提供了有效的解决方案。
附图说明
图1是本发明计数方法测试流程结构图
图2是具体神经网络结构图
图3是数据集中的图片和密度图示例
图4是测试结果图示例
具体实施方式
为了更充分理解本发明的计数内容,下面结合具体实例对本发明的技术方案做进一步介绍和说明,但不限于此。
(1)预处理
由于目前公开数据集有限,于是自主制作了一些相关的密集目标图片,包括工厂里的钢筋,散落到地里的瓜子,最终添加到公开数据集里一起。
参照附图三,首先为原始图像生成相应的密度图。对图像上所有目标位置进行人工标记,一般认定为该目标所占像素点区域的重心位置为标记点。使某一个目标的标记记作pi(xi,yi),并将其表示为δ(x-xi),这样对于具有n个目标的的图像i,这样对于具有n个目标的的图像i,为了使密度图具有连续性,进行归一化高斯处理。接着引入高斯核函数gσ(x),但是由于在复杂场景中目标之间的关联性较大,而且由于透视失真导致某个目标点与周围目标在不同复杂场景区域的尺度不一致,所以为了更加精准地估计,利用k近邻算法的思想,使用该目标与周围目标距离的平均距离作为参照量,来估计高斯函数中σ参数。
对于每一个目标点,求去其于周围k个目标的平均欧式距离而对于不同区域的高斯核的σ参数也是随着区域的改变而改变,所以需要设置一个自适应的高斯核,那么由于目标区域的半径与存在线性比例关系,则通过实验经验设置(β=0.3),则最终的密度图转换函数可表示为式1:
(2)创立训练样本
将每一张图片平均分为大小一致、无重叠部分的9份子图片。而对于标签文件,在经过同样操作的处理之后,还需主要保持每一小块密度矩阵的积分值与原图真实数目一致。
(3)神经网络构建
参照附图二,构建的网络主要分为前后相连的两个部分组成,第一个部分是前期特征提取器,第二个为多尺度特征学习器。
对于第一部分主要由第一部分由conv-pooling-conv-pooling组成,第一个卷积层为24个大小为5*5的卷积核,第一个池化层是大小为2*2,步长为1的最大值池化层,第二个卷积层为48个大小为3*3的卷积核,第二个池化层同样为大小为2*2,步长为1的最大值池化层。
紧接着第二部分主要由一个多孔空间金字塔池化结构组成,由并行的4个空洞卷积层组成,相比于传统的卷积,加入了采样比率参数rate,代表着在计算中被采集的像素点相邻之间的距离为rate,这样便可以保留了内部数据结构和重要层级信息,以便对不同目标的密度图重建。但是由于不同场景下的目标大小不同,大的rate对大的目标包容性更强,小的rate对小的目标更为贴切。本发明所采用的采样率参数分别为2,4,6,8,卷积核大小为3×3。最后再接一个1×1的卷积生成预测密度图,且所有的卷积函数适用relu函数进行非线性激活。
首先前期特征提取器只是为了对图像做初步的学习筛选,为了让最后生成的密度图更能准确地反应实际的数目,所以也只采用两个池化层,保证了足够大的特征分辨率。而多尺度特征学习器则是聚焦到了特征的更深的尺度和语义信息,将不同感受野的学习结果进行整合,增强了系统的鲁棒性。综合其两者便可以更加关注对图像的具体语义信息的提取,从而使其具有网络具有更准确的表达。而且在每一层的卷积层使用较少的滤波器,大大缩减了网络的规模,使工作速度变得更快。
训练:首先定义目标函数为带有正则化的均方误差函数如式2所示。
然后采用k-折叠交叉验证方法进行训练。将数据集分为k份,一次epoch一共训练k次,每次以k-1份作为训练集,1份作为验证集。最后在网络构建完成之后开始进行对训练图像的自动学习,直到收敛后停止训练,并生成相应的模型文件。
测试:参照附图1,将待测试图片同样平均分为大小一致、无重叠部分的9份子图片,再依次输入到已训练好的网络,并输出相应的密度图,对其数值矩阵进行求和得到测试数目,并将9份数值之和作为最终的测试数目。参照附图4,左右两边分别为输入图片和输出图片,其测试结果对不同场景的目标的计数准确率较好,具有较好的稳定性。
评价指标:利用求取平均绝对误差(mae)和均方误差(mse)来评估,mae来评估模型的准确性,mse来评估模型的鲁棒性。
同时在著名的数据集shanghaitechparta,b上也做了相应的实验,结果如以下表1和表2所见:
表1
表2
可以看出本发明的测试结果,在保证一定的准确率上,大大地缩小了网络规模大小,从而有效地提高了识别速度,是一种更快的基于深度学习的密集目标识别方法。而为了验证能在多种场景下同样适应,在原有数据集的情况加入扩充的其他场景的数据集进行一起训练测试,结果如表3所示
在加入其他场景的密集目标数据之后,其结果也保持相对稳定,说明本发明所提出的方法有效。