一种基于深度神经网络的中文简历解析方法与流程
本发明涉及中文简历解析方法自然语言处理领域,特别涉及基于ablstm-crf的中文简历解析方法
背景技术:
现代信息技术和存储技术的快速发展以及互联网的迅速蔓延,形成了巨大的信息海洋,为人们提供了一个触手可及的知识来源,给我们的生活带来了极大的便利。基本上可以说,互联网正在以前所未有的速度改变着人们的生产生活方式。同时引起人们注意的是,在这随着信息不断汇聚而成的汪洋大海中,人们要准确高效地找到想要的信息就好像大海捞针一样,变得越来越耗时耗力。特别是每年的招聘季,企业hr在对海量纷繁复杂格式自由的简历文本进行筛选审查无疑是头疼的。此外证券市场监管机构要从招股书中的董监高简介信息中抽取简历信息用于市场监管,依靠传统人工抽取审查,或者是基于规则模板的抽取方法,显然这两种方法效率低且成本高。研发智能高效的简历解析技术从文本简历中抽取出人物的基本信息元对人物信息数据库的构建,社会行为预测,社会关系网络链接,人才管理,市场监管是极其重要的。与此同时,这个技术可以延伸至电子病历信息元的抽取、产品说明信息解析、微博信息抽取等医疗、社交领域。
技术实现要素:
针对传统的简历解析主要有两种典型的方法,基于规则模版的简历解析和基于统计的简历解析。基于规则的模版的简历解析技术能够很好的把简历信息元抽取,准确率高,但是每个规则模版只能应用到同一模版的文本简历中;基于统计的信息抽取要求用户输入一定量的数据,然后通过规律、分类、聚类等人工只能和数据挖掘的方法进行解析,他减少了用户维护模版的代价。但是也要准备大量的数据,而且准确率一定程度上跟数据的选取和数量有关。
针对此缺点,提出利用ablstm-crf深度神经网络模型来对简历进行解析,使得从大规模的复杂信息中抽取有用信息成为可能。主要分为三个步骤:
步骤101:构建基于深度神经网络的中文简历解析框架;
步骤102:构建基于注意力机制的blstm深度神经网络模型,对词进行向量表示;
步骤103:构建blstm-crf解析中文简历。
优先地,所述步骤101构建基于深度学习的中文简历解析框架包括:
传统的简历解析方法主要是基于规则、基于统计、基于浅层神经网络,不足以达到大批量处理无规则的简历,因此本文采用深度学习框架来对简历进行解析;
本文主要研究的是采用深度神经网络对简历进行解析,该方法主要是利用深度神经网络具有主动学习特征的能力,进而获得相应的特征,然后根据特征对相应的信息元进行标注。
优先地,所述步骤102采用基于注意力机制的blstm深度神经网络模型框架获取相应特征表征,解决目标问题包括:基于深度学习模型的任务中,无论采用英文数据集还是中文数据集,对词进行向量表示这是必不可少的步骤,词表示的好坏将直接影响到模型对简历信息元标注结果的好坏,对于中文的简历解析中,很大程度上都选择采用的特征表征的方法是词向量表示方法,词向量的表示方法一般都用的是主流的glove和word2vec工具,这样的特征表征只能学习有限的特征信息。
针对此缺陷,提出了使用基于注意力机制的blstm模型对词进行向量表示,利用blstm的门机制,采用blstm对中文文字的词根进行建模,然后将获得的包含词根信息的字向量再进行一次序列建模,使得词向量获得相应的字序列信息和词根信息,为了更好的进行一个向量表示,在blstm的串联的时候引入注意力机制(ablstm),更好对前向lstm和后向lstm的输入进行权重串联,获得一个更好的词向量表示。
采用基于ablstm模型对词向量进行表示,主要分为两个步骤:
①数据集:提供训练数据集、验证数据集、测试数据集;
②ablstm:基于注意力机制的双向长短时记忆神经网络模型,基于注意力机制来对词根序列和字序列进行向量表示,获得一个更好的向量表示;
具体如下:
采用了一个新的词向量表示方法,即使用ablstm模型对向量进行表示,首先将词语进行分词,然后拆分成单个字,然后将字拆分成其象形词根,利用blstm对象形词根进行建模,获得包含字内部信息的字向量,然后再利用blstm对字进行建模,获得包含字序列信息的词向量,此方法可以更好的对词进行向量表示。
对于给定一个包含n个字的非结构化文本简历字序列:
char=(char1,...,charn)
将序列进行词根拆分,然后输入到双向lstm神经网络模型中,利用blstm对词根进行建模,获得一个包含字内部信息的字向量,然后再利用双向lstm的前向lstm对字序列进行建模生成一个包含字序列以及字序列上文信息的向量表示charfi,同理后向lstm反向读取字序列,将字序列以及字序列的下文信息表示为charbi,然后将charfi和charbi连接形成一个包含字序列以及上下文信息的词表示:
wd=[charfi:charbi]
此表示方法获得了字序列与词语之间的关系,与主流的stanford的glove和google的word2vec相比,此方法对模型性能具有一个显著的提升。此方法可应用于其他需词表示的深度神经网络模型中。
优先地,所述步骤103构建blstm-crf解析中文简历,具体由两个主要步骤组成包括:由步骤102获得词向量表示、基于blstm-crf模型对中文简历进行解析。
经过blstm对非结构化文本简历的字序列进行建模之后,获得一个包含字序列信息的中文词语序列:
wd=(wd1,...,wdi)
将词序列输入到blstm神经网络中,利用blstm中的前向lstm将词wdi及其上文信息表示为wordfi,同理利用后向lstm将词wdi及其上文信息表示为wordbi,最终将blstm的前向lstm输出结果和后向lstm的输出结果级联起来形成一个新的特征表示ht=[wordfi:wordbi],ht直接作为特征来为每个输出yt做出独立的标记决策,此方法有效的将词及其上下文信息用向量表示,此方法有效的将词及其上下文信息用向量表示;
在本文的非结构化文本简历信息解析任务中,输出标签之间有一个非常强的依赖关系。例如:b-org.company标签的后面不能跟着i-gsp.company或除i-org.company以外的其他标签。因此为了建模标签的依赖关系,本文采用crf来建模整个句子的输出标签。假定得到非结构化文本简历信息的输出目标序列(即对应的标签序列)为:
y=(y1,...,yn)
为了有效的获得非结构化文本简历信息的目标序列,模型的分值公式定义如下:
其中p表示的是双向lstm的输出分值矩阵,其大小为n×k,k表示的是目标标签的数量,n表示词序列的长度。a表示的是转移分值矩阵。y0和yn+1分别表示的是一个序列的开始和结束的标志,因此a方阵的大小为k+2;
在所有简历信息的标签序列上,crf生成目标序列y的概率为:
其中yx代表简历信息序列x对应的所有可能标签序列;
在训练过程中,为了获得简历信息正确的标签序列,将采用最大化正确标签序列的条件似然对数概率:
由上述的表述可以看出本文训练神经网络是为了尽可能输出非结构化简历信息有效的标签序列。因此如下公式给出的最大分值公式用于预测最合适的标签序列:
因为是对输出之间的相互作用进行建模因此采用动态规划的方法计算件似然对数概率公司中的求和以及最大分值公式中的最大后验序列y*。
最终获得中文简历中所需要关注的信息元的实体标签,然后根据信息元的实体标签,解析出相应的中文简历中所需要关注的信息元。
附图说明
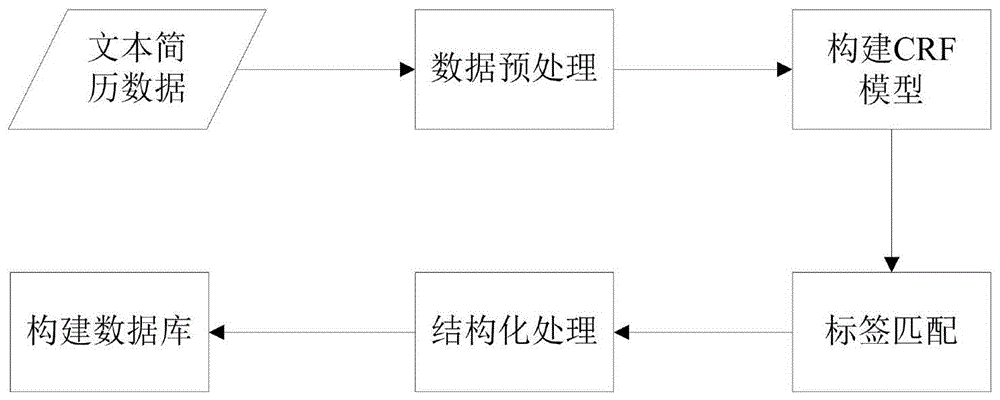
图1本发明所使用的基于深度学习的中文简历解析框架;
图2本发明所提基于ablstm的词向量表示示意图;
图3本发明所使用的blstm-crf示意图;
具体实施方式
为使本发明的目的、技术方案和优点表达得更加清楚明白,下面结合附图及具体实施案例对本发明做进一步详细说明。
图1本发明所使用的基于深度学习的中文简历解析框架,具体包括:
采用深度学习学习框架即ablstm-crf模型对中文简历进行解析,对文本简历进行标注标签,然后根据标签信息,将文本简历中的信息元根据标签处理成相应格式进行存储。
图2是本发明所提基于ablstm的词向量表示示意图,包括以下步骤:
本文采用基于ablstm对词进行向量表示,主要分为两个步骤:
①数据集:提供训练数据集,验证数据集,测试数据集;
②ablstm:基于注意力机制的双向长短时记忆神经网络模型,基于注意力机制来对词根序列和字序列进行向量表示,获得一个更好的向量表示;
具体如下:
首先,对获得的简历信息的数据文本d={d_1…d_n},其中d_n表示第n个数据文本。然后对简历数据文本d={d_1…d_n}进行处理:
1.对文档中的文字利用分词模型进行分词,得到一个个词word={word_1……word_n},其中word_n表示第n个字。
例如:为了让大家更好地模拟真实考场,我们完全仿照真题样式设计了这套“大黑”哟!
分词后得到的结果是:为了/让/大家/更好/地/模拟/真实/考场/,/我们/完全/仿照/真题/样式//设计了/这/套/“/大/黑/”/哟/!/
2.对文档中的文字利用分字代码进行分字,得到一个个单字char={char_1……char_n},其中char_n表示第n个字。
例如:为了让大家更好地模拟真实考场,我们完全仿照真题样式设计了这套“大黑”哟!
字分割后得到的结果是:为/了/让/大/家/更/好/地/模/拟/真/实/考/场/,/我/们/完/全/仿/照/真/题/样/式/设/计/了/这/套/“/大/黑/”/哟/!/
同时对字的组成部分进行拆分,得到他的组成部分pict={pict_1……pict_n},其中pict_n表示的字的组成部分。
3.同时对字的组成部分进行拆分,得到他的组成部分pict={pict_1……pict_n},其中pict_n表示的字的组成部分。
例如:朝/明
其象形词根组成部分分割得到的是:十/日/十/月/日/月
然后,用blstm对词根进行建模,获得一个包含字内部信息的字向量,然后再利用双向lstm的前向lstm对字序列进行建模生成一个包含字序列以及字序列上文信息的向量表示charfi,同理后向lstm反向读取字序列,将字序列以及字序列的下文信息表示为charbi,然后将charfi和charbi连接形成一个包含字序列以及上下文信息的词表示:
wd=[charfi:charbi]
此表示方法获得了字序列与词语之间的关系,与主流的stanford的glove和google的word2vec相比,此方法对模型性能具有一个显著的提升。此方法可应用于其他需词表示的深度神经网络模型中。
图3本发明所使用的blstm-crf示意图;
由图2模型进行序列建模生成一个包含字序列信息和字内部信息的词向量,然后输入到图3模型中进行简历解析。
具体如下:
由ablstm对非结构化文本简历的字序列进行建模之后,获得一个包含字序列信息的中文词语序列:
wd=(wd1,...,wdi)
将词序列输入到blstm神经网络中,利用blstm中的前向lstm将词wdi及其上文信息表示为wordfi,同理利用后向lstm将词wdi及其上文信息表示为wordbi,最终将blstm的前向lstm输出结果和后向lstm的输出结果级联起来形成一个新的特征表示ht=[wordfi:wordbi],ht直接作为特征来为每个输出yt做出独立的标记决策,此方法有效的将词及其上下文信息用向量表示,此方法有效的将词及其上下文信息用向量表示;
在本文的非结构化文本简历信息解析任务中,输出标签之间有一个非常强的依赖关系。例如:b-org.company标签的后面不能跟着i-gsp.company或除i-org.company以外的其他标签。因此为了建模标签的依赖关系,本文采用crf来建模整个句子的输出标签。假定得到非结构化文本简历信息的输出目标序列(即对应的标签序列)为:
y=(y1,...,yn)
为了有效的获得非结构化文本简历信息的目标序列,模型的分值公式定义如下:
其中p表示的是双向lstm的输出分值矩阵,其大小为n×k,k表示的是目标标签的数量,n表示词序列的长度。a表示的是转移分值矩阵。y0和yn+1分别表示的是一个序列的开始和结束的标志,因此a方阵的大小为k+2;
在所有简历信息的标签序列上,crf生成目标序列y的概率为:
其中yx代表简历信息序列x对应的所有可能标签序列;
在训练过程中,为了获得简历信息正确的标签序列,将采用最大化正确标签序列的条件似然对数概率:
由上述的表述可以看出本文训练神经网络是为了尽可能输出非结构化简历信息有效的标签序列。因此如下公式给出的最大分值公式用于预测最合适的标签序列:
因为是对输出之间的相互作用进行建模因此采用动态规划的方法计算件似然对数概率公司中的求和以及最大分值公式中的最大后验序列y*。
最终获得中文简历中所需要关注的信息元的实体标签,然后根据信息元的实体标签,解析出相应的中文简历中所需要关注的信息元,根据规则处理成统一的格式对解析出来的简历信息元进行存储。
- 还没有人留言评论。精彩留言会获得点赞!