一种评估、以及预测深度学习模型中层计算时间的方法与流程
本发明涉及深度学习技术领域;具体地,涉及一种评估、以及预测深度学习模型中层计算时间的方法。
背景技术:
深度学习目前已经在诸如金融保险、安防监控等个行业得到了广泛应用。深度学习的核心方法是使用神经网络模型分析和描述数据的特征。训练一个深度学习的模型需要以秒为数量级的频率进行多轮迭代。其次,相较于线性算法,深度学习往往需要更为庞大的数据训练方能取得准确的模型。训练一个神经网络模型往往需要数天或者数周的时间才能完成。
正是因为上面的原因,仅靠单一节点来训练深度学习模型显然需要花费更长的时间;对此,当前主流的深度学习框架均支持通过并行计算实现分布式训练模型。广义上的分布式训练包括两种:一种是数据并行,另一种是模型并行。在数据并行的场景下,通过预测深度学习模型的训练时间,对动辄数天、数周、数月的深度学习模型训练过程中的资源调配、模型评估等都有着重要的意义。特别是在多个不同的模型训练任务并存的情形下,提前预测训练时间,合理调配资源,将大幅提高资源利用率。对此,通过少量层的测量历史日志,并结合相似层关系复用上述层的时间,将大大降低预测模型训练中迭代时间时的开销。
此外,测量/预测深度学习模型中各层计算时间,对模型以层粒度进行针对性调整也有着重要意义。
技术实现要素:
有鉴于此,本发明提供一种评估、以及预测深度学习模型中层计算时间的方法。该方法根据层间相似程度在待预测层两侧选择历史日志中的相似层计算时间赋值最大、最小计算时间,以此评估、以及预测层计算时间,使利用相似层计算时间估算的待预测层计算时间在可接受范围内。
一方面,本发明提供一种评估层计算时间估算的方法。
上述的评估层计算时间估算的方法,包括:
对于任一的待预测层,
分别将该待预测层的最大计算时间、最小计算时间初始化为0和无穷大;
从历史日志中,
选择在偏序关系上计算时间大于该待预测层的相似层,将这些相似层计算时间按大小排序,选择其中的最小值作为该待预测层的最大计算时间;
选择在偏序关系上计算时间小于该待预测层的相似层,将这些相似层计算时间按大小排序,选择其中的最大值作为该待预测层的最小计算时间;
根据上述的最大计算时间、最小计算时间评估估算是否可接受:
若该最大计算时间、最小计算时间之差小于设定的阈值,则该估算可接受;
否则,该估算不可接受;
其中,根据关键属性确定上述的相似层:
对于任一的该待预测层的相同类型的层,若其与该待预测层全部的相应的关键属性都相同,则其为该待预测层的相似层;上述的相同类型层是指其层输入、输出规模均与待预测层相同的层,其中的层输入、输出规模均为上述层属性中的一种;而关键属性是指全部层属性中对计算时间存在非线性影响的层属性;对应地,全部层属性中对计算时间存在线性影响的层属性,为非关键属性;
恰是由于非关键属性对计算时间的线性影响,故,上述的偏序关系是指存在于待预测层和其部分或全部的相似层中的如下偏序关系:
对它们中任一的正向影响层计算时间的非关键属性,若该非关键属性单调增加时使其计算时间单调增加,
且对它们中任一的反向影响层计算时间的非关键属性,若该非关键属性单调减小时使其计算时间单调增加;
上述的阈值可以设定为最小计算时间乘上系数γ;γ值将限定每层估算的误差。
可选地,前面述及的相似层计算时间,是根据测量获得的,而非估算获得的,以避免放大(以及潜在地级联放大)以该方法估算时的误差。
另一方面,本发明提供一种利用相似层估算层计算时间的方法。
结合第一方面,上述的利用相似层估算层计算时间的方法,包括:
对于任一的待预测层,
若以第一方面述及的方法评估结果为估算可接受,则根据该方法述及的最大计算时间、最小计算时间估算该待预测层的计算时间。
可选地,对前面述及的最大计算时间、最小计算时间求平均值,作为该待预测层的计算时间。
又一方面,本发明提供一种利用相似层预测深度学习模型中层计算时间的方法。
结合第一、第二方面,上述的利用相似层预测深度学习模型中层计算时间的方法,包括:
对任一的待预测层,
先以第一方面述及的方法评估估算是否可接受,
若是,则根据第二方面述及的方法估算该待预测层的计算时间;
否则,测量该待预测层的计算时间。
本发明提供的技术方案,具有着诸多有益效果:
一,低开销;本发明尽可能地复用了已知的层计算时间,避免相同层或相似层的重复测量。
二,预测本地化;即使是对在分布式机器学习平台上训练的模型或是利用在线资源训练的模型,通过本发明预测其计算时间时,完全可以在一台设备上完成。
附图说明
为更加清楚地说明本发明实施例或现有技术中的技术方案,下面将对本发明中一部分实施例涉及的附图做简单介绍。
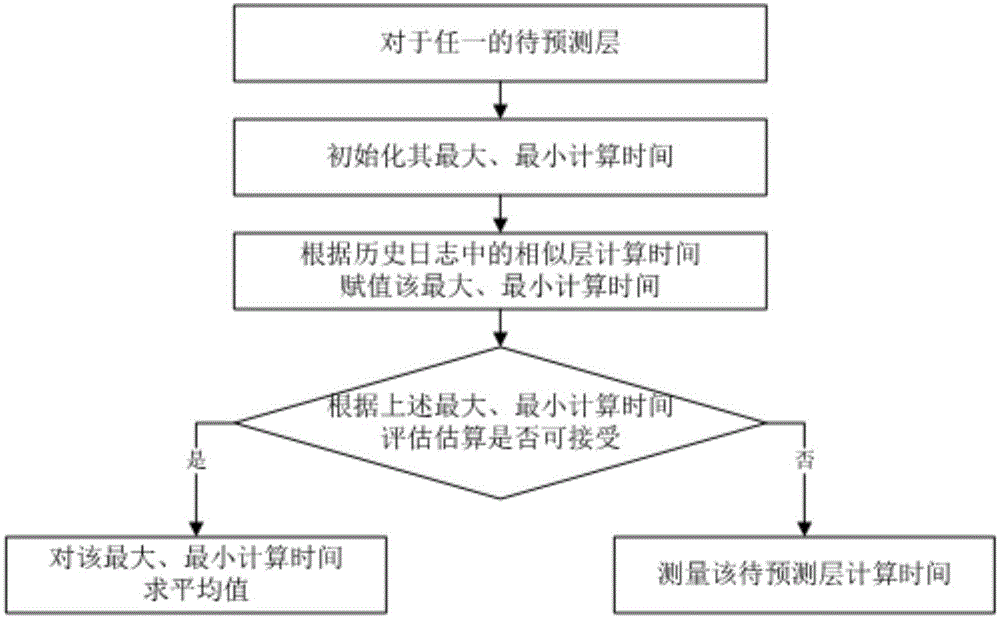
图1为本发明一实施例提供的一种利用相似层预测深度学习模型中层计算时间的方法的流程示意图。
具体实施方式
下面结合本发明实施例的附图,对本发明实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在无需创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
以下为本发明的一个优选实施例。
图1为该实施例提供的一种利用相似层预测深度学习模型中层计算时间的方法的流程示意图。以上实施例展示了在tensorflow框架下实现的模型的层计算时间的预测。
在预测前,通过数据流图解析,获得模型中的层;
其中,流水线图是采用json定义的,该数据流图描述文件将每个层描述为json条目,包括层名称和层属性;
以下为其中一个模型数据流图的描述文件示例,
[
{
"layer_name":"conv1","layer_id":1,"tf_layer_name":"conv2d","params":{
"input_size":112,"kernel_size":3,"ch_in":3,"ch_out":64,"batch_size":32,"stride":1}
},
{
"layer_name":"fc1","layer_id":2,"input_id":1,"tf_layer_name":"dense",
"params":{"num_units":1000}
},
...
]
在获得模型的层后,如图1所示,
对其中每个待预测的层,
首先,将该待预测层的最大计算时间、最小计算时间初始化为0和无穷大;
然后,查询历史日志,根据其中的合适的相似层计算时间赋值上述的最大、最小计算时间:
选择在偏序关系上计算时间大于该待预测层的相似层,将这些相似层计算时间按大小排序,选择其中的最小值作为该待预测层的最大计算时间;
选择在偏序关系上计算时间小于该待预测层的相似层,将这些相似层计算时间按大小排序,选择其中的最大值作为该待预测层的最小计算时间;
其中,对相似层、偏序关系及其相关概念定义如下:
a相似层
对任意两个或两个以上的相同类型的层,若它们的任一相应的关键属性均相同,则认为它们为相似的层;
其中,对前面述及的一些概念,如
相同类型的层:输入、输出规模都相同的层;
关键属性:是指对计算时间影响为非线性的层属性;在本实施例中,kernel_size等对计算时间影响是非线性的,并不会使计算时间随着属性值增大而对应地变化,被认为是关键属性;
非关键属性:对应地,是指对计算时间影响为线性的层属性;在本实施例中,batch_size、channels等对计算时间影响则是线性的,能够使计算时间随着属性值增大而对应地增大,被认为是非关键属性。
b偏序关系
该偏序关系是指存在在部分或全部相似层间的如下的偏序关系:
对上述的相似层,
对它们中任一的正向影响层计算时间的非关键属性,若该非关键属性单调增加时使其计算时间单调增加,
且对它们中任一的反向影响层计算时间的非关键属性,若该非关键属性单调减小时使其计算时间单调增加。
在本实施例中,
对任意的相似层集合中,若该集合中的两个或两个以上的层的channels和batchsize(均为正向影响的非关键属性)属性值均存在着相同的大小关系,同时其他的任一非关键属性也存在与之相应的情形(其中,反向影响的非关键属性存在相反的大小关系),则认为二者存在上述偏序关系。据此,即可对这些层的计算时间做初步的定性排序。,
接下来,根据上述的最大计算时间、最小计算时间评估估算是否可接受:
若该最大计算时间、最小计算时间之差小于设定的阈值,则该估算可接受;则对该最大计算时间、最小计算时间求平均值,作为该待预测层的计算时间;
否则,该估算不可接受,则测量该待预测层的计算时间。
其中,上述的阈值可以设定为最小计算时间乘上系数γ;γ值限定了每层估算的误差。而以上又是以上、下限(最大计算时间、最小计算时间)均值作为估算的计算时间的,故在用于估算的层计算时间是测量值时,可以将误差限定在γ与(最大计算时间-最小计算时间)/2的乘积值范围内。在本实施例中,兼顾效率和准确度,γ被设定为20%。
以上所述仅为本发明的具体实施方式,但本发明的保护范围并不局限于此。
- 还没有人留言评论。精彩留言会获得点赞!