一种单变点检测方法、系统、设备及存储介质与流程
本发明涉及数据统计
技术领域:
,尤其涉及一种单变点检测方法、系统、设备及存储介质。
背景技术:
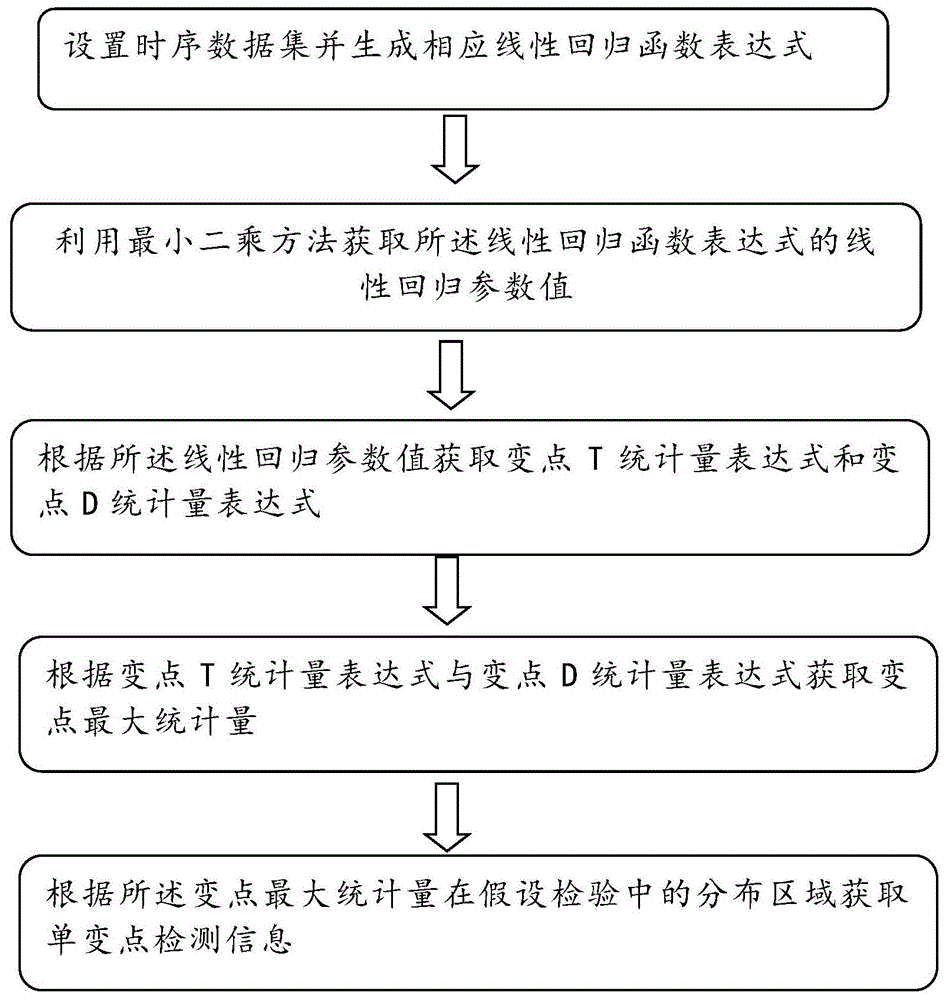
:变点是指一个序列或过程中,当某个统计特性在某时间点受系统性因素而非偶然性因素影响发生变化。传统的变点检测大多基于统计原理,包括最小二乘法、极大似然法、贝叶斯方法等。随着统计控制过程广泛应用于工业生产之中,休哈特控制图(shewhart)、累积和控制图(cusum)以及指数加权滑动平均控制图(ewma)常用于检验时序数据的变点位置。基本上,使用累积和图通过侦测时序均值的偏移,来识别无趋势序列的变点位置。但是,物流收派件量时序数据具有明显的长期增长趋势、季节效应和节假日的外生冲击,现有技术不能解决该类复杂时序数据的单变点检测问题。物流网点拆分合并现象普遍。在数据上表现为某个时间点前后,时序数据在假设检验中的分布区域改变、部分均值偏移等统计特征的变化。现有时间序列预测方法本质上是通过对一条历史序列的趋势项、周期项、外生冲击(节假日、购物节、天气等)、滞后项等时序分量进行分解,一次拟合各分量参数再加总得到预测值。为了灵活刻画较长时期(一般取超过1年的历史件量)的趋势变化,采用分段拟合线性回归,即将整条序列随机分割成n(n>=1)段,对每一段全量数据建模,得到每一个分段的趋势项。变点的存在会影响对整条序列增长或者降低趋势的估计,从而导致整体预测误差的偏大。因此,如何准确的识别变点个数和检测变点位置,成为物流业务预测的关键性问题。但是目前工业上应用广泛的cusum算法对带有趋势性的时间序列做变点检测,往往得到时序的中点即为变点位置的错误结论。历史时序数据作为预测模型的输入,直接关系该条序列数据质量和预测准确率的高低,但是现有变点检测算法无法准确地对历史时序数据集的变点进行检测。技术实现要素:为了解决上述技术问题,本发明的目的在于提供一种单变点检测方法、系统及设备。根据本发明的一个方面,提供了一种单变点检测方法,包括:设置时序数据集并生成相应线性回归函数表达式;利用最小二乘方法获取线性回归函数表达式的线性回归参数值;根据线性回归参数值获取变点t统计量表达式和变点d统计量表达式;根据变点t统计量表达式与变点d统计量表达式获取变点最大统计量;根据变点最大统计量在假设检验中的分布区域获取单变点检测信息。设置时序数据集并生成相应线性回归函数表达式包括:根据输入的时间长度设置时序数据集;根据时序数据集的均值便宜因子、出现变点前的序列均值、随机误差和线性斜率生成线性回归函数表达式。根据变点t统计量表达式与变点d统计量表达式获取变点最大统计量包括:根据变点t统计量表达式和变点d统计量表达式获取变点t统计量与变点d统计量的关系式;根据变点时间趋于时间边界设置防止变点逼近边界点参数;根据变点t统计量与变点d统计量的关系式和防止变点逼近边界点参数获取变点最大统计量。根据变点最大统计量在假设检验中的分布区域获取单变点检测信息包括:建立序列没有变点的原假设和序列有一个变点的备择假设;设置防止变点逼近边界点参数的取值和相应置信度;根据防止变点逼近边界点参数的取值和相应置信度计算检验最大统计量的临界值;根据所述检验最大统计量的临界值判断所述最大统计量是否落在拒绝域:是,则判定接受备择假设并将最大统计量所在时间点作为变点输出;否,则判定接受原假设。根据本发明的另一个方面,提供了一种单变点检测系统,包括:函数生成单元,配置用于设置时序数据集并生成相应线性回归函数表达式;参数获取单元,配置用于利用最小二乘方法获取线性回归函数表达式的线性回归参数值;统计代入单元,配置用于根据线性回归参数值获取变点t统计量表达式和变点d统计量表达式;最大统计单元,配置用于根据变点t统计量表达式与变点d统计量表达式获取变点最大统计量;信息获取单元,配置用于根据变点最大统计量在假设检验中的分布区域获取单变点检测信息。函数生成单元包括:集合设置模块,配置用于根据输入的时间长度设置时序数据集;函数生成模块,配置用于根据时序数据集的均值便宜因子、出现变点前的序列均值、随机误差和线性斜率生成线性回归函数表达式。最大统计单元包括:关系获取模块,配置用于根据变点t统计量表达式和变点d统计量表达式获取变点t统计量与变点d统计量的关系式;边界设置模块,配置用于根据变点时间趋于时间边界设置防止变点逼近边界点参数;最大统计模块,配置用于根据变点t统计量与变点d统计量的关系式和防止变点逼近边界点参数获取变点最大统计量。信息获取单元包括:假设建立模块,配置用于建立序列没有变点的原假设和序列有一个变点的备择假设;置信设置模块,配置用于设置防止变点逼近边界点参数的取值和相应置信度;临界计算模块,配置用于根据防止变点逼近边界点参数的取值和相应置信度计算检验最大统计量的临界值;统计判断模块,配置用于根据所述检验最大统计量的临界值判断所述最大统计量是否落在拒绝域;变点输出模块,配置用于判定接受备择假设并将最大统计量所在时间点作为变点输出;变点否定模块,配置用于判定接受原假设。一个或多个处理器;存储器,用于存储一个或多个程序,当一个或多个程序被一个或多个处理器执行时,使得一个或多个处理器执行如上任一项的方法。根据本发明的另一个方面,提供了一种存储有计算机程序的计算机可读存储介质,该程序被处理器执行时实现如上任一项的方法。与现有技术相比,本发明具有以下有益效果:1、本发明示例的一种单变点检测方法,通过设置时序数据集并生成相应的线性回归函数表达式,根据线性回归函数表达式的线性回归参数获取变点t统计量表达式与变点d统计量表达式,由变点t统计量表达式与变点d统计量表达式即可计算得到最大统计量,根据最大统计量在假设检验中的分布区域即可获取变点检测信息,该方法能够检测有长期趋势的时间序列的变点,且变点检测准确率高于现有检测方法。2、本发明示例的一种单变点检测系统,通过函数生成单元设置时序数据集并生成相应的线性回归函数表达式,参数获取单元获取线性回归函数表达式的线性回归参数后,统计带入单元根据线性回归函数表达式的线性回归参数获取变点t统计量表达式与变点d统计量表达式,最大统计单元由变点t统计量表达式与变点d统计量表达式即可计算得到最大统计量,信息获取单元根据最大统计量在假设检验中的分布区域即可获取变点检测信息,该系统能够检测有长期趋势的时间序列的变点,且变点检测准确率高于现有技术。3、本发明中示例的设备,通过处理器执行单变点检测方法,能够更准确地检测时序数据集的变点。4、本发明中示例的可读存储介质,储存有被处理器执行时实现的所述单变点检测方法,准确地检测时序数据集的变点。附图说明图1为本发明提供的方法的流程示意图。图2为假设检验原理图。图3为本发明提供的方法的效果图。具体实施方式为了更好的了解本发明的技术方案,下面结合具体实施例、说明书附图对本发明作进一步说明。实施例1:本实施例的一种单变点检测系统,包括:函数生成单元,配置用于设置时序数据集并生成相应线性回归函数表达式;函数生成单元包括:集合设置模块,配置用于根据输入的时间长度设置时序数据集;函数生成模块,配置用于根据时序数据集的均值便宜因子、出现变点前的序列均值、随机误差和线性斜率生成线性回归函数表达式。参数获取单元,配置用于利用最小二乘方法获取所线性回归函数表达式的线性回归参数值;统计代入单元,配置用于根据线性回归参数值获取变点t统计量表达式和变点d统计量表达式;最大统计单元,配置用于根据变点t统计量表达式与变点d统计量表达式获取变点最大统计量;最大统计单元包括:关系获取模块,配置用于根据变点t统计量表达式和变点d统计量表达式获取变点t统计量与变点d统计量的关系式;边界设置模块,配置用于根据变点时间趋于时间边界设置防止变点逼近边界点参数;最大统计模块,配置用于根据变点t统计量与变点d统计量的关系式和防止变点逼近边界点参数获取变点最大统计量。信息获取单元,配置用于根据最大统计量在假设检验中的分布区域获取变点检测信息,变点获取单元包括:假设建立模块,配置用于建立序列没有变点的原假设和序列有一个变点的备择假设;置信设置模块,配置用于设置防止变点逼近边界点参数的取值和相应置信度;临界计算模块,配置用于根据防止变点逼近边界点参数的取值和相应置信度计算检验最大统计量的临界值;统计判断模块,配置用于根据检验最大统计量的临界值判断最大统计量是否落在拒绝域;变点输出模块,配置用于判定接受备择假设并将最大统计量所在时间点作为变点输出;变点否定模块,配置用于判定接受原假设。本实施例的单变点检测对应的检测方法,包括以下步骤:s1、设置时序数据集并生成相应线性回归函数表达式。采集历史数据,设定时序数据集的时间长度n,时间序列长期趋势采用线性回归拟合,假设一个时序数据集它具有上升或下降趋势且存在一个未知的变点c,线性回归函数表达式如下:xt=μ+βt+δt+∈t其中,代表均值偏移的因子,即均值在时间c+1上增加δ;μ为出现变点前的序列均值,∈t为随机误差,β为线性斜率。s2、利用最小二乘方法获取所述线性回归函数表达式的线性回归参数值。线性回归一般采用最小二乘方法进行参数估计,最小化目标函数得到线性回归参数的估计值:斜率时间点在t=1,2,…c间的均值:增量由式(1)、(2)(3)得到:s3、根据所述线性回归参数值获取变点t统计量表达式和变点d统计量表达式。t统计量公式为:令r=c/n,将式(5)和式(6)代入t统计量公式,可得已知d统计量渐进性质,将t统计量和d统计量联系起来得到:s4、根据变点t统计量表达式与变点d统计量表达式获取变点最大统计量。根据式(7)和式(8)可得变点t统计量与变点d统计量的关系式:考虑到变点c逼近t=1和t=n时r(1-r)会趋近于0,故加入限定条件后构建检验统计量(变点最大统计量),则式(9)中h是防止变点逼近边界点。s5、根据最大统计量在假设检验中的分布区域获取单变点检测信息。建立原假设和备择假设:原假设h0:序列没有变点;备择假设h1:序列有一个变点。设置h取值和h值对应的置信度,h取值和对应置信度为统计学的常规方法。参考图2,在统计学中,拒绝域为大于统计量对应的临界值的区域,本实施例中检验最大统计量的临界值的确定过程如下:根据d统计量的渐进分布性质(d统计量为渐进布朗运动,可以作为公理使用),可以得到置信度与d统计量的临界值的对应表,如表1:表1置信度与d统计量临界值对应表置信度临界值90.01.22495.01.35897.51.48099.01.62899.91.949将表1中的d统计量临界值代入式(8),即将临界值作为d(c)的取值,计算得到|t(c)|的取值,并将|t(c)|的取值和h取值代入式(9)计算t(c)2的值作为相应的检验最大统计量的临界值。由此可以计算出不同h取值和不同置信度对应的检验最大统计量的临界值,如表2所示。表2,不同h取值和不同置信度对应的检验最大统计量的临界值本实施例设定h=0.05,由上表可以得到变点最大统计量的置信度相应的检验最大统计量的临界值为20.114。将式(8)代入式(9),计算最大统计量的实际值,当最大统计量实际值足够大落在拒绝域即则拒绝原假设,接受备择假设。即该序列有一个变点且发生在时间即变点c即为最大统计量所在的时间点。利用本发明提供的单变点检测方法对某个物流网点的业务数据进行分析,该网点历史上存在一次业务拆分,选择该网点2015.01.01至2018.01.01的派件量时序。参考图3,可以看到采用本发明提供的单变点检测方法的变点检测效果,图中的变点位置十分明显。在现有广义可加prophet预测模型的基础上,对比两种趋势分段拟合方法外推60天的预测效果:平均分段和先识别变点再平均分段。如下表,将变点检测应用到业务预测中,预测准确率提高约2%。本实施例的一个或多个处理器;存储器,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器执行如上任一项所述的单变点检测方法,能够检测有长期趋势的时间序列的变点,且变点检测准确率高于现有检测方法。本实施例的一种存储有计算机程序的计算机可读存储介质,该程序被处理器执行时实现如上任一项所述的单变点检测方法,便于单变点检测系统的使用及推广。以上描述仅为本申请的较佳实施例以及对所运用技术原理的说明。本领域技术人员应当理解,本申请中所涉及的发明范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离所述发明构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。例如上述特征与本申请中公开的(但不限于)具有类似功能。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1