一种结合彩色和深度信息的图像显著目标检测方法与流程
本发明属于图像处理技术领域,具体涉及一种结合彩色和深度信息的图像显著目标检测方法。
背景技术:
图像显著目标检测旨在从包含大量信息的图像场景中检测出重要的、引人注意的区域。研究发现人类的视觉机制总是能够快速从场景中找到这类区域并对其进行分析,而很少对其余并不显著的区域加以处理,显著目标检测任务目的即在于构造自动化的工具模拟此视觉机制,提取图像中的显著区域。对于后续处理来说,以显著区域作为处理单元,可以节省对全图进行处理的时间,提高图像的处理效率。因此,显著目标检测被广泛地应用在图像分割、图像检索和目标识别等领域,是当前计算机视觉领域的热点研究方向之一。
以往大部分的图像显著目标检测算法仅在彩色图像上实现,没有利用其他的补充信息。随着三维感知传感器技术的发展,物体的距离信息是人类可以获取并利用的重要线索。在彩色图像中,目标物体有时与背景或者周围区域拥有相似的纹理、颜色等特征,但与周围物体存在着距离上的差异,此时深度信息通常能够给出具有判别性的线索。这意味着,我们可以结合彩色和深度信息,使其相互补充,共同预测,从而使得显著目标检测任务能够获得表现更好、更具鲁棒性的预测结果。
然而如何对彩色信息与深度信息进行更好地融合仍是一个值得思考的问题,以往的方法对于两种不同模态结合方式的挖掘依然不够深入,只有充分发挥彩色信息与深度信息各自有效的内容,才能有益于最终的检测结果。另外,保持预测显著图的边缘细节也是帮助检测结果获得更好表现的一个关注点。
技术实现要素:
本发明的目的在于克服现有技术的不足,提出新的融合方式,更充分地利用彩色信息和深度信息各自的有效部分,改进结合彩色和深度信息的显著目标检测效果,同时加入边缘损失函数,保持预测显著图的边缘细节。
本发明采用的技术方案是包括如下步骤:
步骤1)采集多幅已知显著目标区域的彩色图像rgb及其对应的深度图像d以及彩色图像rgb和深度图像d对应的显著目标真值图y;显著目标真值图y为显著目标所在区域和非显著目标所在区域的标签,实质上为二值化图。显著目标真值图
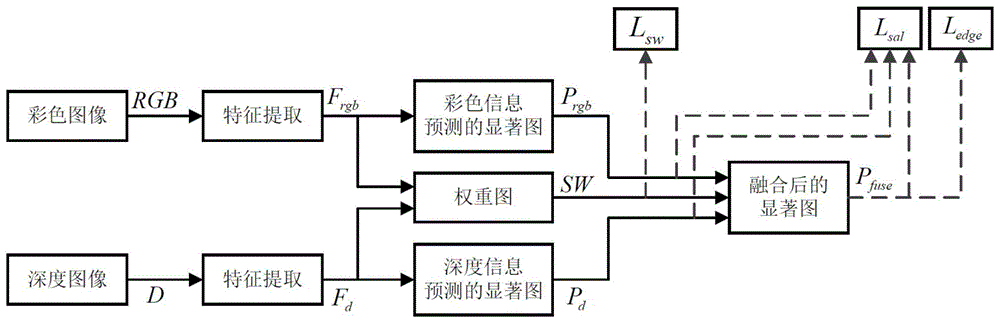
步骤2)构建显著目标检测的神经网络,包括有:将彩色图像rgb和深度图像d输入神经网络得到彩色信息预测的显著图prgb和深度信息预测的显著图pd,神经网络设置一路分支并结合显著目标真值图y预测获得一张权重图sw,权重图sw用于帮助彩色信息预测的显著图prgb和深度信息预测的显著图pd的加权融合,彩色信息预测的显著图prgb和深度信息预测的显著图pd根据权重图sw得到融合后的显著目标检测图pfuse;
步骤3)构建显著图损失函数lsal、权重图损失函数lsw和显著图边缘损失函数ledge三个损失函数,将三个损失函数计算获得的损失函数值通过反向传播进行迭代计算,从而对神经网络进行训练;
步骤4)采用训练后的神经网络处理未知显著区域的彩色图像rgb及其对应的深度图像d,获得待测图像的显著目标检测结果。
本发明特别设计了权重图sw及其标签图,用于神经网络中彩色和深度信息的融合处理,能够帮助具有深度信息的彩色图像实现显著目标的准确检测。
所述步骤2)包括依次连接的特征提取模块、权重图预测模块和显著目标检测图融合模块,具体为:
步骤2.1):将彩色图像rgb和深度图像d输入特征提取模块,输出得到彩色图像特征图frgb和深度图像特征图fd,利用获得的彩色图像特征图frgb和深度图像特征图fd预测得到显著图,即分别得到彩色信息预测的显著图prgb和深度信息预测的显著图pd;
步骤2.2):将彩色图像特征图frgb与深度图像特征图fd级联后作为新的分支输出,得到新特征图frgbd,将新特征图frgbd输入到权重图预测模块预测得到权重图sw;
步骤2.3):显著目标检测图融合模块利用权重图sw对彩色信息预测的显著图prgb和深度信息预测的显著图pd进行加权融合,得到融合后的显著目标检测图pfuse。
所述步骤(2.1)中,彩色图像rgb和深度图像d均采用相同方式进行处理得到图像特征图frgb和深度图像特征图fd,以下以彩色图像rgb为例说明:
所述的特征提取模块包括五个依次连接的小模块,每个小模块均由卷积层、激活层、池化层依次连接构成,小模块中的参数相同,每个小模块各自输出一张特征图,五张特征图分别为f1、f2、f3、f4和f5,然后采用一种往前递进的方式反向融合五张特征图,得到最终输出的特征图;
采用一种往前递进的方式反向融合五张特征图,具体为:在得到五张特征图后,采用以下公式从特征图f5开始进行计算得到递进融合后的特征图f4,再依次以此处理最后得到递进融合后第1个小模块的特征图
其中,
最后以递进融合后第1个小模块的特征图
prgb=h(w*frgb+b)
其中,*表示卷积操作,w和b分别表示卷积层中卷积核的权重和偏置,h(·)表示sigmoid函数。
所述步骤2.2)中,将彩色图像特征图frgb和深度图像特征图fd进行级联之后,通过融合函数输出得到新特征图frgbd,融合函数由一个卷积层和一个激活层组成,利用新特征图frgbd处理预测权重图sw,具体采用以下公式进行计算:
frgbd=g({frgb,fd})
sw=h(w*frgbd+b)
并且,为权重图sw构建一个标签图ysw,标签图ysw由彩色信息预测的显著图prgb与显著目标真值图y计算得到,具体通过以下公式进行计算:
ysw=prgb·y+(1-prgb)·(1-y)
其中,·表示彩色信息预测的显著图prgb与显著目标真值图y之间的点乘运算。标签ysw用于在训练神经网络的过程中监督权重图sw的学习训练过程。如果图像中位置i上的像素点在prgb和y中均显著或均不显著,则被设为高权重,反之则被设为低权重。
所述步骤2.3)中,利用权重图sw采用以下公式对彩色信息预测的显著图prgb和深度信息预测的显著图pd进行加权融合,得到融合后的显著目标检测图pfuse:
pfuse=sw·prgb+(1-sw)·pd。
所述步骤3)中,三个损失函数的计算过程具体为:
步骤3.1)将彩色信息预测的显著图prgb、深度信息预测的显著图pd和融合后的显著目标检测图pfuse输入到显著图损失函数lsal中计算预测显著图的损失函数值,具体采用以下公式计算:
lsal=lrgb+ld+lfuse
其中,θ表示神经网络中的所有参数,i表示像素点在显著目标真值图y中的位置,yi表示显著目标真值图y中在位置i上像素点的显著值,prgb(yi=1|rgb,d;θ)表示彩色信息预测的显著图prgb中位置i上的像素点属于显著像素点的概率,pd(yi=1|rgb,d;θ)表示深度信息预测的显著图pd中位置i上的像素点属于显著像素点的概率,pfuse(yi=1|rgb,d;θ)表示融合后的显著目标检测图pfuse中位置i上的像素点属于显著像素点的概率;lrgb、ld和lfuse分别表示彩色信息预测的显著图prgb、深度信息预测的显著图pd和融合后的显著目标检测图pfuse对应的损失函数,lsal表示三张预测显著图对应的lrgb、ld和lfuse损失函数之和;
步骤3.2):将权重图sw输入到权重图损失函数lsw中计算预测权重图sw的损失函数值,权重图损失函数lsw采用以下公式:
其中,yisw表示标签图ysw中在位置i上像素点的权重值,psw(yisw=1|rgb,d;θ)表示预测的权重图中位置i上的像素点属于高权重的概率;
步骤3.3):对显著目标检测图pfuse提取边缘信息e,将边缘信息e输入到显著图边缘损失函数ledge中计算预测边缘信息e的损失函数值,所述的边缘信息由图像的梯度得到,具体采用以下公式计算:
其中,
所述步骤(4)具体为:针对未知显著目标真值区域的待测彩色图像及其对应的深度图像,输入训练后且去掉所有损失函数的神经网络中,预测得到显著目标检测图pfuse,显著目标检测图pfuse上的值代表了图像每个像素点属于显著像素点的概率值,最后选择概率值大于阈值η的像素点作为显著像素点,其余作为非显著像素点。
优选的,神经网络的训练是利用adam优化器训练。
本发明方法构造一个深度神经网络,在普通显著目标检测网络的基础上增加一路权重图预测的分支,同时构建一个权重图的标签监督权重图的学习,利用学习得到的权重图指导彩色信息预测的显著图和深度信息预测的显著图之间的融合,此外,本发明方法在普通显著图损失函数的基础上,加入边缘保持项从而保持显著目标区域的边缘细节。
本发明的有益效果是:
本发明方法利用权重图模块学习彩色和深度信息各部分的权重,以此指导两种模态信息各自预测的显著图的融合,更加充分地利用彩色信息和深度信息各自的有效部分,同时在损失函数中加入了边缘保持项改善边缘细节。
本发明和以往结合彩色和深度信息的图像显著目标检测方法相比,取得了更好的效果。
附图说明
图1是本发明方法的流程示意图。
图2-5是采用现有图像显著目标检测方法与本发明方法进行图像显著目标检测的结果对比图,其中:
图2-5中的(a)表示为待检测彩色图像rgb;
图2-5中的(b)表示为(a)的深度图像d;
图2-5中的(c)表示为gp算法(renj,gongx,yul,etal.exploitingglobalpriorsforrgb-dsaliencydetection[c]//proceedingsoftheieeeconferenceoncomputervisionandpatternrecognitionworkshops.2015:25-32.)得到的显著目标图像;
图2-5中的(d)表示为lbe算法(fengd,barnesn,yous,etal.localbackgroundenclosureforrgb-dsalientobjectdetection[c]//proceedingsoftheieeeconferenceoncomputervisionandpatternrecognition.2016:2343-2350.)得到的显著目标图像;
图2-5中的(e)表示为ctmf算法(hanj,chenh,liun,etal.cnns-basedrgb-dsaliencydetectionviacross-viewtransferandmultiviewfusion[j].ieeetransactionsoncybernetics,2017.)得到的显著目标图像;
图2-5中的(f)表示为mpci算法(chenh,liy,sud.multi-modalfusionnetworkwithmulti-scalemulti-pathandcross-modalinteractionsforrgb-dsalientobjectdetection[j].patternrecognition,2019,86:376-385.)得到的显著目标图像;
图2-5中的(g)表示为pca算法(chenh,liy.progressivelycomplementarity-awarefusionnetworkforrgb-dsalientobjectdetection[c]//proceedingsoftheieeeconferenceoncomputervisionandpatternrecognition.2018:3051-3060.)得到的显著目标图像;
图2-5中的(h)表示通过本发明得到的显著目标检测图像;
图2-5中的(i)表示为人工标注的显著目标真值图像;
图6是采用现有的图像显著目标检测方法与本发明方法进行图像显著目标检测后的f-measure柱状图的对比。
具体实施方式
下面结合附图与实施例对本发明进行进一步说明。
本发明所述的显著目标一般是指在图像中和周围对比强烈的引起人视觉注意的目标物体。按照本发明发明内容的完整方法实施的实施例及其实施过程是:
(1)采集一幅已知显著目标区域的彩色图像rgb及其对应的深度图像d,显著目标真值图为y;其中显著目标真值图
(2)构建显著目标检测的神经网络。
具体包括特征提取模块、权重图预测模块和显著目标检测图融合模块。彩色图像rgb和深度图像d输入特征提取模块,输出得到彩色图像特征图frgb和深度图像特征图fd,利用获得的彩色图像特征图frgb和深度图像特征图fd预测得到显著图,即分别得到彩色信息预测的显著图prgb和深度信息预测的显著图pd;将彩色图像特征图frgb与深度图像特征图fd级联后,作为神经网络一路新的分支,对其处理得到新的特征图frgbd,通过特征图frgbd预测权重图sw;利用获得的权重图sw对彩色信息预测的显著图prgb和深度信息预测的显著图pd的进行加权融合,得到融合后的显著目标检测图pfuse;
使用vgg16模型中的卷积层作为特征提取模块中的五个基本的小模块,得到不同感受野的五张特征图f1,f2,f3,f4和f5,然后采用一种往前递进的方式反向融合五张特征图,得到彩色图像rgb和深度图像d的特征图frgb和fd;
具体实施中,vgg16模型采用simonyank,zissermana.verydeepconvolutionalnetworksforlarge-scaleimagerecognition文献中的计算方法。
(3)构建损失函数模块,利用adam优化器训练神经网络。
具体包括显著图损失函数模块lsal、权重图损失函数模块lsw和边缘损失函数模块ledge。将彩色信息预测的显著图prgb、深度信息预测的显著图pd和融合后的显著目标检测图pfuse输入到显著图损失函数模块lsal计算预测显著图的损失函数值;将权重图sw输入到权重图损失函数模块lsw中计算预测权重图的损失函数值;对显著目标检测图提取边缘信息e,将边缘信息e输入到边缘损失函数模块ledge中计算预测边缘信息的损失函数值;采用adam优化器训练神经网络,获得神经网络的参数。
具体实施中,学习率设置为10-4,训练至模型收敛,保存神经网络的参数。
(4)训练结束后,针对未知显著目标真值区域的待测彩色图像rgb及其对应的深度图像d,输入训练后且去掉了所有损失函数模块的神经网络中,预测得到显著目标检测图pfuse,显著目标检测图pfuse上的值代表了图像每个像素点属于显著像素点的概率值,最后选择概率值大于阈值η的像素点作为显著像素点,其余作为非显著像素点。
本实施例最后在三个标准数据集njud(jur,gel,gengw,etal.depthsaliencybasedonanisotropiccenter-surrounddifference[c]//imageprocessing(icip),2014ieeeinternationalconferenceon.ieee,2014:1115-1119.)、nlpr(pengh,lib,xiongw,etal.rgbdsalientobjectdetection:abenchmarkandalgorithms[c]//europeanconferenceoncomputervision.springer,cham,2014:92-109.)和stereo(niuy,gengy,lix,etal.leveragingstereopsisforsaliencyanalysis[c]//computervisionandpatternrecognition(cvpr),2012ieeeconferenceon.ieee,2012:454-461.)上评估,在njud中随机抽取1400个样本,nlpr中抽取650个样本组成训练集,另外在njud中随机抽取100个样本,nlpr中抽取50个样本组成验证集,剩余的样本与stereo组成测试集。采用本发明方法对测试集中的数据进行显著目标检测,然后采用其他现有的图像显著目标检测方法进行检测,得出的检测结果如图2至图5所示。各幅图中(a)为待检测彩色图像,(b)为对应的深度信息,(c)为gp算法得到的显著图像,(d)为lbe算法得到的显著图像,(e)为ctmf算法得到的显著图像,(f)为mpci算法得到的显著图像,(g)为pca算法得到的显著图像,(h)为本发明算法得到的显著图像,(i)为人工标注的显著目标真值图像。
实施例一如图2所示,图2展示了处于背景中的一个人像,与图2的(i)相比,通过本发明方法得到的图2的(h)与(i)最为接近,并且在人像与图2的背景较为接近的情况下,本发明方法所得到的图像与(c)~(g)相比较为准确。
实施例二如图3所示,图3展示了在海景植物的背景下的一个手拿箱的潜水员,本发明在图3的背景图像较为丰富的情况下,图3(h)提取到的显著目标仍较为准确。
实施例三如图4所示,图4展示了一个置于展示座上的物品,与人工标注的显著目标真值图像的图4(i)相比,本发明的图4的(h)最为精确。
实施例四如图5所示,图5展示了处于草坪之上的一个带有三角架的天文镜,由图5的(f)、(g)、(h)的对比可以看出,本发明的图5(h)较为清晰、准确,更符合图5的(i)的图像特点。
为了对本发明方法的实施例一、二、三和四进行客观数据指标评价,选用f-measure指标量化评价不同方法的实验结果,如图6所示。f-measure是精确率和召回率的综合考量,其中精确率定义为被正确检测到的显著性像素点数目与检测到的显著性像素点数目之比,召回率定义为被正确检测到的显著性像素点数目与真正的显著性像素点数目之比,f-measure的定义如下式:
本发明实施例中取值:β2=0.3。
由图2至图6可以得出结论:与其他现有显著性方法进行比较,采用本发明图像显著性检测方法的表现结果更好,能更充分地利用彩色信息和深度信息中的有效内容,更加完整和准确地从背景中提取显著物体。
本方法首先生成彩色图像和深度图像的特征图与各自预测的显著图,然后将两张特征图输入权重图预测模块,接着利用输出的权重图指导彩色信息预测的显著图与深度信息预测的显著图,得到融合后的最终检测结果。本发明能够选择彩色及深度信息预测的显著图各自最有效的部分进行融合,同时保持边缘细节,与以往结合彩色和深度信息的图像显著目标检测方法相比取得了更好的效果。
- 还没有人留言评论。精彩留言会获得点赞!