一种模拟遮挡阴影增强植物数据样本的方法与流程
本发明属于农产品图像识别和智能计算领域,特别涉及一种模拟遮挡阴影增强植物数据样本的方法。
技术背景
农业领域,采集植物数据样本难,特别一些不常见的样本更难于采集。在深度学习中,收集数据样本进行训练时,某些分类数据样本严重不足、数据集过小容易造成模型的过拟合。通常会对数据样本进行旋转、平移、翻转、尺度变换、基于图像饱和度与对比度变化、噪声、模糊等方法,来扩展和增强数据样本;但是以上增强数据样本的方法难以满足复杂的植物生长环境。
技术实现要素:
根据上述的技术问题,本发明结合农业现场环境情况,针对农业现场的植物叶、花、果样本,常常被其他植物叶、花、果遮挡而产生遮挡阴影的特性,采用模拟遮挡阴影的方法增强数据样本,本方法更加贴近实际场景,为增强数据样本提供了另一种方法。具体技术方案如下:
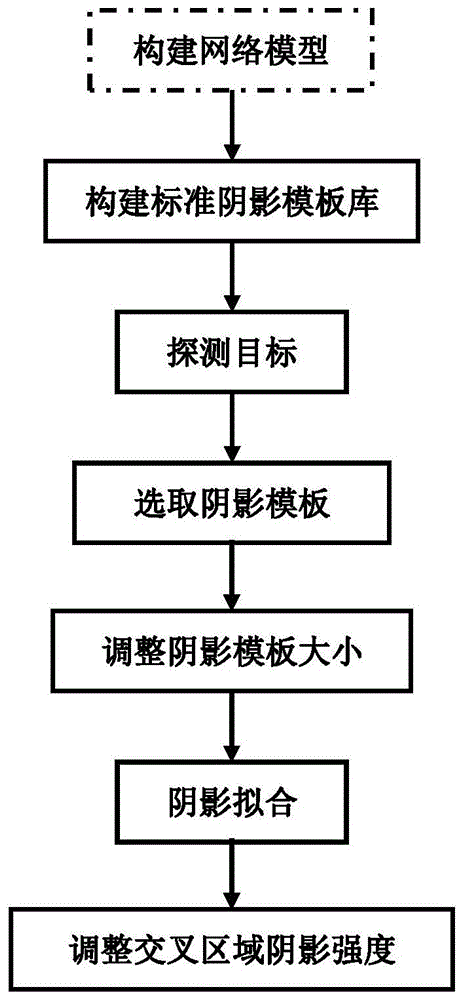
一种模拟遮挡阴影增强植物数据样本的方法,具体步骤如下:
s1:选取植物最典型的阴影模板若干,构建标准阴影模板库;
s2:输入图片,由网络模型进行识别,返回探测出图片中需要增加阴影的目标;
s3:从标准阴影模板库随机选取任一阴影模板;
s4:调整选取的阴影模板的大小;
s5:将调整大小后的阴影模板在输入图片中移动,并使阴影模板与输入图片的识别目标交叉;
s6:根据目标的阴影强度,对阴影模板与输入图片的识别目标交叉的区域进行亮度调整,获得新的数据样本。
进一步地,在步骤s1中,根据植物所属作物,选取植物最典型的形状和姿态的阴影模板若干。
进一步地,还包括步骤s0,建立目标植物的网络模型,具体步骤如下:
s0-1:拍摄不同的含有目标植物的若干照片;
s0-2:利用labelme标注工具对s0-1获取的图片中的目标进行标注,框出图片中的目标;
s0-3:对s0-2标注好的图片进行预处理,包括数据增强和归一化处理;
s0-4:将s0-3预处理后的图片按照5∶1的比例将数据分成训练集和测试集;
s0-5:训练集中的数据通过fasterrcnn深度神经网络提取图片的特征信息,然后预测图片中目标的位置信息,经多次迭代后生成网络参数;
s0-6:测试集中的数据通过fasterrcnn深度神经网络对s0-5生成的网络参数进行测试,获得测试图片的位置信息与测试图片在s0-2标注的位置信息进行比较,最终通过平均精度map和召回率recall进行评估;
s0-7:重复步骤s0-5和s0-6,直至map和recall达到需求;
s0-8:将最终训练好的网络参数,加载到fasterrcnn网络模型当中。
进一步地,在步骤s2中,网络模型进行识别输入图片后,返回探测出图片中需要增加阴影的目标的可信度和位置信息集合。
进一步地,在步骤s4中,将阴影模板扩大k(s)倍,得到调整后的阴影模板;k(s)为阴影模板放大倍数,k(s)根据以下公式获得:
其中,area目标t为目标面积,area阴影模板为阴影模板面积,f为阴影大小系数,f>0,fmin为阴影大小系数最小值,fmax为阴影大小系数最大值。
进一步地,在步骤s5中,将调整大小后的阴影模板在输入图片中随机水平和垂直移动。
进一步地,在步骤s5中,阴影模板与输入图片的识别目标交叉后的面积交并比iou处于ioumin与ioumax之间,并获得交叉位置的位置信息集合。
进一步地,在步骤s6中,目标的阴影强度lδ根据以下公式获得:
lδ=-l0*fl
其中,l0为目标的平均亮度,fl为阴影系数;
进一步地,目标的平均亮度l0通过在目标区域内随机取样若干个像素点的亮度值获得,具体根据以下公式获得:
其中,x为取样数量,li为第i个样本的亮度值。
进一步地,将阴影模板与输入图片的识别目标交叉的区域的每个像素点的亮度调整为目标的阴影强度lδ,获得新的数据样本。
本发明的有益效果为:
本发明采用模拟遮挡阴影的方法增强数据样本,本方法更加贴近植物生长实际场景,为增强数据样本提供了另一种方法。
附图说明
附图1为本发明的一种模拟遮挡阴影增强植物数据样本的方法的实现流程图。
具体实施方式
以下通过附图具体对本发明的方案进行阐述。
一种模拟遮挡阴影增强植物数据样本的方法,以柑橘叶子为例,针对柑橘叶子经常相互遮挡而产生遮挡阴影的特性,模拟遮挡阴影的方法增强数据样本。包括如下步骤:
s0:建立网络模型;
s0-1:拍摄不同的含有柑橘叶子的若干照片作为柑橘叶子样本库,图片数量不少于5000张;
s0-2:利用labelme标注工具对s0-1获取的图片中的柑橘叶子进行标注,框出图片中的柑橘叶子;
s0-3:对s0-2标注好的图片进行预处理,使用opencv的rotateimage对图片进行旋转、使用lightimage对图片亮度进行处理,实现数据增强;使用caffe的scalelayer和batchnormlayer实现数据归一化处理;增加样本数量,以提高算法鲁棒性,使网络能够更好的进行优化;
s0-4:将s0-3预处理后的图片按照5∶1的比例将数据分成训练集和测试集;
s0-5:训练集中的数据通过fasterrcnn深度神经网络提取图片的特征信息,特征信息包括纹理信息、色彩信息、形状信息,然后预测图片中目标的位置信息,经50万次迭代后生成网络参数;
s0-6:测试集中的数据通过fasterrcnn深度神经网络对s0-5生成的网络参数进行测试,获得测试图片的位置信息与测试图片在s0-2标注的位置信息进行比较,最终通过平均精度map和召回率recall进行评估;
s0-7:重复步骤s0-5和s0-6,直至map和recall达到需求;
s0-8:将最终训练好的网络参数,加载到fasterrcnn网络模型当中。
s1:构建标准阴影模板库;
根据柑橘所属作物,根据柑橘叶子形状、姿态,选取柑10张橘叶子最典型的形状和姿态的阴影模板m。
s2:探测目标;
输入图片a,图片a由fasterrcnn网络模型进行识别,返回检测到的柑橘叶子目标t的可信度和位置信息集合:
″label″:″t″,″pa″:″0.9613″,″points″:[[1067.68,188.40],[839.68,333.40],[721.68,606.40]…]
其中:
″label″:″t″表示检测目标名称为t;
″pa″:″0.9613″表示可信度为96.13%,本实施例取可信度最高的探测结果为探测目标,也可根据需要,按可信度从高到低,取topn个为探测目标;
points为目标位置信息集合,本实施例返回20个坐标点。
s3:选取阴影模板;
从标准阴影模板库随机选取任一阴影模板m;
m(n)=rand(1,10)
本实施例选取第二个阴影模板m(n)=2。
s4:调整阴影模板大小;
将阴影模板m扩大k(s)倍,得到调整后的阴影模板m′;k(s)为阴影模板放大倍数,k(s)根据以下公式获得:
其中,area目标t为目标面积,area阴影模板为阴影模板面积,f为阴影大小系数,f>0,fmin为阴影大小系数最小值,fmax为阴影大小系数最大值。根据k(s)把阴影模板扩大k倍,获得放大后阴影模板m′。
s5:阴影拟合;
以输入图片a为底板,将调整大小后的阴影模板m′在输入图片a中随机水平和垂直移动,并使阴影模板与输入图片的识别目标交叉d;调整大小后的阴影模板m′与输入图片a的识别目标t交叉后的面积交并比iou处于ioumin与ioumax之间,并获得交叉位置d的位置信息集合。
″label″:″iou1″,″points″:[[789.49,473.68],[751.49,603.68],[724.49,749.68]…]
其中:
″label″:″iou1″为交叉区域;
″points″为交叉位置信息集合。
s6:调整交叉区域阴影强度
随机取样目标t目标区域内的10个像素点的亮度值,并通过以下公式获取目标t的平均亮度值l0:
其中,x为取样数量,li为第i个样本的亮度值;平均亮度值l0的值越大,表明光照强度大,阴影的强度大,阴影就更明显,阴影强度与平均亮度成正比。
目标的阴影强度lδ根据以下公式获得:
lδ=-l0*fl
其中,fl为阴影系数;阴影系数fl为负号表示调暗,正号表示调亮,本实施例中取负号。
本实施例中,随机取样目标t的10个像素点后得到的平均亮度值l0=112,阴影系数fl取值为fl=0.68,得到的阴影强度lδ=-76。
遍历交叉区域d,将交叉区域d中每个像素的亮度进行调整为-76,获得新的数据样本。
- 还没有人留言评论。精彩留言会获得点赞!