一种监控场景下的基于非机动车再识别的行人检索方法与流程
本发明属于计算机视觉技术领域,涉及一种监控场景下的基于非机动车再识别的行人检索方法。
背景技术:
进入大数据时代,面对日益普及的视频监控技术,如何从海量图像或视频中快速地检索到出特定人员变得越来越重要。而对目前的监控场景来说,尤其是交通监控,有相当多的摄像头由于架设高度、位置、图像分辨率等因素的影响,获取高质量的用于检索的图像数据是非常困难的。
相反地,这些监控场景架设的摄像头中出现的目标中有很大一部分是非机动车,包含自行车、电瓶车等。同时,这些监控场景对基于非机动车再识别的行人检索方法的需求也变得日益迫切,比如在“飞抢”案件中、入室盗窃后作案嫌疑人乘坐非机动车逃离现场等需求场景,就需要从监控视频中快速地检索出嫌疑人。目前采用的技术还是人工来对可能经过的每个摄像头的视频进行查看,所耗费的人力、物力资源是很大的。因此需要一个基于非机动车再识别的行人检索方法来辅助办案人员,提高检索效率。
目前的行人检索方法主要建立在行人再识别方法上,比如专利[cn106960182a]集成不同的特征来增加特征的表现能力,从而提高行人检索性能。然而,由于监控场景中摄像头架设问题,获取高质量行人数据很困难;同时,单纯的行人数据中只有行人,与人驾驶非机动车的数据有很大的不同,无法采用行人再识别的技术来很好地解决监控场景下的行人检索问题。
目前的行人检索主要借助基于行人再识别的方法来从海量数据中检索出特定人员,有两个不足:
1、数据来源受限:对监控场景来说,目前的摄像头基本都架设于主干道路的上方用来抓取机动车辆与非机动车辆,由于摄像头高度、角度、分辨率等的影响,很难获取到满足行人检索的图像数据,而由于单纯的行人数据很难获取,会带来两个问题:
1-1、缺少数据,将会使得基于行人再识别的行人检索方法性能不够鲁棒,无法为办案人员提供有效的筛选结果。
1-2、在进行检索时,由于数据库中的行人图像非常少,绝大多数是非机动车与机动车图像。而单纯的行人图像与驾驶非机动车的行人图像,在特征表达上有很大的不同,这会进一步降低基于行人再识别的行人检索性能。
2、面对日益增加的视频监控需求,目前尚没有针对非机动车再识别的行人检索方法,而在诸如“飞抢”等案件中,需要将驾驶非机动车的人检索出来。
针对以上存在的问题,需要提出新的基于非机动车再识别的行人检索方法,使得此方法能够满足现在视频监控场景的需求。
技术实现要素:
对于基于行人再识别的行人检索方法来说,由于采用了端到端的深度学习策略,需要大量的行人数据,而目前监控场景中摄像头的架设不利于行人数据的采集;同时,采用行人数据学习到的模型只能用来对人进行识别,无法对人驾驶非机动车这种情况进行识别。而对目前监控场景的需求来说,更多的是需要对驾驶非机动车的行人进行检索。
针对这个问题,本发明提出了一个新的基于非机动车再识别的行人检索方法,对训练样本的采集、制作、训练以及行人检索进行设计,从而使得行人检索方法最终能够达到视频监控场景的需求。
本发明包括以下步骤:
建立非机动车再识别模型,具体是:
一.数据采集
a1、从监控场景获取原始视频:根据摄像头的分布位置找到可能有同一目标同时经过若干摄像头的场景,采集这些摄像头的监控视频。
a2、截取相同行人视频片段:对每个摄像头一个小时的视频片段进行播放、查找,从这些个摄像头中找到相同的行人,一旦找到,则将行人从出现到离开这段时间内的视频截取出来保存为视频片段。
a3、抽帧、标框:对得到的视频片段进行抽帧,将视频片段保存为图片,然后对得到的图片进行标注,将出现的相同行人用矩形框进行标注,将图片与矩形框标注文件进行存储。
二.训练样本制作
b1、抠图:根据得到的图片与矩形框标注文件,将矩形框对应的行人抠出来保存为图片。
b2、扩边:经过抠图之后,得到紧致包围行人的图片。
b3、编号:对得到的行人图片进行编号。
三.训练模型
模型采用14层的卷积网络、全连接层与softmax损失函数。
行人检索,具体是:
c1、将监控场景中数据库的所有图片作为输入送入训练好的模型,每张图片会得到一个m维的特征向量。
c2、将待检索的非机动车图像送入训练好的模型,得到一个m维的特征向量。
c3、采用如下公式计算由步骤c2得到的特征向量与由步骤c1得到的z个特征向量的差异,得到z个数值:
这里qj表示由步骤c2得到的m维特征的第j个分量;gij表示数据库中第i张图片得到m维特征的第j个分量;di表示待检索的图片与数据库中第i张图片的特征差异,i∈[0,z],j∈[0,m]。
c4、对由步骤c3得到的z个数值进行升序排序并保留其排序前的索引,取排在前几位的结果,将索引所对应的图片进行显示,由办案人员进行最终确定是否为同一个行人。
本发明的有益效果:
1、数据来源更实际:采用的数据来源为目前监控场景中已有的摄像头,无需再另行架设摄像头,极大的降低了成本。
2、数据形式更统一:训练数据与最终检索时用到的图像数据一致,均为人驾驶非机动车,这会使的方法的检索成功率更高
3、方法可信性更高:本检索方法提供一些候选图像,然后再经过人工筛选,使得检索结果更加准确。
附图说明
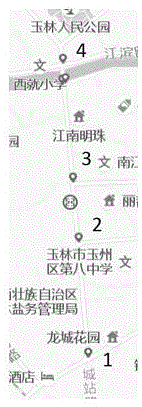
图1.摄像头排布示意图;
图2.矩形框标注不同摄像头中的同一个人;
图3.抠图后及扩边后结果图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他的实施例,都属于本发明保护的范围。
由于无法采用现有的基于行人再识别技术的行人检索方法来进行监控场景下的行人检索,因此本发明设计了一个新的基于非机动车再识别的行人检索方法,包含四个部分:数据采集、训练样本制作、网络训练以及行人检索。
一.数据采集
当使用深度学习进行端到端的非机动车再识别模型训练时,需要大量标注好的训练数据,因此采集训练数据是第一步,包括以下几个步骤:
1、从监控场景获取原始视频:根据摄像头的分布位置找到可能有同一目标同时经过若干摄像头的场景,采集这些摄像头的监控视频。假设当前采集场景有三个摄像头a、b、c,每个摄像头各采集一天的视频片段。
2、截取相同行人视频片段:对a、b、c三个摄像头一个小时的视频片段进行播放、查找,从这三个摄像头中找到相同的行人,一旦找到,则将行人从出现到离开这段时间内的视频截取出来保存为视频片段
3、抽帧、标框:对2得到的视频片段进行抽帧,将视频片段保存为图片,然后对得到的图片进行标注,将出现的相同行人用矩形框进行标注,将图片与矩形框标注文件进行存储。
二.训练样本制作
经过第一部分数据采集之后,假设得到了1000个不同行人的图片集合,接下来要制作训练样本,包括以下几个步骤:
1、抠图:根据第一部分第3步得到的图片与矩形框标注文件,将矩形框对应的行人抠出来保存为图片。
2、扩边:经过第1步抠图之后,得到了紧致包围行人的图片。为了使网络学习到更加鲁棒的特征,需要对样本进行旋转等数据增广操作,旋转之后的图片比输入图片要大,通常的做法是进行补零。补零之后,图片内容发生的变化,与原图片信息有较大差异,为了解决这个问题,对抠好的图片进行扩边,使得扩边之后的图片中含有一部分背景,这样在进行旋转等增广操作后,图片中保留的仍是原图的信息。
3、编号:对1000个行人图片进行编号,比如第一个行人在a摄像头的第一张图片编号为00000_a_1,同一个摄像头下的第二张图片编号为00000_a_2;b摄像头中第一个行人的第一张图片编号为00000_b_1;c摄像头中第一个行人的第三张图片编号为00000_c_3;第二个行人在a摄像头的第一张图片编号为00001_a_1;以此类推,将1000个行人的图片均进行编号。
三.训练
经过第一、二两部分的准备,训练样本已经准备完毕,将这些制作好的样本作为模型的输入进行学习:
1、模型:采用14层的卷积网络、全连接层与softmax损失函数,分为以下四个部分:
1-1、卷积参数为:128*3*3*32,128*3*3*64,其中128是一次输入图片的个数,3*3是卷积核的大小,32与64是输出特征图的个数,本部分包含2个128*3*3*32的卷积层,每个卷积层后面跟一个批归一化层(batchnormalizationlayer),最后跟一个2*2的最大池化层(maxpoolinglayer)。
1-2、卷积参数为:128*3*3*128,其中128是一次输入图片的个数,3*3是卷积核的大小,128是输出特征图的个数,本部分包含3个128*3*3*128的卷积层,每个卷积层后面跟一个批归一化层(batchnormalizationlayer),最后跟一个2*2的最大池化层(maxpoolinglayer)。
1-3、卷积参数为:128*3*3*256,其中128是一次输入图片的个数,3*3是卷积核的大小,256是输出特征图的个数,本部分包含4个128*3*3*256的卷积层,每个卷积层后面跟一个批归一化层(batchnormalizationlayer),最后跟一个2*2的最大池化层(maxpoolinglayer)。
1-4、卷积参数为:128*3*3*m,其中128是一次输入图片的个数,3*3是卷积核的大小,m是输出特征图的个数,本部分包含5个128*3*3*m的卷积层,每个卷积层后面跟一个批归一化层(batchnormalizationlayer),最后跟一个全局池化层(globalpoolinglayer),输出为128*1*1*m,这里的m是模型最终采用的特征长度。
1-5、全连接层,假设训练样本有5000个不同的行人,则此全连接层的分类数为5000。
1-6、损失函数:采用如下所示的多分类softmax损失函数:
这里n表示训练样本总数。
2、数据增广:为了使训练得到的模型具有更好的泛华性能,需要进行数据增广,采用旋转、镜像、平移、随机裁剪、高斯噪音、颜色空间扰动这些数据增广操作。
四.行人检索
经过上述三部分的工作,已经得到训练好的模型,执行以下步骤来进行行人检索:
1-1、将监控场景中数据库的所有图片作为输入送入训练好的模型,每张图片会得到一个m维的特征向量,假设数据库中有10000张图片,则会得到10000个m维的特征向量。
1-2、将待检索的非机动车图像送入训练好的模型,得到一个m维的特征向量。
1-3、采用如下公式计算由1-2得到的特征向量与由1-1得到的10000个特征向量的差异,会得到10000个数值:
这里qj表示由2得到的m维特征的第j个分量;gij表示数据库中第i张图片得到m维特征的第j个分量;di表示待检索的图片与数据库中第i张图片的特征差异,i∈[0,10000],j∈[0,m]。
1-4、对由3得到的10000个数值进行升序排序并保留其排序前的索引,取排在前5的结果,假设它们排序前的索引分别是10、55、125、561、7845,则将数据库中的编号为10、55、125、561、7845的这些图片进行显示,由办案人员进行最终确定是否为同一个行人。
实施例:
例如,当某地发生“飞抢”案件时,首先调取案发地监控,截取作案人员图片,然后在监控数据库中进行查找,可以迅速地在其它摄像头中找到目标嫌疑人,从而可以描绘出其逃跑路线,为破案提供非常有利的线索。
数据采集:
假设有如图1所标的四个摄像头1,2,3,4,可以看到同一目标可能会同时经过这四个摄像头,将这四个摄像头的视频数据进行采集,通常采集一天的即可。
将这四个摄像头中的同一个人从出现到离开的视频片段保存下来。
对截取到的视频片段进行抽帧、标框,得到图2的结果:
样本制作:
1、根据标注框,将目标从大图中抠出来。
2、对抠出的图片进行扩充,以方便数据增广,见图3,从图片边界可以看出扩边前后的差别。
3、对所有图片进行编号,比如00000_a_1.jpg,00001_b_2.jpg等训练:
将制作好的训练样本作为网络的输入进行训练,得到训练好的模型,在训练的同时要进行数据增广来增加模型的泛华能力,采用的增广操作有旋转、镜像、平移、随机裁剪、高斯噪音、颜色空间扰动。
行人检索
在得到训练好的模型之后,对输入的待检索的图片与数据库中的所有图片都提取特征向量,然后计算待检索图片特征与数据库中所有图片特征的差值进行升序排序,取排在前5的图片并将它们在排序前的索引对应的图片作为候选给办案人员进行人工筛选来确认最终检索到的行人。
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围,应当理解,本发明并不限于这里所描述的实现方案,这些实现方案描述的目的在于帮助本领域中的技术人员实践本发明。
- 还没有人留言评论。精彩留言会获得点赞!