基于U-Net网络的互联网广告点击率预估方法与流程
本发明属于互联网技术领域,涉及一种互联网广告点击率预估方法,具体涉及一种基于u-net网络的互联网广告点击率预估方法,可应用于互联网广告投放领域。
背景技术:
随着电子商务的发展,互联网广告已成为一种新媒介广告进入人们的生活。通常,广告主在投放广告之前,希望了解网站上某广告位的已投放广告的点击率,并根据了解的点击率来制定预订广告位的决策。为给广告主提供预定广告位置决策的依据,可以对某广告位置上所投放的广告的点击率进行预估,以供广告主参考。现有技术进行广告点击率预估通常采用的方法是:用待预估广告的历史数据训练出预估模型,上述历史数据包括待预估广告的特征和实际点击率,将待预估广告的特征作为预估模型的输入,将预估模型的输出结果作为待预估广告的预估点击率。其中,模型进行点击率预估的精度,即预估的准确率依赖于模型针对输入数据特征的泛化能力,即对原始特征进行隐含特征提取的能力,其中隐含特征包含原始特征的交叉组合特征和原始特征的深层特征。
互联网广告点击率预估方法根据所使用基础算法不同,主要分为基于机器学习模型的预估方法和基于深度神经网络模型的预估方法。其中,基于机器学习模型的预估方法主要利用矩阵分解方式对互联网广告数据进行点击率预估,随着网络用户不断地增加,无法应对互联网广告数据量大的问题。
目前基于深度学习的互联网广告点击率预估方法的研究刚刚起步,其主要思想是利用深度神经网络进行训练数据的高阶特征的提取,从而实现互联网广告的点击率预估,该方法提高了在复杂场景下的点击率预估精度。例如,guo等人于2017年5月在ijcai发表了一篇题为“deepfm:afactorization-machinebasedneuralnetworkforctrprediction”的文章,公开了一种宽线性模型与深度神经网络模型相结合的互联网广告点击率预估方法,首先利用编码模型将稀疏的原始特征编码为因子分解模型所需的数据格式,然后利用因子分解模型对原始特征进行两两交叉组合得到交叉特征向量,并对该特征向量进行线性组合学习,得到特征的相关性,然后利用映射层将高维稀疏的类别特征映射为低维稠密的向量,与其他原始连续特征拼接,输入到多层神经网络中,输出学习到的新特征,最后将两个模型的输出进行拼接,实现点击率预估,得到互联网广告点击率预估结果。该方法完成了数据相关性学习和泛化学习,实现了与原始数据有共性的特征和具有多样性的特征的提取,但是该方法深度模块仅使用两层全连接网络,模型泛化能力不足,无法有效获取原始数据的深层特征,导致点击率预估精度降低。
目前互联网广告投放领域主要使用的神经网络模型是全连接网络,模型结构简单,泛化能力不足,从而导致点击率预估精度低,相较于全连接网络,u-net网络中包含一个获取上下文信息的由多个卷积层组成的收缩路径以及一个对称的由多个转置卷积层和卷积层组成的扩张路径,利用收缩路径提取输入数据的特征,同时利用扩张路径对收缩路径所获得的特征再次进行提取,从而提高模型对输入数据的泛化能力,获取更多的深层特征。
技术实现要素:
本发明的目的在于针对上述现有技术存在的缺陷,提出一种基于u-net网络的互联网广告点击率预估方法,用以解决现有互联网广告点击率预估方法中存在的预估精度低的技术问题。
为实现上述目的,本发明采取的技术方案包括如下步骤:
(1)获取训练数据集和测试数据集:
(1a)选取n个按行排列且包含有原始特征和实际点击率的互联网广告数据,其中,每个广告数据的原始特征,包括广告所针对人群的特征和广告对应产品的特征,广告所针对人群的特征和广告对应产品的特征均由分类型特征和数值型特征组成,n≥500000;
(1b)对互联网广告数据按行进行缺失值填补,并从得到的不包含空值的n个按行排列的互联网广告数据中选取m个广告数据作为测试数据,剩余广告数据作为训练数据,m≥20000;
(1c)分别对训练数据和测试数据中的分类型特征进行类别编码,对数值型特征进行归一化,得到训练数据集和测试数据集;
(2)获取原始特征索引矩阵和原始特征值矩阵:
(2a)将训练数据集和测试数据集中数值型特征包含的数值分别按照从小到大的顺序进行排列,并将排列结果中每个数值对应的序号作为数值型特征索引,将排列结果中的每个数值作为数值型特征值,同时将训练数据集和测试数据集中分类型特征包含的类别分别按照从小到大的顺序进行排列,并将排列结果中的每个类别对应的序号作为分类型特征索引,将排列结果中的每个类别作为分类型特征值,分类型特征值的大小统一定义为a,a≥1;
(2b)将数值型特征索引和分类型特征索引的组合保存为原始特征索引矩阵,同时将数值型特征值和分类型特征值的组合保存为原始特征值矩阵;
(3)基于深度卷积神经网络u-net构建点击率预估模型:
将深度卷积神经网络u-net收缩路径中的深度卷积模块替换为由p个c×c卷积层组成的深度收缩模块,并在深度收缩模块与该u-net的输入层之间添加宽度线性收缩模块,将扩张路径中的嵌套卷积模块替换为包含p个转置卷积层和p个d×d卷积层的扩张模块,同时将扩张路径中的输出层替换为softmax分类器,得到点击率预估模型,其中,p≥2,c≥1,d≥1;
(4)对点击率预估模型进行训练:
(4a)将训练数据集对应的原始特征索引矩阵和原始特征值矩阵输入点击率预估模型中,利用宽度线性收缩模块,对原始特征索引矩阵与原始特征值矩阵进行线性组合,得到线性组合矩阵并保存;
(4b)利用深度收缩模块,对线性组合矩阵进行卷积,得到p组高阶特征矩阵并保存;
(4c)利用扩张模块所包含的p个转置卷积层对p组高阶特征矩阵进行转置卷积,然后利用扩张模块所包含的p个d×d卷积层对转置卷积的结果进行卷积,并对卷积的结果进行组合,得到组合高阶特征矩阵,然后对该组合高阶特征矩阵和线性组合矩阵以及p组高阶特征矩阵进行拼接并输出;
(4d)利用softmax分类器对扩张模块的输出结果进行分类,得到点击率预估结果并输出;
(4e)利用softmax分类器输出的点击率预估结果和训练数据集的实际点击率结果计算损失函数值,训练至损失函数值在j代内不再减小时停止,得到训练好的点击率预估模型,j≥50
(5)获取互联网广告点击率预估结果:
将测试数据集对应的特征索引矩阵和特征值矩阵输入步骤(4)训练好的点击率预估模型,得到互联网广告点击率预估结果。
本发明与现有的技术相比,具有以下优点:
1.本发明将深度卷积神经网络u-net收缩路径中的深度卷积模块替换为适用于点击率预估领域的深度收缩模块,并在深度收缩模块与该u-net的输入层之间添加宽度线性收缩模块,将扩张路径中的嵌套卷积模块替换为适用于点击率预估领域的扩张模块,将点击率预估领域的宽线性模型与深度卷积神经网络模型相结合,解决的现有模型中深度神经网络模型过于简单,对互联网广告数据的泛化能力差,无法有效获取原始数据的深层特征,导致点击率预估精度降低的问题,加强了对互联网广告数据深层特征的提取,有效提高了点击率预估的精度。
2.本发明在进行互联网广告数据点击率预估模型训练之前,利用类别编码和归一化后的原始训练数据集和测试数据集,针对两个数据集中的类别型特征和数值型特征分别进行特征索引矩阵和特征值矩阵的获取,并将分类型特征的特征值矩阵中元素大小统一定义为常值,最后将数值型特征索引和分类型特征索引的组合保存为原始特征索引矩阵,同时将数值型特征值和分类型特征值的组合保存为原始特征值矩阵,解决了现有模型中训练数据没有按照特征的不同类型进行特征矩阵提取和预处理,从而导致特征信息复杂冗余,预估精度降低的问题,加入了对互联网广告数据中不同类型特征的有针对性的特征矩阵的提取和预处理,进一步提高了点击率预估的精度。
附图说明
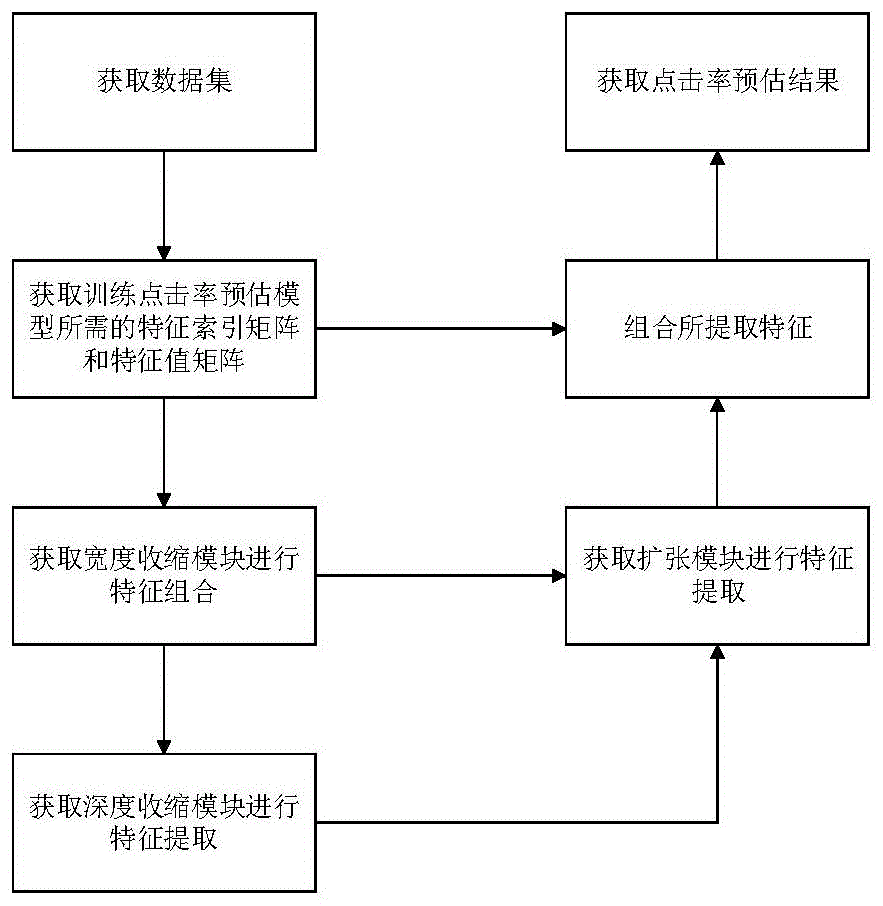
图1是本发明的实现流程图;
图2是本发明适用的点击率预估模型的结构示意图;
图3是本发明与现有技术点击率预估精度的仿真对比图。
具体实施方式
下面结合附图和具体实施例,对本发明作进一步的详细描述。
参照图1,本发明包括如下步骤:
步骤1)获取训练数据集和测试数据集:
(1a)随机选取n个按行排列且包含有原始特征和实际点击率的互联网广告数据,本实例中n=500000,其中,对广告数据采用按行排列方式使得每行数据代表用户对广告的一次操作,每行包含多列,一列代表一个用户或广告的原始特征,每个广告数据的原始特征,包括广告所针对人群的特征和广告对应产品的特征,广告所针对人群的特征和广告对应产品的特征,均由分类型特征和数值型特征组成;
(1b)对互联网广告数据按行进行缺失值填补,并从得到的不包含空值的n个按行排列的互联网广告数据中选取m个广告数据作为测试数据,剩余广告数据作为训练数据,本实例中所使用的缺失值填补值为-1,m=50000,保证所使用数据集具备完整性,不存在缺失值,同时训练集与测试集的比例为10%,保证测试数据集数量充足;
(1c)分别对训练数据和测试数据中的分类型特征进行类别编码,对数值型特征归一化至0到1之间,得到数据分布较为均匀的训练数据集和测试数据集;
步骤2)获取原始特征索引矩阵和原始特征值矩阵:
(2a)将训练数据集和测试数据集中数值型特征包含的数值分别按照从小到大的顺序进行排列,并将排列结果中每个数值对应的序号作为数值型特征索引,将排列结果中的每个数值作为数值型特征值,同时将训练数据集和测试数据集中分类型特征包含的类别分别按照从小到大的顺序进行排列,并将排列结果中的每个类别对应的序号作为分类型特征索引,将排列结果中的每个类别作为分类型特征值,分类型特征值的大小统一定义为a,在本实例中,a=1,对于分类型特征,只考虑将分类型特征的分类属性,分类型特征值的大小没有实际意义,采用统一定义常值降低分类型特征值的影响;
(2b)将数值型特征索引和分类型特征索引的组合保存为原始特征索引矩阵,同时将数值型特征值和分类型特征值的组合保存为原始特征值矩阵,在训练模型时,将训练数据集所对应的原始特征索引矩阵和原始特征值矩阵输入点击率预估模型,在获取点击率预估结果时,将测试数据集所对应的原始特征索引矩阵和原始特征值矩阵输入点击率预估模型中;
步骤3)基于深度卷积神经网络u-net构建点击率预估模型,结合图2说明如下:
将深度卷积神经网络u-net收缩路径中的深度卷积模块替换为由p个c×c卷积层组成的深度收缩模块,并在深度收缩模块与该u-net的输入层之间添加宽度线性收缩模块,将扩张路径中的嵌套卷积模块替换为包含p个转置卷积层和p个d×d卷积层的扩张模块,同时将扩张路径中的输出层替换为softmax分类器,得到点击率预估模型,在本实例中,p=2,c=3,d=1;
步骤4)对点击率预估模型进行训练:
(4a)将训练数据集对应的原始特征索引矩阵和原始特征值矩阵输入点击率预估模型中,利用宽度线性收缩模块,对原始特征索引矩阵与原始特征值矩阵进行线性组合,得到线性组合矩阵并保存,提取原始特征中有共性的特征,实现原始特征的交叉组合,组合公式为:
其中,y为线性组合矩阵,w0为随机初始化的常值,n表示输入数据的特征数量,xi、xj分别表示输入数据的第i列、第j列特征,wi和wij为点击率预估模型的权重参数。
(4b)利用深度收缩模块,对线性组合矩阵、原始特征索引矩阵、原始特征值矩阵的组合结果进行p次卷积,得到p组高阶特征矩阵并保存,针对原始特征和其进行交叉组合后的特征都进行了初步的深层特征的提取,增加了特征提取的对象,可以获取更多的特征;
(4c)利用扩张模块所包含的转置卷积层对在深度收缩模块中与其对应的c×c卷积层的卷积结果进行转置卷积,然后与所使用卷积层的上一个c×c卷积层的卷积结果组合,再进行扩张模块的d×d卷积层对组合结果进行卷积,并将卷积结果输入下一个转置卷积层,再次进行组合、卷积,直到扩张模块的p次卷积完成,得到组合高阶特征矩阵,然后对该组合高阶特征矩阵和线性组合矩阵以及p组高阶特征矩阵进行拼接并输出;
(4d)利用softmax分类器对扩张模块的输出结果进行分类,得到点击率预估结果并输出,其中利用softmax分类器得到的点击率预估结果为广告被用户点击的概率值,适用于点击率预估领域;
(4e)利用softmax分类器输出的点击率预估结果和训练数据集的实际点击率结果计算损失函数值,训练至损失函数值在j代内不再减小时停止,得到训练好的点击率预估模型,在本实例中,j=50,使得模型得到充分训练,同时存在损失函数值j代内不再减小的停止的早停机制,避免模型训练过久导致过拟合,其中,损失函数的计算公式为:
其中,loss为损失函数值,n为模型输入数据的个数,yi为输入数据实际点击率结果,
步骤5)利用训练好的点击率预估模型对互联网广告点击率进行预估:
将测试数据集对应的特征索引矩阵和特征值矩阵输入步骤(4)训练好的点击率预估模型,得到互联网广告点击率预估结果。
以下结合仿真实验对本发明的效果做进一步的说明:
1.仿真条件及所采用数据集:
硬件平台为:主频2.2ghz的intel(r)xeon(r)e5-2630cpu、核心频率1607-1733mhz的gtx1080-8g、内存为64gb;
软件平台为:tensorflow;
本发明仿真实验使用criteo数据集和porto数据集;
本发明仿真实验所使用的仿真参数如下:
精度auc:是特征曲线下的面积,其中特征曲线的x轴坐标为预测为1(点击)的错误结果在所有负样本中的占比,y轴坐标为预测为1的正确结果在所有正样本中的占比,它衡量了预测结果中正样本的得分高于负样本的得分的概率。
2、仿真内容与结果分析:
采用本发明和背景技术中“deepfm:afactorization-machinebasedneuralnetworkforctrprediction”的现有技术,在上述仿真条件下,分别对criteo数据集和porto数据集进行点击率预估,将得到的点击率预估结果进行精度对比,仿真对比结果如图3所示,通过对仿真对比结果进行统计分析,在criteo数据集下,本发明的平均点击率预估精度为0.8015,仿真实验中所使用现有技术的平均点击率预估精度为0.7995;在porto数据集下,本发明的平均点击率预估精度为0.6351,仿真实验中所使用现有技术的平均点击率预估精度为0.6346。
由上述的仿真对比结果可以看出,本发明提出的方法相比于对比方法在精度方面有明显地提高。
综上所述,本发明提出的基于u-net网络的互联网广告点击率预估方法能够明显地提高对于互联网广告数据的泛化能力,加强对原始数据深层特征的提取,有效提高了广告点击率预估的精度。
- 还没有人留言评论。精彩留言会获得点赞!