一种英文文章质量评估方法及系统与流程
本发明涉及信息技术领域,特别是涉及一种英文文章质量评估方法及系统
背景技术:
英文文章质量评估有助于英语语言的学习者和使用者提高自己的英文写作水平,更有利于教学工作者在教学过程中给予学生快速反馈提高学习效率。同时高效的英文文章质量评估可以帮助英语语言的使用者在文章发表,会议报告中使用更加地道的英文。
但是目前的英文质量评估系统更加偏向于语法纠错和单词检查,对于文章本身的风格以及英文的地道程度没有涉及。尤其是国内,更没有针对中式英语和中式写作思维的检查。
另外现有的英文文章质量评估方法主要是从文章的语法错误和单词的拼写错误出发,进行惩罚式的评分,或者单纯的只看高级词汇和句型的多少。对于英文的初学者来说这样的方法很有用。但是对于对英语有更高追求和理解的人来说非常不合适,因为地道的英文并非是对高级词汇和句型的堆砌。
为了更好的帮助英语语言的学习者和使用者在英文写作中摆脱中式英语和中式写作思维的影响,写出更加地道的英文文章,提供一种全新的,针对中式英语的英文文章质量评估方法是很有必要的。
应该注意,上面对技术背景的介绍只是为了方便对本申请的技术方案进行清楚、完整的说明,并方便本领域技术人员的理解而阐述的。不能仅仅因为这些方案在本申请的背景技术部分进行了阐述而认为上述技术方案为本领域技术人员所公知。
技术实现要素:
有鉴于现有技术上的缺陷,本发明所要解决的技术问题是提供一种英文文章质量评估方法和系统,其通过对标准的目标英文文章进行学习、并建立语言语法特征模型、文章质量评估模型从而实现对输入的英文文章进行质量评估。
为了实现上述目的,本发明提供了一种英文文章质量评估方法,包括:
s1、输入待评估文档,对文档进行预处理;
s2、提取待评估文档语言语法特征;
s3、根据语言语法特征模型给出语言特征评分;
s4、根据文章质量评估模型给出文章质量评分;
s5、给出每个语言特征的参考值。
进一步的,s1中对文档进行预处理的步骤包括:对文档进行断句处理;对文档进行分词处理;对文档进行词性标记。
s2中,所述提取的语言语法特征包括且不限于:1)句首名词在仅隔一个逗号后的重复率、2)句首名词在仅隔一个句号后的重复率、3)排除句首状语后,实际句首名词的重复率、4)包含一个以上逗号的句子中代词出现的频率、5)文章中代词的使用频率、6)英文基本动词的使用频率、7)文章中动词的使用频率、8)because的使用频率、9)more的使用频率、10)less的使用频率、11)ization或isation结尾的名词出现的频率;12)6个字母以上动词的使用频率、13)7个字母以上动词的使用频率、14)8个字母以上动词的使用频率、15)状语前置句式出现得频率、16)连续状语当先得频率、17)句子中出现一个逗号得频率、18)句子中出现两个逗号得频率、19)that和which在一个句子中间的名词后出现的频率、20)that和which在一个句子中带冠词的名词后出现的频率、21)基本介词的使用频率、22)句平均单词数。
进一步的,所述文章中基本动词包括且不局限于have,do,make,get,is,are,give,take,put,set,bring,come,go。
进一步的,所述文章中基本介词包括且不局限于in,on,at,for,with,by。
所述语言语法特征模型是基于大规模的训练语料,对比分析标准的目标英语文章和其它英语文章中的语言语法特征分布规律,对于这些特征本身构建的正态分布分位数评分模型。
所述文章质量评估模型是对样本预处理后,基于大规模的训练语料,通过检测所述语言语法特征的分布规律,对比分析标准的目标英语文章和其它英语文章中的语言语法特征分布规律,构建的复合式logistic回归模型。
所述语言语法特征模型的训练步骤包括:
s31、对原始样本文章进行断句处理;
s32、对断句得到的每个句子进行分词、词性标记;
s33、提取原始样本文章的语言语法特征,选取标准的目标英语文章作为研究对象,筛选这些文章;原始样本文章应包括需要研究的标准的目标英语文章和其它英语文章;选取提取标准的目标英语文章和其它英语文章中具有明显区别的语言语法特征,并将此语言语法特征纳入评价指标;
s34、计算评价指标的各语言语法特征的均值和方差;建立各语言语法特征所对应的正态分布;将各语言语法特征的正态分布的分位数作为语言特征评分,即语言特征的参考值。
进一步的,所述标准的目标英语文章为美式英语文章。
进一步的,所述提取的语言语法特征包括且不局限于:1)句首名词在仅隔一个逗号后的重复率;2)句首名词在仅隔一个句号后的重复率、3)排除句首状语后,实际句首名词的重复率、4)包含一个以上逗号的句子中代词出现的频率、5)文章中代词的使用频率、6)英文基本动词的使用频率、7)文章中动词的使用频率、8)because的使用频率、9)more的使用频率、10)less的使用频率、11)ization或isation结尾的名词出现的频率、12)6个字母以上动词的使用频率、13)7个字母以上动词的使用频率、14)8个字母以上动词的使用频率、15)状语前置句式出现得频率、16)连续状语当先得频率、17)句子中出现一个逗号得频率、18)句子中出现两个逗号得频率、19)that和which在一个句子中间的名词后出现的频率、20)that和which在一个句子中带冠词的名词后出现的频率、21)基本介词的使用频率、22)句平均单词数。
所述文章质量评估模型的训练步骤包括:
s41、对于原始样本文章进行断句处理;
s42、对于断句得到的每个句子进行词性标记;
s43、提取原始样本文章的语言语法特征,选取标准的目标英语文章作为研究对象,筛选这些文章;原始样本文章包括需要研究的标准的目标英语文章和其它英语文章;选取提取标准的目标英语文章和其它英语文章中具有明显区别的语言语法特征,并将此语言语法特征纳入评价指标;给定标准的目标英语文章标签为1,其余文章标签为0;
s43、将纳入评价指标的语言语法特征作为影响因子,以给定的标签0或1作为因变量训练logistic回归模型;
s44、重复上述步骤,训练多个logistic回归模型;
s45、采用随机梯度上升法通过多次迭代求得各logistic回归模型参数,根据各logistic回归模型参数到其均值的2范数距离将模型分类;对于不同类别的模型赋予不同的权重;
s47、将各模型的sigmoid函数值作为各模型对文章质量的评分,其评分的加权平均作为复合模型的输出结果,即为文章质量评分。
进一步的,所述目标语言包括美式英语。
进一步的,所述logistic回归模型的个数为100个。
进一步的,所述训练的logistic回归模型的准确率均高于90%。
进一步的,所述模型的分类为4个等级,所述权重为每个等级的总权重从40%到10%递减,每次减少10%。
进一步的,所述提取的语言语法特征包括且不局限于1)句首名词在仅隔一个逗号后的重复率、2)句首名词在仅隔一个句号后的重复率、3)排除句首状语后,实际句首名词的重复率、4)包含一个以上逗号的句子中代词出现的频率、5)文章中代词的使用频率、6)英文基本动词的使用频率、7)文章中动词的使用频率、8)because的使用频率、9)more的使用频率、10)less的使用频率、11)ization或isation结尾的名词出现的频率、12)6个字母以上动词的使用频率、13)7个字母以上动词的使用频率、14)8个字母以上动词的使用频率、15)状语前置句式出现得频率、16)连续状语当先得频率、17)句子中出现一个逗号得频率、18)句子中出现两个逗号得频率、19)that和which在一个句子中间的名词后出现的频率、20)that和which在一个句子中带冠词的名词后出现的频率、21)基本介词的使用频率、22)句平均单词数。
本发明还公开了一种英文文章质量评估系统,包括:
文档预处理模块,用于对输入的英文文章进行预处理,包括断句、分词、词性标注;
特征提取模块,用于对输入的英文文章进行语言语法特征提取;
特征分析模块,用于根据已建立的语言语法特征模型,给出文章各语言语法特征的评分。
文章评分模块,用于根据已建立的文章质量评估模型,给出文章值质量评分。
输出模块,用于输出文章各语言语法特征的评分及参考值、文章质量评分。
本发明的有益效果是:本发明可以充分提取文章的语言语法特征,合理运用这些特征规律,构建正态分布分位数评分模型和复合式logistic回归模型,对于文章质量的评价非常的客观全面。有助于英语语言的学习者和使用者提高自己的英文写作水平,更有利于教学工作者在教学过程中给予学生快速反馈提高学习效率。同时高效的英文文章质量评估还能帮助英语语言的使用者在文章发表,会议报告中使用更加地道的英文。
鉴于对于语法和拼写的检查目前已有技术已经非常完善,本发明从语法和用词习惯的角度出发,对比了上万篇地道的美式英语和其它英语文章后发现,美式英语和其它英语在句首名词重复率等诸多指标上表现出了明显差异。于是,本发明从这些差异出发,建立了文章质量评估模型和语言语法特征模型,可有效地检测英文文章在这些指标上的表现水平和标准的目标英文文章之间的差异。并使用logistic回归模型给出文章评分,全面而客观的给出对文章质量的总体评价。尤其是,本发明更注重突破语法纠错和拼写检查的阶段,在更高的语言语法习惯的层次上评价文章的优劣,可以帮助使用者写出更地道的英文文章。
参照后文的说明和附图,详细公开了本申请的特定实施方式,指明了本申请的原理可以被采用的方式。应该理解,本申请的实施方式在范围上并不因而受到限制。在所附权利要求的精神和条款的范围内,本申请的实施方式包括许多改变、修改和等同。
针对一种实施方式描述和/或示出的特征可以以相同或类似的方式在一个或更多个其它实施方式中使用,与其它实施方式中的特征相组合,或替代其它实施方式中的特征。
应该强调,术语“包括/包含”在本文使用时指特征、整件、步骤或组件的存在,但并不排除一个或更多个其它特征、整件、步骤或组件的存在或附加。
附图说明
所包括的附图用来提供对本申请实施例的进一步的理解,其构成了说明书的一部分,用于例示本申请的实施方式,并与文字描述一起来阐释本申请的原理。显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来将,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。在附图中:
图1是本发明一种英文文章质量评估方法的流程图。
图2是本发明一种英文文章质量评估系统的示意图。
具体实施方式
为了使本技术领域的人员更好地理解本申请中的技术方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动成果前提下所获得的所有其它实施例,都应当属于本申请保护的范围。
实施例一:
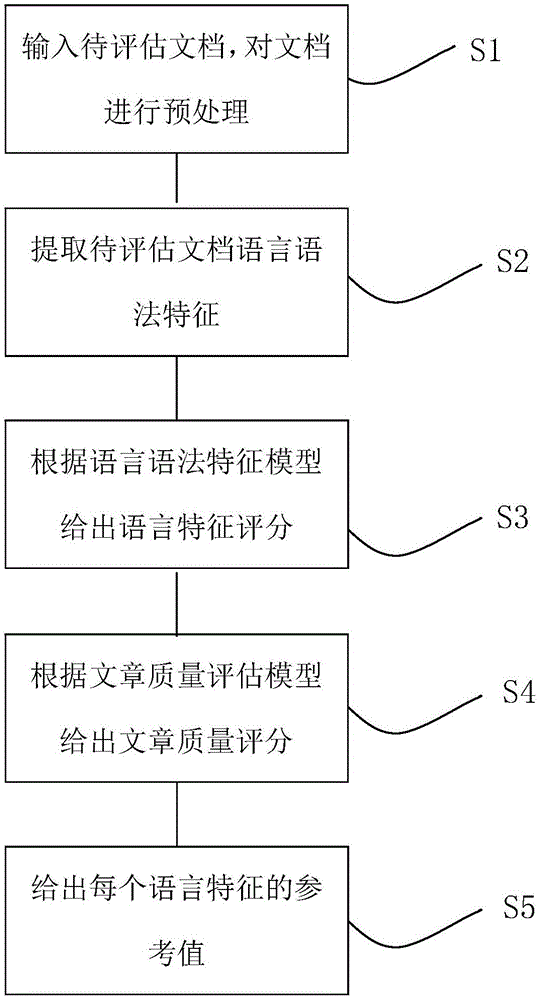
图1是本发明一种英文文章质量评估方法的流程图,参考图1可知:本实施例的英文文章质量评估方法,包括:
s1:输入待评估文档,对待评估文档进行预处理;
s2:提取待评估文档语言语法特征;
s3:根据语言语法特征模型给出语言特征评分;
s4:根据文章质量评估模型给出文章质量评分;
s5:给出每个语言特征的参考值。
本实施例中,文档预处理的步骤包括对待评估文档进行断句处理;对每个句子进行词性标记。
本实施例优选的,提取待评估文档的语言语法特征包括且不局限于:1)句首名词在仅隔一个逗号后的重复率、2)句首名词在仅隔一个句号后的重复率、3)排除句首状语后,实际句首名词的重复率、4)包含一个以上逗号的句子中代词出现的频率、5)文章中代词的使用频率、6)英文基本动词的使用频率、7)文章中动词的使用频率、8)because的使用频率、9)more的使用频率、10)less的使用频率、11)ization或isation结尾的名词出现的频率、12)6个字母以上动词的使用频率、13)7个字母以上动词的使用频率、14)8个字母以上动词的使用频率、15)状语前置句式出现得频率、16)连续状语当先得频率、17)句子中出现一个逗号得频率、18)句子中出现两个逗号得频率、19)that和which在一个句子中间的名词后出现的频率、20)that和which在一个句子中带冠词的名词后出现的频率、21)基本介词的使用频率、22)句平均单词数。
本实施例优选的,s3中,语言语法特征模型为提取的各类语言语法特征所对应的模型。
本实施例优选的,s4中,文章质量评估模型应为根据训练数据所提取得各类语言语法特征上的检测水平所建立的复合logistic回归模型。
本实施例优选的,语言语法特征模型的训练步骤包括:
s31、对原始样本文章进行断句处理;原始样本文章包括标准的美式英语文章和其它英语文章;
s32、对断句得到的每个句子进行分词、词性标记;
s33、选取标准的原始样本文章作为研究对象,筛选这些文章;具体为:筛选出样本文章中标准的美式英语文章和其它英语文章,根据它们每个语言语法特征的检测水平绘制折线图,确认两者在语言语法特征的检测水平上有明显的区分(折线图出现明显不同),即此语言语法特征可以作为区分标准的美式英语文章和其它英语文章的指标,然后将此语言语法特征纳入评价指标中;
s34、提取美式英语文章在s33中纳入评价指标的语言语法特征;
s35、计算s34提取出的各语言语法特征的均值和方差;建立各语言语法特征所对应的正态分布;将各语言语法特征的正态分布的分位数作为其评分;
建立正态分布分位数评分模型如下:
其中
μ为样本均值,σ2为样本方差,y为该语言语法特征项的评分,x为该项语言语法特征的检测水平。
本实施例优选的,s33中,标准的原始样本文章为美式英语文章。
本实施例优选的,s34中,提取的语言语法特征包括且不局限于:1)句首名词在仅隔一个逗号后的重复率、2)句首名词在仅隔一个句号后的重复率、3)排除句首状语后,实际句首名词的重复率、4)包含一个以上逗号的句子中代词出现的频率、5)文章中代词的使用频率、6)英文基本动词的使用频率、7)文章中动词的使用频率、8)because的使用频率、9)more的使用频率、10)less的使用频率、11)ization或isation结尾的名词出现的频率、12)6个字母以上动词的使用频率、13)7个字母以上动词的使用频率、14)8个字母以上动词的使用频率、15)状语前置句式出现得频率、16)连续状语当先得频率、17)句子中出现一个逗号得频率、18)句子中出现两个逗号得频率、19)that和which在一个句子中间的名词后出现的频率、20)that和which在一个句子中带冠词的名词后出现的频率、21)基本介词的使用频率、22)句平均单词数。
本实施例优选的,文章质量评估模型的训练步骤包括:
s41、对于原始样本文章进行断句处理;
s42、对于断句得到的每个句子进行分词、词性标记;
s43、选取原始样本文章作为研究对象,筛选这些文章,具体为:提取原始样本文章的语言语法特征;筛选出原始样本文章中标准的目标英语文章(美式英语文章)和其它英语文章,通过以上语言语法特征的检测水平绘制折线图,确认两者在检测水平上有明显的区分,即该项语言语法特征可以作为区分标准的美式英语文章和其它英语文章的指标,将该项语言语法特征纳入评价指标中;给定标准的美式英语文章标签为1,其余文章标签为0;
s44、将s43中纳入的评价指标中的项语言语法特征作为自变量,以给定的标签0或1作为因变量训练logistic回归模型;将该标签作为因变量构建logistic回归模型如下:
其中βi为待估计参数,xi为第i个语言语法特征的检测水平;
s45、重复上述步骤,训练多个logistic回归模型;
s46、采用随机梯度上升法通过多次迭代求得各logistic回归模型参数,根据各logistic回归模型参数到其均值的2范数距离将模型分类;对于不同类别的模型赋予不同的权重;
s47、将各模型sigmoid函数的加权平均作为文章质量评估复合logistic回归模型对于文章质量的评分,其评分的加权平均作为复合模型的输出结果,即:
y=w0σ0(x)+w1σ1(x)+···+wmσm(x)
其中,
y为文章质量模型给出的质量评分,σi(x)为模型i对应的sigmoid函数,xj为第j个语言语法特征的检测水平。
本实施例优选的,所训练的logistic回归模型的个数为100个。
本实施例优选的,所训练的logistic回归模型的准确率均高于90%。
本实施例优选的,将上述100个模型分为4个等级。
本实施例优选的,每个等级的总权重从40%到10%递减。
本实施例优选的,s43中,提取的语言语法特征包括且不局限于:1)句首名词在仅隔一个逗号后的重复率、2)句首名词在仅隔一个句号后的重复率、3)排除句首状语后,实际句首名词的重复率、4)包含一个以上逗号的句子中代词出现的频率、5)文章中代词的使用频率、6)英文基本动词的使用频率、7)文章中动词的使用频率、8)because的使用频率、9)more的使用频率、10)less的使用频率、11)ization或isation结尾的名词出现的频率、12)6个字母以上动词的使用频率、13)7个字母以上动词的使用频率、14)8个字母以上动词的使用频率、15)状语前置句式出现得频率、16)连续状语当先得频率、17)句子中出现一个逗号得频率、18)句子中出现两个逗号得频率、19)that和which在一个句子中间的名词后出现的频率、20)that和which在一个句子中带冠词的名词后出现的频率、21)基本介词的使用频率、22)句平均单词数。
实施例二:
本实施例选择标准的美式英语文章作为检测标准。
s1、对待评估的文档进行预处理,文档预处理过程文章断句,文本分词和词性标记;
s2、提取如下语言语法特征:1)句首名词在仅隔一个逗号后的重复率、2)句首名词在仅隔一个句号后的重复率、3)排除句首状语后,实际句首名词的重复率、4)包含一个以上逗号的句子中代词出现的频率、5)文章中代词的使用频率、6)英文基本动词的使用频率、7)文章中动词的使用频率、8)because的使用频率、9)more的使用频率、10)less的使用频率、11)ization或isation结尾的名词出现的频率、12)6个字母以上动词的使用频率、13)7个字母以上动词的使用频率、14)8个字母以上动词的使用频率、15)状语前置句式出现得频率、16)连续状语当先得频率、17)句子中出现一个逗号得频率、18)句子中出现两个逗号得频率、19)that和which在一个句子中间的名词后出现的频率、20)that和which在一个句子中带冠词的名词后出现的频率、21)基本介词的使用频率、22)句平均单词数;
s3、根据语言语法特征分位数评分模型给出文档语言语法特征评分;
s4、根据文章质量评估模型给出文章质量评分;
s5、给出每个语言语法特征的参考值。
进一步地,s3中语言语法特征模型的训练步骤如下:
s31、对原始样本文章进行预处理,本例所用样本文章包括标准的美式英语文章24000篇,非美式英语文章15000篇。文章预处理过程包括文章断句,文本分词和词性标记。
s32、提取语言语法特征,提取的语言语法特征包括且不限于:1)句首名词在仅隔一个逗号后的重复率、2)句首名词在仅隔一个句号后的重复率、3)排除句首状语后,实际句首名词的重复率、4)包含一个以上逗号的句子中代词出现的频率、5)文章中代词的使用频率、6)英文基本动词的使用频率、7)文章中动词的使用频率、8)because的使用频率、9)more的使用频率、10)less的使用频率、11)ization或isation结尾的名词出现的频率、12)6个字母以上动词的使用频率、13)7个字母以上动词的使用频率、14)8个字母以上动词的使用频率、15)状语前置句式出现得频率、16)连续状语当先得频率、17)句子中出现一个逗号得频率、18)句子中出现两个逗号得频率、19)that和which在一个句子中间的名词后出现的频率、20)that和which在一个句子中带冠词的名词后出现的频率、21)基本介词的使用频率、22)句平均单词数。
s33、筛选出样本文章中标准的美式英语文章和其它英语文章,根据s32提取的语言语法特征的检测水平绘制折线图,折线图包括同一语言语法特征在美式英语文章和其它英语文章中的语言语法特征的检测水平;并选取标准的美式英语文章和其它英语文章有明显区别的语言语法特征(通过折线图对比可以获得区别),将此语言语法特征纳入评价指标中;
s34、针对评价指标中的每一项语言语法特征,选取s3中筛选的标准的美式英语文章作为研究对象,计算这些样本在该语言语法特征上的检测水平的均值和方差,将各语言语法特征的正态分布的分位数作为其评分;
建立的正态分布分位数评分模型如下:
其中
μ为样本均值,σ2为样本方差,y为该语言语法特征项的评分,x为该项语言语法特征的检测水平。
s4中,文章质量评估模型的训练步骤:
s41、对原始样本文章进行预处理,本例所用样本文章包括标准的美式英语文章24000篇,非美式英语文章15000篇。文章预处理过程包括文章断句,文本分词和词性标记。
s42、提取原始样本文章的语言语法特征,提取的语言语法特征包括且不限于:1)句首名词在仅隔一个逗号后的重复率、2)句首名词在仅隔一个句号后的重复率、3)排除句首状语后,实际句首名词的重复率、4)包含一个以上逗号的句子中代词出现的频率、5)文章中代词的使用频率、6)英文基本动词的使用频率、7)文章中动词的使用频率、8)because的使用频率、9)more的使用频率、10)less的使用频率、11)ization或isation结尾的名词出现的频率、12)6个字母以上动词的使用频率、13)7个字母以上动词的使用频率、14)8个字母以上动词的使用频率、15)状语前置句式出现得频率、16)连续状语当先得频率、17)句子中出现一个逗号得频率、18)句子中出现两个逗号得频率、19)that和which在一个句子中间的名词后出现的频率、20)that和which在一个句子中带冠词的名词后出现的频率、21)基本介词的使用频率、22)句平均单词数。
s43、筛选出样本文章中标准的美式英语文章和其它英语文章,根据s42中提取的语言语法特征的检测水平分别绘制折线图,折线图分别为根据美式英语文章和其它英语文章的语言语法特征的检测水平绘制。根据两者的折线图区别选取标准的美式英语文章和其它英语文章有明显区别的语言语法特征,并将此语言语法特征纳入评价指标中。
s44、将评价指标中的每个语言语法特征作为自变量,给s43中筛选出的英文文章加上标签1、其它语言文章加上标签0,将该标签作为因变量构建logistic回归模型如下:
其中βi为待估计参数,xi为第i个语言语法特征的检测水平。
s45、采用随机梯度上升法通过600次迭代求得各个logistic回归模型参数。
s46、重复s45,计算得到100个logistis回归模型(由于模型自变量存在共线性,故符合样本数据的logistic回归模型不唯一)。
s47、根据s46所得到的100个logistic回归模型距其各参数均值的2范数距离将它们分为4个类别,根据类别等级的不同(即离参数均值的2范数距离大小)赋予各模型不同权重,每个等级的总权重从40%到10%递减。
s48、将各模型sigmoid函数的加权平均作为文章质量评估复合logistic回归模型对于文章质量的评分,即:
y=w0σ0(x)+w1σ1(x)+···+wmσm(x)
其中,
y为文章质量模型给出的质量评分,σi(x)为模型i对应的sigmoid函数,xj为第j个语言语法特征的检测水平。
实施例三:
图2是本发明英文文章质量评估系统示意图,该英文文章质量评估系统100,包括:
文档预处理模块10,用于对输入的英文文章进行预处理,包括断句、分词、词性标注;
特征提取模块20,用于对输入的英文文章进行语言语法特征提取;
特征分析模块30,用于根据已建立的语言语法特征模型,给出文章各语言语法特征的评分。
文章评分模块40,用于根据已建立的文章质量评估模型,给出文章值质量评分。
输出模块50,用于输出文章各语言语法特征的评分及参考值,文章质量评分。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!