一种基于字典的光学字符识别纠错方法与流程
本发明涉及图像文字识别领域,具体涉及一种基于字典的光学字符识别纠错方法。
背景技术:
基于ocr的针对金融领域文字区域检测定位识别技术是指通过计算机等设备,利用ocr技术(光学字符识别)将纸质材料中的有效信息自动提取和识别出来,并进行相应处理。它是实现银行无纸化的计算机自动处理的关键技术之一。而传统的图像文字识别为光学文字识别(ocr),光学文字识别在将待识别纸质文件扫描成电子图像的基础上进行识别。但是考虑到扫描效果的好坏、纸质文件本身的品质(别如印刷质量、字体清晰度,字体规范度等)、内容布局(文字的排列情况,比普通文本与表格文本和票据)的差异,ocr的实际效果不总是让人满意。而针对不同的纸质文档的识别准确率的要求有差异,比如票据的识别,对准确率的要求是非常高的,因为如果一个数字识别错误就可能导致致命的后果,传统的ocr识别不能满足这样高精度的识别要求。面对巨大的识别需要急需能够快速高效的图像文字识别方法。现有的技术方案都没有利用自身规律对错误数据实施检查和纠正。
技术实现要素:
针对现有技术的不足,本发明根据所要识别ocr字符集的已知完整集合,针对ocr软件从图像中提取出的字符串提出一种检错与纠错的方法,从而辅助ocr软件检查出识别结果中的错误数据并对这些错误数据实施纠正,基于字典搜索的纠错策略,以提高文字识别精度,从而提高识别结果的准确率。ocr软件从图像中提取出的这些字符串的纠错修改结果记为ocr最终识别结果。
本发明的目的是通过下述技术方案来实现的:
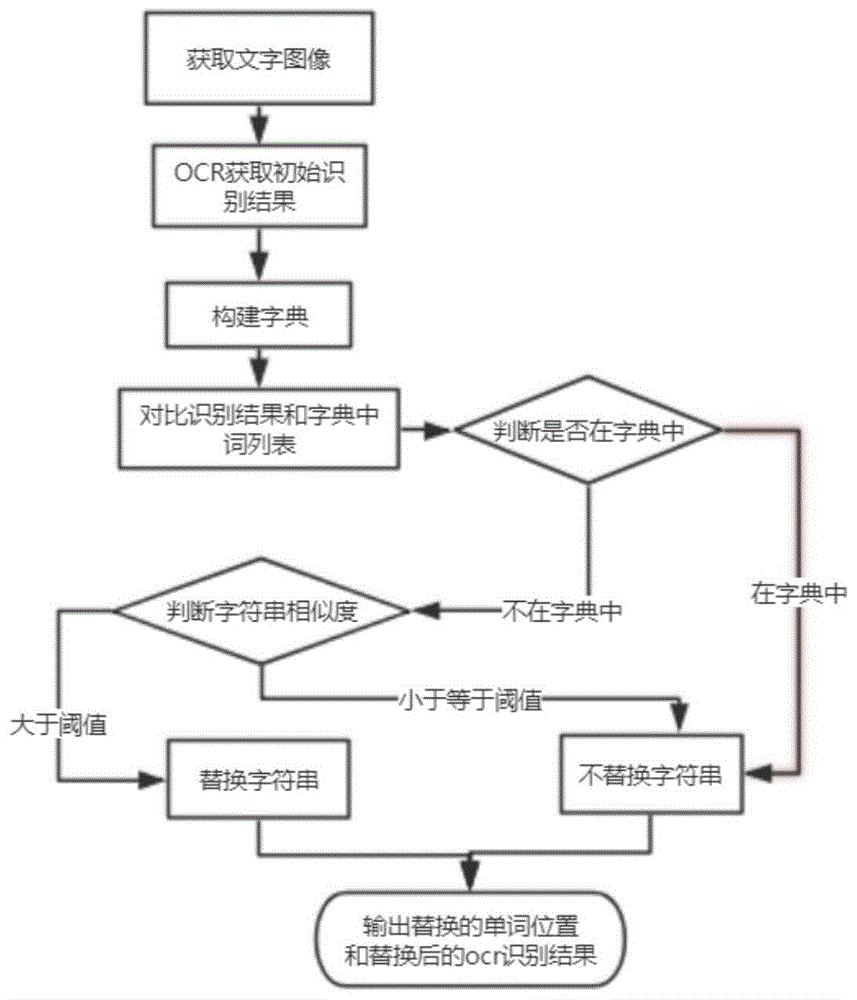
一种基于字典的光学字符识别纠错方法,其特征在于,该方法包括如下步骤:
s1:获取文字图像;
s2:所述文字图像经过ocr识别获得初始的识别结果;
s3:构建字典;
s4:将初始的识别结果与字典中的单词进行对比,然后利用单词在字典中的相对排名计算相似度,具体为:
对于给定文本行默认为正序和反序的排列方式,将文本行划分为单独的单词,得到初始的识别结果的每个单词和其反序版本,然后将两个版本中的单词均与字典中的所有单词进行匹配,对于正序版本和反序版本中的每个单词,当该单词存在于字典中时,不进行替换;当该单词不在字典中时,计算并记录该单词与字典中的单词的相似度,形成相似度矩阵,并设置相似度阈值对其进行过滤,然后将该单词的正序和反序版本按照相似度最大的那个字典中的单词进行n元语法纠错,并用纠错结果替代初始识别结果,反之,则保留初始的识别结果;
s5:对s4中已经被替换的单词的位置进行标记,输出ocr识别结果。
进一步地,所述的字典来源于搜索引擎bing的常见词列表。
进一步地,所述的s4具体为:
所述的给定的文本行首先被划分为单独的单词ωi,对于每一个ωi,原始识别结果ξ(ωi),将ξ(ωi)和其反向版本ξ←(ωi)均与字典中的所有单词进行匹配,搜索与ξ(ωi)和ξ(ωi)相似度最高的两个单词η(ωi)和η←(ωi),相似度分别记为s(ωi)和s←(ωi);
对于单词不在字典中的情况,设置阈值τ;如果相似度s(ωi)和s←(ωi)均小于τ,则η(ωi)和η←(ωi)被对ξ(ωi)和ξ←(ωi)进行n元语法纠错之后的字符串取代,而s(ωi)和s←(ωi)被设为常数;
对于一个由n个单词组成的文本行l,l={ωi|i=1,2,...,n},正序的总相似度s(l)和反序的总相似度s←(l)分别定义为:
文本行l的排列顺序通过以下方式确定:
其中,
则最终的识别结果为:
进一步地,所述的s4中的字符相似度的定义具体为:
其中,ω为待查询词,
进一步地,所述的s4中单词不在字典中的情况下设置的阈值τ=0.8。
相对于现有技术,本发明的有益效果如下:
(1)本发明的纠错方法不仅与字典中的词进行对比,还利用单词在字典中的相对排名来计算相似度:
(2)该方法定义适应的字符替换代价;
(3)该方法可以处理不同方向排列的文字,而以往的算法假设文字从左到右排列。
附图说明
图1为本发明的基于字典的光学字符识别纠错方法的流程图。
具体实施方式
下面根据附图和优选实施例详细描述本发明,本发明的目的和效果将变得更加明白,以下结合附图和实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
如图1所示,一种基于字典的光学字符识别纠错方法,其特征在于,该方法包括如下步骤:
s1:获取文字图像;
s2:所述文字图像经过ocr识别获得初始的识别结果;
s3:构建字典;
这里的字典来源于搜索引擎bing的常见词列表,该列表包含搜索引擎的用户经常使用的1000000个关键词,由微软网络n语法服务项目提供。不同于传统的字典,该列表中的单词是按照用户搜索的频度从高到低排列的,这种排列顺序也包含额外的有用信息,可以用来提升纠错算法的性能。
s4:将初始的识别结果与字典中的单词进行对比,然后利用单词在字典中的相对排名计算相似度,具体为:
对于给定文本行默认为正序和反序的排列方式,将文本行划分为单独的单词,得到初始的识别结果的每个单词和其反序版本,然后将两个版本中的单词均与字典中的所有单词进行匹配,对于正序版本和反序版本中的每个单词,当该单词存在于字典中时,不进行替换;当该单词不在字典中时,计算并记录该单词与字典中的单词的相似度,形成相似度矩阵,并设置相似度阈值对其进行过滤,然后将该单词的正序和反序版本按照相似度最大的那个字典中的单词进行n元语法纠错,并用纠错结果替代初始识别结果,反之,则保留初始的识别结果;
字典中单词的排名可以提供有用的信息。直观而言,在字典中的两个单词与输入的查询词具有相同的相似度的情况下,应该优先选择排名较高的单词。在定义查询词与字典中单词的相似度时,不仅考虑编辑距离,也考虑单词的相对排名。
因此,这里相似度定义为:
其中,ω为待查询词,
字符串相似度是通过一定方法来计算不同字符串之间的相似度程度,通常会用百分比来衡量。字符串字形的相似度,直接通过字符串中每个汉字转化为音形码,然后再将所以音形码合并进行编辑距离算法比较。音形码采用使用70%的四角编码的汉字检定法算法加上30%的笔画数形成一个字符串,作为这个字符串的hash值。
给定的文本行首先被划分为单独的单词ωi,对于每一个ωi,原始识别结果ξ(ωi),将ξ(ωi)和其反向版本ξ←(ωi)均与字典中的所有单词进行匹配,搜索与ξ(ωi)和ξ←(ωi)相似度最高的两个单词η(ωi)和η←(ωi),相似度分别记为s(ωi)和s←(ωi);
对单词不在字典中的情况,设置阈值τ;如果相似度s(ωi)和s←(ωi)均小于τ,则η(ωi)和η←(ωi)被对ξ(ωi)和ξ←(ωi)进行n元语法纠错之后的字符串取代,而s(ωi)和s←(ωi)被设为常数;这里τ=0.8,该参数根据经验得到,在所有的实验中取得良好的效果。
对于一个由n个单词组成的文本行l,l={ωi|i=1,2,…,n},正序的总相似度s(l)和反序的总相似度s←(l)分别定义为:
文本行l的排列顺序通过以下方式可以确定:
其中
则最终的识别结果为:
s5:对s4中已经被替换的单词的位置进行标记,输出ocr识别结果。
本领域普通技术人员可以理解,以上所述仅为发明的优选实例而已,并不用于限制发明,尽管参照前述实例对发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实例记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在发明的精神和原则之内,所做的修改、等同替换等均应包含在发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!