一种面向在线问答平台的基于深度强化学习的问题标注方法与流程
本发明属于自然语言处理领域,更具体地,涉及一种面向在线问答平台的基于深度强化学习的问题标注方法。
背景技术:
随着web2.0的发展,quora1和知乎等社交问答(sqa)网站的发展越来越重要。一方面,类似于基于社区的问答(cqa)网站,它们包括提问的机制,发布答案问题的平台,以及围绕这些信息建立的社区。另一方面,sqa网站突出社交信息,尤其是主题标签之间的联系。例如,在知乎中,用户必须为他们的问题分配至少一个主题标签,并且他们能够遵循他们感兴趣的主题标签,这反过来有益于基于主题的问题路由和浏览。鉴于此,自动为新发布的问题提供正确的主题标签是加强用户体验和内容分发效率的关键。
现有的解决问题标签的任务在技术上主要可以分为两类:基于规则模型和数据驱动模型。前者通常将此问题标记任务视为给定问题与每个候选主题之间的匹配问题。为了估计相似性,手动设计了大量模板和规则,这将耗费大量的人工劳力。至于数据驱动的问题,他们将此任务表述为分类问题,例如char-convolutionalneuralnetwork(ccnn)和深层次cnn。他们尝试从训练数据中学习规则,以适应新问题,使其更容易实施,并通常实现最佳性能。尽管它们具有重要意义,但它们在实践中并不适用,因为有许多新创建的主题标签,其中的问题样本很少。这是因为有经验的用户可以随时在sqa站点中创建新的主题标签。另外,现有模型依次依赖于密集标记数据,即每个主题标签成千上万个问题,并且它们无法很好地处理实际环境中的任务。
在这样的短文中,有助于弥合问题和标签之间语义鸿沟的有用信息非常稀少。其次,我们观察到问题标签遵循长尾分布,其中大部分标签很少发生。超过98%的标签在两个数据集上出现的次数不超过500次(即0.05%的问题)。我们将这些标签称为“尾标签”和其他常用标签“头标签”。虽然偶然发生,尾部标签是对问题的特定和细粒度描述,其反映更准确的语义,因此对于专家发现,搜索和知识挖掘等更有用。现有的方法对标签多样性的考虑不足,标签所属话题领域的多样化往往能使得问题描述变得更加具体和丰富,因为在推荐给不同专家时能使得问题得到更多元化,更多层次的解决。
技术实现要素:
为解决现有的技术缺陷,本发明公开了一种新的面向在线问答平台的基于深度强化学习的问题标注方法。本发明能有效解决由于标签过多,问题样本很少导致的过拟合问题,并在考虑为问题标注保证准确性的同时,对其标注多样性进行改善。
为解决上述技术问题,本发明的技术方案如下:
一种面向在线问答平台的基于深度强化学习的问题标注方法,包括以下步骤:
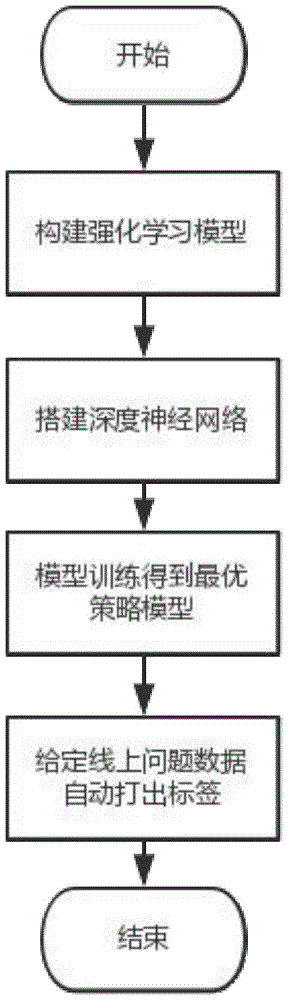
s1:利用mdp马尔科夫决策过程对问题构建q-learning强化学习模型;
s2:搭建深度神经网络优化训练q值;所述的q值表示q-learning强化学习模型中在状态s动作后获取的得分奖励;
s3:利用训练集训练深度强化学习模型;
s4:根据深度强化学习模型输出结果对问题进行标签标注。
在一种优选的方案中,所述的s1中的mdp马尔科夫决策过程定义为μ=<s,a,r,p,γ>,其中,
所述的s表示问题以及其当前所标注的标签的集合,通过下式进行表达:s={q,i0,i1...it}
式中,所述的t表示当前的状态值,所述的t-1表示上一个状态;所述的q表示需要打标签的问题,所述的i表示问题对应的标签;
所述的a表示空间,指动作at针对智能体的策略π所做出的一个推荐的标签,π是st到at的一个映射,且每次动作推荐一个标签;
所述的p表示了概率转移矩阵,指智能体采取了at动作以后,从st转移到st+1的概率,所述的智能体表示强化学习的算法主体,与其交互的对象称为环境。智能体通过观察环境,得到环境的状态信息。根据状态信息判断自己该采取的策略并做出相应的动作,环境在接受智能体的动作之后给予奖励,反映动作的好坏,同时智能体的动作对状态产生影响,使接下来观察到的状态信息发生变化,再次决策,得到一系列状态-动作的序列。智能体的目标就是使得在一定时间内的回报累加和最大化,得到一组最优化行为策略。
所述的r表示奖励函数,指智能体在st采取了一个动作at以后,对标签多样性的评价函数;
所述的γ表示未来动作所得到的奖励对当前状态值的影响程度。
在一种优选的方案中,所述的r通过下式进行表达:
式中,所述的f(it)对应的是ndcg值,通过下式进行表达:
所述的rel是该标签的相关性值,所述的i表示标签所在的当前位置大的序号,所述的k为智能体的参考的标签数量,所述的m表示标签所在的当前位置序号;
所述的τ(it)对应的是α-ndcg值,是ndcg值的变形,表示标签如果含有新发现的子话题,则α-ndcg值增加;如果含有无关的子话题则α-ndcg值降低,所述的τ(it)通过下式进行表达:
所述的ng(i)表示智能体提供的第i个标签所能获得的多样性评估得分,所述的α为影响系数,所述的ng*(i)标签i在理想情况下的最优得分值。
在一种优选的方案中,所述的q值通表示在状态s采取动作后能获取的期望得分奖励,q(st,at)=q(st,at)+μ[r+γmaxa'q(st+1,aa+1)-q(st,at)],所述的μ是q-learning过程中的学习率,所述的maxa'q(st+1,aa+1)是智能体模拟的下个动作能得到的最大得分值。
在一种优选的方案中,所述的s2包括以下流程:
s2.1:构造深度卷积网络,用于对q值进行初步计算;通过输入固定格式的问题和标签数据,经卷积层以及全连接层,最后输出每一个标签的预计收益a;
s2.2:构造回放经验池,通过记录训练过程中所有的样本<st,at,rt,st+1>,每一个样本定义为一个经验,存入经验池中,网络学习从经验池中均匀抽出样本进行学习;
s2.3:定义一个实时更新的深度神经网络,记为q(s,a;θ),所述的θ为神经网络的网络参数值;另外定义一个与q(s,a;θ)相同结构的深度神经网络,但是参数相隔时间c从实时更新的深度神经网络中同步一次,记为
θt+1=θt+μ[r+γmaxa'q(s',a';θ-)-q(s,a;θ)]▽q(s,a;θ)。
在一种优选的方案中,所述的s3包括以下流程:
s3.1:初始化一个容量为n的回放经验池d,随机初始化动作价值函数q,记录其参数为θ;初始化目标动作价值函数
s3.2:智能体的动作执行以下内容:
概率ξ:随机选择一个动作at;
概率1-ξ:执行动作at=argmaaxq(φ(st),a;θ),所述的ξ是人为预设值;
s3.3:观察智能体执行动作at后的回报rt以及下一个数据xt+1;
s3.4:更新st+1=st,at,xt+1,φt+1=φ(st+1),将样本(φt,at,rt,φt+1)存到经验回放池d中;
s3.5:从d中随机采样一个批次的样本(φk,ak,rk,φk+1);
s3.6:最佳得分值yk通过下式进行表达:
s3.7:对参数θ进行(yk-q(θk,ak;θ-))2梯度反转;
s3.8:每c步将目标动作价值函数
s3.9:若没有完成最大迭代数目,则执行s3.3;否则执行s3.10;
s3.10:若没有结束所有采样序列episode,执行s3.2;否则执行s4。
在一种优选的方案中,所述的s4包括以下流程:
s4.1:输入训练完成的标注策略π,问题q,候选标签t;
s4.2:初始化候选标签集合;
s4.3:通过标注策略π选择一个标签;
s4.4:更新标签列表,到达下一个状态st+1;
s4.5:若标签列表中标签数量未达到要求预设值,执行s4.2。
s4.6:输出标签列表,作为该问题的标签。
与现有技术相比,本发明技术方案的有益效果是:
(1)在为问题进行标签标注的时候,本发明不仅考虑标签标注的准确性,而且还创新性地应用最新理论对标签内容的多样性进行考虑,丰富了问题性质的维度,使得社交问答平台中的问题能更好被利用。
(2)本发明的方法运用deepmind提出的深度强化学习技术对模型进行建模,速度比传统的q-learning强化学习算法要快很多,并且能在一定置信度下保证相似性的误差范围。
(3)本发明减少了尾标签由于其自身数据属性特征导致的难以被问题匹配的情况,使得问题的复杂描述得以被模型重视。
附图说明
图1为本实施例的流程图。
图2为本实施例中s2中深度强化学习网络参数更新说明图。
图3为本实施例中s3中深度强化学习网络中经验池学习说明图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
如图1所示,一种面向在线问答平台的基于深度强化学习的问题标注方法,包括以下步骤:
s1:利用mdp马尔科夫决策过程对问题构建q-learning强化学习模型;
s1中的mdp马尔科夫决策过程定义为μ=<s,a,r,p,γ>,其中,
s表示问题以及其当前所标注的标签的集合,通过下式进行表达:s={q,i0,i1...it}
式中,t表示当前的状态值,t-1表示上一个状态;q表示需要打标签的问题,i表示问题对应的标签;
a表示空间,指动作at针对智能体的策略π所做出的一个推荐的标签,π是st到at的一个映射,且每次动作推荐一个标签;
p表示了概率转移矩阵,指智能体采取了at动作以后,从st转移到st+1的概率;
r表示奖励函数,指智能体在st采取了一个动作at以后,对标签多样性的评价函数;r通过下式进行表达:
式中,f(it)对应的是ndcg值,通过下式进行表达:
rel是该标签的相关性值,i表示标签所在的当前位置大的序号,k为智能体的参考的标签数量,m表示标签所在的当前位置序号;
τ(it)对应的是α-ndcg值,是ndcg值的变形,表示标签如果含有新发现的子话题,则α-ndcg值增加;如果含有无关的子话题则α-ndcg值降低,τ(it)通过下式进行表达:
ng(i)表示智能体提供的第i个标签所能获得的多样性评估得分,α为影响系数,ng*(i)标签i在理想情况下的最优得分值;
γ表示未来动作所得到的奖励对当前状态值的影响程度;
s2:搭建深度神经网络优化训练q值;q值通表示在状态s采取动作后能获取的期望得分奖励,q(st,at)=q(st,at)+μ[r+γmaxa'q(st+1,aa+1)-q(st,at)],μ是q-learning过程中的学习率,maxa'q(st+1,aa+1)是智能体模拟的下个动作能得到的最大得分值;
如图2所示,s2包括以下流程:
s2.1:构造深度卷积网络,用于对q值进行初步计算;通过输入固定格式的问题和标签数据,经卷积层以及全连接层,最后输出每一个标签的预计收益a;
s2.2:构造回放经验池,通过记录训练过程中所有的样本<st,at,rt,st+1>,每一个样本定义为一个经验,存入经验池中,网络学习从经验池中均匀抽出样本进行学习;
s2.3:定义一个实时更新的深度神经网络,记为q(s,a;θ),θ为神经网络的网络参数值;另外定义一个与q(s,a;θ)相同结构的深度神经网络,但是参数相隔时间c从实时更新的深度神经网络中同步一次,记为
θt+1=θt+μ[r+γmaxa'q(s',a';θ-)-q(s,a;θ)]▽q(s,a;θ)。
s3:利用训练集训练深度强化学习模型;
如图3所示,s3包括以下流程:
s3.1:初始化一个容量为n的回放经验池d,随机初始化动作价值函数q,记录其参数为θ;初始化目标动作价值函数
s3.2:智能体的动作执行以下内容:
概率ξ:随机选择一个动作at;
概率1-ξ:执行动作at=argmaaxq(φ(st),a;θ),ξ是人为预设值;
s3.3:观察智能体执行动作at后的回报rt以及下一个数据xt+1;
s3.4:更新st+1=st,at,xt+1,φt+1=φ(st+1),将样本(φt,at,rt,φt+1)存到经验回放池d中;
s3.5:从d中随机采样一个批次的样本(φk,ak,rk,φk+1);
s3.6:最佳得分值yk通过下式进行表达:
s3.7:对参数θ进行(yk-q(θk,ak;θ-))2梯度反转;
s3.8:每c步将目标动作价值函数
s3.9:若没有完成最大迭代数目,则执行s3.3;否则执行s3.10;
s3.10:若没有结束所有采样序列episode,执行s3.2;否则执行s4
s4:根据深度强化学习模型输出结果对问题进行标签标注;
s4包括以下流程:
s4.1:输入训练完成的标注策略π,问题q,候选标签t;
s4.2:初始化候选标签集合;
s4.3:通过标注策略π选择一个标签;
s4.4:更新标签列表,到达下一个状态st+1;
s4.5:若标签列表中标签数量未达到要求预设值,执行s4.2。
s4.6:输出标签列表,作为该问题的标签。
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!