可配置的异构数据实时同步并可视化的系统及方法与流程
本发明涉及大数据技术领域,特别涉及一种可配置的异构数据实时同步并可视化的系统及方法。
背景技术:
关系型数据库和大数据仓库hive之间的数据同步的解决方案一方面体现在开源产品上:1、sqoop广泛应用于将离线数据从关系型数据库导入到hadoop大数据平台中;2、kettle可以通过时间戳字段对原有全量数据进行排序,并结合中间表记录每次更新的时间戳的方式实现数据实时增量同步。另一方面体现在同行的研究上:1、使用消息中间件来屏蔽两种异构数据库的差异性。比如已经公开的一种基于消息中间件的异构数据库实时同步方法,方法中包括:数据采集模块,根据不同类型的数据源部署不同的数据采集装置进行数据的采集。数据模型模块,将各自采集来的数据进行加工处理并采用protobuffer技术封装成统一数据模型。持久化模块,将采集模块封装的统一数据模型发送给消息中间件进行持久化。数据处理模块,通过消息处理框架api(应用程序编程接口)从消息中间件中拉取数据,并根据业务规则进行业务处理。
开源同步工具虽然为数据同步提供了强大的功能,但一般需要单独的部署,很难大数据统计分析平台整合在一起。另外,kettle可以通过时间戳字段对原有全量数据进行排序,并结合中间表记录每次更新的时间戳的方式实现数据实时增量同步,这种方式明显的缺点是:1、对关系型数据源进行io操作,影响线上业务性能;2、周期性进行数据同步,实时性差。sqooop主要用来进行离线数据的同步,它的缺点是使用命令行的形式进行同步操作,使用门槛比较高,可用性差。在同行的研究中使用消息系统可以屏蔽异构的数据库的异构性,但没有体现使用的便捷性,以及和具体的统计分析任务整合的便捷性。
为了解决海量数据的分析需求,围绕hive(统计分析用的,将结构化的数据文件映射为数据表)进行大数据仓库建设并在之上使用hiveql进行统计分析是业界常用的解决方案,而线上web业务系统产生的数据一般存储在关系型数据库中,这就需要将关系型数据库中的数据导入到大数据仓库hive中,对于需要对线上业务产生的最新全量数据进行实时统计分析的用户,同时需要将线上业务产生的增量数据实时数据同步到大数据仓库hive中。
技术实现要素:
本发明旨在至少在一定程度上解决相关技术中的技术问题之一。
为此,本发明的一个目的在于提出一种可配置的异构数据实时同步并可视化的系统,该系统可以对大数据仓库hive中的实时数据流通过自定义统计指标的形式和统计分析任务结合在一起,还可以以配置的方式将将统计自定义的统计指标和实时大屏绑定在一起,从而为统计分析人员提供了数据从线上业务系统到进行大数据统计分析的便捷的一栈式解决方案。
本发明的另一个目的在于提出一种可配置的异构数据实时同步并可视化的方法。
为达到上述目的,本发明一方面实施例提出了一种可配置的异构数据实时同步并可视化的系统,包括:元仓子系统模块,用于存储元数据信息,其中,所述元数据信息包括:历史元数据信息和实时增量元数据信息;历史数据批处理同步子系统模块,用于获取所述历史元数据信息并进行数据批处理,将批处理过的数据以预设格式存储在预设数据仓库中;实时同步子系统模块,用于获取所述实时增量元数据信息进行处理并完成指定数据类型的转换,将处理后的数据存储在所述预设数据仓库中;可视化大屏子系统模块,用于将所述预设数据仓库中的数据和自定义的统计指标与可视化大屏进行配置管理;可视化模块,用于将所述可视化大屏子系统模块进行配置管理后的数据展示在所述可视化大屏上提供给用户查看管理。
本发明实施例的可配置的异构数据实时同步并可视化的系统,通过canal解析binlog日志的形式获得线上业务的实时增量数据,不经过io操作,对线上业务性能无影响,将基于spark的批处理同步任务和基于storm的实时同步任务结合在一起,通过任务开关在一个配置任务先后进行批处理同步和实时同步,进而将生产系统中的全量的数据同步到大数据仓库hive中,极大地方便了系统使用任务的使用。
另外,根据本发明上述实施例的可配置的异构数据实时同步并可视化的系统还可以具有以下附加的技术特征:
进一步地,在本发明的一个实施例中,所述预设数据仓库通过图形化界面的形式完成所述自定义的统计指标。
进一步地,在本发明的一个实施例中,所述历史数据批处理同步子系统模块进一步用于:在将批处理过的数据保存到所述预设数据仓库时,将所述预设数据仓库的表格式保存为orc形式以支持实时数据的插入操作。
进一步地,在本发明的一个实施例中,所述可视化大屏子系统模块进一步用于:将所述自定义的统计指标和所述可视化大屏绑定在一起提供一个配置管理界面来更新或预览所述可视化大屏对应的统计指标,并查看所述可视化大屏的相关所述元数据信息。
进一步地,在本发明的一个实施例中,所述可视化模块进一步用于:查看数据实时同步任务的任务名称、创建时间、执行状态和实时与非实时任务切换开关的所述元数据信息。
为达到上述目的,本发明另一方面实施例提出了一种可配置的异构数据实时同步并可视化的方法,包括:s1,获取历史元数据信息并进行数据批处理,将批处理过的数据以预设格式存储在预设数据仓库中;s2,获取实时增量元数据信息进行处理并完成指定数据类型的转换,将处理后的数据存储在所述预设数据仓库中;s3,将所述预设数据仓库中的数据和自定义的统计指标与可视化大屏进行配置管理;s4,将s3中配置管理后的数据展示在所述可视化大屏上提供给用户查看管理。
本发明实施例的可配置的异构数据实时同步并可视化的方法,通过canal解析binlog日志的形式获得线上业务的实时增量数据,不经过io操作,对线上业务性能无影响,将基于spark的批处理同步任务和基于storm的实时同步任务结合在一起,通过任务开关在一个配置任务先后进行批处理同步和实时同步,进而将生产系统中的全量的数据同步到大数据仓库hive中,极大地方便了系统使用任务的使用。
另外,根据本发明上述实施例的可配置的异构数据实时同步并可视化的方法还可以具有以下附加的技术特征:
进一步地,在本发明的一个实施例中,所述预设数据仓库通过图形化界面的形式完成所述自定义的统计指标。
进一步地,在本发明的一个实施例中,s2进一步包括:在将批处理过的数据保存到所述预设数据仓库时,将所述预设数据仓库的表格式保存为orc形式以支持实时数据的插入操作。
进一步地,在本发明的一个实施例中,s3进一步包括:将所述自定义的统计指标和所述可视化大屏绑定在一起提供一个配置管理界面来更新或预览所述可视化大屏对应的统计指标,并查看所述可视化大屏的相关元数据信息。
进一步地,在本发明的一个实施例中,s4进一步包括:查看数据实时同步任务的任务名称、创建时间、执行状态和实时与非实时任务切换开关的所述元数据信息。
本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
图1为根据本发明一个实施例的可配置的异构数据实时同步并可视化的系统的结构示意图;
图2为根据本发明一个实施例的可配置的异构数据实时同步并可视化的系统的总体架构图;
图3为根据本发明一个实施例的可配置的异构数据实时同步并可视化的系统的框架图;
图4为根据本发明一个实施例的历史数据批处理同步子系统模块的系统架构图;
图5为根据本发明一个实施例的实时同步子系统模块功能架构图;
图6为根据本发明一个实施例的可视化大屏子系统模块功能架构图;
图7为根据本发明一个实施例的web平台可视化模块功能架构图;
图8为根据本发明一个实施例的可配置的异构数据实时同步并可视化的方法流程图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
下面参照附图描述根据本发明实施例提出的可配置的异构数据实时同步并可视化的系统及方法,首先将参照附图描述根据本发明实施例提出的可配置的异构数据实时同步并可视化的系统。
图1为根据本发明一个实施例的可配置的异构数据实时同步并可视化的系统的结构示意图。
如图1所示,该可配置的异构数据实时同步并可视化的系统包括:元仓子系统模块100、历史数据批处理同步子系统模块200、实时同步子系统模块300、可视化大屏子系统模块400和可视化模块500。
其中,元仓子系统模块100用于存储元数据信息,其中,元数据信息包括:历史元数据信息和实时增量元数据信息。
历史数据批处理同步子系统模块200用于获取历史元数据信息并进行数据批处理,将批处理过的数据以预设格式存储在预设数据仓库中。
实时同步子系统模块300用于获取实时增量元数据信息进行处理并完成指定数据类型的转换,将处理后的数据存储在预设数据仓库中。
可视化大屏子系统模块400用于将预设数据仓库中的数据和自定义的统计指标与可视化大屏进行配置管理。
可视化模块500用于将可视化大屏子系统模块进行配置管理后的数据展示在可视化大屏上提供给用户查看管理。
该系统可以对大数据仓库hive中的实时数据流通过自定义统计指标的形式和统计分析任务结合在一起,同时,系统还可以以配置的方式将将统计自定义的统计指标和实时大屏绑定在一起,从而为统计分析人员提供了数据从线上业务系统到进行大数据统计分析的便捷的一栈式解决方案。
进一步地,总体架构设计如图2所示,由图2可以看出,可配置的异构数据实时同步并可视化系统包括交互层、逻辑抽象层、框架层和基础层。如图3所示,具体可以分为元仓子系统模块,历史数据批处理同步子系统模块、实时同步子系统模块、可视化大屏子系统模块和web平台可视化模块五大模块。
web平台架构在spark和storm分布式集群之上,其中使用spark作为整个海量历史数据同步处理的计算引擎,历史数据的批处理同步子系统基于spark进行二次开发,使其具有处理海量历史数据批处理同步的能力。采用storm作为实时同步主要组件,对其进行二次开发,使其满足具体的业务场景的实时数据处理任务。同时在实时同步子系统中使用canal解析关系型数据库mysql中的增量数据,使用kafka作为峰值缓存数据的消息中间件,使用hive作为异构的数据目的地。在可视化大屏子系统中使用quartz执行定时的统计任务,实时更新统计指标生成实时可视化大屏。整个平台对外统一使用vue实现可视化web平台,使用echarts插件实现可视化大屏的绘图展示。
本系统强调了两大功能,一、便捷的数据同步同能,可以在一个数据同步任务中通过任务开关的形式完成历史数据的批处理以及增量数据的实时同步进而获取线上业务系统关系行数据库表中的最新的全量数据;二、便捷的将数据同步任务和大数据统计分析绑定在一起,在图形化界面可以预览部署目标hive表中的数据,在预览数据的同时可以在当前任务加入自定义统计指标任务,并且可以通过配置的方式将统计指标和具体的大屏绑定在一起。在启动的任务系统中加入quartz定时任务定时计算更新统计指标对应的统计值,在绘制可视化大屏时通过定时轮询访问的和当前大屏绑定的统计指标值的方式实时绘制可视化大屏,最终大屏的实时可视化展示。
进一步地,在本发明的实施例中,通过各个模块以及模块间的交互实现异构数据的实时同步并可视化,下面详细介绍系统模块的组成。
1)元仓子系统模块
元仓子系统模块100是用来存储本系统的元数据信息,使用mysql作为底层的存储架构,主要存储了生成同步任务所需的数据源配置信息,同步过滤规则配置信息,数据目的地配置信息,任务本身的创建时间、创建人、任务状态信息,实时同步模块的自定义统计指标信息、可配置大屏的配置信息等,元仓子系统模块为其他模块提供所需的元数据信息,是其他子系统模块的辅助模块。
2)历史数据批处理同步子系统模块
进一步地,在本发明的一个实施例中,历史数据批处理同步子系统模块进一步用于:在将批处理过的数据保存到预设数据仓库时,将预设数据仓库的表格式保存为orc形式以支持实时数据的插入操作。其中,在本发明的实施例中,预设数据仓库为hive。预设数据仓库hive通过图形化界面的形式完成自定义的统计指标。
如图4所示,为历史数据批处理同步子系统模块的系统架构图,图底层基于spark进行搭建,充分利用spark优秀的计算能力以及系统容错能力。在spark之上,对spark进行二次封装,构建出执行处理引擎模块。执行处理引擎模块主要包含了三个子模块,数据源读取模块,数据过滤处理模块,装载数据模块。
2-1)数据源读取模块
数据源读取模块是基于spark对各种数据源支持的接口进行二次封装开发的,封装了spark读取mysql的接口,读取hive的接口。同时,将存储于元仓子系统模块中的任务配置数据通过pandas的dataframe读取后驻留在内存中,提供给数据过滤处理模块使用。为了实现平台后期的可扩展性可以根据数据源配置信息中不同的数据源类型选择使用不同的数据读取接口读取数据。
2-2)数据过滤处理模块
数据过滤处理模块是基于spark的抽象数据结构dataframe进行开发的,sparkdataframe提供了详细的数据结构信息,在内存中以数据库表的形式存在,使用sparkdataframe的filter接口对读取的数据进行过滤操作。使用sparkdataframe的drop接口完成忽略字段操作,使用sparkdataframe的withcolumn函数结合udf(用户定义函数)对选定的列进行加密操作,同时将加密的密钥通过元仓子系统模块进行持久化保存。
2-3)数据装载模块
数据装载模块同数据源读取模块一样是基于spark对各种数据源支持的接口进行的二次封装开发,不同的是,数据源读取模块读取的是需要进行同步操作的数据源,而数据装载模块是把进行过数据过滤处理模块处理过后的结果数据集保存到同步的数据目的地。同时,本模块在实现将数据保存到hive时做了特殊的处理,需要将hive的表格式保存为orc形式,原因是orc类型的表才支持实时数据的插入操作。
3)实时同步子系统模块
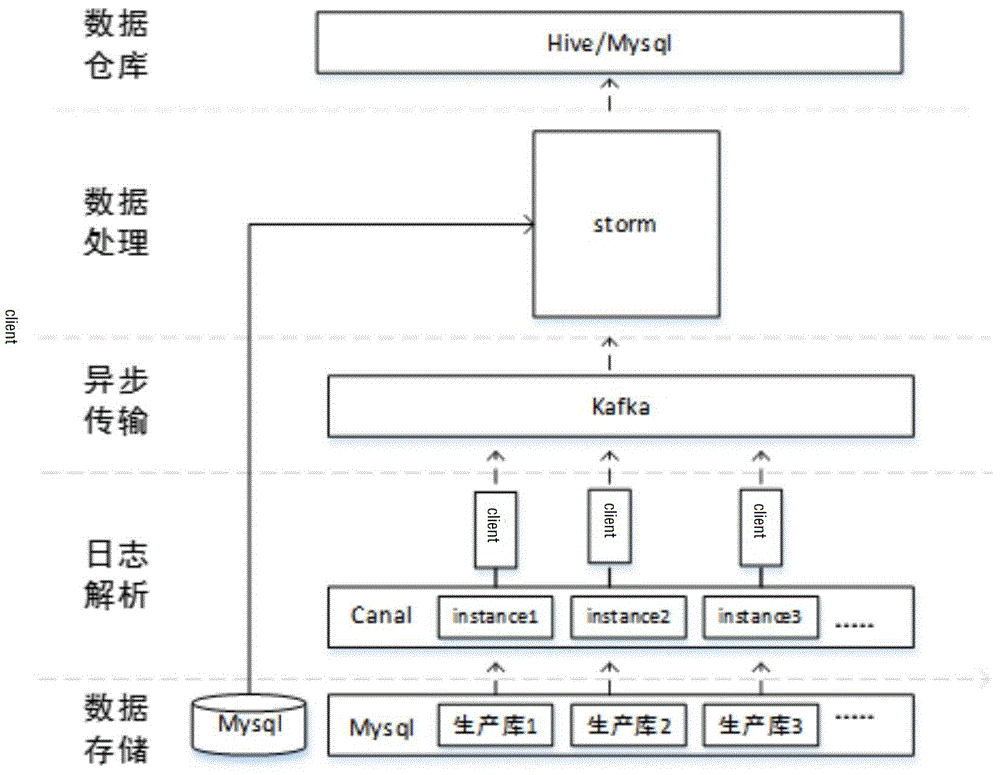
如图5所示,为实时同步子系统模块的系统架构图。底层基于canal、storm和kafka开发,充分利用了各大数据组件的优良特性,并在其原有的api(applicationprogramminginterface,应用程序编程接口)上进行了二次开发,分别实现了日志解析模块、异步传输模块、数据处理模块以及数据仓库模块。
3-1)日志解析模块
日志解析模块主要完成的工作是使用canal通过binlog日志的方式捕获实时增量数据,并发送到下游的异步传输模块具体处理执行流程:
a.对mysql数据源进行相关配置。开启mysql的binlog日志功能,在mysql中添加一个用于canal的数据库管理用户并授予replication权限,在其instance.properties文件中配置前面添加的用户名和密码以及需要监听的数据库信息,将其伪装成mysqlslaver。配置destination,每个destination代表对某一特点表监听的线程,从而实现并行化,同时使用数据库和表明组成destination的名称,确保destination名称的唯一性。
b.启动canalserver对数据源进行监听。
c.在web项目中使用canal客户端连接cannalserver,同时根据数据源配置信息中数据库名和表名称订阅指定对应的destination,获取connector。
d.判断下游kafka中是否存在以数据目的地配置信息中获取的{目的地ip}.{目的地数据库}.{目的地表}的格式组成topic名称,如不存在则使用cafka客户端api进行创建。
e.读取任务元数据获取读取的数据库名称以及表名称并使用canalconnecor对指定的数据库名称和表名称进行订阅,然后进行轮询操作,至此canal会使用指定的destination处理订阅的表的监听工作。
f.监听到的增量数据会被封装到protobuff定义通信协议结构中,对其进行解析只获取insert类型的增量数据,并将其数据类型、数据字段名称、数据值封装到自定义的数据结构kafkatuple中。
g.对kafkatuple填充从元仓子系统获得的任务元数据过滤规则、以及数据目的地配置信息。
h.将kafkatuple使用gson序列化成json格式并使用kafkaproducerapi发送到对应的topic中。
3-2)异步传输模块
异步传输模块的功能是对上游发送来的消息进行缓存,在峰值数据到来时起到削峰的作用,主要完成的工作是对其api(应用程序编程接口)进行二次封装,向日志解析模块提供易于使用的api接口,主要封装了对判断指定的topic是否存在的接口,向指定topic发送消息的接口。
3-3)数据处理模块
此模块是基于storm实现,并对storm的api进行二次封装,充分利用了storm的低延迟、高容错、分布式实时并行计算的特点。主要完成与上游异构传输模块的整合以及过滤业务的处理。在与上游异构传输模块的数据整合中封装了storm的kafkaspout接口,同时为了防止对上游kafka的topic中的信息的重复读取,对kafkasoput接口的配置api设置了kafka.api.offsetrequest.lastesttime(),从而实现了每次都读取topic中的最新消息。在过滤业务处理按功能实现了三种bolt,omitcolumnbolt实现过滤字段功能,datafilterbolt实现数据过滤功能,dataencryptionbolt实现数据加密功能,storm框架本身提供了很多bolt接口,本模块中实现的bolt是通过集成抽象类baserichbolt实现
3-4)数据仓库模块
数据仓库模块主要完成了storm与hive以及mysql的整合,由于从canal获取的增量数据的数据类型都是string(字符串)类型的,所以在本模块完成了从string类型到指定数据类型的转换工作。
4)可视化大屏子系统模块
如图6所示,为可视化大屏子系统模块的系统架构图,同时使用元仓子系统模块进行元数据管理。根据实际的业务需求分别实现了自定义统一指标模块,大屏配置化模块和可视化大屏模块。
4-1)自定义统计指标模块
自定义统计指标模块是直接在基于storm的实时同步子系统模块之上进行的二次开发,一方面可以服务于基于storm的实时同步子子系统模块,自定义的统计指标直接和具体的实时同步任务关联,当实时同步任务的数据目的地增加了一条数据时,可以动态地反映到自定义的统计指标上,可以对实时同步的数据任务起到一种校验功能,同时,对第一阶段的实时同步任务的数据有个直观的展示。自定义统计指标子模块基于quartz开发,系统使用人员通过直接在目标数据集上添加统计指标名称和对应的统计sql来完成自定义统计指标的添加工作。为了保证统计指标的唯一性会对名称进行判重操作。把自定义的统计指标持久化保存到元仓子系统模块中,然后通过quartz定时任务定时执行统计指标对应的统计sql并对统计结果进行更新。同时会根据同步任务的数据目的地类型动态选择sql引擎,从而方便支持sql新的执行引擎的集成,有利于系统的扩展。
4-2)可视化大屏配置模块
进一步地,在本发明的一个实施例中,将自定义的统计指标和可视化大屏绑定在一起提供一个配置管理界面来更新或预览可视化大屏对应的统计指标,并查看可视化大屏的相关元数据信息。
具体地,可视化大屏配置模块主要负责将一些自定义的统计指标和可视化大屏绑定在一起,提供一个易于使用的配置管理界面,可以更新或者预览大屏对应的统计指标,可以查看大屏的相关元数据信息,可以通过模糊查询的方式查找特定的大屏。
4-3)可视化大屏模块
可视化大屏模块主要负责最终的可视化大屏的展示,为了实现最终的可视化大屏的展示还需要进行前置配置工作,需要配置大屏的实时属性,如果是实时的可视化大屏会轮询请求接口获取当前大屏的最新的统计指标值,如果是非实时,则只请求一次接口获得当前最新的统计指标值,最后使用echart插件进行动态绘图,生成最终的可视化大屏。
5)可视化模块
进一步地,在本发明的一个实施例中,可视化模块进一步用于:查看数据实时同步任务的任务名称、创建时间、执行状态和实时与非实时任务切换开关的元数据信息。
可以理解的是,可视化模块是基于web平台进行开发的,如图7所示,为web平台可视化模块功能架构图,主要包含三个子模块,可视化任务管理模块、可视化大屏管理模块以及访问权限控制模块。
5-1)可视化任务管理模块
可视化任务管理模块对应的是基于spark的历史数据批处理同步子系统模块和基于storm的实时同步子系统模块对应的功能,能够以可视化的方式对同步任务进行数据源的配置、过滤规则的配置、数据目的地的配置等。可以查看任务的任务名称、创建时间、执行状态、实时与非实时任务切换开关等元数据信息。
5-2)可视化大屏管理模块
可视化大屏管理模块对应的是基于quartz定时任务的可视化大屏子系统模块所提供的系统能力,能够通过web可视化的方式添加自定义的统计指标、实时查看统计指标对应的统计值,能够以可视化的方式对大屏元数据信息进行管理、为大屏绑定对应的统计指标,最终能通过选择配置好的大屏元数据信息的方式将大屏可视化展示。
5-3)访问权限控制模块
访问权限控制模块是基于对平台使用和的不用定位,赋予不同使用这不同的使用权限,并根据不同的使用权限来提供不同的功能。
根据本发明实施例提出的可配置的异构数据实时同步并可视化的系统,通过canal解析binlog日志的形式获得线上业务的实时增量数据,不经过io操作,对线上业务性能无影响,将基于spark的批处理同步任务和基于storm的实时同步任务结合在一起,通过任务开关在一个配置任务先后进行批处理同步和实时同步,进而将生产系统中的全量的数据同步到大数据仓库hive中,极大地方便了系统使用任务的使用。
其次参照附图描述根据本发明实施例提出的可配置的异构数据实时同步并可视化的方法。
图8为根据本发明一个实施例的可配置的异构数据实时同步并可视化的方法流程图。
如图8所示,该可配置的异构数据实时同步并可视化的方法包括以下步骤:
s1,获取历史元数据信息并进行数据批处理,将批处理过的数据以预设格式存储在预设数据仓库中;s2,获取实时增量元数据信息进行处理并完成指定数据类型的转换,将处理后的数据存储在预设数据仓库中;s3,将预设数据仓库中的数据和自定义的统计指标与可视化大屏进行配置管理;s4,将s3中配置管理后的数据展示在可视化大屏上提供给用户查看管理。
进一步地,在本发明的一个实施例中,预设数据仓库通过图形化界面的形式完成自定义的统计指标。
进一步地,在本发明的一个实施例中,s2进一步包括:在将批处理过的数据保存到预设数据仓库时,将预设数据仓库的表格式保存为orc形式以支持实时数据的插入操作。
进一步地,在本发明的一个实施例中,s3进一步包括:将自定义的统计指标和可视化大屏绑定在一起提供一个配置管理界面来更新或预览可视化大屏对应的统计指标,并查看可视化大屏的相关元数据信息。
进一步地,在本发明的一个实施例中,s4进一步包括:查看数据实时同步任务的任务名称、创建时间、执行状态和实时与非实时任务切换开关的元数据信息。
需要说明的是,前述对可配置的异构数据实时同步并可视化的系统实施例的解释说明也适用于该实施例的方法,此处不再赘述。
根据本发明实施例提出的可配置的异构数据实时同步并可视化的方法,通过canal解析binlog日志的形式获得线上业务的实时增量数据,不经过io操作,对线上业务性能无影响,将基于spark的批处理同步任务和基于storm的实时同步任务结合在一起,通过任务开关在一个配置任务先后进行批处理同步和实时同步,进而将生产系统中的全量的数据同步到大数据仓库hive中,极大地方便了系统使用任务的使用。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!